
前言
在这篇文章中,我们将探讨如何通过使用ml来预测一个信号,并且该信号对于购买特定股票是否有帮助?
目录
1. 相关库和数据集
1.1 相关库介绍
python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
pandas– 该库有助于以 2d 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。numpy– numpy 数组速度非常快,可以在很短的时间内执行大型计算。matplotlib/seaborn– 此库用于绘制可视化效果,用于展现数据之间的相互关系。sklearn– 包含多个库,这些库具有预实现的功能,用于执行从数据预处理到模型开发和评估的任务。xgboost– 包含 extreme gradient boosting 机器学习算法,是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import standardscaler
from sklearn.linear_model import logisticregression
from sklearn.svm import svc
from xgboost import xgbclassifier
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore')
1.2 数据集介绍
我们将在这里用于执行分析和构建预测模型的数据集是特斯拉股价数据。我们将使用 2010 年 1 月 1 日至 2017 年 12 月 31 日的 ohlc(‘开盘价’、‘最高价’、‘最低价’、‘收盘价’)数据,这是特斯拉股票的 8 年数据。
使用read_csv函数读取.csv文件,加载数据。
df = pd.read_csv('tesla.csv')
df.head()
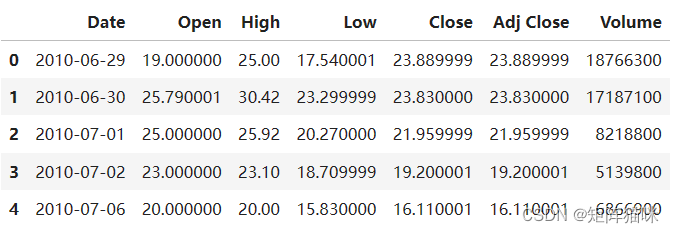
