网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
使用wireshark嗅探getdatarequest产生的tcp包(十六进制字节数组)
| 十六进制位 | 协议部分 | 数值或字符串 |
|---|---|---|
| 00,00,00,1d | 0-3位:len 整个数据包长度 | 长度29 |
| 00,00,00,01 | 4-7位:xid 客户端请求的发起序号 | 1 |
| 00,00,00,04 | 8-11位:type 客户端请求类型 | 4 opcode.getdata |
| 00,00,00,10 | 12-15位:len 节点路径的长度 | 16 节点路径长度转换成十六进制是16位 |
| 2f,24,37,5f, 32,5f,34,2f, 67,65,74,5f, 64,61,74,61 | 16-31位:path 节点路径 | hex编码 |
| 01 | 32位:是否注册watcher | 1-是 |
响应
getdataresponse响应完整协议定义
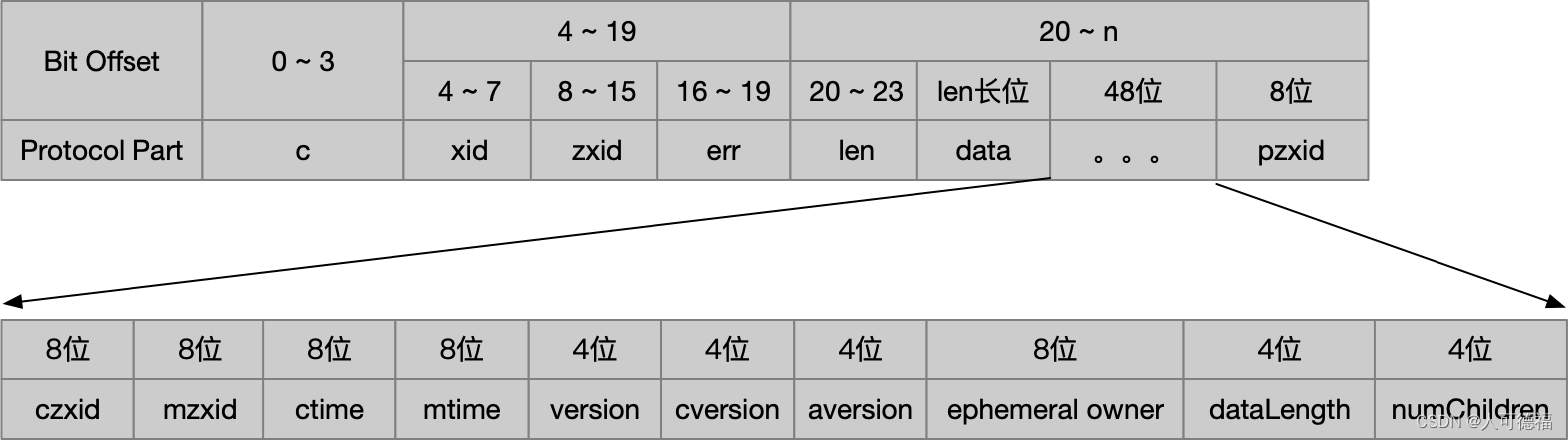
响应头 replyheader
public class replyheader implements record {
private int xid; // 请求时传过来的xid会在响应中原样返回
private long zxid; // zxid 代表zk服务器上当前最新事务id
private int err; // 错误码:code.ok-0,nonode-101,noauth-102,定义在keeperexception.code中
响应体response
//会话创建
public class connectresponse implements record {
private int protocolversion;
private int timeout;
private long sessionid;
private byte[] passwd;
// 获取节点数据
public class getdataresponse implements record {
private byte[] data;
private org.apache.zookeeper.data.stat stat;
// 更新节点数据
public class setdataresponse implements record {
private org.apache.zookeeper.data.stat stat;
getdataresponse 协议定义
| 十六进制位 | 协议解释 | 当前值 |
|---|---|---|
| 00,00,00,63 | 0-3位:len 整个响应的数据包长度 | 99 |
| 00,00,00,05 | 4-7位:xid 客户端请求序号 | 5 本次请求所属会话创建后的第5次请求 |
| 00,00,00,00, 00,00,00,04 | 8-15位: zxid 当前服务器处理过的最大zxid | 4 |
| 00,00,00,00 | 16-19位:err 错误码 | 0-codes.ok |
| 00,00,00,0b | 20-23位:len 节点数据内容的长度 | 11 后面11位是数据内容的字节数组 |
| xxx | 24-34位:data 节点数据内容 | hex编码 |
| 00,00,00,00, 00,00,00,04 | 35-42位:czxid 创建该节点时的zxid | 4 |
| 00,00,00,00, 00,00,00,04 | 43-50位:mzxid 最后一次访问该数据节点时的zxid | 4 |
| 00,00,01,43,67,bd,0e,08 | 51-58位:ctime 数据节点的创建时间 | unix_timestamp 1389014879752 |
| 00,00,01,43,67,bd,0e,08 | 59-66位:mtime 数据节点最后一次变更的时间 | |
| 00,00,00,00 | 67-70位:version 数据节点内容的版本号 | 0 |
| 00,00,00,00 | 71-74位:cversion 数据节点的子版本号 | 0 |
| 00,00,00,00 | 75-78位:aversion 数据节点的acl变更版本号 | 0 |
| 00,00,00,00,00,00,00,00 | 79-86位:ephemeralowner 如果是临时节点,则记录创建该节点的sessionid,否则置0 | 0 (该节点是永久节点) |
| 00,00,00,0b | 87-90位:datalength 数据节点的数据内容长度 | 11 |
| 00,00,00,00 | 91-94位:numchildren 数据节点的子节点个数 | 0 |
| 00,00,00,00,00,00,00,04 | 95-102位:pzxid 最后一次对子节点列表变更的zxid | 4 |
zk客户端
zk客户端的组成:zookeeper实例-客户端入口,hostprovider - 客户端地址列表管理器,clientcnxn-客户端核心线程,内部包含sendthread和eventthread两个线程。前者是一个io线程,负责zookeeper客户端和服务器端间的网络io通信,后者是一个事件线程,负责对服务端事件进行处理。
zk会话的创建过程
初始化阶段
- 初始化zk对象,通过调用zookeeper的构造方法实例化,在此过程中会创建客户端watcher管理器 clientwatchermanager
- 设置会话默认watcher:如果在构造方法中传入了一个watcher对象,客户端会将这个对象作为默认watcher保存在clientwatchermanager中
- 构造zookeeper服务器地址列表管理器 hostprovider:对于构造函数传入的服务器地址,客户端会将其存放在服务器地址列表管理器hostprovider中
- 创建并初始化客户端网络连接器 clientcnxn:clientcnxn连接器的底层io处理器是clientcnxnsocket。另外还会初始化客户端两个核心队列 outgoingqueue 和 pendingqueue 分别作为客户端的请求发送队列和服务端响应的等待队列。
- 初始化sendthread和eventthread:前者管理客户端与服务端之间的所有网络io,后者用于客户端的事件处理
会话创建阶段
- 启动sendthread和eventthread
- 获取一个服务器地址:开始创建tcp连接前,sendthread从hostprovider中随机选择一个地址,调用clientcnxnsocket 创建与zk服务器之间的tcp连接
- 创建tcp长连接
- 构造connectrequest请求:sendthread根据当前客户端的实际设置,构造出一个connectrequest请求,代表了客户端视图与服务端创建一个会话。同时zk客户端会将请求包装成io层的packet对象放入请求发送队列outgoingqueue中
- 发送请求:clientcnxnsocket从outgoingqueue中取出一个待发送的pocket对象序列化成bytebuffer发送到服务端
