
目录
前言
机器学习中的聚类分析是一种无监督学习方法,旨在将数据点划分为相似的组或簇,使得同一组内的数据点彼此相似,而不同组之间的数据点则相对较不相似。聚类分析可以帮助我们理解数据的内在结构,发现数据中隐藏的模式,并将数据进行自然的分组,从而为进一步分析或决策提供基础。

正文
01-聚类分析简介
在机器学习中,常见的聚类算法包括:
k-means 聚类:将数据点分成预先指定的 k 个簇,每个簇具有最小化簇内平方误差的中心点。k-means 是一种迭代算法,通过不断更新簇中心点来优化聚类结果。
层次聚类:逐步将数据点合并到不断增长的聚类中,形成层次结构。层次聚类可分为凝聚式和分裂式两种方法,分别是自底向上和自顶向下的聚类过程。
谱聚类:基于图论中的谱分析方法,通过构建数据的相似度矩阵,并对其进行特征分解来进行聚类。谱聚类通常适用于数据集中存在非凸形状的聚类结构或者复杂的聚类结构。
均值移位聚类:基于核密度估计的非参数聚类方法,通过寻找数据空间中密度最大化的区域来发现聚类中心。
dbscan:基于密度的聚类算法,将高密度区域视为聚类,并通过将低密度区域视为噪声点来实现聚类。
亲密传播聚类:基于图论的聚类方法,通过在数据点之间传播消息来发现聚类中心,并将数据点分配到这些中心。
这些算法各有特点,适用于不同类型的数据和聚类问题。在选择聚类算法时,需要考虑数据的特征、聚类结构的性质以及算法的计算复杂度等因素。下面从一些实例中分析应用过程:
02-绘制基于层次聚类的树状图
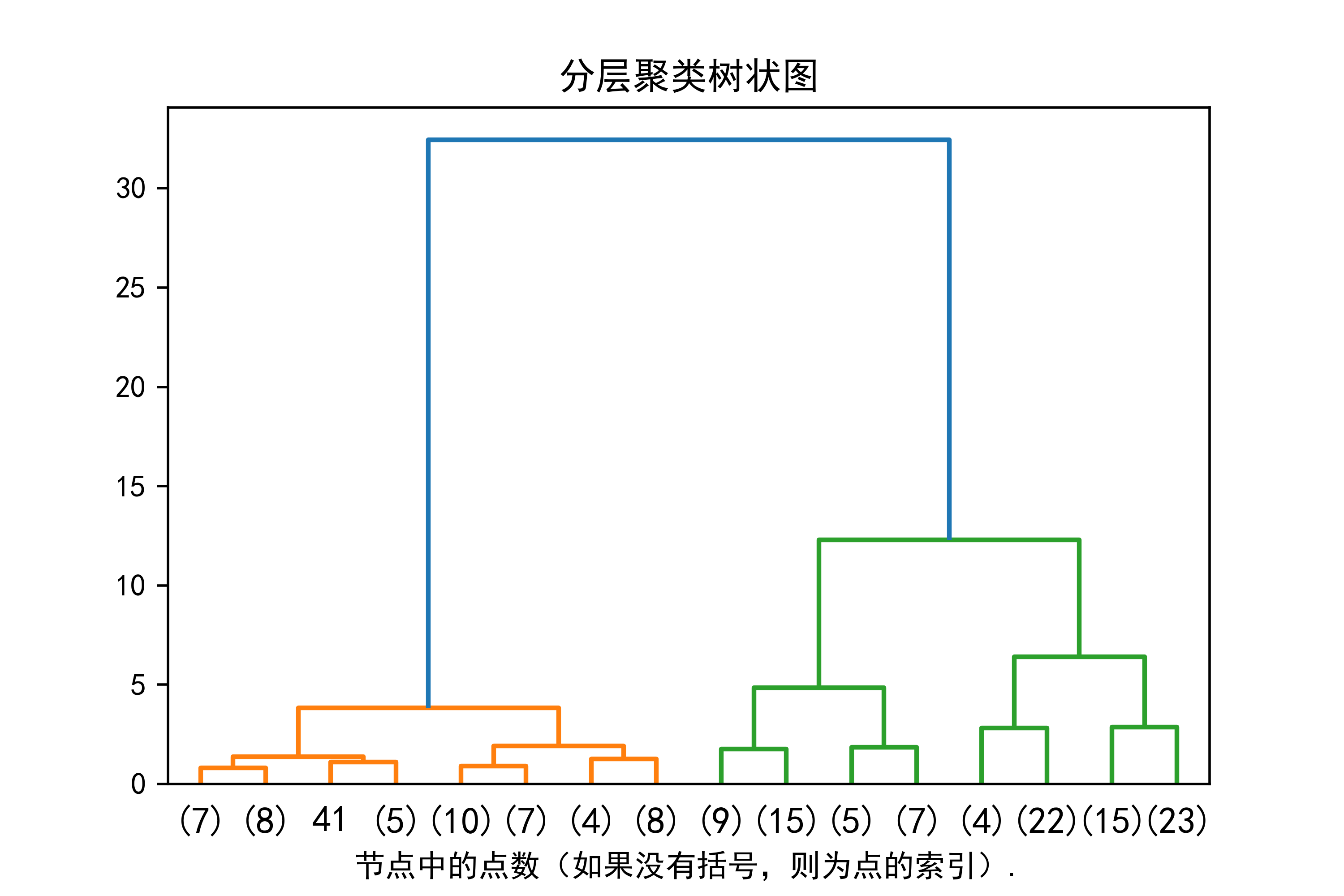
下面给出具体代码分析应用过程,这段代码是用于绘制层次聚类的树状图,展示数据点之间的聚类关系和层次结构。解释如下:
导入必要的库:首先,代码导入了必要的库,包括numpy用于数值计算,matplotlib用于绘图,scipy中的层次聚类模块和scikit-learn中的数据集和聚类算法。
定义绘制树状图的函数 plot_dendrogram:这个函数的作用是根据层次聚类模型的结果绘制树状图。函数首先计算每个节点下的样本数量,然后创建链接矩阵,最后绘制树状图。
加载数据集:代码加载了鸢尾花(iris)数据集,这是一个经典的机器学习数据集,包含了三种不同种类的鸢尾花的花萼和花瓣的长度和宽度。
初始化层次聚类模型 agglomerativeclustering:这里使用了scikit-learn中的agglomerativeclustering类来进行层次聚类。distance_threshold=0表示不设置距离阈值,n_clusters=none表示不指定聚类数量,而是通过完整的树状图展示聚类结构。
拟合模型并绘制树状图:代码对模型进行拟合,并调用plot_dendrogram函数绘制树状图。truncate_mode='level', p=3指定了截断模式为按层级截断,只显示树的前三个层级。这有助于避免树状图过于复杂而难以解读。
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from sklearn.datasets import load_iris
from sklearn.cluster import agglomerativeclustering
plt.rcparams['font.sans-serif'] = ['simhei'] #解决中文显示乱码问题
plt.rcparams['axes.unicode_minus'] = false
def plot_dendrogram(model, **kwargs):
# create linkage matrix and then plot the dendrogram
# create the counts of samples under each node
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # leaf node
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([model.children_, model.distances_,
counts]).astype(float)
# plot the corresponding dendrogram
dendrogram(linkage_matrix, **kwargs)
iris = load_iris()
x = iris.data
# setting distance_threshold=0 ensures we compute the full tree.
model = agglomerativeclustering(distance_threshold=0, n_clusters=none)
model = model.fit(x)
plt.title('分层聚类树状图')
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode='level', p=3)
plt.xlabel("节点中的点数(如果没有括号,则为点的索引).")
