1 介绍
本文将介绍使用开源工具ollama(60.6k⭐)部署llama大模型,以及使用open webui搭建前端web交互界面的方法。
我们先来过一遍几个相关的概念,对这块比较熟悉的朋友可跳过。
1.1 大规模语言模型
大规模语言模型(large language models, llms),顾名思义是指在大量语料数据的基础上训练成的模型,能够模拟人类的语言风格生成较为生动的文本。这类模型的主要特征有:
- 规模大:训练所使用的数据量非常庞大,有时超过1000亿个参数。
- 复杂性高:模型结构比较复杂
- 具有较好的上下文理解能力:大规模语言模型可以理解文本的上下文和细微差别
1.2 llama
llama是一种大规模语言模型,由meta ai基于transformer深度学习框架开发。该模型旨在生成各种风格的高质量文本(例如创意写作、对话甚至诗歌),能够胜任以下工作:
- 自然语言处理(nlp):理解和生成自然语言。
- 机器学习:根据数据和算法学习新的信息和技能。
- 对话生成:可以与用户进行对话,并根据情况生成合适的回应。
1.3 ollama
一款可以快速部署大模型的工具。
1.4 open webui
open webui 是一个可视化的web交互环境,它拥有清新简约的ui风格,具有可扩展、功能丰富、用户友好、自托管的特点,可以完全离线运行。它支持各种 llm 运行程序,包括 ollama 和 openai 兼容的 api。
2 部署llm服务
本文介绍的方法使用于linux系统,同样适用于windows系统的wsl(安装方法可参见我的)。
2.1 部署ollama
1、下载ollama
linux系统的安装命令如下:
curl -fssl https://ollama.com/install.sh | sh
※此外官方还提供了macos和windows的下载方式。
2、下载llama3模型
ollama run llama3
※在这里可以看到该命令的相关介绍。
上述命令将自动拉取模型,并进行sha256验签。处理完毕后自动进入llama3的运行环境,可以使用中文或英文进行提问,ctrl+d退出。
3、配置服务
为使外网环境能够访问到服务,需要对host进行配置。
打开配置文件:vim /etc/systemd/system/ollama.service,根据情况修改变量environment:
- 服务器环境下:
environment="ollama_host=0.0.0.0:11434" - 虚拟机环境下:
environment="ollama_host=服务器内网ip地址:11434"
3、启动服务
启动服务的命令:ollama serve
首次启动可能会出现以下两个提示:
该提示表示文件系统中不存在ssh私钥文件,此时命令将自动帮我们生成该文件,并在命令行中打印相应的公钥。
看到该提示,大概率服务已在运行中,可以通过netstat -tulpn | grep 11434命令进行确认。
- 若命令输出的最后一列包含“ollama”字样,则表示服务已启动,无需做额外处理。
- 否则,可尝试执行下列命令重启ollama:
# ubuntu/debian
sudo apt update
sudo apt install lsof
stop ollama
lsof -i :11434
kill <pid>
