windows本地操作
环境配置
前提:已下载并配置好anaconda、cuda、pytorch、colmap等。
已在anaconda中配置好虚拟环境,pytorch最好安装在虚拟环境中,不要在base中。
可参考:过程挺详细的
在python终端运行如下代码,将官方代码进行下载。
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
复现流程参考一个外国的大佬写的,但是有些文件的存放在我电脑上运行是有些问题的,以下是我自己进行调整后,可以运行的操作。
复现流程
手动配置操作colmap
因为我的电脑无法用自动配置,所以用的手动。手动和自动配置都在上面的连接中有写到。
1、将已拍好的物体图片存放在文件夹中,命名为input。
 2、利用colmap进行获取相机位姿等操作
2、利用colmap进行获取相机位姿等操作
直接打开colmap。
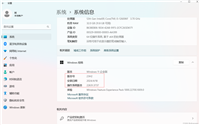
(1)新建一个工程:file>new project,会出现如下对话框
点击new,选择你存放图片所在的文件夹下,新建.db文件,images即存放的图片路径。
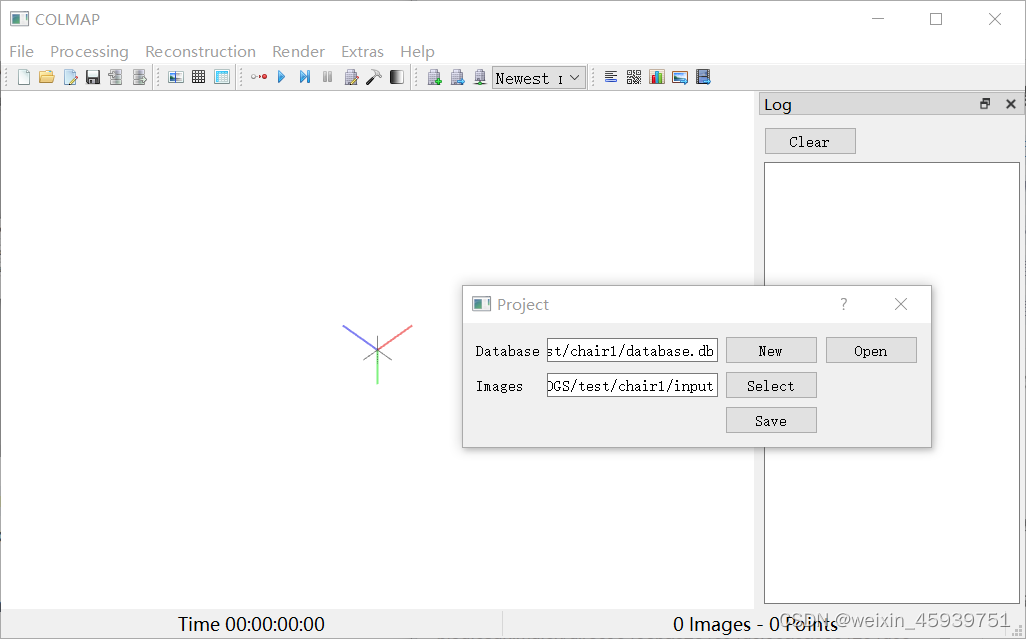
(2)提取特征值:processing>feature extraction,将shared for all images勾上,first_octave设为0,其他设置保持默认选项。
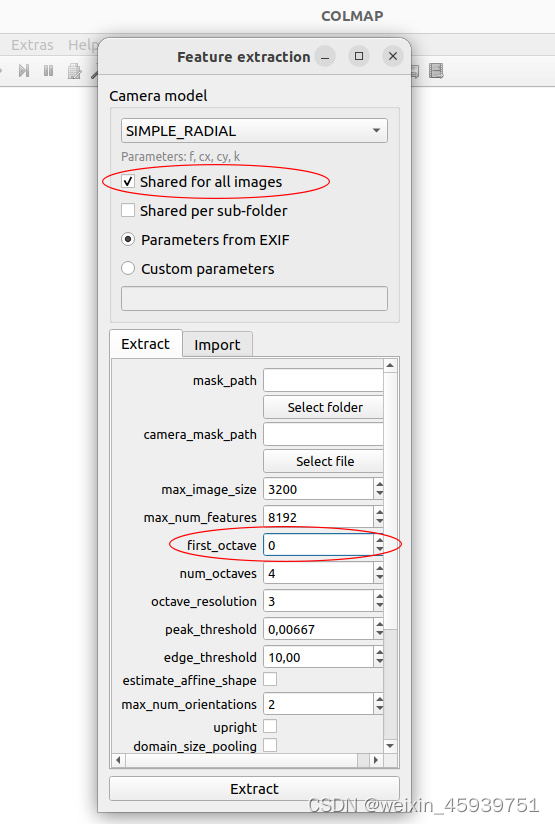
(3)特征匹配:processing>feature matching。
因为拍摄图片时,应该是通过绕着对象走动来记录的,所以相邻的图像在空间上应该是接近的,因此可以使用sequential(顺序匹配模式)。这将比默认的exhaustive(穷举模式)更快(如果重构失败,可以用穷举模式再次尝试)。然后点击run(这将花费几秒钟到一分钟)。
