目录
一、tensorflow介绍
tensorflow是一个强大的用于数值计算的库,特别适合大规模机器学习或者可以将其用于需要大量计算的任何其他场景。tensorflow是由google brain团队开发,并未许多google的大规模服务提供了支持,例如google cloud speech、google photos和google search。它于2015年11月开源,现在是最受欢迎的深度学习库。
tensorflow提供什么?
- tensorflow核心与numpy非常相似,但具有gpu支持;
- tensorflow支持分布式计算(跨多个设备和服务器);
- tensorflow包含一种即时(jit)编译器,可使其针对速度和内存使用情况来优化计算,它的工作方式是从python函数中提取计算图,然后进行优化(通过修剪未使用的节点),最后有效地运行它(通过自动并行运算相互独立的操作);
- 计算图可以导出为可移植格式,因此那你可以在一个环境中(例如linux上使用python)训练tensorflow模型,然后在另一个环境中(例如在android设备上使用java)运行tensorflow模型;
- tensorflow实现了自动微分(autodiff),并提供了一些优秀的优化器,例如rmsprop和nadam,因此你可以轻松地最小化各种损失函数。
tensorflow使用图(graph)来表示计算任务,图中的节点(node)称为op(“operation”的缩写)。一个op获得0个或者多个张量,执行计算,产生0个或者多个张量。每个张量是要给类型化的多维数组。一个tensorflow图描述了计算的过程。为了进行计算,图必须在session(会话)里被启动。会话将图的op分发到诸如cpu或gpu之类的设备上,同时提供执行op的方法。这些方法执行后,将所产生的张量返回。
一开始,我们需要导入tensorflow这个包,为了以后调用tensorflow包中的对象、成员变量和成员函数更加方便,我们import tensorflow后面加上了as tf,表示以后可以用tf这个简写来代表tensorflow的全名。
#载入库
import tensorflow as tf
#显示版本
print(tf.__version__) #注意是version前后都是两个下划线。
二、张量
tensorflow中tensor意思是“张量”,flow意思是“流或流动”。任意维度的数据可以称为“张量”,如一维数组、二维数组、n维数组。它最初想要表达的含义是保持计算节点不变,让数据在不同的计算设备上传输并计算。
- 零阶张量表示标量,一个数;
- 一阶张量表示一维向量;
- 2阶张量表示矩阵;
- n阶张量表示n维数组;
张量中并没有真正存储数字,它存储的是如何得到这些数字的计算过程。tesorflow中的张量和numpy中的数组不同,tensorflow的计算结果不是一个具体的数字,而是一个张量的结构。如:
>>> a = tf.constant([1.0, 2.0], name="a")
>>> a
<tf.tensor: shape=(2,), dtype=float32, numpy=array([1., 2.], dtype=float32)>
>>> print(a)
tf.tensor([1. 2.], shape=(2,), dtype=float32)
- 占位符(placeholder):事先未指定的值,(个人理解为c语言中对变量使用前进行定义)
- 变量(variable):一个可以改变的值,
>>> tf.variable([[1., 2., 3.],[4., 5., 6]])#matirx
<tf.variable 'variable:0' shape=(2, 3) dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>- 常量(constant):一个不可变的值,使用tf.constant()创建张量,
>>> tf.constant([[1., 2., 3.],[4., 5., 6]]) #矩阵
<tf.tensor: shape=(2, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
>>> tf.constant(42) #标量
<tf.tensor: shape=(), dtype=int32, numpy=42>
三、有用的tensorflow运算符
- tf.add(x,y) 两个类型相同张量相加,x+y;
- tf.subtract(x,y)两个类型相同张量相减,x-y;
- tf.multiply(x,y)两个张量元素相乘
- tf.pow(x,y)求元素x的y次方
- tf.exp(x)相当于pow(e,x)其中e为欧拉常数(2.718...)
- tf.sqrt(x)相当于pow(x,0.5)
- tf.div(x,y)两个张量元素相除