ollama serve
# centos
sudo yum update
sudo yum install lsof
stop ollama
lsof -i :11434
kill <pid>
ollama serve
如果您使用的是macos,可在🔗这里找到解决方法。
4、在外网环境验证连接
方法一:执行curl http://ip:11434命令,若返回“ollama is running”,则表示连接正常。
方法二:在浏览器访问http://ip:11434,若页面显示文本“ollama is running”,则表示连接正常。
2.2 ollama常用命令
1、进入llama3运行环境:ollama run llama3
2、启动服务:ollama serve
3、重启ollama
systemctl daemon-reload
systemctl restart ollama
4、重启ollama服务
# ubuntu/debian
sudo apt update
sudo apt install lsof
stop ollama
lsof -i :11434
kill <pid>
ollama serve
# centos
sudo yum update
sudo yum install lsof
stop ollama
lsof -i :11434
kill <pid>
ollama serve
5、确认服务端口状态:netstat -tulpn | grep 11434
3 部署open webui
1、下载open webui
open webui基于docker部署,docker的安装方法可以参考这篇知乎文章。
open webui既可以部署在服务端,也可以部署在客户端:
# 若部署在客户端,执行:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# 若部署在服务端,执行:
docker run -d -p 3000:8080 -e ollama_base_url=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
如果您的机器在国内,建议将--restart的参数值替换为ghcr.nju.edu.cn/open-webui/open-webui:main,下载速度会快非常多(见up主小杨生存日记的这篇文章)。
2、检查相关配置
下载完之后,就可以在浏览器访问了,地址为http://loacalhost:3000(客户端部署)或http://服务器ip:3000。
页面加载完成后(这个过程可能需要一些时间),新注册一个账号并登录。
登录之后,点击页面顶端的齿轮⚙图标进入设置:
- 侧边导航栏-general,将语言设置为中文
- 侧边导航栏-连接,若“ollama 基础 url”这一项为
http://host.docker.internal:11434,则表示ollama服务正常且连接成功;如果是空的,则需要回头检查一下ollama服务了 - 侧边导航栏-模型,一般会自动拉取ollama服务上部署好的模型,可选模型参看官方的这篇文档
- 其它的项目根据需要设置即可
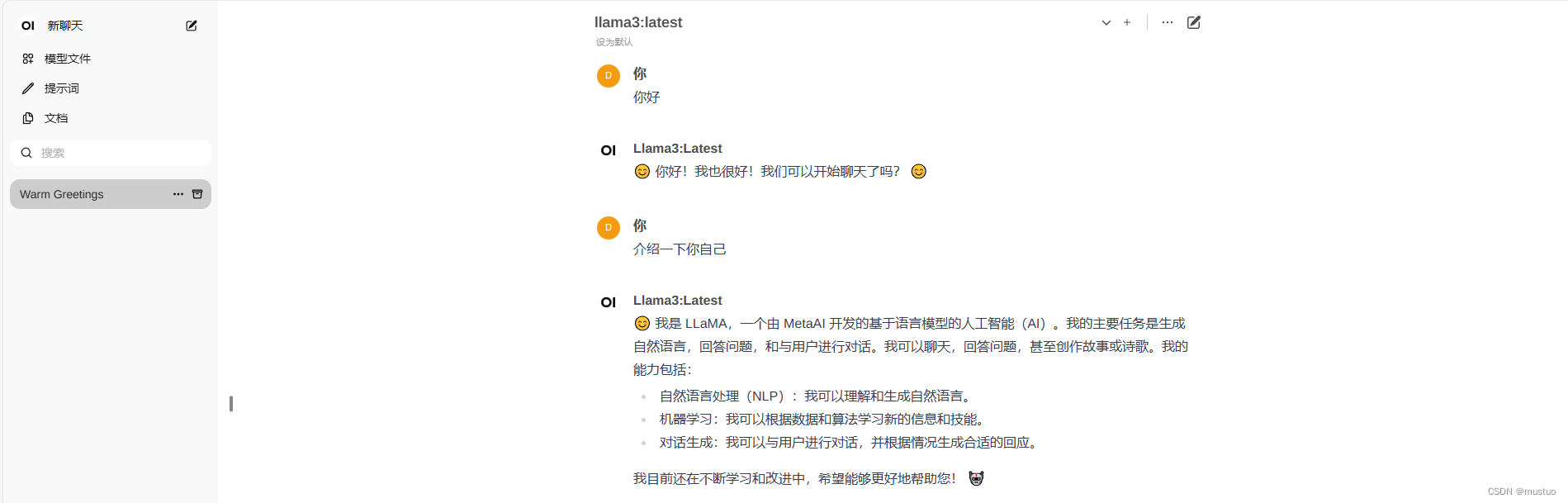
3、选择模型
在顶端下拉框选择好模型,就可以开始提问啦!

发表评论