响应处理阶段
- 接收并处理服务端响应:clientcnxnsocket接收到服务端的响应后,会首先判断当前客户端状态是否是已初始化,才进行反序列化,得到connectresponse对象,从中获取zk服务端分配的sessionid
- 连接成功:通知sendthread进一步对客户端进行会话参数的设置:readtimeout\connecttimeout,更新客户端状态。通知hostprovider当前成功连接的服务器地址
- 生成事件 syncconnected - none:为了让上层应用感知到会话的成功创建,sendthread会生成该事件传递给eventthread,通知会话创建成功
- 查询watcher:eventthread线程收到事件后,会从clientwatchmanager中获取对应watcher,针对syncconnected-none事件找到默认的wathcer,放入eventthread的waitingevents队列中
- 处理事件:eventthread不断从waitingevents队列中取出待处理的watcher对象,调用process方法触发watcher
connectstring解析
connectstring 形如 192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181,zk客户端允许将服务器所有地址配置在字符上,zk客户端在连接服务器的过程中是如何从服务器列表中选择机器的?是顺序?还是随机?
org.apache.zookeeper.client.connectstringparser 中的构造方法对connectstring进行的处理有:解析chrootpath + 保存服务器地址列表到 arraylist serveraddresses
chroot 客户端命名空间
zk3.2.0 之后的版本中添加了该特性,connectstring 可 设置为 192.168.0.1:2181,192.168.0.2:2181/apps/domainname,将解析出chroot=/apps/domainname,这样客户端的所有操作都会限制在这个命名空间下
zookeeper.java
private static hostprovider createdefaulthostprovider(string connectstring) {
return new statichostprovider(new connectstringparser(connectstring).getserveraddresses());
}
解析的结果会返回 地址列表管理器 statichostprovider 的构造方法中
hostprovider
hostprovider 提供了客户端连接所需的host,每一个实现该接口的类需要确保下述几点:
- next() 方法必须有效的inetsocketaddress,这样迭代器能一直运行下去。必须返回解析过的inetsocketaddress实例
- size() 方法不能返回0
public interface hostprovider {
//当前服务器地址列表的个数,不能返回0
int size();
// 获取下一个将要连接的inetsocketaddress,spindelay 表示所有地址都尝试过后的等待时间
inetsocketaddress next(long spindelay);
//连接成功后的回调方法
void onconnected();
//更新服务器列表,返回是否需要改变连接用于负载均衡
boolean updateserverlist(collection<inetsocketaddress> serveraddresses, inetsocketaddress currenthost);
}
解析服务器地址:statichostprovider会解析服务器地址放入serveraddress 集合中,同时使用collections#shuffle方法将服务器地址列表进行随机打散。
获取可用的服务器地址:statichostprovider#next() 方法中将随机排序后的服务器地址列表拼成一个环形循环队列,该过程是一次性的。
hostprovider的实现:自动从配置文件中读取服务器地址列表、动态变更的地址列表管理器(定时从配置管理中心上解析zk服务器地址)、实现服务调用时同机房优先的策略
clientcnxn 网络io
clientcnxn维护客户端与服务器之间的网络连接并进行通信
packet是clientcnxn的内部类,定义:
static class packet {
requestheader requestheader;
replyheader replyheader;
record request;
record response;
bytebuffer bb;
string clientpath;
//server视角下的path,chroot不同
string serverpath;
boolean finished;
asynccallback cb;
object ctx;
watchregistration watchregistration;
public boolean readonly;
watchderegistration watchderegistration;
//并不是packet中的所有字段都进行网络传输,在createbb方法中定义了用于网络传输的bytebuffer bb字段的生成逻辑
//里面只用到了requestheader requestheader,record request,boolean readonly 3个字段
public void createbb() {}
}
clientcnxn的两个核心队列(都是packet队列):
- outgoingqueue:客户端的请求发送队列,存储要发送到服务端的packet集合
- pendingqueue:服务端响应的等待队列,存储已经从客户端发送到服务端但需要等待服务端响应的packer集合
clientcnxnsocket
zk3.4之后clientcnxnsocket从clientcnxn中提取了出来,便于对底层socket进行扩展(如使用netty实现)
通过系统变量配合clientcnxnsocket实现类的全类名:-dzookeeper.clientcnxnsocket=org.apache.zookeeper.clientcnxnsocketnio
clientcnxnsocketnio是clientcnxnsocket的java nio原生实现
会话session
【分布式】zookeeper会话 - leesf - 博客园
会话状态有:connecting connected reconnecting reconnected close
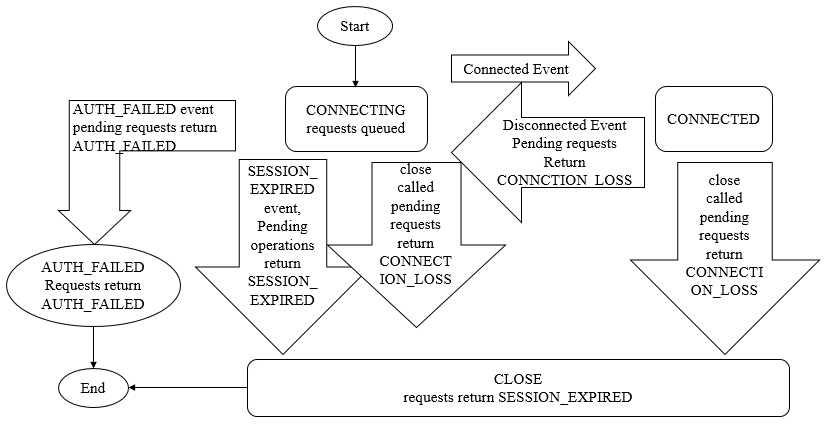
session是zk中的会话实体,代表一个客户端会话,包含以下4个基本属性:
- sessionid 唯一标识一个会话,每次客户端创建新会话时,zk会为其分配一个全局唯一的sessionid
