

spark sql
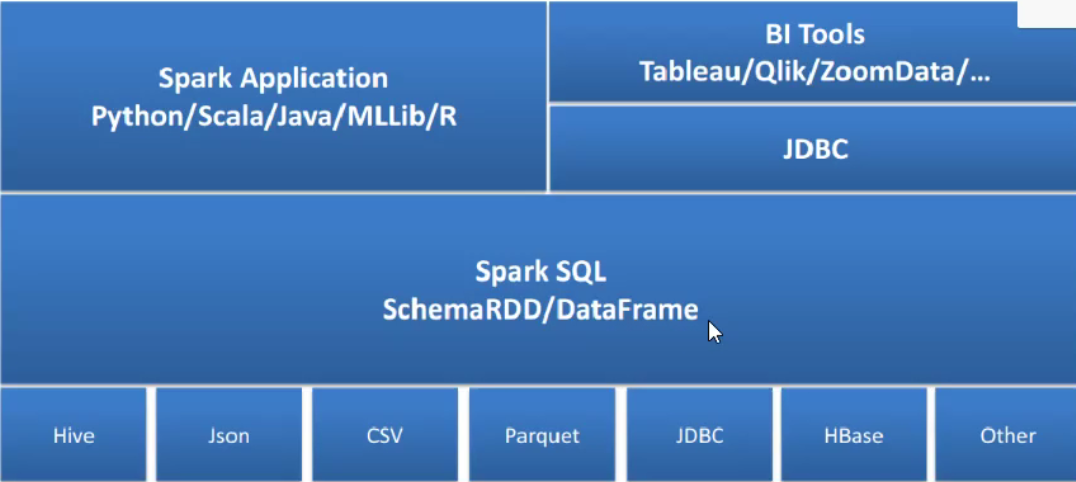
一、spark sql架构
-
能够直接访问现存的hive数据
-
提供jdbc/odbc接口供第三方工具借助spark进行数据处理
-
提供更高层级的接口方便处理数据
-
支持多种操作方式:sql、api编程
- api编程:spark sql基于sql开发了一套sql语句的算子,名称和标准的sql语句相似
-
支持parquet、csv、json、rdbms、hive、hbase等多种外部数据源。(掌握多种数据读取方式)
-
spark sql核心:是rdd+schema(算子+表结构),为了更方便我们操作,会将rdd+schema发给dataframe
-
数据回灌:用于将处理和清洗后的数据回写到hive中,以供后续分析和使用。
-
bi tools:主要用于数据呈现。
-
spark application:开发人员使用spark application编写数据处理和分析逻辑,这些应用可以用不同的编程语言编写,比如python、scala、java等。
二、spark sql运行原理
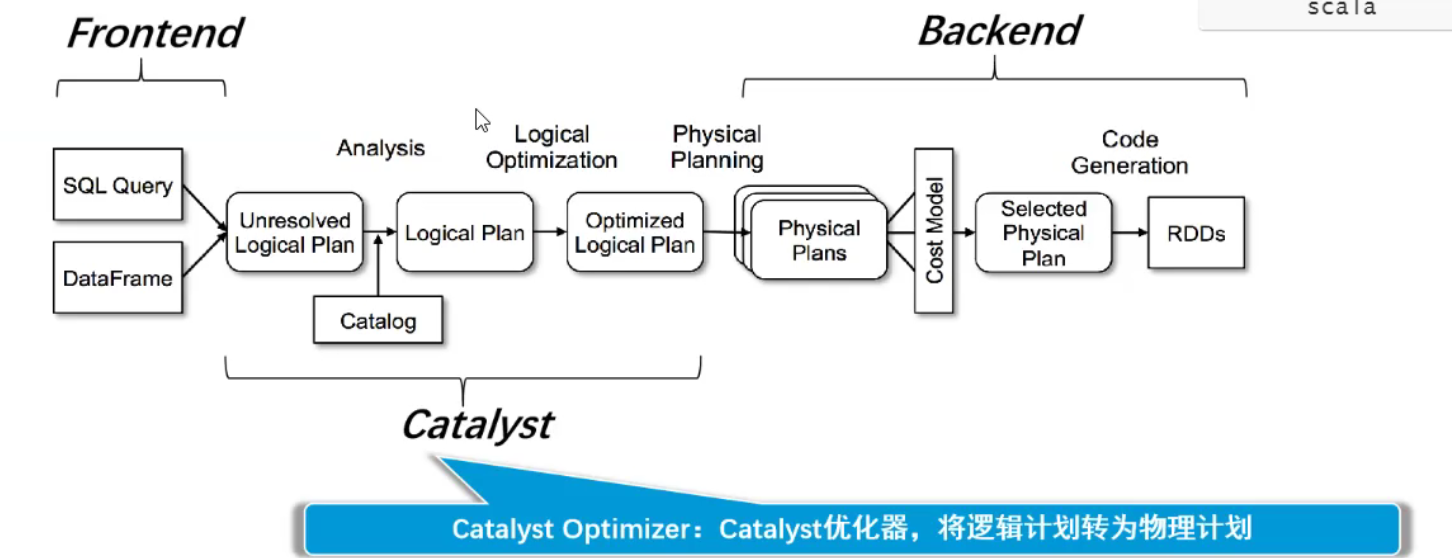
- catalyst优化器的运行流程:
- frontend(前端)
- 输入:用户可以通过sql查询或dataframe api来输入数据处理逻辑。
- unresolved logical plan(未解析的逻辑计划):输入的sql查询或dataframe转换操作会首先被转换为一个未解析的逻辑计划,这个计划包含了用户请求的所有操作,但其中的表名和列名等可能尚未解析。
- catalyst optimizer(catalyst优化器) catalyst优化器是spark sql的核心组件,它负责将逻辑计划转换为物理执行计划,并进行优化。catalyst优化器包括以下几个阶段:
- analysis(分析):将未解析的逻辑计划中的表名和列名解析为具体的元数据,这一步依赖于catalog(元数据存储)。输出是一个解析后的逻辑计划。
- logical optimization(逻辑优化):对解析后的逻辑计划进行各种优化,如投影剪切、过滤下推等。优化后的逻辑计划更加高效。
- physical planning(物理计划):将优化后的逻辑计划转换为一个或多个物理执行计划。每个物理计划都代表了一种可能的执行方式。
- cost model(成本模型):评估不同物理计划的执行成本,选择代价最低的物理计划作为最终的物理计划。
- backend(后端)
- code generation(代码生成):将选择的物理计划转换为可以在spark上执行的rdd操作。这一步会生成实际的执行代码。
- rdds:最终生成的rdd操作被执行,以完成用户请求的数据处理任务。
- 一个sql查询在spark sql中的优化流程
select name from(
select id, name from people
) p
where p.id = 1
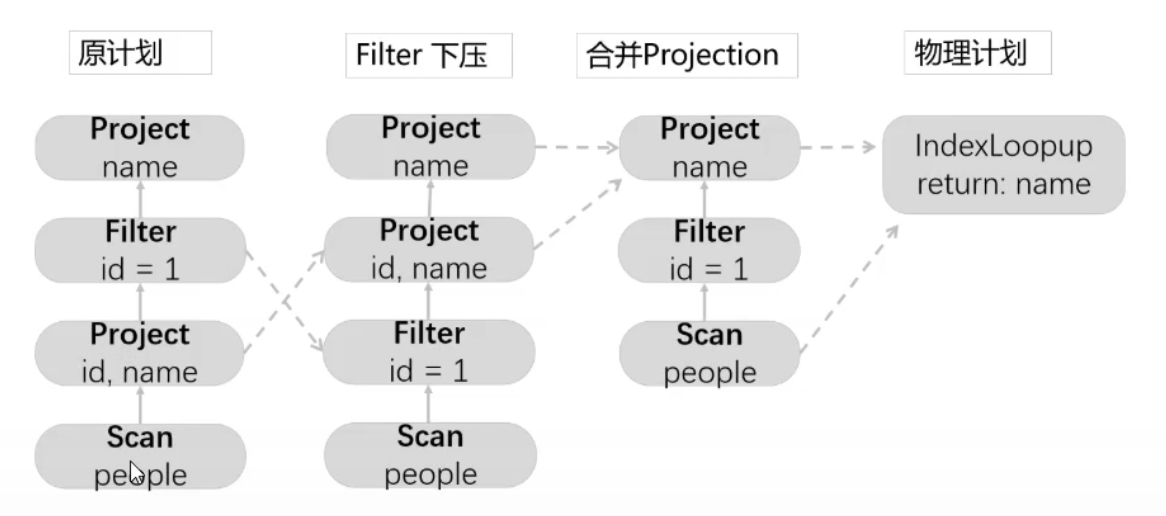
- filter下压:将filter操作推到更靠近数据源的位置,以减少不必要的数据处理。
- 合并projection:减少不必要的列选择
- indexlookup return:name:如果存在索引,可以直接通过索引查找并返回
name列
三、spark sql api
-
sparkcontext:spark应用的主入口,代表了与spark集群的连接。
-
sqlcontext:spark sql的编程入口,使用sqlcontext可以运行sql查询、加载数据源和创建dataframe。
-
hivecontext:sqlcontext的一个子集,可以执行hiveql查询,并且可以访问hive元数据和udf。
-
sparksession:spark2.0后推荐使用,合并了sqlcontext和hivecontext,提供了与spark所有功能交互的单一入口点。
创建一个sparksession就包含了一个sparkcontext。
-
若同时需要创建sparkcontext和sparksession,必须先创建sparkcontext再创建sparksession。否则,会抛出如下异常,提示重复创建sparkcontext:
详细解释
创建sparksession的代码
val conf: sparkconf = new sparkconf()
.setmaster("local[4]")
.setappname("sparksql")
def main(args: array[string]): unit = {
sparksession.builder()
.config(conf)
.getorcreate()
}