plt.savefig("../4.png", dpi=500)
plt.show()实例运行结果如下图所示:图像展示了鸢尾花数据集的层次聚类结果。在树状图中,横轴表示样本点的索引或样本点所在的聚类,纵轴表示聚类过程中的距离或合并程度。通过观察树状图,可以发现不同样本点之间的聚类关系和层次结构,以及聚类过程中的合并情况。
03-基于特征集聚方法合并相似特征
下面给出具体应用实例分析应用过程:这段代码展示了使用特征集聚类(feature agglomeration)对手写数字图像进行降维和重建的过程,并展示了原始图像、聚合后的图像以及聚类标签的可视化结果。解释如下:
导入必要的库:代码导入了numpy用于数值计算,matplotlib用于绘图,以及scikit-learn中的数据集和聚类模块。
加载手写数字数据集:代码加载了scikit-learn中的手写数字数据集(digits),该数据集包含了一系列手写数字图像。
准备数据:通过对图像进行reshape操作,将二维图像数据转换为一维向量。同时,使用grid_to_graph函数构建了图像的连通性,用于特征集聚类。
特征集聚类:使用cluster.featureagglomeration类进行特征集聚类,其中connectivity参数指定了图像的连通性,n_clusters参数指定了聚类的数量。
降维和重建:通过fit和transform方法对数据进行降维,然后使用inverse_transform方法将降维后的数据重建到原始维度。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, cluster
from sklearn.feature_extraction.image import grid_to_graph
digits = datasets.load_digits()
images = digits.images
x = np.reshape(images, (len(images), -1))
connectivity = grid_to_graph(*images[0].shape)
agglo = cluster.featureagglomeration(connectivity=connectivity,
n_clusters=32)
agglo.fit(x)
x_reduced = agglo.transform(x)
x_restored = agglo.inverse_transform(x_reduced)
images_restored = np.reshape(x_restored, images.shape)
plt.figure(1, figsize=(4, 3.5))
plt.clf()
plt.subplots_adjust(left=.01, right=.99, bottom=.01, top=.91)
for i in range(4):
plt.subplot(3, 4, i + 1)
plt.imshow(images[i], cmap=plt.cm.gray, vmax=16, interpolation='nearest')
plt.xticks(())
plt.yticks(())
if i == 1:
plt.title('原始数据')
plt.subplot(3, 4, 4 + i + 1)
plt.imshow(images_restored[i], cmap=plt.cm.gray, vmax=16,
interpolation='nearest')
if i == 1:
plt.title('聚合数据')