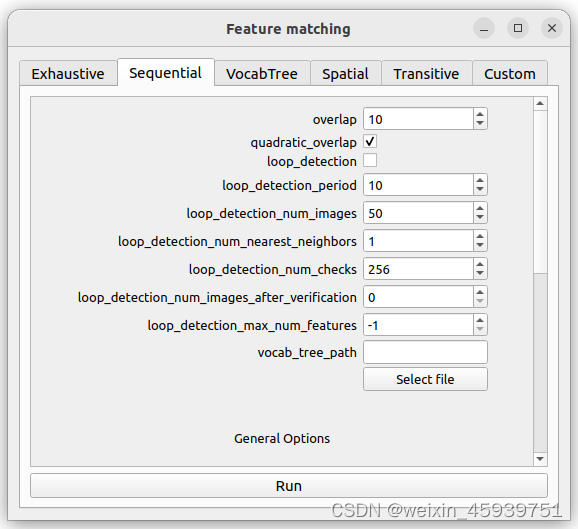
(4)重建:reconstruction>reconstruction options。取消勾选multiple_models(因为我们是对一个而不是多个场景重构),关闭窗口。然后开始重建优化:reconstruction>start reconstruction。
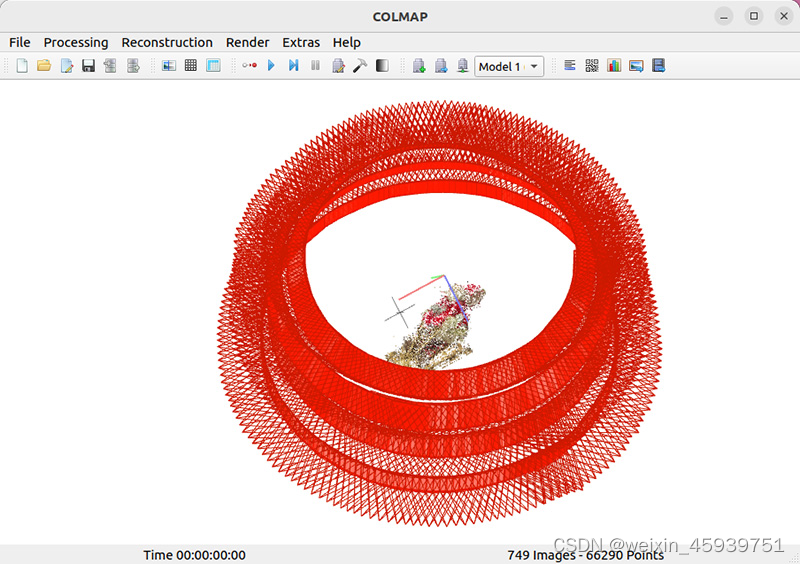
(5)colmap重建完成,将在gui中看到相机姿势(红色)以及场景的稀疏点云。现在通过点击file>export model导出相机姿势,保存在新建的distort文件夹中(与input文件夹相同级别),然后可以关闭colmap。
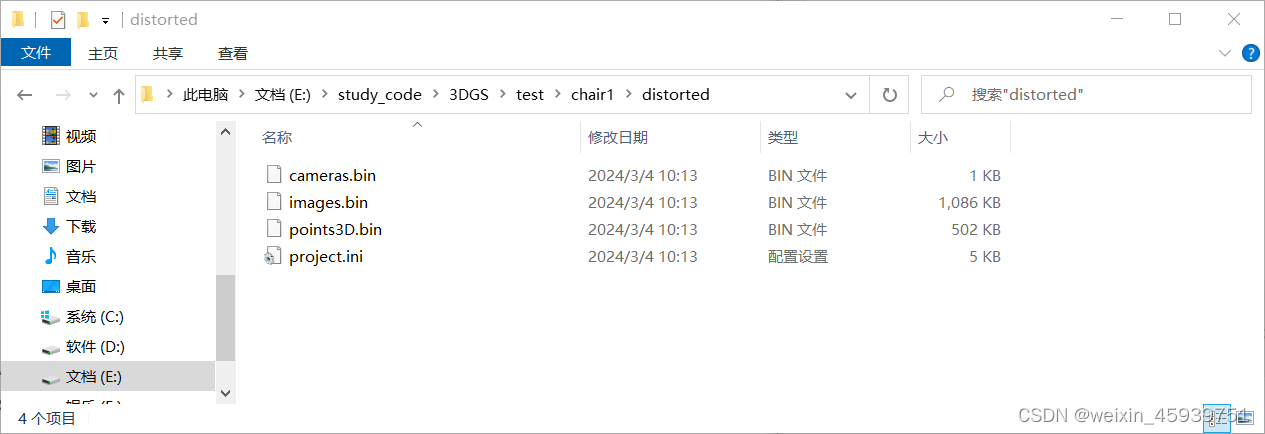
现在的数据应该存放如下:

进行训练前的准备(undistort the images)