优化:减少创建代码,sparksessionbuilder工具类
package com.ybg
import org.apache.spark.{sparkconf, sparkcontext}
import org.apache.spark.sql.sparksession
// 封装sparksession的创建方法
class sparksessionbuilder(master:string,appname:string){
lazy val config:sparkconf = {
new sparkconf()
.setmaster(master)
.setappname(appname)
}
lazy val spark:sparksession = {
sparksession.builder()
.config(config)
.getorcreate()
}
lazy val sc:sparkcontext = {
spark.sparkcontext
}
def stop(): unit = {
if (null != spark) {
spark.stop()
}
}
}
object sparksessionbuilder {
def apply(master: string, appname: string): sparksessionbuilder = new sparksessionbuilder(master, appname)
}
四、spark sql依赖
pom.xml
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceencoding>utf-8</project.build.sourceencoding>
<spark.version>3.1.2</spark.version>
<spark.scala.version>2.12</spark.scala.version>
<hadoop.version>3.1.3</hadoop.version>
<mysql.version>8.0.33</mysql.version>
<hive.version>3.1.2</hive.version>
<hbase.version>2.3.5</hbase.version>
<jackson.version>2.10.0</jackson.version>
</properties>
<dependencies>
<!-- spark-core -->
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-core_${spark.scala.version}</artifactid>
<version>${spark.version}</version>
</dependency>
<!-- spark-sql -->
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-sql_${spark.scala.version}</artifactid>
<version>${spark.version}</version>
</dependency>
若出现如下异常:
caused by: com.fasterxml.jackson.databind.jsonmappingexception:
scala module 2.10.0 requires jackson databind version >= 2.10.0 and < 2.11.0
追加如下依赖:
-->
<!-- jackson-databind -->
<dependency>
<groupid>com.fasterxml.jackson.core</groupid>
<artifactid>jackson-databind</artifactid>
<version>2.10.0</version>
</dependency>
<!-- mysql -->
<dependency>
<groupid>com.mysql</groupid>
<artifactid>mysql-connector-j</artifactid>
<version>${mysql.version}</version>
</dependency>
</dependencies>
log4j.properties
log4j.properties应该放在资源包下。
log4j.rootlogger=error, stdout, logfile # 设置可显示的信息等级
log4j.appender.stdout=org.apache.log4j.consoleappender
log4j.appender.stdout.layout=org.apache.log4j.patternlayout