plt.xticks(())
plt.yticks(())
plt.subplot(3, 4, 10)
plt.imshow(np.reshape(agglo.labels_, images[0].shape),
interpolation='nearest', cmap=plt.cm.nipy_spectral)
plt.xticks(())
plt.yticks(())
plt.title('标签')
plt.savefig("../4.png", dpi=500)
plt.show()实例运行结果如下图所示:图像解释:
a、左侧列显示了原始的手写数字图像。
b、右侧列显示了经过特征集聚类降维和重建后的图像。
c、底部显示了聚类标签的可视化结果,将聚类标签映射为颜色。
这样的可视化结果有助于理解特征集聚类对数据的降维效果,并且可以直观地观察到降维后的图像重建质量以及聚类标签的分布情况。
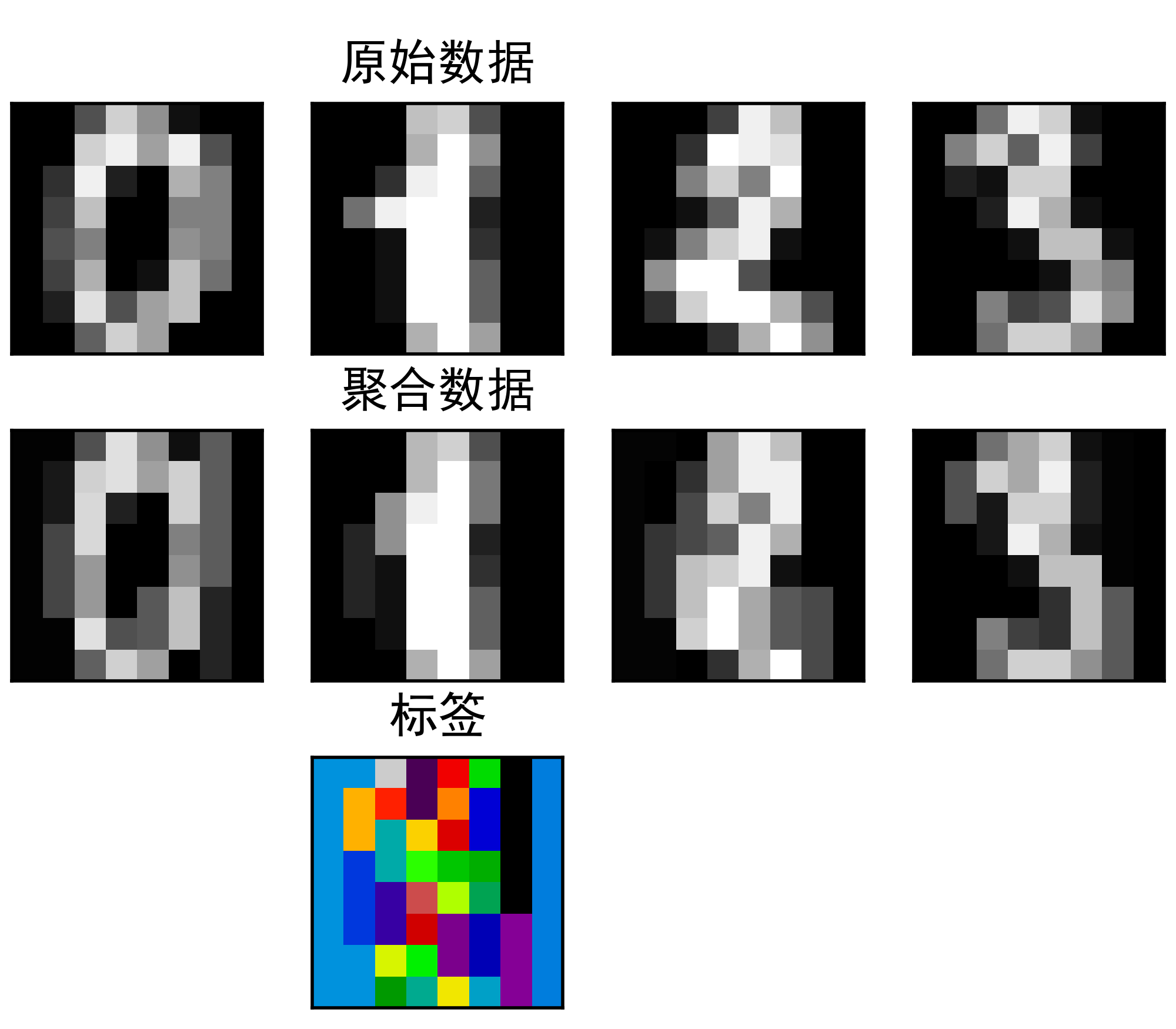
04-均值移位聚类算法实例分析
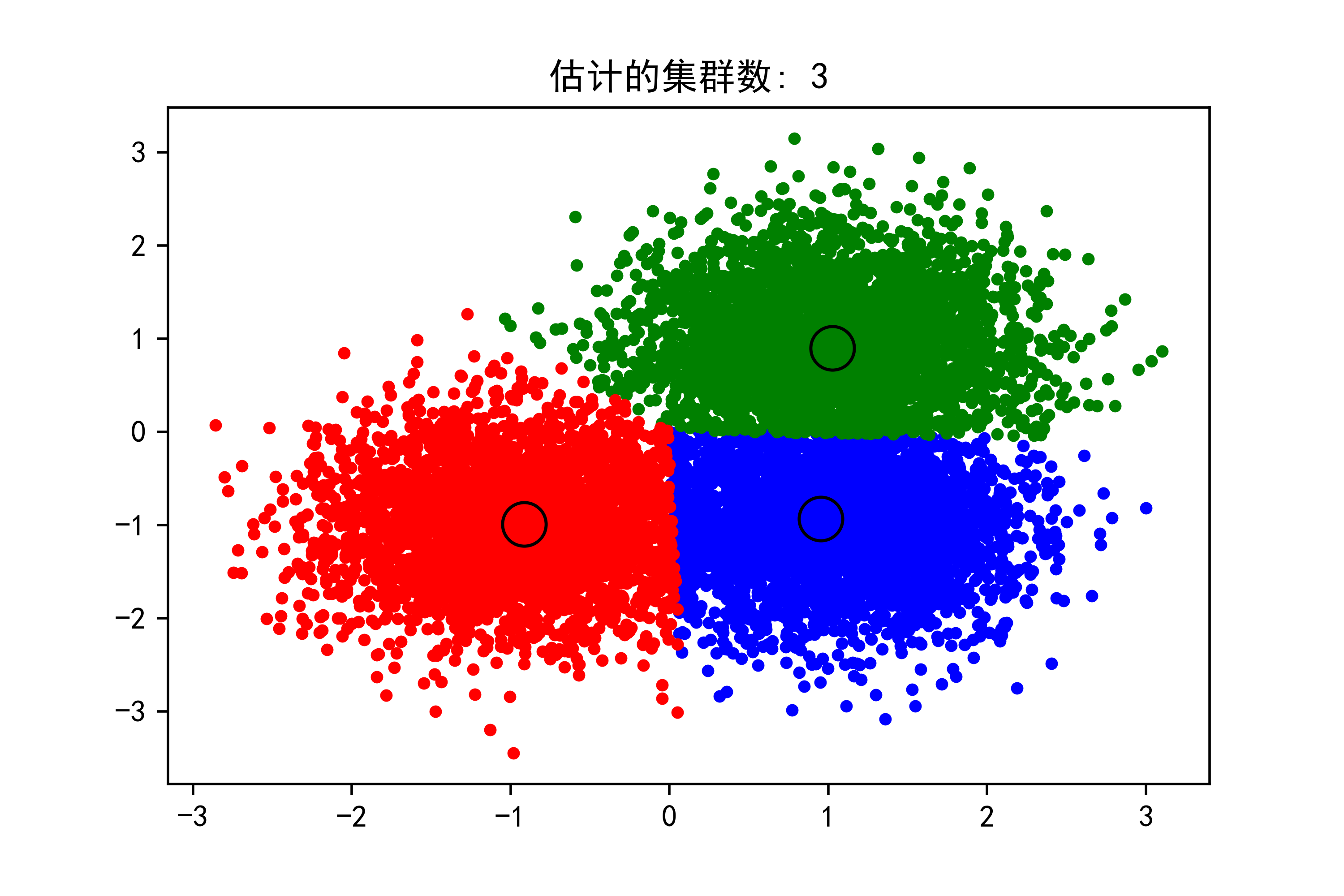
下面给出具体应用实例分析应用过程:这段代码演示了如何使用均值移位聚类算法对生成的样本数据进行聚类,并可视化聚类结果。解释如下:
生成样本数据:首先使用make_blobs函数生成了一个具有三个中心的随机样本数据集。这个数据集包含了10000个样本,每个中心点周围的标准差为0.6。
计算带宽:使用estimate_bandwidth函数估计了均值移位算法中的带宽参数。这个参数用于控制聚类的宽度,影响着聚类中心的数量和形状。
应用均值移位聚类:使用meanshift类构建了均值移位聚类器,并将估计的带宽参数传入。在这个例子中,还设置了bin_seeding=true,表示使用数据的离散化来初始化聚类中心。
获取聚类结果:通过调用fit方法拟合模型,并获取聚类的标签和聚类中心。
可视化聚类结果:使用matplotlib绘制了聚类结果的散点图。每个聚类用不同的颜色表示,聚类中心用大圆圈标出。
import numpy as np
from sklearn.cluster import meanshift, estimate_bandwidth
from sklearn.datasets import make_blobs
# #############################################################################
# generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
x, _ = make_blobs(n_samples=10000, centers=centers, cluster_std=0.6)
# #############################################################################
# compute clustering with meanshift
# the following bandwidth can be automatically detected using
bandwidth = estimate_bandwidth(x, quantile=0.2, n_samples=500)
ms = meanshift(bandwidth=bandwidth, bin_seeding=true)
ms.fit(x)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