从前五行中,我们可以看到某些日期的数据缺失,原因是在周末和节假日,股市仍然关闭,因此这些日子没有交易。
df.shape
输出:
(2416, 7)
由此,我们知道有 2416 行可用数据,每行都有 7 个不同的特征或列。
df.describe()

df.info()

2. 探索性数据分析
eda是一种使用视觉技术分析数据的方法。它用于发现趋势和模式,或借助统计摘要和图形表示来检查假设。
2.1 检查数据的趋势
在对特斯拉股价数据进行 eda 时,我们将分析股票价格在一段时间内的变动情况以及季度末如何影响股票价格。
plt.figure(figsize=(15,5))
plt.plot(df['close'])
plt.title('tesla close price.', fontsize=15)
plt.ylabel('price in dollars.')
plt.show()
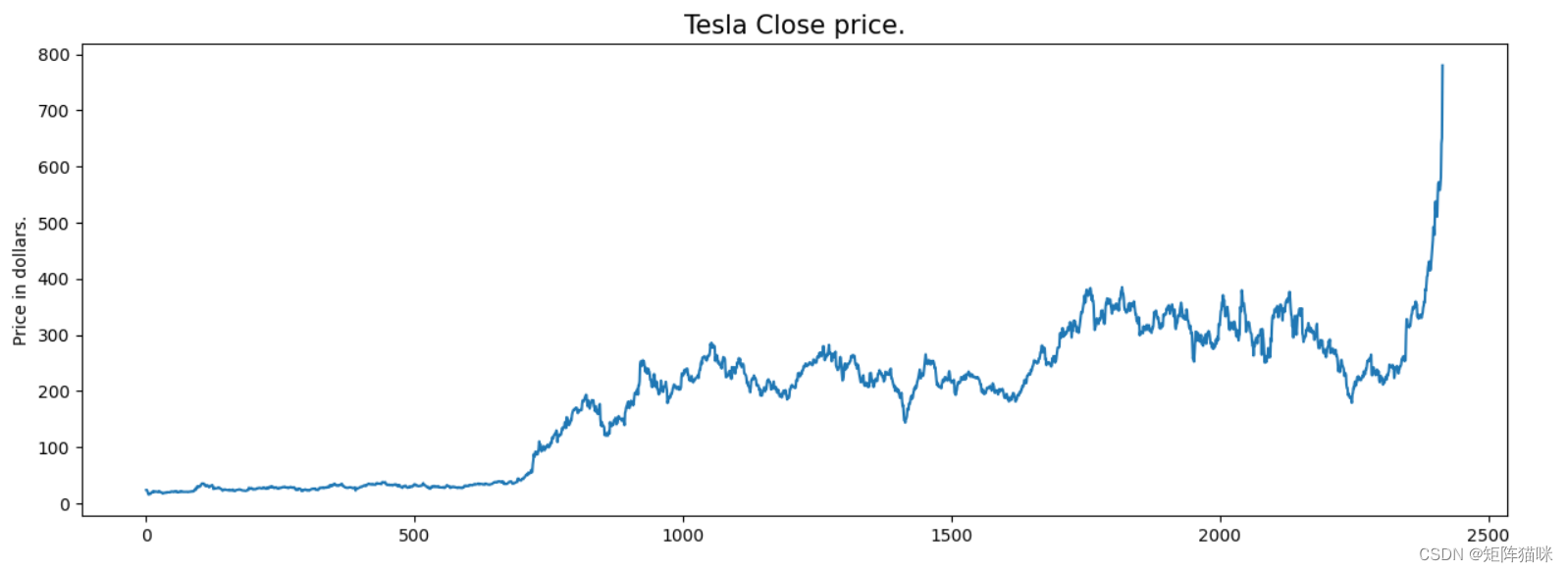
特斯拉股票的价格呈上升趋势,如股票收盘价图所示。
2.2 检查数据重复值
df.head()

如果我们仔细观察,我们可以看到“关闭”列中的数据和“调整关闭”列中可用的数据是相同的,让我们检查每行是否都是这种情况。
df[df['close'] == df['adj close']].shape
输出:
(2416, 7)
从这里我们可以得出结论,所有列“close”和“adj close”行都具有相同的数据。因此,数据集中的冗余数据无济于事,因此,在进一步分析之前,我们将删除此列。
df = df.drop(['adj close'], axis=1)
2.3 检查数据的空值
现在,让我们绘制数据集中给定的连续特征的分布图。在继续之前,让我们检查数据框中是否存在空值(如果存在)。
df.isnull().sum()
输出:

这意味着提供的数据集中没有空值。
2.4 检查数据的分布
features = ['open', 'high', 'low', 'close', 'volume']