log4j.appender.stdout.layout.conversionpattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.fileappender
log4j.appender.logfile.file=log/spark_first.log
log4j.appender.logfile.layout=org.apache.log4j.patternlayout
log4j.appender.logfile.layout.conversionpattern=%d %p [%c] - %m%n
五、spark sql数据集
1、dataset
- 简介:
- 从spark 1.6开始引入的新的抽象。
- 是特定领域对象中的强类型集合。
- 可以使用函数式编程或sql查询进行操作。
- 等于rdd + schema。
2、dataframe
- 简介:
- dataframe是特殊的dataset:
dataframe=dataset[row],行对象的集合,每一行就是一个行对象。 - 类似于传统数据的二维表格。
- dataframe是特殊的dataset:
- 特性:
- schema:在rdd基础上增加了schema,描述数据结构信息
- 嵌套数据类型:支持
struct,map,array等嵌套数据类型。 - api:提供类似sql的操作接口。
详细解释
创建dataset的代码
val spark: sparksession = sparksession.builder().config(conf).getorcreate()
// 提供了一组隐式转换,这些转换允许将scala的本地集合类型(如seq、array、list等)转换为spark的dataset。
import spark.implicits._
val dsphone: dataset[product] = spark.createdataset(seq(
product(1, "huawei mate60", 5888.0f),
product(2, "iphone", 5666.0f),
product(3, "oppo", 1888.0f)
))
dsphone.printschema()
/**
* root
* |-- id: integer (nullable = false)
* |-- name: string (nullable = true)
* |-- price: float (nullable = false)
*/
创建dataframe的代码
-
读取csv文件
-
对于csv文件,在构建dataframe之前,必须要先创建一个schema,再根据文件类型分不同情况进行导入。(读取json文件或者数据库表都并不需要)
-
注意:必须要
import spark.implicits._,导入隐式类,才能够识别一些隐式转换,否则会报错。 -
csv文件在创建dataframe时,可以选择尽量模仿hive中的opencsvserde的
-
val spark: sparksession = sparksession.builder()
.config(conf)
.getorcreate()
import spark.implicits._
val schema: structtype = structtype(
seq(
structfield("user_id", longtype),
structfield("locale", stringtype),
structfield("birthyear", integertype),
structfield("gender", stringtype),
structfield("joinedat", stringtype),
structfield("location", stringtype),
structfield("timezone", stringtype)
)
)
val frmusers: dataframe = spark.read
.schema(schema)
.option("separator", ",") // 指定文件分割符
.option("header", "true") // 指定csv文件包含表头
.option("quotechar", "\"")
.option("escapechar", "\\")
.csv("c:\\users\\lenovo\\desktop\\users.csv")
.repartition(4)
.cache()
- 读取json文件
val frmusers2: dataframe = spark.read.json("hdfs://single01:9000/spark/cha02/users.json")
frmusers2.show()
- 读取数据库表