labels_unique = np.unique(labels)
n_clusters_ = len(labels_unique)
print("估计的集群数 : %d" % n_clusters_)
# #############################################################################
# plot result
import matplotlib.pyplot as plt
from itertools import cycle
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
my_members = labels == k
cluster_center = cluster_centers[k]
plt.plot(x[my_members, 0], x[my_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
plt.title('估计的集群数: %d' % n_clusters_)
plt.savefig("../4.png", dpi=500)
plt.show()实例运行结果如下图所示:
在生成的图像中,你可以看到不同颜色的点代表了不同的聚类,而大圆圈则表示了每个聚类的中心。这些聚类中心是根据数据的密度分布自动确定的,而不需要预先指定聚类的数量。这正是均值移位聚类算法的一个优势所在。
通过观察图像,你可以看到数据点被聚类成了三个主要的簇,对应着我们在生成样本数据时设定的三个中心。这说明均值移位算法成功地识别出了数据中的聚类结构,并将数据点分配到了相应的簇中。
05-k-均值聚类算法假设的证明
下面给出具体应用实例分析应用过程:这段代码演示了使用k均值聚类算法在不同情况下对数据进行聚类,并可视化了聚类结果。解释如下:
生成样本数据:使用make_blobs函数生成了四组不同特征的随机样本数据集,其中包括了不同形状、大小和方差的斑点。
聚类并可视化:对于每组样本数据,使用k均值聚类算法进行聚类,并将聚类结果可视化在一个大图中的不同子图中。
第一个子图:展示了一个blob数据集,但指定的聚类数量不正确(n_clusters=2),导致部分数据点被错误地分配到了同一个簇中。
第二个子图:展示了一个具有各向异性分布的blob数据集,由于数据点的分布形状不规则,k均值聚类可能无法很好地捕捉到簇的形状。
第三个子图:展示了一个具有不同方差的blob数据集,这种情况下,k均值聚类可能会受到不同方差的影响,导致聚类结果不理想。
第四个子图:展示了一个大小不均匀的blob数据集,其中一些簇比其他簇更大,这种情况下,k均值聚类可能会对较大的簇进行过度拟合,而忽略掉较小的簇。
通过观察这些子图,可以更好地理解k均值聚类算法在不同数据情况下的表现,以及它对于数据分布形状、方差和大小的敏感程度。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import kmeans
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
n_samples = 1500
random_state = 170
x, y = make_blobs(n_samples=n_samples, random_state=random_state)
# incorrect number of clusters
y_pred = kmeans(n_clusters=2, random_state=random_state).fit_predict(x)