现在需要消除图像的扭曲(undistort the images)。这是因为3d高斯的训练要求图像具有理想的针孔特性。
注意,对文件进行多一步操作
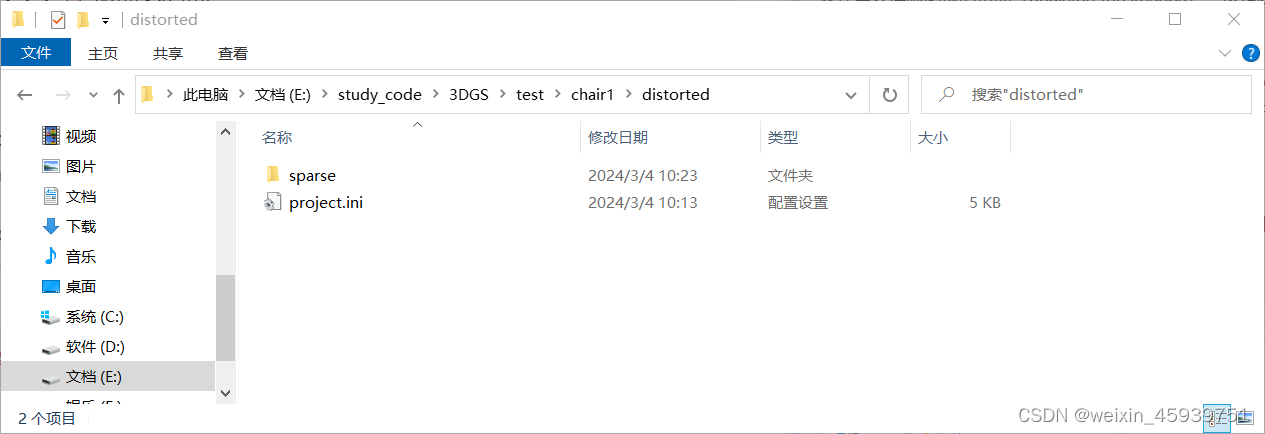
(1)关键!!!跟上面的链接不同之处:
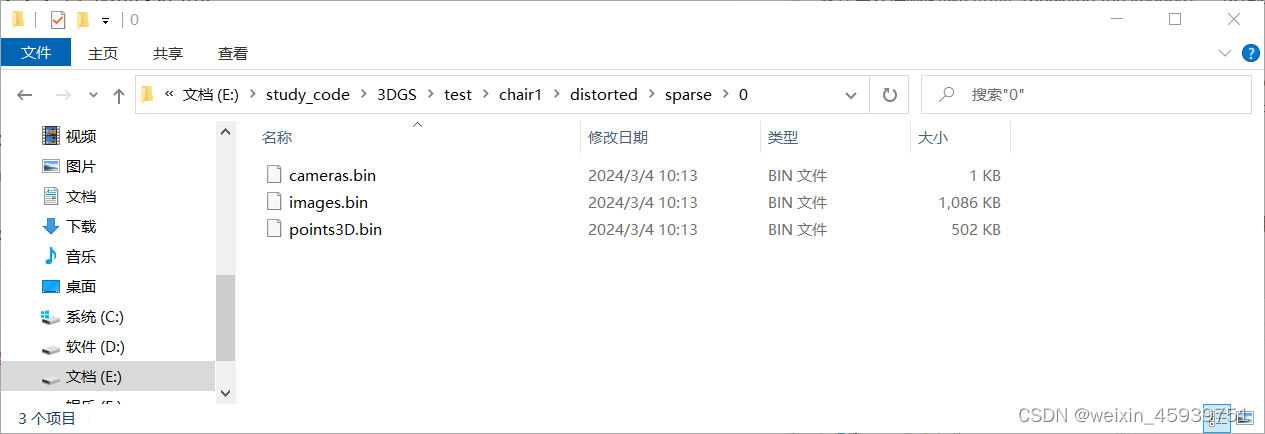
在distorted文件夹下面,新建sparse/0文件夹,并将distorted文件下面的points3d.bin、images.bin、cameras.bin三个文件移到sparse/0文件夹下面。
(2)进入代码的文件夹,新建一个data文件夹,用于存放需要用到的训练数据。

将对象文件移入data
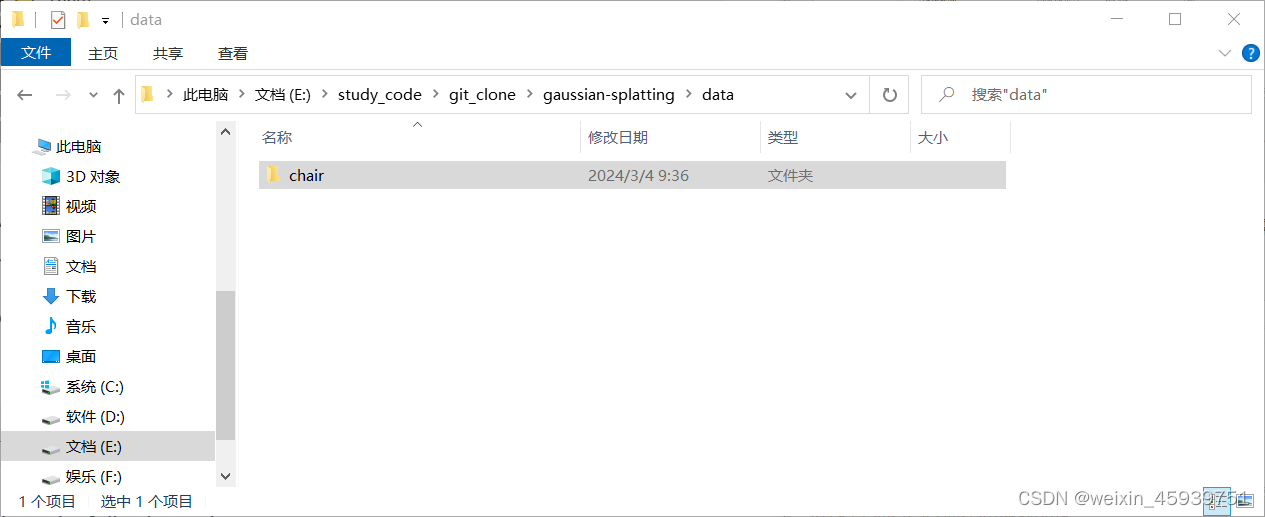
对于下一步进行的训练,实际只需要用到images和sparse两个文件夹下的东西

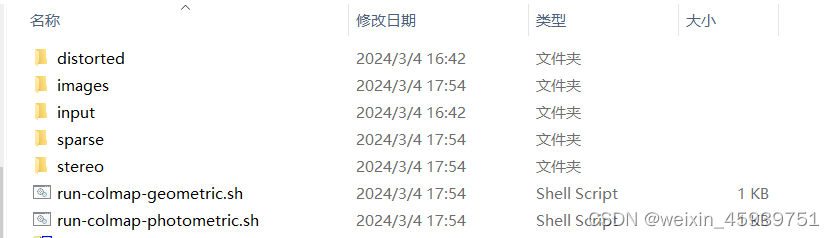