val url = "jdbc:mysql://single01:3306/test_db_for_bigdata" // 数据库连接地址
val mysql = new properties()
mysql.setproperty("driver", "com.mysql.cj.jdbc.driver")
mysql.setproperty("user", "root")
mysql.setproperty("password", "123456")
spark
.read
.jdbc(url,"test_table1_for_hbase_import",mysql) // (url,tablename,连接属性)
.show(100)
六、spark_sql的两种编码方式
val spark: sparksession = sparksession.builder()
.config(conf)
.getorcreate()
import spark.implicits._
val schema: structtype = structtype(
seq(
structfield("user_id", longtype),
structfield("locale", stringtype),
structfield("birthyear", integertype),
structfield("gender", stringtype),
structfield("joinedat", stringtype),
structfield("location", stringtype),
structfield("timezone", stringtype)
)
)
val frmusers: dataframe = spark.read
.schema(schema)
.option("separator", ",") // 指定文件分割符
.option("header", "true") // 指定csv文件包含表头
.option("quotechar", "\"")
.option("escapechar", "\\")
.csv("c:\\users\\lenovo\\desktop\\users.csv")
.repartition(4)
.cache()
此处已经创建好了dataframe
1. 面向标准sql语句(偷懒用)
frmusers.registertemptable("user_info") // 此方法已过期
spark.sql(
"""
|select * from user_info
|where gender='female'
|""".stripmargin)
.show(10)
2. 使用spark中的sql算子(更规范)
frmusers
.where($"birthyear">1990)
.groupby($"locale")
.agg(
count($"locale").as("locale_count"),
round(avg($"birthyear"),2).as("avg_birth_year")
)
.where($"locale_count">=10 and $"avg_birth_year">=1993)
.orderby($"locale_count".desc)
.select(
$"locale", $"locale_count", $"avg_birth_year",
dense_rank()
.over(win)
.as("rnk_by_locale_count"),
lag($"locale_count",1)
.over(win)
.as("last_locale_count")
)
.show(10)
七、常用算子
1.基本sql模板
select
col,cols*,agg*
where
conditioncols
group by
col,cols*
having
condition
order by
col asc|desc
limit
n
2.select
select语句在代码的开头可以不写,因为有后续的类似where和group by语句已经对列进行了操作,指明了列名。如果后续有select语句,则优先按照后面的select语句进行。
frmusers.select(
$"locale",$"locale_count"
)
3.agg
.agg(
count($"locale").as("locale_count"),
round(avg($"birthyear"),2).as("avg_birth_year")
)
4.窗口函数
- over子句
注意:over子句中的分区信息是可以被重用的
val win: windowspec = window.partitionby($"gender").orderby($"locale_count".desc)
frmusers
...