- timeout 会话超时时间,客户端构造zk实例时会传入sessiontimeout指定会话的超时时间,客户端向服务器发送这个超时时间后,服务器会根据自己的超时限定确定会话的超时时间
- ticktime 下次会话超时时间点,这个参数用于会话管理的分桶策略执行。ticktime是一个13位的long型(unix_timestamp)
- isclosing 服务端检测到一个会话失效后会标记其isclosing=true,这样就不再处理来自该会话的新请求了
sessionid的生成原理
代码位于 sessiontrackerimpl#initializenextsession
//最终返回的sessionid:高8位是传入的id,剩下的56位最后16位被置零了,前面的40位是最高位截掉的timestamp(去掉数字1)
public static long initializenextsessionid(long id) {
long nextsid;
// nanotime/10^6 就是 currenttimemillis 13位long型,long型占空间8b,共64位
//如 1657349408123 对应 44 位的二进制是 00011000000111110001101110010000010101111011
//左移24位后再右移8位后的结果:00000000(-8位)1000000111110001101110010000010101111011(16位-)0000000000000000
//注意这个右移8位是无符号右移,防止unixtimes第5位是1带来的负数问题
nextsid = (system.nanotime() / 1000000 << 24) >>> 8;
//添加机器标识 sid 正好补在前面腾出的8位中
nextsid = nextsid | (id << 56);
if (nextsid == ephemeraltype.container_ephemeral_owner) {
++nextsid; // this is an unlikely edge case, but check it just in case
}
return nextsid;
}
左移24位可以将高位的1去掉(unixtimestamp转二进制的44位数字开头总是0001),防止负数(负数右移8位后最高位的1不变),sid不能明确得出
sessiontracker
zk服务端的会话管理器,负责会话的创建、管理和清理,使用3个数据结构管理session:
- sessionsbyid:concurrenthashmap<long, sessionimpl>类型,根据sessionid管理session实体
- sessionswithtimeout:concurrentmap<long, integer> 根据sessionid管理会话的超时时间,定期被持久化到快照文件中
- sessionsets:expiryqueue sessionexpiryqueue 服务于会话管理和超时检查,分桶策略会用到
session管理 - 分桶策略
zk的会话管理主要由sessiontracker负责,其采用了分桶策略:将理论上可以在同一时间点超时的会话放在同一区块中,便于进行会话的隔离处理和同一区块的统一管理。
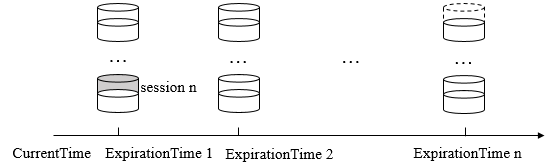
对于一个会话的超时时间理论上就是客户端设置的超时时间之后,即图中的 expirationtime = currenttime + sessiontimeout(客户端进行设置),这样到达这个expirationtime检查各会话是否真的需要置超时状态
但是zk服务端检查各区块的会话是否超时是有周期的,如每隔 expirationinterval 进行检查,这样实际的 expirationtime 是在原数值之后的最近一个周期上进行检查,这样
如对于当前时间为4,,10 超时,检查周期为3,在15的时候才是第一个可能的超时时间。这样 expirationtime_adjust 总是 expirationinterval 的整数倍。这样sessiontracker中的会话超时检查线程就可以在 expirationinterval 的整数倍的时间点上对会话进行批量清理(未及时移走的会话都是要被清理掉的,没有客户端触发会话激活)
会话激活
leader服务器收到客户端的心跳消息ping后:
- 检查改会话是否是isclose
- 如果会话尚未关闭,则激活会话,计算出会话的下一次超时时间点 expirationtime_new
- 根据会话的旧超时时间点 expirationtime_old 定位到会话所在的区块
- 迁移会话,将会话放入 expirationtime_new 对应的新区块中
触发会话激活的两种场景:
- 只要客户端向服务器发送请求(不论读/写)就会触发一次会话激活
- 客户端在sessiontimeout / 3 的时间间隔内没有向服务器发出任何请求,就会主动发起一次ping请求触发会话激活
会话清理的步骤
- 先将该会话的isclosing置为true,这样在会话清理期间再收到客户端的新请求就返回 session_expire,再标记会话状态为已关闭 - close
- 发起会话关闭 请求给 preprequestprocessor处理器进行处理
- 根据sessionid从内存数据库中找到对应的临时节点列表
- 将这些临时节点转换成 节点删除 请求,放入事务变更队列 outstandingchanges 中
- finalrequestprocessor触发内存数据库,删除该会话对应的所有临时节点
- 节点删除后从sessiontracker中移除session(从sessionbyid sessionwithtimeout sessionexpiryqueue中移除对应session的信息)
- 从nioservercnxnfactory中找到会话对应的nioservercnxn进行关闭
重连机制
客户端与服务端网络连接断开时,zk客户端会进行反复的重连
客户端经常看到的两种连接异常是:connection_loss 连接断开,session_expire 会话过期;服务端可能看到的连接异常是session_moved 会话转移
- connection_loss:客户端在发现连接断开时会逐个尝试连接 connectstring 解析出的服务器地址,同时此时收到连接事件 none-disconnected,同时抛出异常 keeperexception$connectionlossexception,应用层应捕获住此异常并等待重连成功(收到none-syncconnected事件)后进行重试
- session_expire:通常发生在connection_loss,客户端重连成功后会话在服务端已过期被清理。应用层此时需要重新创建一个zookeeper实例进行初始化
- session_moved:zookeeper在3.2.0版本后明确提出的概念,客户端 c 向服务端 s1发出的请求r1因网络抖动导致重连到s2,并重试请求r11,但后面r1成功到达s1,导致s1 s2 都执行了相同的请求。针对这一罕见场景,zookeeper提出的处理方案: 在处理客户端请求时检查此会话owner是不是当前服务器,不是的话会抛出 sessionmovedexception 异常,但c1因为已断开与s1的连接,看不到s1上的这个异常。在多个客户端使用相同的sessionid/pass连接不同服务端时才会看到这种异常