接着,打开终端,进入虚拟环境,进入在gaussion splatting(代码所在)文件夹下。运行如下代码:
python convert.py -s $folder_path --skip_matching
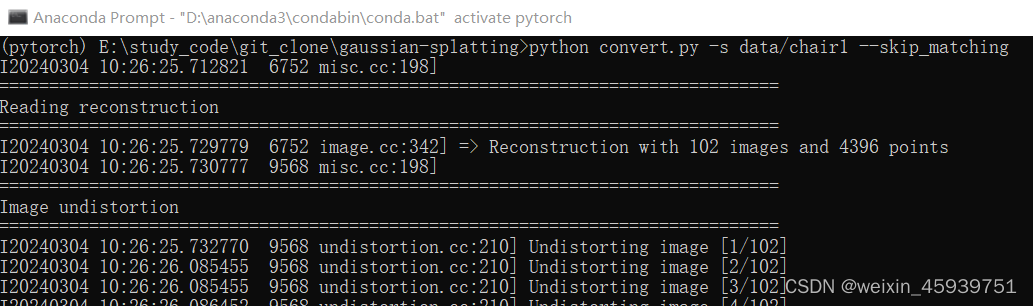

见到done.即代表完成undistort the images的操作。
文件夹的文件分布如下:

至此即可以开始进行训练。
训练
还是在终端进入虚拟环境,进入在gaussion splatting(代码所在)文件夹下。运行如下代码:
python train.py -s $folder_path -m $folder_path/output
运行完后即会得到output文件夹,output中文件如下:
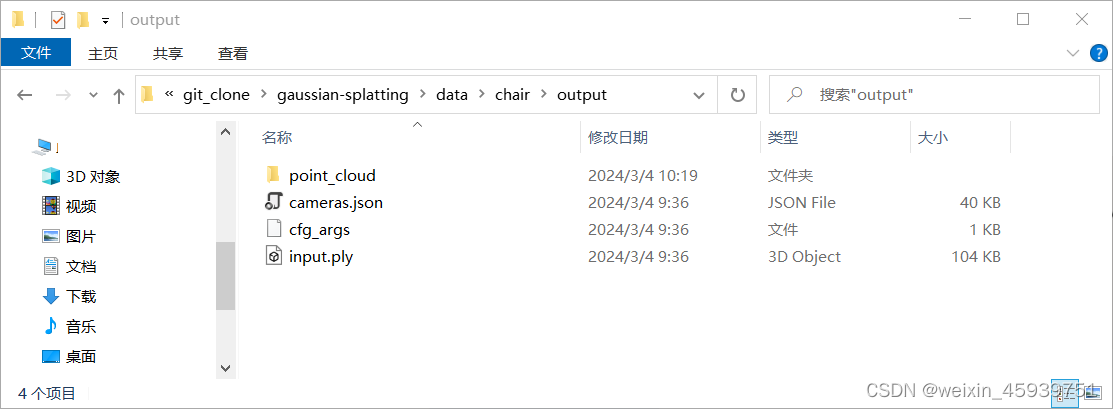
其中,iteration_7000和30000中各存有一个point_cloud.ply文件。