plt.subplots(figsize=(20,10))
for i, col in enumerate(features):
plt.subplot(2,3,i+1)
sb.distplot(df[col])
plt.show()
输出:

在ohlc数据的分布图中,我们可以看到两个峰值,这意味着数据在两个区域发生了显着变化。并且 volume 数据是左偏的。
2.5 检查数据异常值
plt.subplots(figsize=(20,10))
for i, col in enumerate(features):
plt.subplot(2,3,i+1)
sb.boxplot(df[col])
plt.show()
输出
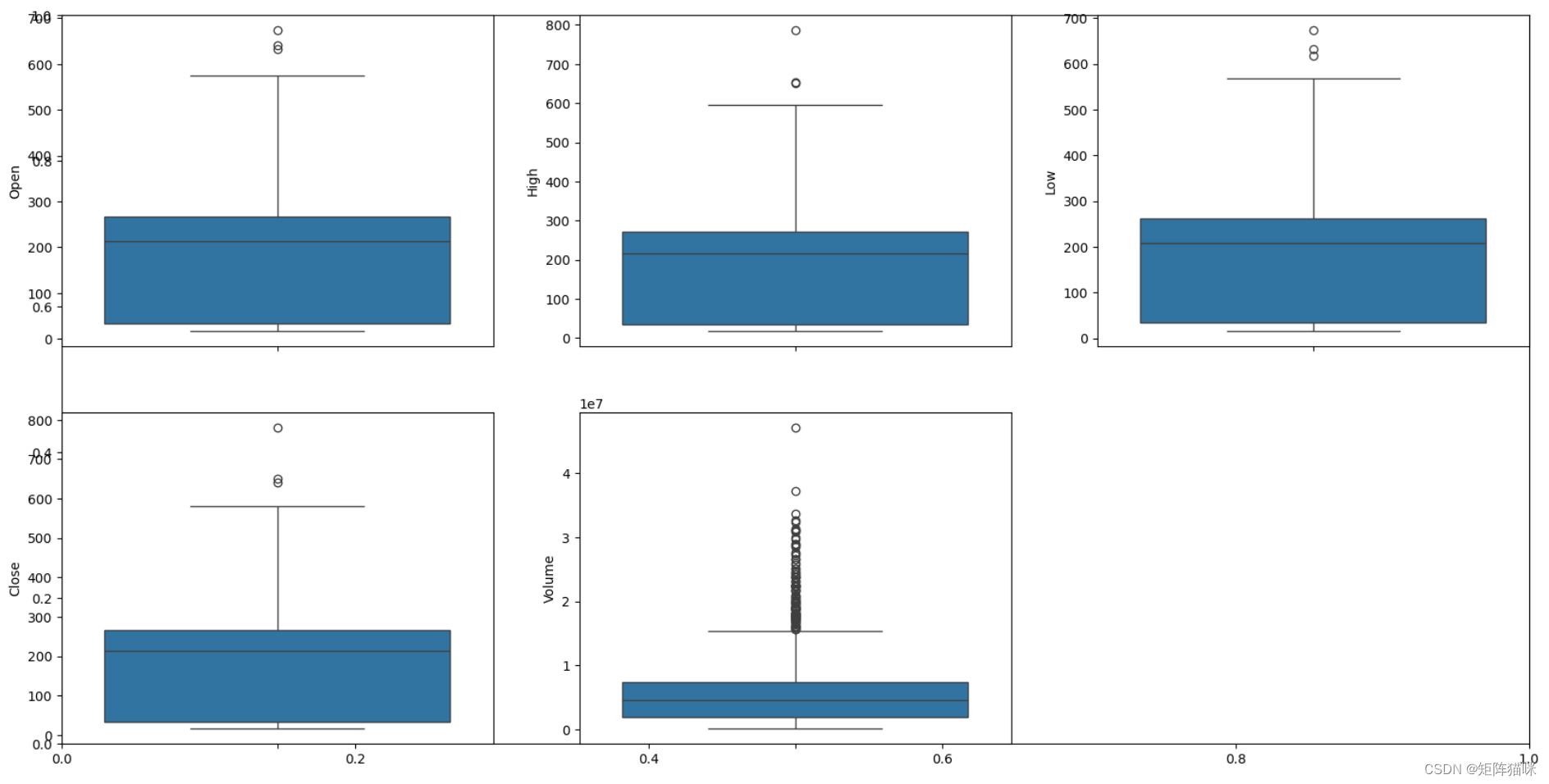
从上面的箱线图中,我们可以得出结论,只有volume数据包含异常值,但其余列中的数据没有任何异常值。
3. 特征工程
特征工程有助于从现有特征中派生出一些有价值的特征。这些额外的功能有时有助于显著提高模型的性能,当然也有助于更深入地了解数据。
splitted = df['date'].str.split('-', expand=true)
df['day'] = splitted[2].astype('int')
df['month'] = splitted[1].astype('int')
df['year'] = splitted[0].astype('int')
df.head()
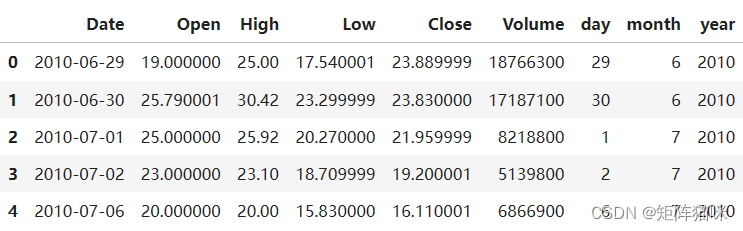
现在我们又有三列,即“日”、“月”和“年”,这三列都是从数据中最初提供的“日期”列派生而来的。
df['is_quarter_end'] = np.where(df['month']%3==0,1,0)
df.head()