zk服务端
zk服务端架构
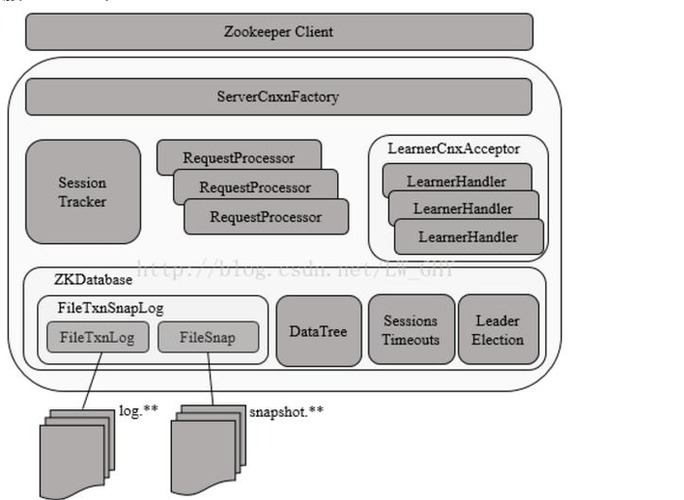
单机版zk服务器的启动流程

预启动
- 不论是单机还是集群模式,zkserver.cmd和zkserver.sh两个脚本中都配置了使用quorumpeermain 作为启动入口类
zoomain="org.apache.zookeeper.server.quorum.quorumpeermain" - 解析配置文件 zoo.cfg
- 在quorumpeermain#initializeandrun方法中创建并启动了文件清理器 datadircleanupmanager,包括对事物日志和快照数据文件的定时清理
- 根据zoo.cfg配置文件的解析判断当前是单机还是集群模式启动,单机模式使用zookeeperservermain启动
- 创建zookeeperserver实例并进行初始化,包括连接器、内存数据库和请求处理器等组件的初始化
初始化
-
创建服务器统计器serverstats,包含下述基本运行时信息:
- packetssent: 从服务启动或重置以来,服务端向客户端发送的响应包次数
- packetsreceived: … 服务端接收到的来自客户端的请求包次数
- maxlatency/minlatency/totallatency: 服务端请求处理的最大延时、最小延时、总延时
- count: 服务端处理的客户端请求总次数
-
创建zk数据管理器filetxnsnaplog:filetxnsnaplog是zk上层服务器和底层数据存储之间的对接层,提供了一些列操作数据文件的接口,包括事务日志文件(txnlog接口)和快照数据文件(snapshot接口)。zk根据zoo.cfg文件中解析出的快照数据目录datadir和事务日志目录datalogdir来创建filetxnsnaplog。
-
设置服务端 ticktime 和 会话超时时间 限制
-
创建并初始化 servercnxnfactory , 通过属性 zookeeper.servercnxnfactory 指定zookeeper使用 java原生nio还是netty框架作为zookeeper服务端网络连接工厂
-
启动servercnxnfactory主线程(执行主逻辑所在的run方法)此时zk的nio服务器已经对外开放了端口,客户端可以访问到2181端口,但此时zk服务器还无法正常处理客户端请求
-
恢复本地数据:zk启动时都会从本地快照文件和事务日志文件中进行数据恢复
-
创建并启动会话管理器sessiontracker,同时会设置 expirationinterval 计算 nextexpirationtime、sessionid ,初始化本地数据结构 sessionswithtimeout(保存每个会话的超时时间)。之后zk就会开始会话管理器的会话超时检查
-
初始化zk的请求处理链,zk服务端对于请求的初始方式是典型的责任链模式,单机版服务器的处理链主要包括:preprequestprocessor -> syncrequestprocessor ->finalrequestprocessor
-
注册jmx服务:zk会将服务器运行时的一些状态信息以jmx的方式暴露出来
-
注册zk服务器实例:此时zk服务器初始化完毕,注册到servercnxnfactory之后就可以对外提供服务了,至此单机版的zk服务器启动完毕
集群版zk服务器的启动过程
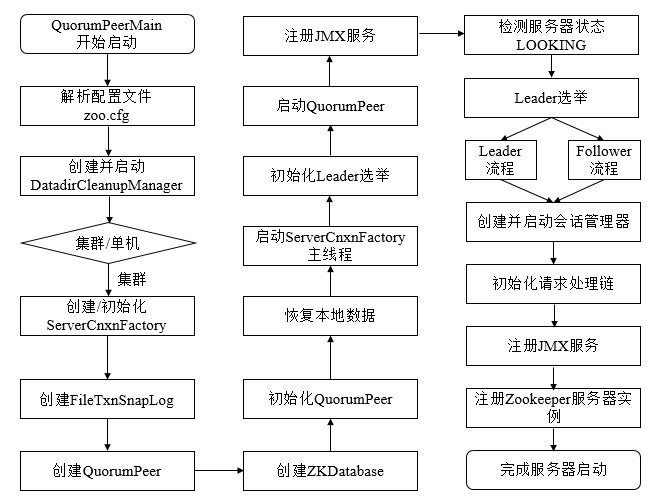
预启动过程与单机版一致
初始化
- 创建并初始化 servercnxnfactory
- 创建zookeeper数据管理器 filetxnsnaplog
- 创建quorumpeer 实例:quorum是集群模式下特有的对象,是zookeeper服务器实例zookeeperserver的托管者。从集群层面看quorumpeer代表了zookeeper集群中的一台机器。在运行期间,quorum会不断检测当前服务器实例的运行状态,同时根据情况发起leader选举
- 创建内存数据库 zkdatabase,管理zookeeper的所有会话记录以及datatree 和事务日志的存储
- 初始化 quorumpeer,将一些核心组件注册到quorumpeer,包括 filetxnsnaplog、servercnxnfactory、zkdatabase,同时配置一些参数,包括服务器地址列表、leader选举算法和会话超时时间限制等
- 恢复本地数据
- 启动 servercnxnfactory 主线程
leader选举
- leader选举初始化阶段:leader选举是集群版启动流程与单机版最大的不同,zk会根据sid(服务器分配的id)、lastloggedzxid(最新的zxid)和当前的服务器epoch(currentepoch)生成一个初始化的投票,初始化过程中每个服务器会为自己投票。 zookeeper会根据zoo.cfg中的配置(electionalg),创建响应的leader选举算法实现,3.4.0之前支持 leaderelection\authfastleaderelection\fastleaderelection 三种算法实现,3.4.0之后只支持fastleaderelection。 在初始化阶段,zookeeper会首先创建leader选举所需的网络io层 quorumcnxmanager,同时启动对leader选举端口的监听,等待集群中的其他服务器创建连接
- 注册jmx服务
- 检测当前服务器状态:quorumpeer不断检测当前服务器的状态做出相应的处理,正常情况下,zk服务器的状态在looking、leading和following/observing之间进行切换,。启动阶段quorumpeer的状态是looking,因此开始进行leader选举
- leader选举:投票选举产生leader服务器,其他机器成为follower或是observer; leader选举算法的原则:集群中的数据越新(根据每个服务器处理过的最大zxid来确定数据是否比较新)越有可能成为leader,zxid相同时sid越大越有可能成为leader。
leader和follower服务器启动期交互过程

- 完成leader选举后,每个服务器根据自己的角色创建相应服务器实例,并开始进入各自角色主流程
- leader服务器启动follower接收器learnercnxacceptor,负责接收所有非leader服务器的连接请求
- learner服务器根据投票选举结果找到当前集群中的leader服务器,与其建立连接
- leader接收来自其他机器的连接创建请求后,创建一个learnerhandler实例。每个learnerhandler实例都对应了一个leader与learner的服务器之间的连接,负责消息、数据同步
- learner向leader发起注册:将含有当前服务器sid和服务器处理的最新zxid信息的learnerinfo发送给leader服务器