.select(
dense_rank()
.over(win)
.as("rnk_by_locale_count")
)
5.show
show(n)表示显示符合条件的至多n条数据。(不是取前n条再提取出其中符合条件的数据)
frmusers
...
.show(10)
6.条件筛选 where
newcol:column = $"cus_state".isnull
newcol:column = $"cus_state".isnan
newcol:column = $"cus_state".isnotnull
newcol:column = $"cus_state".gt(10) <=> $"cus_state">10
newcol:column = $"cus_state".geq(10) <=> $"cus_state">=10
newcol:column = $"cus_state".lt(10) <=> $"cus_state"<10
newcol:column = $"cus_state".leq(10) <=> $"cus_state"<=10
newcol:column = $"cus_state".eq(10) <=> $"cus_state"===10
newcol:column = $"cus_state".ne(10) <=> $"cus_state"=!=10
newcol:column = $"cus_state".between(10,20)
newcol:column = $"cus_state".like("张%")
newcol:column = $"cus_state".rlike("\\d+")
newcol:column = $"cus_state".isin(list:any*)
newcol:column = $"cus_state".isincollection(values:itrable[_])
多条件:
newcol:column = colone and coltwo
newcol:column = colone or coltwo
在spark sql中,不存在having子句,where子句的实际作用根据相对于分组语句的前后决定。
7.分组
// 多重分组
/**
rollup的效果:
select birthyear,count(*) from user group by birthyear
union all
select gender,birthyear,count(*) from user group by gender,birthyear
存在"字段不对应"的情况:
空缺的字段会自动补全为null
*/
frmusers
.rollup("gender", "birthyear")
.count()
.show(100)
// 为了方便查找到每个数据行所对应的分组方式
spark.sql(
"""
|select grouping__id,gender,birthyear,count(8) as cnt from user_info
|group by gender,birthday,
|grouping sets(gender,birthday,(gender,birthyear))
|""".stripmargin)
.show(100)
// 这里的group by子句定义了分组的列,到grouping sets明确指定了分组的组合
// 因而,在数仓设计的过程中,我们能够对不同分组依据下的不同数据依据grouping__id做分区。
-
rollup和cube的区别假设有三列:
1,2,3,使用cube(1, 2, 3),会生成以下组合:group by ()(不分组,整体聚合)group by (1)group by (2)group by (3)group by (1, 2)group by (1, 3)group by (2, 3)group by (1, 2, 3)
rollup生成的分组组合是层级的,它从最详细的分组开始,一步步减少分组的列,直到整体聚合。假设有三列:
1,2,3,使用rollup(1, 2, 3),会生成以下组合:group by (1, 2, 3)(最详细的分组)group by (1, 2)group by (1)group by ()(不分组,整体聚合)
8.关联查询
val frmclass: dataframe = spark.createdataframe(
seq(
class(1, "yb12211"),
class(2, "yb12309"),
class(3, "yb12401")
)
)
val frmstu: dataframe = spark.createdataframe(
seq(
student("henry", 1),
student("ariel", 2),
student("jack", 1),
student("rose", 4),
student("jerry", 2),
student("mary", 1)
)
)
// 1.笛卡尔积(默认情况下)
frmstu.as("s")
.join(frmclass.as("c"))
.show(100)
/**
+-----+-------+-------+---------+
| name|classid|classid|classname|
+-----+-------+-------+---------+
|henry| 1 | 1 | yb12211|
|henry| 1 | 2 | yb12309|
|henry| 1 | 3 | yb12401|
|ariel| 2 | 1 | yb12211|
|ariel| 2 | 2 | yb12309|
|ariel| 2 | 3 | yb12401|
| jack| 1 | 1 | yb12211|
| jack| 1 | 2 | yb12309|
| jack| 1 | 3 | yb12401|
| rose| 4 | 1 | yb12211|
| rose| 4 | 2 | yb12309|
| rose| 4 | 3 | yb12401|
|jerry| 2 | 1 | yb12211|
|jerry| 2 | 2 | yb12309|
|jerry| 2 | 3 | yb12401|
| mary| 1 | 1 | yb12211|
| mary| 1 | 2 | yb12309|
| mary| 1 | 3 | yb12401|
+-----+-------+-------+---------+
*/
// 2.内连接
frmstu.as("s")
.join(frmclass.as("c"), $"s.classid" === $"c.classid","inner")
.show(100)
/**
+-----+-------+-------+---------+
| name|classid|classid|classname|
+-----+-------+-------+---------+