plt.subplot(221)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.title("blob 数不正确")
# anisotropicly distributed data
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
x_aniso = np.dot(x, transformation)
y_pred = kmeans(n_clusters=3, random_state=random_state).fit_predict(x_aniso)
plt.subplot(222)
plt.scatter(x_aniso[:, 0], x_aniso[:, 1], c=y_pred)
plt.title("各向异性分布的 blob")
# different variance
x_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = kmeans(n_clusters=3, random_state=random_state).fit_predict(x_varied)
plt.subplot(223)
plt.scatter(x_varied[:, 0], x_varied[:, 1], c=y_pred)
plt.title("不等方差")
# unevenly sized blobs
x_filtered = np.vstack((x[y == 0][:500], x[y == 1][:100], x[y == 2][:10]))
y_pred = kmeans(n_clusters=3,
random_state=random_state).fit_predict(x_filtered)
plt.subplot(224)
plt.scatter(x_filtered[:, 0], x_filtered[:, 1], c=y_pred)
plt.title("大小不均匀的斑点")
plt.savefig("../4.png", dpi=500)
plt.show()实例运行结果如下图所示:

总结
综上所述,以下是对层次聚类、特征集聚、均值移位聚类和k-均值聚类四种聚类算法的简要总结:
层次聚类:原理:层次聚类是一种自底向上或自顶向下的聚类方法,通过将数据点逐步合并或分割成不同的簇来构建聚类层次结构。优点:不需要预先指定聚类数量;可以形成聚类的层次结构,提供更丰富的信息。缺点:计算复杂度较高;对于大型数据集可能不太适用。
特征集聚:原理:特征集聚是一种基于特征选择的聚类方法,它将数据点聚类时不仅考虑数据本身的相似性,还考虑到特征之间的相似性。优点:能够处理高维数据;可以发现特征之间的关联性。缺点:对特征之间的相似性定义较为复杂;计算量可能较大。
均值移位聚类:原理:均值移位聚类是一种基于密度估计的非参数聚类方法,通过迭代地调整数据点的位置来找到局部最优的聚类中心。优点:不需要预先指定聚类数量;对于不规则形状的簇具有较好的适应性。缺点:计算复杂度较高;可能收敛速度较慢。
k-均值聚类:原理:k-均值聚类是一种基于距离的聚类方法,将数据点分配到预先指定数量的簇中,使得簇内数据点尽可能接近簇中心。优点:简单、直观;对于大型数据集具有较高的效率。缺点:需要预先指定簇的数量;对初始簇中心敏感;对非凸形状的簇效果较差。
总的来说,选择合适的聚类算法取决于数据的特点、聚类的目的以及算法的计算效率要求。在实际应用中,常常需要根据具体情况选择合适的算法并进行参数调优。

发表评论