- leader接收到注册信息后解析出sid和zxid,根据zxid解析出learner对应的epoch_of_learner_parse,与自己的epoch_of_leader_self进行比较,如果epoch_of_learner_parse>epoch_of_leader_self,则更新 epoch_of_leader_self=epoch_of_learner_parse+1。learnerhandler会进行等待,直到过半的learner向leader注册完毕,同时更新 epoch_of_leader 之后,leader就可以确定当前集群的epoch
- leader将最终的epoch以leaderinfo消息的形式发送给learner,同时等待learner的响应
- follower从leaderinfo消息中解析出epoch和zxid向leader返回ackepoch响应
- leader收到反馈响应ackepoch后与follower进行数据同步
- 如果过半的learner完成了数据同步,就启动leader和learner服务器实例
leader和follower启动
接上面步骤10,启动步骤如下:
- 创建并启动会话管理器
- 初始化zookeeper的请求处理链:根据服务器角色的不同生成不同的请求处理链
- 注册jmx服务
至此,集群版的zk服务器启动完毕
leader选举过程
leader选举是zookeeper中最重要的技术之一,也是保证分布式数据一致性的关键
服务器启动时期的leader选举
以3台机器组成的集群为例:server1首先启动,此时无法完成leader选举
-
server2启动后,与server1进行leader选举,由于是初始化阶段,都会投票给自己,于是server1投票内容 (myid, zxid) 为 (1,0),server2投票 (2,0),各自将这个投票发送给集群中的其他所有机器
-
每个服务器接收来自其他各服务器的投票,并判断投票的有效性:检查是否是本轮投票,是否来自looking状态的服务器
-
收到其他服务器的投票后与自己的投票进行pk,pk规则有:
- 优先检查zxid,zxid较大的服务器优先作为leader
- zxid相同时比较myid,myid较大的作为leader
- 统计投票:每次投票后服务器会统计所有投票,判断是否有过半(> n/2 + 1)的机器接收到相同的投票信息来决定leader服务器 此时3台服务器已有 2台(server1 server2)达成一致,超过半数,将选举出leader - server2
- 改变服务器状态:确定了leader后服务器需要更新自己的状态,follower变更为following,leader会变更为 leading 状态
服务器运行期间的leader选举
leader服务器宕机后进入新一轮的leader选举
- 变更状态:leader宕机后剩下的非observer服务器都会将自己的状态变更为looking,开始进入leader选举流程
- 每个server发出一个投票:生成投票信息(myid, zxid)在第一轮投票中,每个服务器都会投自己,后续的判断过程与服务器启动时期的leader选举相同
leader选举算法 - fastleaderelection
zookeeper提供了3种leader选举算法:leaderelection、udp版本的fastleaderelection、tcp版本的fastleaderelection。
术语解释:
sid - 服务器id,唯一标识zookeeper集群中的机器的数字,与myid一致
zxid - 事务id,用于唯一标识一次服务器状态的变更,某一时刻,集群中的每台服务器的zxid不一定完全一致
vote - 投票
quorum - 过半机器数,quorum = n/2 + 1
zookeeper集群中服务器出现下述两种情况之一就会进入leader选举:集群初始化启动阶段;leader宕机/断网
而一台机器进入leader选举流程时,当前集群也可能会处于两种状态:
- 集群中本来就存在leader,此时试图发起选举会被告知当前服务器的leader信息,直接与leader建立连接并同步状态
- 集群中不存在leader:所有机器进入looking状态进行投票选举leader
【选举案例】集群有5台机器,sid分别为 1 2 3 4 5,zxid分别为 9 9 9 8 8,在某一时刻sid为 1 2 的机器宕机退出,集群此时开始进行leader选举
第一次投票时,由于还无法检测到集群中其他机器的状态信息,每台机器都将投自己,于是sid为 3 4 5的机器分别投票(sid,zxid) (3,9) (4,8) (5,8)
每台机器发出自己的投票后也会收到来自集群中其他机器的投票,每台机器都会对比收到的投票,决定是否替换。假设机器自己的投票是 (self_sid, self_zxid) 接收到的投票是 (vote_sid, vote_zxid),对比的规则是:
- 如果 vote_zxid > self_zxid 则认可当前投票,并再次将更新后的投票发送出去
- 如果 vote_zxid < self_zxid 则不作变更
- 如果 vote_zxid = self_zxid && vote_sid > self_sid,就认可当前接收到的投票,并改为 (vote_sid, vote_zxid) 投递出去
- 如果 vote_zxid = self_zxid && vote_sid < self_sid,则不作变更
sid为 3 4 5的机器对投票进行对比,会统一更新为投票 (3,9) ,此时quorum = 3 >= (5/2 + 1) 超过半数,选举服务器3作为leader
zxid越大的机器,数据也就越新,这样可以保证数据的恢复(更少的数据丢失),所以适合作为leader服务器
leader选举的实现细节
在quorumpeer.serverstate 类中定义了4种服务器状态
public enum serverstate {
looking, // 寻找leader状态,当前集群中没有leader,需要进入leader选举流程
following, // 当前服务器的角色是follower
leading, // 当前服务器角色是leader
observing // 当前服务器角色是 observer
}
org.apache.zookeeper.server.quorum.vote 数据结构的定义
public class vote {
private final int version;
private final long id; // 选举的leader的sid
private final long zxid;
//逻辑时钟,用于判断多个投票是否在同一轮选举周期中。该值在服务端是一个自增序列,每次进入新一轮投票后,都会对该值+1
private final long electionepoch;// 被推举的leader的epoch
private final long peerepoch;//当前服务器的状态
quorumcnxmanager 网络io
每个服务器启动时会启动一个quorumcnxmanager,负责各服务器的底层leader选举过程中的网络通信。
quorumcnxmanager内部维护了一系列按sid分组的消息队列:
recvqueue:消息接收队列,存放从其他服务器接收到的消息
