目录
一、pipeline 背景和原理
elasticsearch 5.0之前的文档预处理
在 elasticsearch 5.0 版本之前,如果用户希望在文档被索引到 elasticsearch 之前进行预处理,他们通常需要依赖外部工具,如 logstash,或者以编程方式/手动进行预处理。这是因为早期的 elasticsearch 版本并不提供文档预处理或转换的能力,它仅仅是将文档按原样索引。
ingest node的引入
从 elasticsearch 5.x 版本开始,为了解决这个问题,elasticsearch 引入了一个名为 ingest node 的功能。ingest node 为 elasticsearch 本身提供了文档预处理和丰富的轻量级解决方案。这意味着用户可以在 elasticsearch 内部直接对文档进行预处理,而无需依赖外部工具。
ingest node的工作原理
当数据进入 elastic 集群并指定了特定的 pipeline 时,elasticsearch 中的 ingest node 会按照定义好的处理器(processor)顺序对数据进行操作和处理。这种预处理是通过截取批量和索引请求在 ingest node 上执行的,处理完成后将文档传递回索引或批量 api。
要在索引之前预处理文档,用户必须定义一个 pipeline。pipeline 是一系列处理器的集合,用于转换传入的文档。每个处理器都以某种方式转换文档,并且它们按照在 pipeline 中定义的顺序执行。
要使用 pipeline,用户只需在索引或批量请求上指定 pipeline 参数,告诉 ingest node 使用哪个 pipeline。
ingest node的配置与灵活性
如果使用默认配置实现 elasticsearch 节点,默认情况下将启用 master、data 和 ingest 功能,这意味着节点将充当主节点、数据节点和提取节点。但是,如果用户在 elasticsearch.yml 文件中配置了 node.ingest: false,则该节点上的 ingest 功能将被禁用。
与 logstash 相比,elasticsearch 的 ingest node 提供了更高的灵活性。因为用户可以通过编程的方式随时修改 pipeline,而无需重启整个 logstash 集群。
elasticsearch对logstash的替代
随着新的 ingest 功能的发布,elasticsearch 已经取出了 logstash 的部分功能,特别是其过滤器部分。这意味着用户现在可以在 elasticsearch 中直接处理原始日志,而无需先通过 logstash 进行过滤和预处理。这进一步简化了数据处理流程,并提高了系统的整体性能。
二、pipeline api使用
要使用pipeline api,首先需要定义pipeline。pipeline由两部分组成:描述(description)和处理器列表(processor list)。
- 描述(description):这是一个非必需字段,用于存储关于pipeline的一些描述性信息,如用途、作者等。虽然这个字段不是必需的,但它对于理解和维护pipeline非常有帮助。
- 处理器列表(processor list):这是pipeline的核心部分,它定义了用于转换文档的处理器序列。每个处理器以某种方式转换文档,如替换文本、转换数据类型、删除字段等。处理器按照在pipeline中定义的顺序执行。
elasticsearch提供了大约20个内置的处理器,这些处理器可以在构建pipeline时使用。此外,还可以使用一些插件提供的处理器,如ingest attachment用于处理附件数据、ingest geo-ip用于根据ip地址提取地理位置信息等。这些插件增强了pipeline的数据处理能力。
定义好pipeline后,就可以通过在索引或批量请求上指定pipeline参数来使用它。例如,当通过post请求将数据发送到指定索引时,可以带上pipeline参数来指定使用的pipeline。
1. 定义 pipeline
使用 put 请求和 _ingest/pipeline/<pipeline_id> 端点来定义一个新的 pipeline 或更新一个已存在的 pipeline。pipeline 的定义包含了一个可选的 description 字段和一个 processors 列表。
例如,定义一个名为 firstpipeline 的 pipeline,它将消息字段(message)中的值转换为大写:
put _ingest/pipeline/firstpipeline
{
"description": "将 message 字段中的值转换为大写",
"processors": [
{
"uppercase": {
"field": "message"
}
}
]
}
2. 使用 pipeline
要在索引文档之前使用定义的 pipeline,只需在索引或批量请求的 url 中添加 ?pipeline=<pipeline_id> 参数。
例如,使用之前定义的 firstpipeline 来索引一个文档:
put my_index/_doc/1?pipeline=firstpipeline
{
"name": "pipeline",
"message": "this is so cool!"
