1. 高阶函数
1.1 定义高阶函数
高阶函数和lambda的关系是密不可分的。一些与集合相关的函数式api的用法,如map、filter函数等,kotlin的标准函数,如run、apply函数等。这几个函数有一个共同的特点:它们都会要求我们传入一个lambda表达式作为参数。像这种接收lambda参数的函数就可以称为具有函数式编程风格的api,而如果你想要定义自己的函数式api,那就得借助高阶函数来实现了.
如果一个函数接收另一个函数作为参数,或者返回值的类型是另一个函数,那么该函数就称为高阶函数。
一个函数怎么能接收另一个函数作为参数呢?这就涉及另外一个概念了:函数类型。我们知道,编程语言中有整型、布尔型等字段类型,而kotlin又增加了一个函数类型的概念。如果我们将这种函数类型添加到一个函数的参数声明或者返回值声明当中,那么这就是一个高阶函数了。
接下来我们就学习一下如何定义一个函数类型。不同于定义一个普通的字段类型,函数类型的语法规则是有点特殊的,基本规则如下:
(string, int) -> unit
既然是定义一个函数类型,那么最关键的就是要声明该函数接收什么参数,以及它的返回值是什么。因此,->左边的部分就是用来声明该函数接收什么参数的,多个参数之间使用逗号隔开,如果不接收任何参数,写一对空括号就可以了。而->右边的部分用于声明该函数的返回值是什么类型,如果没有返回值就使用unit,它大致相当于java中的void。
现在将上述函数类型添加到某个函数的参数声明或者返回值声明上,那么这个函数就是一个高
阶函数了,如下所示:
fun example(func: (string, int) -> unit) {
func("hello", 123)
}
可以看到,这里的example()函数接收了一个函数类型的参数,因此example()函数就是一个高阶函数。而调用一个函数类型的参数,它的语法类似于调用一个普通的函数,只需要在参数名的后面加上一对括号,并在括号中传入必要的参数即可。
高阶函数允许让函数类型的参数来决定函数的执行逻辑。即使是同一个高阶函数,只要传入不同的函数类型参数,那么它的执行逻辑和最终的返回结果就可能是完全不同的。类似于java中的回调函数,同样的参数,由于回调函数的实现不同,那么结果也是完全不同的,kotlin中的高阶函数把设置回调函数和调用回调函数放在了一起.
1.2 高阶函数的使用
如果每次调用任何高阶函数的时候都还得先定义一个与其函数类型参数相匹配的函数,这是不是有些太复杂了?因此kotlin还支持其他多种方式来调用高阶函数,比如lambda表达式、匿名函数、成员引用等。
回顾之前学习的apply函数,它可以用于给lambda表达式提供一个指定的上下文,当需要连续调用同一个对象的多个方法时,apply函数可以让代码变得更加精简,比如stringbuilder就是一个典型的例子。接下来我们就使用高阶函数模仿实现一个类似的功能。修改higherorderfunction.kt文件,在其中加入如下代码:
fun stringbuilder.build(block: stringbuilder.() -> unit): stringbuilder {
block()
return this
}
这里我们给stringbuilder类定义了一个build扩展函数,这个扩展函数接收一个函数类型参
数,并且返回值类型也是stringbuilder。
注意,这个函数类型参数的声明方式和我们前面学习的语法有所不同:它在函数类型的前面加上了一个stringbuilder. 的语法结构。这是什么意思呢?其实这才是定义高阶函数完整的语法规则,函数类型的前面加上classname. 就表示这个函数类型是定义在哪个类当中的。那么这里将函数类型定义到stringbuilder类当中有什么好处呢?好处就是当我们调用build函数时传入的lambda表达式将会自动拥有stringbuilder的上下文,同时这也是apply函数的实现方式。
现在我们就可以使用自己创建的build函数来简化stringbuilder构建字符串的方式了。
fun main() {
val list = listof("apple", "banana", "orange", "pear", "grape")
val result = stringbuilder().build {
append("start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("ate all fruits.")
}
println(result.tostring())
}
可以看到,build函数的用法和apply函数基本上是一模一样的,只不过我们编写的build函数目前只能作用在stringbuilder类上面,而apply函数是可以作用在所有类上面的。如果想实现apply函数的这个功能,需要借助于kotlin的泛型才行.