queuesendmap:消息发送队列,保存待发送的消息。此map的key是sid,分别为集群中的每台机器分配了一个单独队列,从而保证各台机器之间的消息发送互不影响
senderworkermap:发送器集合,同样按sid分组,每个senderworker消息发送器对应一台远程zookeeper服务器
lastmessagesent:最近发送过的消息,为每个sid记录最近发送过的消息
选举时集群中的机器是如何建立连接的:
为了能够进行互相投票,zookeeper集群中的机器需要两两建立网络连接。
quorumcnxmanager启动时会创建一个serversocket监听leader选举的通信端口(默认3888),接收其他服务器的tcp连接请求并交给receiveconnection函数来处理。为了避免两台机器之间重复创建tcp连接,zookeeper设计一种建立tcp连接的规则:只允许sid大的服务器主动和其他服务器建立连接,否则断开连接。如果服务器收到tcp连接请求发现比自己的sid值小,会断开这个连接并主动与发起连接的远程服务器建立连接。
建立连接后就会根据外部服务器的sid创建对应的消息发送器 sendworker 和 消息接收器recvworker 并启动
fastleaderelection选举算法的核心
zookeeper对于选票的管理
- sendqueue:选票发送队列,保存待发送的选票
- recvqueue:选票接收队列,保存接收到的外部选票
- fastleaderelection.messenger.workerreceiver:选票接收器,不断从quorumcnxmanager中取出其他服务器发出的选举消息,并转成vote,保存到recvqueueu。如果接收到的外部投票选举轮次小于当前服务器(validvoter方法返回false),直接忽略改选票同时发出自己的投票。如果当前的服务器并不是looking状态(if (self.getpeerstate() == quorumpeer.serverstate.looking)),就将leader信息以投票的形式发出。 选票接收器接收到的消息如果来自observer就会忽略该消息,并将自己当前的投票发送出去
- workersender 选票发送器,会不断从sendqueue队列中获取待发送的选票,并将其传递到底层quorumcnxmanager中
fastleaderelection#lookforleader方法中揭示了选举算法的流程,该方法在服务器状态变成looking时触发
选举算法流程
-
自增选举轮次 logicalclock ++ fastleaderelection中的 atomiclong logicalclock 字段标记当前leader的选举轮次,zookeeper在开始新一轮投票时,会首先对logicalclock进行自增操作
-
初始化选票 初始化选票vote的属性:将自己推荐为leader(id=服务器自身sid,zxid=当前服务器最新zxid,electionepoch=当前服务器的选举轮次,peerepoch=被推举的服务器的选举轮次,state=looking)
-
将初始化好的选票放入sendqueue中,由workersender负责发出
-
服务器不断从 recvqueue 接收外部投票,如果服务器发现无法获取到任何投票会检查与其他服务器的连接,修复连接后重新发出
-
处理外部投票,根据选举轮次判断进行不同的处理:
- 外部投票选举轮次 > 内部轮次:立即更新自己的选举轮次logicalclock,清空所有已收到的投票,使用初始化的投票进行pk以确定是否变更内部投票,最终将内部投票发送出去
- 外部投票选举轮次 < 内部轮次:忽略外部投票,返回步骤4
- 两边一致,绝大多数场景,选举轮次一致时开始进行选票pk
-
选票pk:收到其他服务器有效的外部投票后,进行选票pk,执行fastleaderelection.totalorderpredicate方法,选票pk的目的是确定当前服务器是否需要变更投票,主要从 logicalclock、zxid、sid三个维度判断,符合下述任意一个条件就进行投票变更:
- 外部投票推举的leader服务器的 logicalclock > 内部投票的,需要进行内部投票变更
- logicalclock一致的,对比两者的zxid,外部投票zxid > 内部的,进行内部投票变更
- 两者的zxid一致就对比sid,外部的大就进行投票变更
-
变更投票:如果需要变更投票就使用外部投票的选票信息覆盖内部投票,变更完成后再将这个变更后的内部投票发出去
-
选票归档:无论是否进行了投票变更,外部投票都会存入recvset中进行归档,recvset中按照服务器对应的sid来区分{(1,vote1),(2,vote2),…}
-
统计投票:统计集群中是否已经有过半的机器认可了当前的内部投票,否则返回步骤4
-
更新服务器状态:如果此时已经确定可以终止投票,就更新服务器状态:根据过半机器认可的投票对应的服务器是否是自己确定是否成为leader,并将状态切换为leading/following/observing
上述10个步骤就是fastleaderelection的选举流程,步骤4~9会经过几轮循环,直到leader选举产生。在步骤9如果已经有过半服务器认可了当前选票,此时zookeeper并不会立即进入步骤10,而是等待一段时间(默认200ms)来确定是否有新的更优的投票。
服务器角色介绍
leader
工作内容:事务请求的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各服务器的调度者;
zookeeper使用责任链模式来处理客户端请求

-
preprequestprocessor是leader服务器的请求预处理器,在zk中,将创建删除节点/更新数据/创建会话等会改变服务器状态的请求称为事务请求,对于事务请求,预处理器会进行一系列预处理,如创建请求事务头、事务体、会话检查、acl检查和版本检查
-
proposalrequestprocessor leader的事务投票处理器,也是leader服务器事务处理流程的发起者。
- 对于非事务请求:直接将请求流转到commitprocessor,不作其他处理
- 对于事务请求:除了交给commitprocessor,还会根据对应请求类型创建对应的proposal,并发送给所有follower服务器发起一次集群内的事务投票。proposalrequestprocessor还会将事务请求交给syncrequestprocessor进行事务日志的记录
-
syncrequestprocessor 事务日志处理器,将事务请求记录到事务日志文件中,触发zookeeper进行数据快照
-
ackrequestprocessor 是leader特有的处理器,负责在syncrequestprocessor处理器完成事务日志记录后向proposal的投票收集器发送ack反馈,通知投票收集器当前服务器已完成对该proposal的事务日志记录
-
commitprocessor 事务提交处理器
-
tobecommitprocessor 该处理类中有一个tobeapplied队列(concurrentlinkedqueue tobeapplied)存储被commitprocessor处理过的可被提交的proposal,等待finalrequestprocessor处理完提交的请求后从队列中移除