季度被定义为三个月的时间段。每家公司都会准备季度业绩并公开发布,以便人们可以分析公司的业绩。这些季度业绩对股价有重大影响,这就是我们添加此功能的原因,因为这可能对学习模型有所帮助。
df.drop('date',axis=1,inplace=true)
data_grouped = df.groupby('year').mean()
plt.subplots(figsize=(20,10))
for i, col in enumerate(['open', 'high', 'low', 'close']):
plt.subplot(2,2,i+1)
data_grouped[col].plot.bar()
plt.show()
输出:
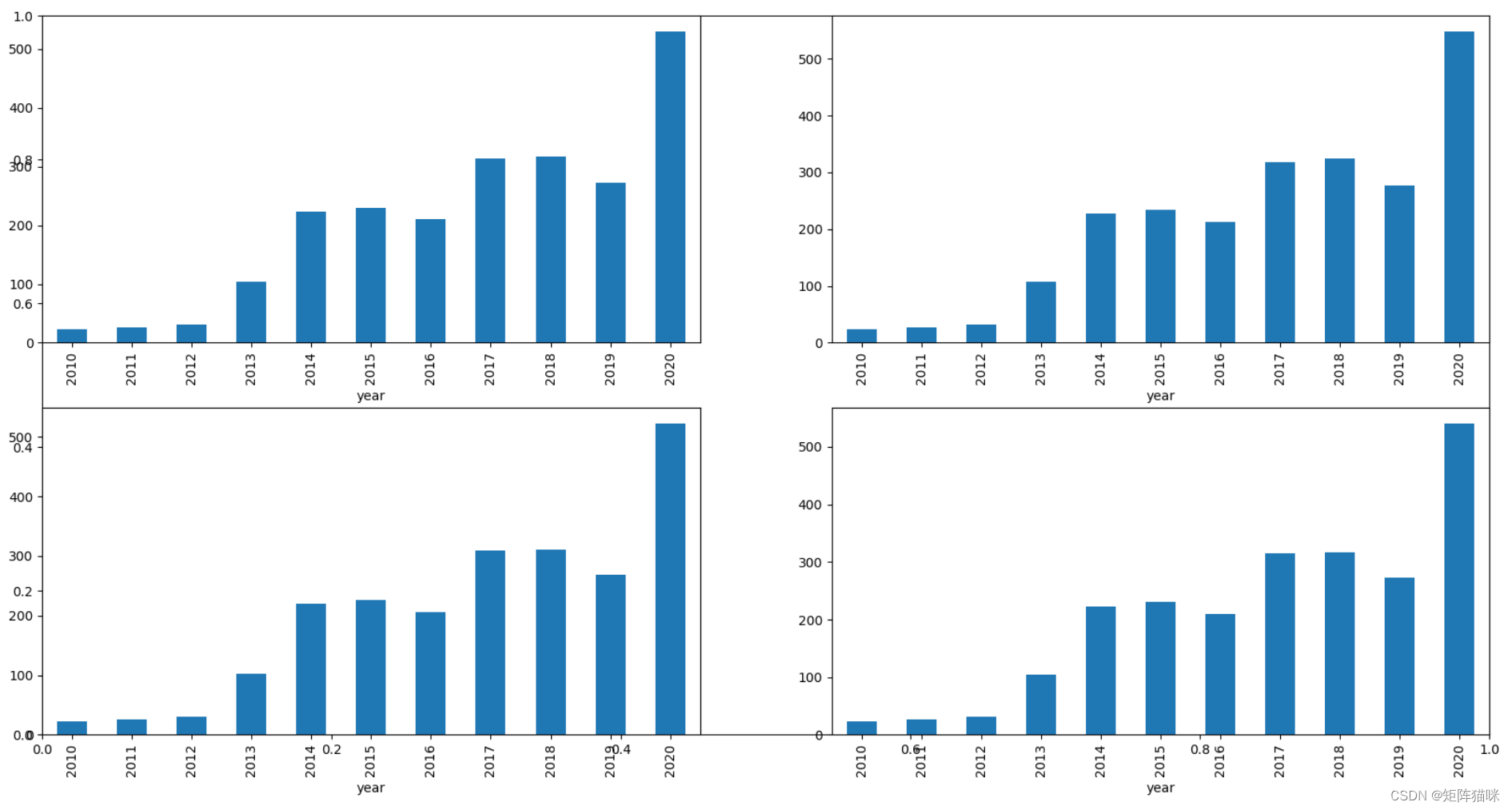
从上面的条形图中,我们可以得出结论,从2013年到2014年,股价翻了一番。
df.groupby('is_quarter_end').mean()

以下是对上述分组数据的一些重要观察结果:
- 与非季度末月份相比,季度末月份的价格更高。
- 季度末的月份交易量较低。
df['open-close'] = df['open'] - df['close']
df['low-high'] = df['low'] - df['high']
df['target'] = np.where(df['close'].shift(-1) > df['close'], 1, 0)
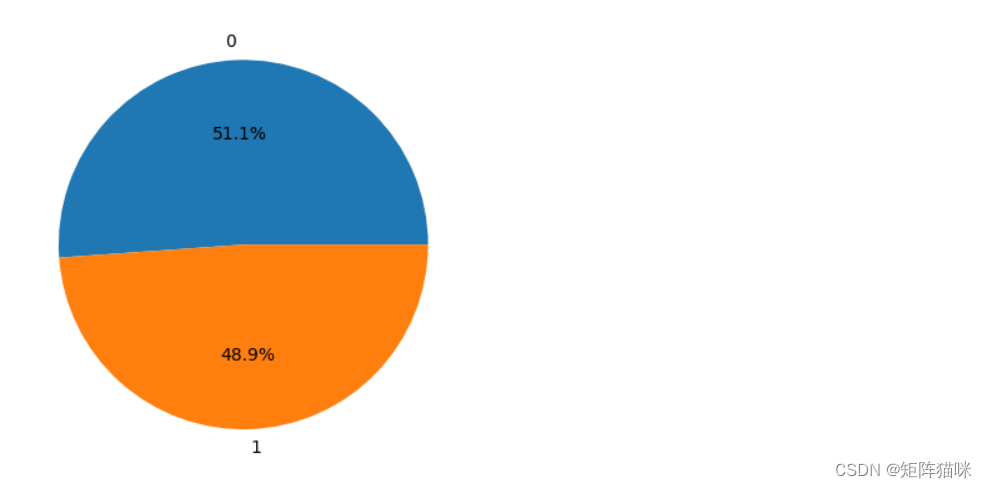
上面我们添加了一些列,这将有助于训练我们的模型。我们添加了目标特征,这是一个是否购买的信号,我们将训练我们的模型来仅预测这一点。但在继续之前,让我们使用饼图检查目标是否平衡。
plt.pie(df['target'].value_counts().values,
labels=[0, 1], autopct='%1.1f%%')
plt.show()
输出:
当我们向数据集添加特征时,我们必须确保没有高度相关的特征,因为它们对算法的学习过程没有帮助。
