在开发中,一般会使用redis缓存一些常用的热点数据用来减少数据库io,提高系统的吞吐量
先了解一下分布式系统中的一致性概念。
强一致性:所有节点的数据必须实时同步,保证任何时候读取到的数据都是最新的。
弱一致性:系统允许数据暂时不一致,但最终会达到一致状态。
最终一致性:数据更新后,经过一段时间,系统会逐步达到一致状态。这个时间不固定,但在业务允许的范围内。
双写一致性:当数据同时存在于缓存(redis)和数据库(mysql)时,两者之间数据一致
那么容易出现数据一致性问题的场景是:
- 数据写入数据库,未更新缓存
- 删除缓存后,数据库更新失败
一、策略模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。有三种经典的缓存使用模式:
- cache-aside pattern
- read-through/write-through
- write-behind
1、旁路缓存模式(cache aside pattern)
cache aside pattern的提出是为了尽可能地解决缓存与数据库的数据不一致问题
流程:
- 读取操作:先从缓存中读取数据,缓存命中返回结果;缓存未命中,从db中读取数据,并将数据写入缓存。
- 更新操作:先更db,再删除缓存中的旧数据。
在日常开发中,一般使用了cache aside pattern缓存更新策略模式,以数据库为主,缓存为辅
public class cacheasidepattern {
private redisservice redis;
private databaseservice database;
// 读取操作
public string getdata(string key) {
// 从缓存中获取数据
string value = redis.get(key);
if (value == null) {
// 缓存未命中,从数据库获取数据
value = database.get(key);
if (value != null) {
// 将数据写入缓存
redis.set(key, value);
}
}
return value;
}
// 更新操作
public void updatedata(string key, string value) {
// 更新数据库
database.update(key, value);
// 删除缓存中的旧数据
redis.delete(key);
}
}?:cache-aside在操作数据库时,为什么是先操作数据库呢?为什么不先操作缓存呢?
1、先删除缓存后,数据库更新失败
线程1:删除缓存a,由于网络问题没有操作数据库失败
线程2:查询a,缓存无数据,并把a写入缓存
线程1:网络堵塞结束,修改数据库a为b
那么此时缓存是a【旧数据】,数据库是b【新数据】,脏数据出现啦!!!
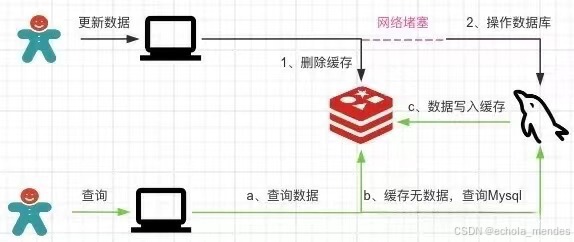
因此,cache-aside缓存模式,选择了先操作数据库而不是先操作缓存
2、先操作数据库再删除缓存方案
线程1:操作数据库,a更新数据为b,删除缓存a
线程2:查询a,缓存无数据,并把b写入缓存
这种方案下,在数据库更新成功后到删除redis缓存数据之前的这段时间中,其他线程读取的数据都是旧数据,等redis删除缓存后会重新从数据库中读取最新数据同步到redis,这样可以在一定程度上保证数据的最终一致性
但是在极端情况下,线程1的缓存删除失败,线程2读取的也就是旧数据a,而不是新数据b了
这种方案也就是旁路缓存模式,那么cache-aside的优缺点就是:
优点:
简单易懂,易于实现
读性能高,因为大部分读操作都会命中缓存
缺点:
更新数据库后缓存可能还没删除,存在短暂的不一致
删除缓存后,如果数据库更新失败,会导致数据不一致
?:cache-aside在写入请求的时候,为什么是删除缓存而不是更新缓存呢?
线程1:操作数据库,更新数据为a,由于网络问题未更新缓存
线程2:操作数据库,更新数据为b,更新缓存为b
线程1:网络堵塞结束,更新缓存为a
那么此时缓存是a【旧数据】,数据库是b【新数据】,脏数据出现啦!!!
如果是删除缓存取代更新缓存则不会出现这个脏数据问题!!!