}
执行上述请求后,索引到 my_index 中的文档将具有大写形式的 message 字段。
3. 获取 pipeline 信息
使用 get 请求和 _ingest/pipeline 端点可以检索现有 pipeline 的定义。
例如,要获取所有 pipeline 的定义:
get _ingest/pipeline
或者,要获取特定 pipeline(如 secondpipeline)的定义:
get _ingest/pipeline/secondpipeline
4. 删除 pipeline
使用 delete 请求和 _ingest/pipeline/<pipeline_id> 端点可以删除一个 pipeline。
例如,删除名为 firstpipeline 的 pipeline:
delete _ingest/pipeline/firstpipeline
5. 模拟 pipeline
使用 _simulate 端点可以模拟 pipeline 的执行,而不实际索引文档。这对于测试 pipeline 定义和查看预期结果非常有用。
例如,模拟 secondpipeline 对提供的文档集的执行:
post _ingest/pipeline/secondpipeline/_simulate
{
"docs": [
{
"_source": {
"name": "pipeline",
"message": "this is so cool!"
}
},
{
"_source": {
"name": "nice",
"message": "this is nice!"
}
}
]
}
上述请求将返回模拟执行后的文档,并显示每个文档经过 pipeline 处理后的结果。
6. 引用其他 pipeline
在 pipeline 的定义中,还可以引用其他已存在的 pipeline。这允许用户创建复杂的文档处理流程,通过组合多个 pipeline 来实现。
例如,先定义一个 pipelinea,然后在 pipelineb 中引用它:
put _ingest/pipeline/pipelinea
{
"description": "内部 pipeline",
"processors": [
{
"set": {
"field": "inner_pipeline_set",
"value": "inner"
}
}
]
}
put _ingest/pipeline/pipelineb
{
"description": "外部 pipeline",
"processors": [
{
"pipeline": {
"name": "pipelinea"
}
},
{
"set": {
"field": "outer_pipeline_set",
"value": "outer"
}
}
]
}
在上述示例中,当使用 pipelineb 索引文档时,首先会执行 pipelinea 的处理器,然后再执行 pipelineb 中定义的其他处理器。
三、pipeline api应用场景
pipeline api在数据预处理方面有着广泛的应用。以下是一些具体的应用场景:
-
数据清洗:通过pipeline api,可以在数据索引到elasticsearch之前对数据进行清洗,去除无用的字段、转换数据类型、处理缺失值等。这有助于确保数据的准确性和一致性。
-
日志处理:对于日志数据,pipeline api非常有用。它可以用于解析和格式化日志数据,提取出有用的字段进行索引,以便于后续的查询和分析。例如,可以使用grok处理器来解析复杂的日志行。
-
数据增强:除了基本的数据清洗和转换外,pipeline api还可以用于数据增强。例如,通过ingest geo-ip插件,可以根据ip地址提取出地理位置信息并添加到文档中;通过ingest user-agent插件,可以解析用户代理字符串并提取出浏览器、操作系统等信息。
-