plt.figure(figsize=(10, 10))
# as our concern is with the highly
# correlated features only so, we will visualize
# our heatmap as per that criteria only.
sb.heatmap(df.corr() > 0.9, annot=true, cbar=false)
plt.show()
输出:
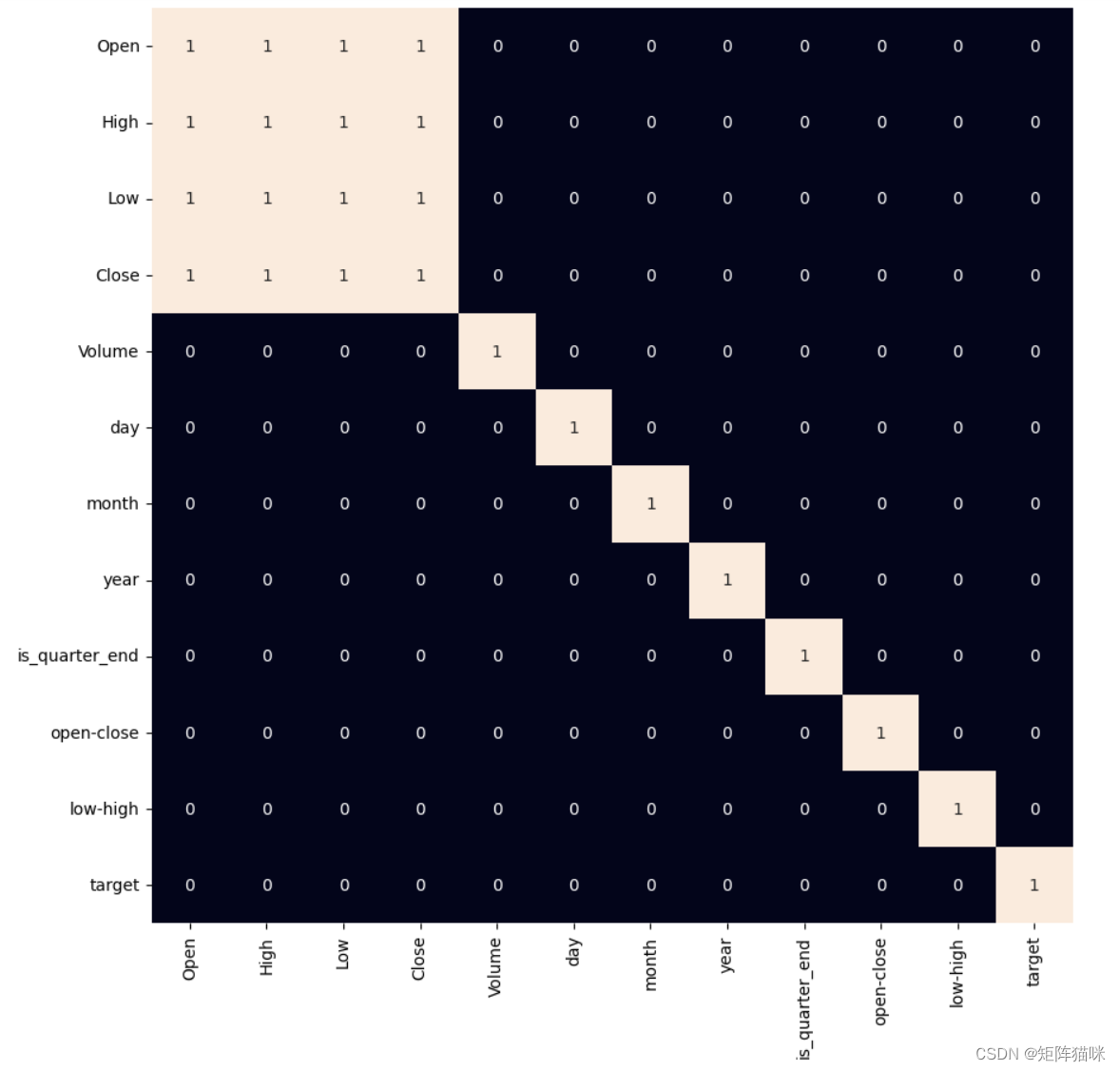
从上面的热图中,我们可以说 ohlc 之间存在非常明显的高度相关性,并且添加的功能彼此之间或以前提供的功能之间没有高度相关性,这意味着我们可以开始构建我们的模型。
4. 数据建模(randomforestclassifier)
4.1 数据准备(拆分为训练集和测试集)
features = df[['open-close', 'low-high', 'is_quarter_end']]
target = df['target']
scaler = standardscaler()
features = scaler.fit_transform(features)
x_train, x_valid, y_train, y_valid = train_test_split(
features, target, test_size=0.1, random_state=2022)
print(x_train.shape, x_valid.shape)
输出:
(2174, 3) (242, 3)
在选择要训练模型的特征后,我们应该对数据进行归一化,因为归一化数据会导致模型的稳定和快速训练。在整个数据以 90/10 的比例分成两部分之后,我们可以评估模型在看不见的数据上的性能。
4.2 模型构建与评估
现在是时候训练一些最先进的机器学习模型(逻辑回归、支持向量机、xgbclassifier),然后根据它们在训练和验证数据上的性能,我们将选择哪个 ml 模型更好地服务于手头的目的。