- tf.truediv(x,y)与tf.div相同,但将参数转换为浮点数
- tf.floordiv(x,y)与tf.truediv相同,但将最终结果取整
- tf.mod(x,y)取元素商的余数
- tf.negative(x)每个元素都取反
四、reduce系列函数实现约减
- tf.reduce_mean()
- tf.reduce_sum()
- tf.reduce_max()
- tf.math.log()
约减这一概念的解释,可以通过以下两种方法来理解:
- 引入轴的概念,0表示垂直方向,即沿着行的方向,1表示水平方向,即沿着列的方向;
- 按张量括号层次的方式
其中第一种理解方式简单且直观,但是仅限于2维以内的数组,当维数超过3时,我们很闹找到直观可以理解的方向。
1-第一种理解方式:引入轴概念后直观可理
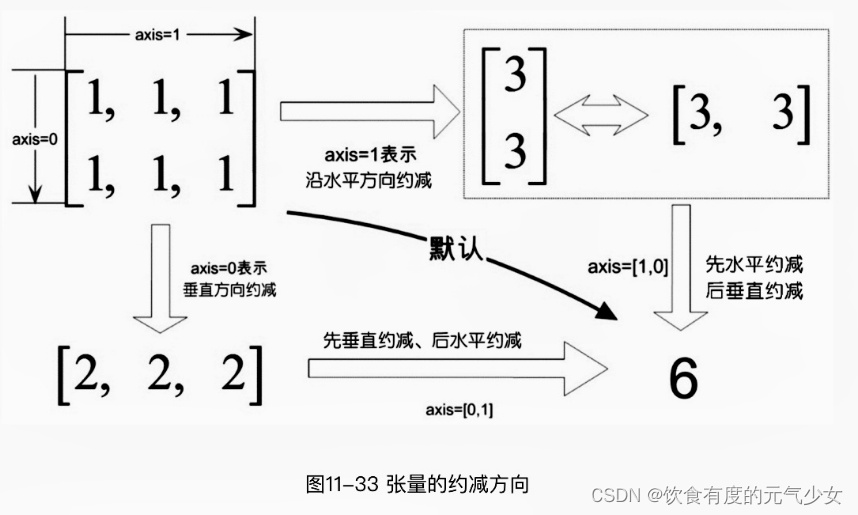
tf.reduce_sum()功能时对张量中的所有元素进行求和,它的函数原型如下:
>>> x = tf.constant([[1, 2, 3],[4, 5, 6]])
>>> x
<tf.tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]])>
>>> tf.reduce_sum(x) #axis取默认值,即对两个维度都执行约减
<tf.tensor: shape=(), dtype=int32, numpy=21>
>>> tf.reduce_sum(x,0) #axis=0
<tf.tensor: shape=(3,), dtype=int32, numpy=array([5, 7, 9])>
>>> tf.reduce_sum(x,1) #axis=1
<tf.tensor: shape=(2,), dtype=int32, numpy=array([ 6, 15])>2-第二种理解方式:按张量括号层次的方式
由于第一种理解方式对三维以上数组的约减没办法找到直观可以理解的方向,因此,更加普适的解释应该是按张量括号层次的方式来理解。张量括号由外到内,对应从小到大的维数,最外面的括号为0,表示第0维度;倒数第二括号,记为1,表示第1维度;以此类推0,1,2,。。。
>>> y=tf.constant([[[1, 1, 1],[2, 2, 2]],[[3, 3, 3],[4, 4, 4]]])
>>> y
<tf.tensor: shape=(2, 2, 3), dtype=int32, numpy=
array([[[1, 1, 1],
[2, 2, 2]],
[[3, 3, 3],
[4, 4, 4]]])>
>>> tf.reduce_sum(y,0)
<tf.tensor: shape=(2, 3), dtype=int32, numpy=
array([[4, 4, 4],
[6, 6, 6]])>
>>> tf.reduce_sum(y,1)
<tf.tensor: shape=(2, 3), dtype=int32, numpy=
array([[3, 3, 3],
[7, 7, 7]])>
>>> tf.reduce_sum(y,2)
<tf.tensor: shape=(2, 2), dtype=int32, numpy=
array([[ 3, 6],
[ 9, 12]])>
>>> tf.reduce_sum(y,[0,1])
<tf.tensor: shape=(3,), dtype=int32, numpy=array([10, 10, 10])>
>>> tf.reduce_sum(y,[0,1,2])
<tf.tensor: shape=(), dtype=int32, numpy=30>- 当axis=0时:

- 当axis=1时:

- 当axis=2时:

总结使用外层括号的进行约减的步骤:
- 根据axis的值,将相应的成对括号进行配对,括号内的元素表示这个维度下的元素,注意,这个维度下的元素可以根据相应的成对括号有几对便有几组;
- 计算每组这个维度下元素的和,注意,这里的元素可以表示标量、矩阵、三维数组、n维数组;
- 将每组这个维度下的计算结果放回到原先划分这个维度的元素的位置里,同时去掉这个维度的配对的括号。
参考:
《深度学习之美:ai时代的数据处理与最佳实践》(2018年6月出版,电子工业出版社)(这本书是我目前看到的介绍reduce(约减)最棒的书!把约减这个概念介绍的很清楚!其他书在介绍约减时很含糊,对于初学者不友好。)
《机器学习实战:基于scikit-learn、keras和tensorflow(原书第2版)》(2020年10月出版,机工社)
《python深度学习:基于tensorflow》(python深度学习:基于tensorflow)
《tensorflow机器学习(原书第2版)》(2022年5月出版,机工社)


发表评论