-
finalrequestprocessor 进行客户端请求返回前的收尾工作:创建客户端请求的响应、将事务应用到内存数据库
learnerhandler:leader服务器会与每一个follower/observer服务器建立一个tcp长链接,同时为每个follower/observer服务器创建learnerhandler。learnerhandler是zk集群中的learner服务器的管理器,负责follower/observer服务器和leader服务器之间的网络通信:数据同步、请求转发、proposal提议的投票。
follower
follower的职责:处理客户端非事务请求,转发事务请求给leader服务器;参与事务请求proposal的投票;参与leader选举投票;
follower不需要负责事务请求的投票处理(所以不需要proposalrequestprocessor),所以其请求处理链简单一些
- followerrequestprocessor 识别出当前请求是否是事务请求,如果是事务请求,follower就会将请求转发给leader服务器,leader服务器收到请求后提交给请求处理器链,按正常事务请求进行处理
- sendackrequestprocessor follower服务器上另一个和leader服务器有差异的请求处理器,与leader服务器上的ackrequestprocessor类似,sendackrequestprocessor同样承担了事务日志记录反馈的角色,在完成事务日志记录后,会向leader服务器发送ack消息表明自身完成了事务日志的记录工作。两者的一个区别是:ackrequestprocessor在leader服务器上,因此ack反馈是一个本地操作,而sendackrequestprocessor在follower上,需要通过ack消息的形式向leader服务器进行反馈。
observer
观察zookeeper集群的最新状态并将这些状态变更同步过来,observer服务器在工作原理上与follower基本一致,对于非事务请求可以进行独立的处理,对于事务请求同样需要转发到leader服。与follower的一大区别是:observer不参与任何形式的投票,包括leader选举和事务请求proposal的投票。
集群内消息通信
zk集群各服务器间消息类型分为4类:数据同步型、服务器初始化型、请求处理型、会话管理型
数据同步消息
learner与leader进行数据同步使用的消息,分为4种(消息类型定义在leader.java中,使用常量数字标记):
- diff, 13 leader发送给learner,通知learner进行diff方式的数据同步
- trunc, 14 leader --> learner 触发learner服务器进行内存数据库的回滚操作
- snap, 15 leader --> learner 通知learner,leader即将与其进行全量数据同步
- uptodate, 12 leader --> learner 通知learner完成了数据同步,可以对外提供服务
服务器初始化型消息
整个集群或某些机器初始化时,leader与learner之间相互通信所使用的消息类型:
- observerinfo,16: observer在启动时发送消息给leader,用于向leader注册observer身份,消息中包含当前observer服务器的sid和已经处理的最新zxid
- followerinfo,11:follower启动时发送包含sid和已处理的最新zxid的注册消息到leader
- leaderinfo,17:上述两种情形下,leader服务器会返回包含最新epoch值的leaderinfo返回给observer或follower
- ackepoch,18:learner在收到leaderinfo消息时会将自己的最新zxid和epoch以ackepoch消息的形式发送给leader
- newleader,10:足够多的follower连接上leader服务器,或是leader服务器完成数据同步后,leader向learner发送的阶段性标识信息,包含当前最新zxid
请求处理型
请求处理过程中leader和learner之间互相通信所使用的消息:
- request,1:learner收到事务请求时需要将请求转发给leader,该请求使用request消息的形式进行转发
- proposal,2:在处理事务请求时,leader服务器会将事务请求以proposal消息的形式创建投票发送给集群中的所有的follower进行事务日志的记录
- ack,3:follower完成事务日志的记录后会以ack消息的形式反馈给leader
- commit,4:leader通知集群中的所有follower,可以进行事务请求的提交了,leader在收到过半follower发来的ack消息后,进入事务请求的最终提交流程——生成commit消息,告知所有follower进行事务请求的提交,这是一个2pc的过程
- inform,8:leader发起事务投票并通知提交事务,只需要proposal和commit消息给follower就可以了,而observer不参与事务投票,无法接收commit消息,但需要知道事务提交的内容,所以zk设计了inform消息发给observer,消息中会携带事务请求的内容
- sync,7:leader通知learner服务器已完成sync操作
会话管理型
zk服务器在进行会话管理过程中,与learner服务器之间通信所使用的消息:
- ping,5:zk客户端随机选择一个服务器进行连接,所以leader服务器无法直接收到所有客户端的心跳检测,所以需要委托learner维护所有客户端的心跳检测。leader定时向learner发送ping消息就是要求learner将一段时间内保持心跳检测的客户端列表同样以ping消息的形式返回给leader,这样leader就能获取到全部客户端的活跃状态并进行会话激活了。
- revalidate,6:客户端发生重连后(可能切换了服务器)新连接的服务器需要向leader发送revalidate消息以确定客户端会话是否已经超时。
客户端请求的处理
会话创建请求
zk服务端对于会话创建的处理,可以分为请求接收、会话创建、预处理、事务处理、事务应用和会话响应。
zookeeper源码分析(3)— 一次会话的创建过程 - 简书— 一次会话的创建过程 - 简书")

请求接收
- io层接收来自客户端的请求,nioservercnxn实例维护每一个客户端连接,负责客户端与服务端通信,并将请求内容从底层网络io中读取出来
- 判断是否是客户端“会话创建”请求:检查当前请求对应的nioservercnxn实体是否已经初始化,未初始化时第一个请求必定是会话创建请求
- 反序列化connectrequest请求,确定是会话创建请求后就可以反序列化得到一个connectrequest请求实体
- 判断是否是readonly客户端,如果zk服务器是以readonly模式启动,所有来自非readonly型客户端的请求将无法处理。所以服务端需要从connectrequest中检查是否是readonly客户端,以此来决定是否接受此“会话创建”请求