对于评估指标,我们将使用 roc-auc 曲线,但为什么会这样,因为我们希望它预测的是 0 到 1 之间的连续值,而不是预测 0 或 1 的硬概率。对于软概率,roc-auc 曲线通常用于衡量预测的准确性。
models = [logisticregression(), svc(kernel='poly', probability=true), xgbclassifier()]
for i in range(3):
models[i].fit(x_train, y_train)
print(f'{models[i]} : ')
print('training accuracy : ', metrics.roc_auc_score(
y_train, models[i].predict_proba(x_train)[:,1]))
print('validation accuracy : ', metrics.roc_auc_score(
y_valid, models[i].predict_proba(x_valid)[:,1]))
print()
输出:

在3个模型中,我们训练的xgbclassifier性能最高,但由于训练和验证精度的差异太大,它被修剪为过拟合。但在逻辑回归的情况下,情况并非如此。
现在,让我们为验证数据绘制一个混淆矩阵。
metrics.confusionmatrixdisplay.from_estimator(models[0], x_valid, y_valid)
plt.show()

我们可以观察到,最先进的 ml 模型所达到的准确性并不比以 50% 的概率进行简单的猜测好。造成这种情况的可能原因是缺乏数据或使用非常简单的模型来执行股票市场预测等复杂任务。
若要提高模型的准确度,接下来我们将尝试使用深度学习进行股票市场预测,在我们将探讨如何使用长短期记忆lstm预测股票市场
拓展阅读



发表评论