|henry| 1 | 1 | yb12211|
|ariel| 2 | 2 | yb12309|
| jack| 1 | 1 | yb12211|
|jerry| 2 | 2 | yb12309|
| mary| 1 | 1 | yb12211|
+-----+-------+-------+---------+
*/
// 启用using:使用seq("column")代表关联字段
frmstu.as("s")
.join(frmclass.as("c"), seq("classid"),"right")
.show(100)
// 3.外连接
frmstu.as("s")
.join(frmclass.as("c"), $"s.classid" === $"c.classid","outer") // left | right | outer
.show(100)
/**
+-----+-------+-------+---------+
| name|classid|classid|classname|
+-----+-------+-------+---------+
|henry| 1 | 1 | yb12211|
| jack| 1 | 1 | yb12211|
| mary| 1 | 1 | yb12211|
| null| null | 3 | yb12401|
| rose| 4 | null | null|
|ariel| 2 | 2 | yb12309|
|jerry| 2 | 2 | yb12309|
+-----+-------+-------+---------+
*/
// 4.反连接:返回左数据集中所有没有关联字段匹配记录的左数据集的行
frmstu.as("s")
.join(frmclass.as("c"), $"s.classid" === $"c.classid","anti")
.show(100)
/**
+----+-------+
|name|classid|
+----+-------+
|rose| 4 |
+----+-------+
*/
// 5.半连接:返回左数据集中所有有关联字段匹配记录的左数据集的行
frmstu.as("s")
.join(frmclass.as("c"), $"s.classid" === $"c.classid","semi")
.show(100)
/**
+-----+-------+
| name|classid|
+-----+-------+
|henry| 1 |
|ariel| 2 |
| jack| 1 |
|jerry| 2 |
| mary| 1 |
+-----+-------+
*/
9.排序
frmstu.orderby(cols:column*)
10.数据截取
frmstu.tail(n:int)
frmstu.take(n:int)
八.sql函数
常用函数
$"name" = col("name") // 取列值
as("alias_name") // 别名
as(alias:seq[string]) // 多个别名
when(condition,v1) // 条件
.when(...)
.otherwise(vn)
lit(v) // 常量列
withcolumn(colname:string,col:column) // 扩展列(通常用于使用窗口函数做扩展列)
cast(datatype) // 类型转换
常用函数案例
spark.createdataframe(seq(
test(1,array("money","freedom"),map("java"->85,"c++"->92)),
test(2,array("beauty","writing"),map("math"->91,"english"->88)),
test(3,array("movie","draw"),map("sql"->100,"llm"->77))
))
// 多个explode不能写在一个select中
.select($"id",explode($"hobbies").as("hobby"),$"scores")
.select($"id",$"hobby",explode($"scores").as(seq("course","score")))
.select($"id",$"hobby",$"course",$"score".cast("integer"))
.withcolumn("score_rank",
when($"score">=90,lit("a")))
when($"score">=80,lit("b"))
when($"score">=70,lit("c"))
when($"score">=60,lit("d"))
.otherwise(lit("e"))
集合函数
array
size(collectcol:column) // 计算数组大小
array(cols:column*) // 一行中的多列转为单列数组类型
array_sort(arraycol:column) // 对数组列中的元素进行排序
array_contains(arraycol:column,value:any) // 依次判断数组列的各个元素是否含有特定值
array_distinct(arraycol:column) // 对数组列的各个元素进行去重并返回去重后的结果
array_join(arraycol:column,sep:string,nullreplacement:string) // 对数组列的各个元素进行拼接
array_except(arraycol:column)
array_intersect(arraycol:column)
array_union(arraycol:column)
map
map_keys(mapcol:column)
map_values(mapcol:column)
map_entries(mapcol:column)
集合函数案例
data.select($"id",size($"hobbies").as("hobbies_cnt")).show()
data.select($"id",array_sort($"hobbies").as("hobbies_sort")).show()
data.select($"id",array_contains($"hobbies","money")).show()
data.select($"id",array_distinct($"hobbies").as("unique_hobbies")).show()
data.select($"id",array_join($"hobbies",",","unknown value").as("union_hobby")).show()
data.withcolumn("next_hobbies",lead($"hobbies",1) over(window.orderby("id")))
.where($"next_hobbies".isnotnull) // 提前做条件筛选