因此,cache-aside缓存模式,选择了删除缓存而不是更新缓存
适应场景:适用于读多写少的场景,特别是对数据一致性要求不是特别高的应用
2、读写穿透(read-through/write-through)
read-through:当缓存未命中时,自动从数据库加载数据,并写入缓存
write-through:当缓存更新时,同步将数据写入数据库
和旁路缓存模式很像,只有写操作不太一样
public class readwritethroughpattern {
private redisservice redis;
private databaseservice database;
// read-through
public string readthrough(string key) {
// 从缓存中获取数据
string value = redis.get(key);
if (value == null) {
// 缓存未命中,从数据库获取数据
value = database.get(key);
if (value != null) {
// 将数据写入缓存
redis.set(key, value);
}
}
return value;
}
// write-through
public void writethrough(string key, string value) {
// 将数据写入缓存
redis.set(key, value);
// 同步将数据写入数据库
database.update(key, value);
}
}优点:
- 保证了数据的强一致性,缓存和数据库的数据始终同步。
- 读写操作都由缓存处理,数据库压力较小。
缺点:
- 写操作的延迟较高,因为每次写入缓存时都需要同步写入数据库,增加了系统的响应时间
- 实现复杂度较高,需要额外的缓存同步机制
适应场景:适合读多写多、且对数据一致性要求较高的场景
3、异步缓存写入(write behind)
异步缓存就是缓存更新后,异步批量写入数据库。这种策略适用于可以容忍一定数据不一致的高性能场景
示例代码:
public class writebehindpattern {
private redisservice redis;
private databaseservice database;
private updatequeue updatequeue;
// 异步缓存写入
public void writebehind(string key, string value) {
// 将数据写入缓存
redis.set(key, value);
// 异步将数据写入数据库
asyncdatabaseupdate(key, value);
}
private void asyncdatabaseupdate(string key, string value) {
// 异步操作,将更新请求放入队列
updatequeue.add(new updatetask(key, value));
}
}优点:
写操作的性能非常高,因为只需更新缓存,数据库更新是异步进行的
适用于对写操作性能要求较高的场景
缺点:
存在数据不一致的风险,缓存更新后数据库可能还未更新。
实现复杂度较高,需要处理异步操作中的异常和重试
适应场景:大批量数据读取,允许短期数据不一致,写密集型场景
二、一致性解决方案
缓存系统适用的场景就是非强一致性的场景,它属于cap中的ap
cap理论,指的是在一个分布式系统中, consistency(一致性)、 availability(可用性)、partition tolerance(分区容错性),三者不可得兼。
没办法做到数据库与缓存绝对的一致性,但通过一些方案优化处理,是可以保证弱一致性,最终一致性的
1、缓存延迟双删
流程:
- 先删除缓存
- 再更新数据库
- 休眠一会(比如1秒),再次删除缓存
但休眠的时间内,可能有脏数据,且第二次删除也可能失败,导致的数据不一致问题
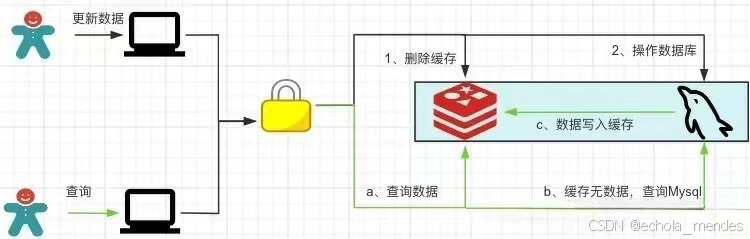
延迟双删策略只能保证最终的一致性,不能保证强一致性。由于对redis的操作和mysql的操作不是原子性操作,所以如果想保证数据的强一致性就需要加锁控制,如下图所示
加锁之后势必会带来系统的吞吐量的下降,所以需要衡量利弊来确定是否使用加锁
方案优化:删除失败就多删除几次呀,保证删除缓存成功就可以了!
所以可以引入删除缓存重试机制
2、删除重试机制
删除缓存失败,则将这些key放入到消息队列中,消费消息队列的消息,获取要删除的key,重试删除缓存操作
3、读取biglog异步删除缓存
重试删除缓存机制还可以吧,就是会造成好多业务代码入侵。
方案优化:通过数据库的binlog来异步淘汰key
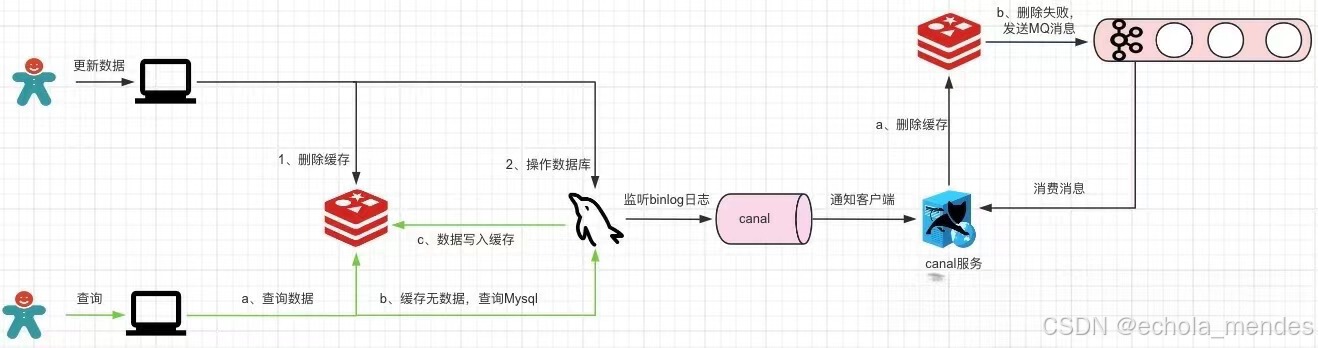
以mysql为例,通过canal监听binlog日志感知数据的变动后,canal客户端执行删除redis缓存数据,如果缓存数据删除失败那么发送一条mq消息让canal客户端继续执行删除操作,这样可以保证数据的最终一致性,但是这样也增加了系统的复杂性
三、总结
(1)实际开发中一般使用使用了cache aside pattern缓存更新策略模式,此方案最大程度上保证了数据的一致性并且实现也最简单
(2)无论是先操作数据库再删除缓存还是先删除缓存再操作数据库都有可能会出现删除缓存失败的情况,所以需要加入删除重试机制
(3)如果想要redis和mysql的数据强一致性,可以考虑使用加锁的方式实现
以上就是redis与mysql数据一致性问题的策略模式及解决方案的详细内容,更多关于redis与mysql数据一致性的资料请关注代码网其它相关文章!




发表评论