模型可视化
首先下载可视化工具
下载完后得到viwer文件夹,把它移到你建立的工程文件夹下(我的电脑上是gaussian-splatting)
终端进入如下带有sibr_gaussianviewer_app.exe文件的文件夹中

运行如下代码:
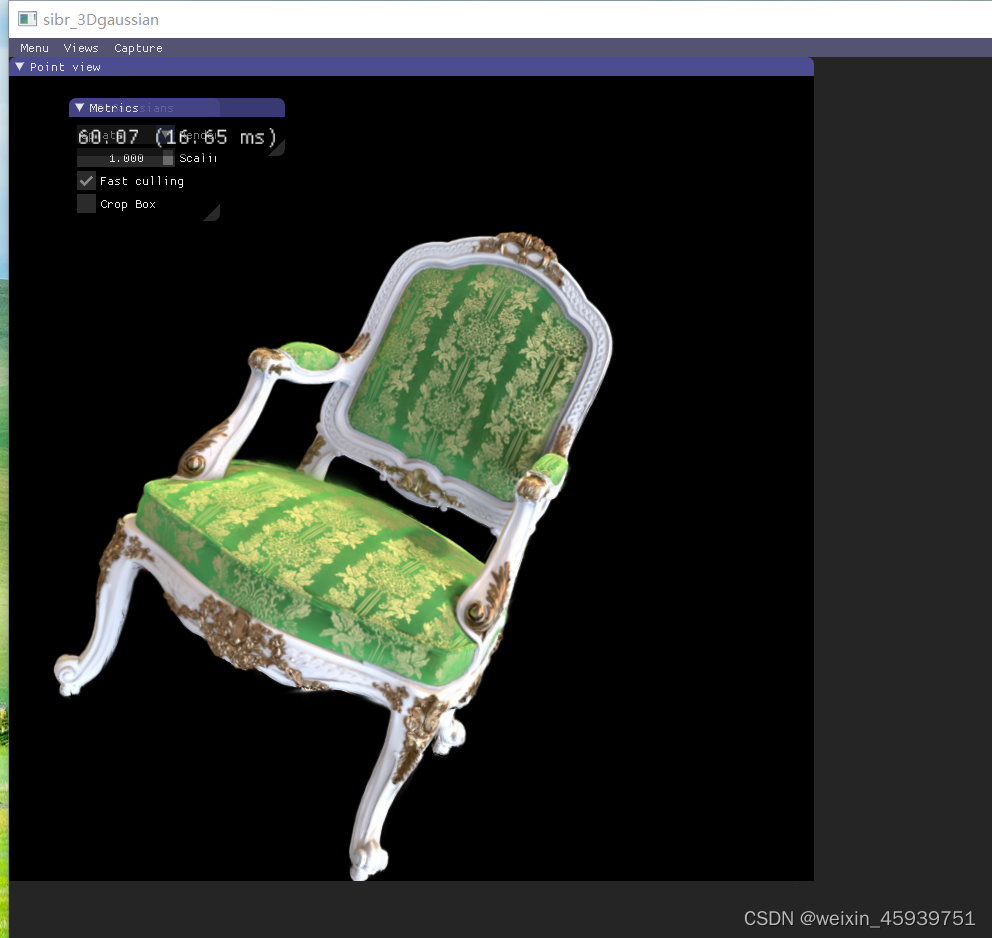
sibr_gaussianviewer_app -m $folder_path/output
到这步就通过sibr看到训练后的可视化成果了。
colab上运行
首先默认大家已经会使用colab再开始看本教程。
不会的可以参考,colab使用教程
进入网址,官方给的ipynb,可以在colab上跑
官方给的代码是默认跑他们给的数据集,如果要跑自己的数据集,则直接修改下面的程序就行:
python train.py -s $folder_path -m $folder_path/output
发表评论