.select(
array_intersect($"hobbies",$"next_hobbies").as("intersect_hobbies")
)
.show(10)
data.select($"id",
map_keys($"scores").as("course_list"),
map_values($"scores").as("scores"),
map_entries($"scores").as("course_score_list")
).show()
// 考java的学生人数有多少
val num: long = data.select(
array_contains(map_keys($"scores"), "java").as("isjava")
).filter($"isjava").count()
字符串函数
// 提取
// 1、提取 json
json_tuple(jsoncol:column, fields:string*) // $"jsonstring" => field1,field2 获取单层json字段
get_json_object(jsoncol:column, path:string) // $"jsonstring" => $.field1[.field2] 获取多层嵌套json字段
// 2、正则分组
regexp_extract(col:column, pattern:string, groupid:int)
// 3、分裂与截取
split(col:column,pattern:string)
substring(col:column,pos:int,len:int)
substring_index(col:column,sep:string,groupid:int)
// groupid +n 从左向右前n个
// groupid -n 从右向左前n个
// 第n个 substring_index(substring_index(col,sep,+n),sep,-1)
// 4、子字符串在字段中的位置(表示子字符串的第一个字符在字符串中的索引位置)
locate(substr:string,col:column) // 有则>0,否则=0,
instr(col:column,substr:string)
// 5、字符串拼接
concat(cols:column*)
concat_ws(sep:string,cols:column*)
// 6、内容长度
length(col:column) // 字符长度
// 字节长度,未提供算子,需要通过 spark.sql(""" select octet_length(...)""") 实现
// 7、定长填充
lpad(col:column,len:int,pad:string)
rpad(col:column,len:int,pad:string)
// 8、清除两端空格
ltrim(col:column)
rtrim(col:column)
trim(col:column)
// 9、大小写转换
initcap(col:column) // 每个单词首字母大写
upper(col:column) // 全大写
lower(col:column) // 全小写
hash(col:column) // 去哈希值
regexp_replace(col:column,pattern:string,replace:string) // 正则替换
translate(col:column,from:string,to:string) // 按字母转换
reverse(col:column) // 翻转
// 10、转码
encode(col:column, charset:string)
decode(col:column, charset:string)
// 11、非对称加密
sha1(col:column)
md5(col:column)
字符串函数案例
val frm: dataframe = spark
.createdataframe(seq(
json(1, """{"name":"henry","age":22,"hobbies":["beauty","money","power"],"address":{"province":"jiangsu","city":"nanjing"}}"""),
json(2, """{"name":"jack","age":23,"hobbies":["beauty","power"],"address":{"province":"jiangsu","city":"wuxi"}}"""),
json(3, """{"name":"tom","age":24,"hobbies":["beauty","money"],"address":{"province":"jiangsu","city":"yancheng"}}""")
))
frm.select($"id",
json_tuple($"json","name","age","hobbies").as(seq("name","age","hobbies")),
get_json_object($"json","$.address.province").as("province"),
get_json_object($"json","$.address.city").as("city")
).show(10)
// 通过正则提取获取特定的日志信息
val regex_line = "(.*?) (info|warn|error) (.*?):(.*)"
val regex_log = "^\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}:\\d{2},\\d{3} (info|warn|error) .*"
val frm: dataframe = spark
.read
.text("spark-warehouse/datanode.log")
.todf("line")
frm
.where($"line".rlike(regex_log))
.select(
regexp_extract($"line",regex_line,1).as("log_in_time"),
regexp_extract($"line",regex_line,2).as("log_type"),
regexp_extract($"line",regex_line,3).as("log_full_pack"),
regexp_extract($"line",regex_line,4).as("log_detail")
)
// 获取错误日志信息中错误类别及其所占数量
.where($"log_type".equalto("error"))
.groupby($"log_detail")
.count()
.show(100)
spark自定义函数流程
自定义函数流程:定义-注册-调用






发表评论