- 检查客户端zxid:出现客户端zxid比服务端还大这种反常情形时,服务端不接受此会话创建请求
- 协商sessiontimeout:客户端有自己设置的sessiontimeout值,传到服务端后,服务端要根据自身配置进行检查限定,通常的规则是 2 * tickettime ~ 20 * tickertime 之间
- 判断是否需要重新创建会话:解析客户端传入的sessionid进行判断
会话创建
- 为客户端生成sessionid:每个zk服务器启动时都会初始化一个会话管理器sessiontracker,同时初始化一个基准sessionid,这个基准sessionid的生成需要保证后续客户端在此基础上不断+1能够全局唯一。sessionid生成算法见客户端介绍:会话session > sesssionid的生成原理。
- 注册会话:将会话信息保存到sessiontracker的本地字段中:concurrenthashmap<long, sessionimpl> sessionsbyid、concurrentmap<long, integer> sessionswithtimeout
- 会话激活:服务端根据配置的tickettime和会话超时时间比对计算下一次会话超时时间(使用了分桶策略)sessionswithtimeout
- 生成会话密码:随机数,生成代码见 zookeeperserver#generatepasswd
预处理
- preprequestprocessor处理请求(责任链模式)
- 创建请求事务头:对于事务请求,zk会为其创建请求事务头,后续请求处理器都是基于该请求头标识当前请求是否是事务请求,请求事务头包含:clientid(唯一标识请求所属客户端)cxid(客户端操作序列号)zxid(事务请求对应的zxid)time(服务端开始处理事务请求的时间)type(事务请求的类型:zoodefs.opcode.create、delete、setdata和createsession等)
- 创建请求事务体createsessiontxn
- 注册与激活会话:额外处理非leader转发的会话创建请求
事务处理

-
proposalrequestprocessor处理请求:preprequestprocessor将请求交给下一级处理器,提案proposal是zk中对因事务请求展开的投票流程中的事务操作的包装,该处理器就是处理提案的,处理流程有:
-
sync流程:syncrequestprocessor处理器记录事务日志。完成事务日志记录后,每个follower都会向leader发送ack消息,表明自身完成了事务日志的记录,以便leader服务器统计每个事务请求的投票情况
-
proposal流程:zk的实现中,每个事务请求都需要集群中过半机器投票认可才能真正应用到zk的内存数据库中,这个投票与统计的过程就叫 proposal流程:
- 发起投票:对于事务请求,leader服务器会发起一轮事务投票,发起事务投票之前会检查服务端zxid是否可用,如果不可用会抛出xidrolloverexception
- 生成提议proposal:如果服务端zxid可用,就可以开始事务投票了,zk会将之前创建的请求头和事务体,以及zxid和请求本身序列化到proposal对象中
- 广播提议:leader服务器会以zxid作为key,将提议放入投票箱concurrentmap<long, proposal> outstandingproposals中,同时将该提议广播给所有follower服务器
- 收集投票:follower服务器接收到leader发来的提议后,会进入sync流程进行事务日志的记录,执行完后发送ack消息给leader,leader根据ack消息统计proposal的投票情况。当过半机器通过时,就进入proposal的commit阶段
- commit proposal前将请求放入 tobeapplied 队列中
- 广播commit消息:leader会向observer广播包含proposal内容的inform消息,而对于follower服务器则需只发送zxid(上文有介绍)
-
commit流程:
- 将请求交给commitprocessor.java处理器,放入 linkedblockingqueue queuedrequests 中,独立线程会取出处理
- 标记toppending:如果是事务请求(write类型),就会将toppending标记为当前请求,用于确保事务请求的顺序性,便于commitprocessor检测当前集群中是否正在进行事务请求的投票
- 等待proposal投票:commit流程处理时,leader根据当前事务请求生成proposal广播给所有follower,此时commit流程需要等待
- 投票通过,提议获得过半机器认可,zk会将请求放入committedrequests队列中,同时唤醒commit流程
- 提交请求:将请求放入toprocess队列中,交给finalrequestprocessor处理
-
事务应用
- finalrequestprocessor检查outstandingchanges队列中请求的有效性,如果队列中的请求落后于当前正在处理的请求,则从队列中移除
- 之前的请求处理逻辑中仅仅是将事务请求记录到了事务日志中,内存数据库中的状态尚未变更。因此需要将事务变更应用到内存数据库中。对于会话创建这种“事务请求”,只需向sessiontracker进行会话注册
- 完成内容应用后将事务请求放入队列 commitproposal,这个队列保存最近被提交的事务请求,以便集群间机器进行数据的快速同步

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
用于确保事务请求的顺序性,便于commitprocessor检测当前集群中是否正在进行事务请求的投票
+ 等待proposal投票:commit流程处理时,leader根据当前事务请求生成proposal广播给所有follower,此时commit流程需要等待
+ 投票通过,提议获得过半机器认可,zk会将请求放入committedrequests队列中,同时唤醒commit流程
+ 提交请求:将请求放入toprocess队列中,交给finalrequestprocessor处理
事务应用
- finalrequestprocessor检查outstandingchanges队列中请求的有效性,如果队列中的请求落后于当前正在处理的请求,则从队列中移除
- 之前的请求处理逻辑中仅仅是将事务请求记录到了事务日志中,内存数据库中的状态尚未变更。因此需要将事务变更应用到内存数据库中。对于会话创建这种“事务请求”,只需向sessiontracker进行会话注册
- 完成内容应用后将事务请求放入队列 commitproposal,这个队列保存最近被提交的事务请求,以便集群间机器进行数据的快速同步
[外链图片转存中…(img-ybqd3big-1715341903538)]
[外链图片转存中…(img-p0dh29hs-1715341903539)]
[外链图片转存中…(img-7ar2803b-1715341903539)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新



发表评论