动态修改pipeline:由于pipeline api支持编程方式修改,因此可以根据实际需求动态地修改pipeline。这意味着当数据格式或处理需求发生变化时,无需修改源代码或重启elasticsearch集群,只需通过api调用即可更新pipeline。
四、pipeline 应用方式
-
在 bulk api 中使用
使用 bulk api 时,可以指定 pipeline 来预处理批量文档。例如:
post _bulk {"index": {"_index": "my_index", "_id" : "1", "pipeline": "my_pipeline"}} {"name": "zhang san", "category": "sports"}对于 bulk api 请求,可以包含多个操作(如 index, update, delete 等),并为每个操作指定不同的 pipeline(如果需要)。
-
在 beats 中使用
在 filebeat 或其他 beats 中,可以通过配置 pipeline processor 来预处理事件数据。这允许在数据发送到 elasticsearch 之前进行必要的转换和增强。具体可参阅 elastic 官方文档中关于 beats 和 pipeline processor 的部分。
-
在 reindex api 中使用
当从一个索引重新索引到另一个索引时,可以使用 pipeline 来预处理数据。例如:
post _reindex { "source": { "index": "source_index" }, "dest": { "index": "destination_index", "pipeline": "some_ingest_pipeline" } }这样,从
source_index重新索引到destination_index的所有文档都将通过some_ingest_pipeline进行预处理。 -
在 enrich processors 中使用
elasticsearch 的 enrich processor 允许你根据其他索引中的数据进行数据丰富。结合 ingest pipeline,可以在数据丰富之前对文档进行预处理。例如,可以在 enrich processor 之前使用 pipeline 来提取或转换字段,以确保它们可用于 enrich processor。
-
在 update by query api 中使用
使用 update by query api 更新索引中的文档时,可以通过指定 pipeline 来预处理这些文档。例如:
post my_index/_update_by_query?pipeline=my_pipeline { "query": { "match": { "some_field": "some_value" } } }上述请求将更新
my_index中满足some_field: some_value条件的文档,并在更新前通过my_pipeline对它们进行预处理。 -
在索引中设置 default pipeline
对于特定索引,可以通过设置默认 pipeline 来确保所有新索引的文档都经过该 pipeline 的处理。例如:
put my_index { "settings": { "index.default_pipeline": "my_pipeline" } }此后,任何索引到
my_index的新文档都将默认通过my_pipeline进行预处理。注意,在较新版本的 elasticsearch 中,设置方式可能有所变化,请查阅相应版本的官方文档。
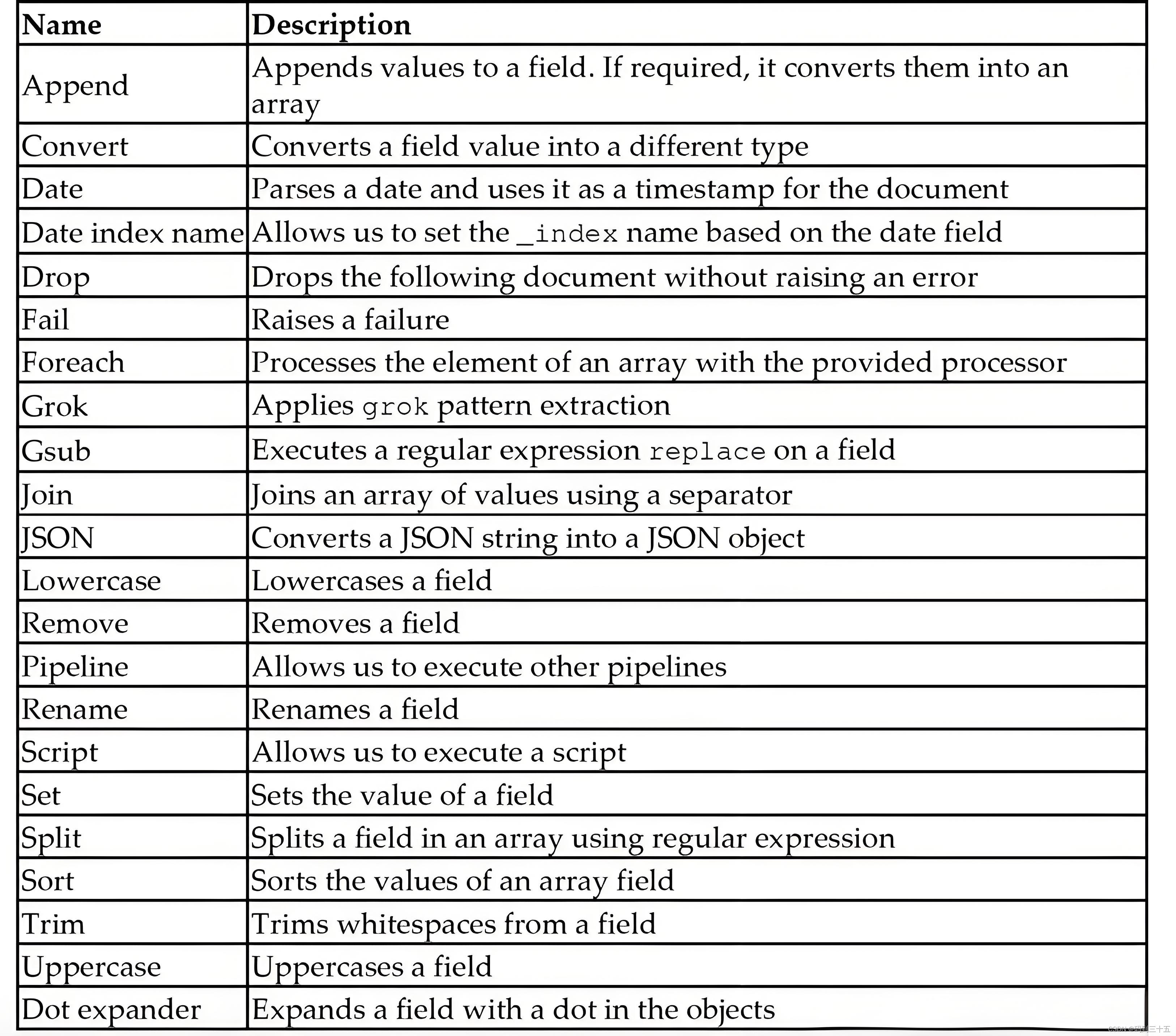
五、内置 processors
默认情况下,elasticsearch 提供大量的ingest处理器。 可以在地址https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest-processors.html 找到已经为我设计好的内置的 processors。下面是一些常见的一些 processor :



发表评论