1.3 高阶函数的原理及内联函数
我们还是简单分析一下高阶函数的实现原理,使用刚num1andnum2()函数来举例,代码如下所示:
fun num1andnum2(num1: int, num2: int, operation: (int, int) -> int): int {
val result = operation(num1, num2)
return result
}
fun main() {
val num1 = 100
val num2 = 80
val result = num1andnum2(num1, num2) { n1, n2 ->
n1 + n2
}
}
可以看到,上述代码中调用了num1andnum2()函数,并通过lambda表达式指定对传入的两个整型参数进行求和。这段代码在kotlin中非常好理解,因为这是高阶函数最基本的用法。可是我们知道,kotlin的代码最终还是要编译成java字节码的,但java中并没有高阶函数的概念。
那么kotlin究竟使用了什么魔法来让java支持这种高阶函数的语法呢?这就要归功于kotlin强大
的编译器了。kotlin的编译器会将这些高阶函数的语法转换成java支持的语法结构,上述的kotlin代码大致会被转换成如下java代码:
public static int num1andnum2(int num1, int num2, function operation) {
int result = (int) operation.invoke(num1, num2);
return result;
}
public static void main() {
int num1 = 100;
int num2 = 80;
int result = num1andnum2(num1, num2, new function() {
@override
public integer invoke(integer n1, integer n2) {
return n1 + n2;
}
});
}
考虑到可读性,我对这段代码进行了些许调整,并不是严格对应了kotlin转换成的java代码。可
以看到,在这里num1andnum2()函数的第三个参数变成了一个function接口,这是一种kotlin内置的接口,里面有一个待实现的invoke()函数。而num1andnum2()函数其实就是调用了function接口的invoke()函数,并把num1和num2参数传了进去。在调用num1andnum2()函数的时候,之前的lambda表达式在这里变成了function接口的匿名类实现,然后在invoke()函数中实现了n1 + n2的逻辑,并将结果返回。
这就是kotlin高阶函数背后的实现原理。你会发现,原来我们一直使用的lambda表达式在底层
被转换成了匿名类的实现方式。这就表明,我们每调用一次lambda表达式,都会创建一个新的匿名类实例,当然也会造成额外的内存和性能开销。为了解决这个问题,kotlin提供了内联函数的功能,它可以将使用lambda表达式带来的运行时开销完全消除。
内联函数的用法非常简单,只需要在定义高阶函数时加上inline关键字的声明即可,如下所示:
inline fun num1andnum2(num1: int, num2: int, operation: (int, int) -> int): int {
val result = operation(num1, num2)
return result
}
内联函数的工作原理又是什么呢?其实并不复杂,就是kotlin编译器会将内联函数中的代码在编译的时候自动替换到调用它的地方,这样也就不存在运行时的开销了。
我们通过图例的方式来详细说明内联函数的代码替换过程。首先,kotlin编译器会将lambda表达式中的代码替换到函数类型参数调用的地方:

接下来,再将内联函数中的全部代码替换到函数调用的地方
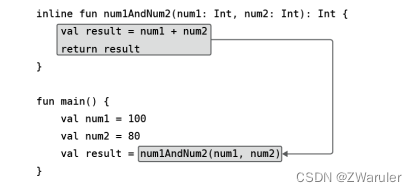
最终的代码就被替换成了如下图所示的样子

正是如此,内联函数才能完全消除lambda表达式所带来的运行时开销。在编译时,将lambda表达式中的实现代码替换到内联函数中,从而消除了额外的资源开销.
1.4 noinline与crossinline
接下来我们要讨论一些更加特殊的情况。比如,一个高阶函数中如果接收了两个或者更多函数类型的参数,这时我们给函数加上了inline关键字,那么kotlin编译器会自动将所有引用的lambda表达式全部进行内联。但是,如果我们只想内联其中的一个lambda表达式该怎么办呢?这时就可以使用noinline关键字了,如下所示:
inline fun inlinetest(block1: () -> unit, noinline block2: () -> unit) {
}
可以看到,这里使用inline关键字声明了inlinetest()函数,原本block1和block2这两
个函数类型参数所引用的lambda表达式都会被内联。但是我们在block2参数的前面又加上了
一个noinline关键字,那么现在就只会对block1参数所引用的lambda表达式进行内联了。这就是noinline关键字的作用。
前面我们已经解释了内联函数的好处,那么为什么kotlin还要提供一个noinline关键字来排除内联功能呢?这是因为内联的函数类型参数在编译的时候会被进行代码替换,因此它没有真正的参数属性。非内联的函数类型参数可以自由地传递给其他任何函数,因为它就是一个真实的参数,而内联的函数类型参数只允许传递给另外一个内联函数,这也是它最大的局限性。
另外,内联函数和非内联函数还有一个重要的区别,那就是内联函数所引用的lambda表达式
中是可以使用return关键字来进行函数返回的,而非内联函数只能进行局部返回, 这一点思考一下内联函数编译替换的过程即可理解。为了说明这个问题,我们来看下面的例子。
fun printstring(str: string, block: (string) -> unit) {
println("printstring begin")
block(str)
println("printstring end")
}
fun main() {
println("main start")
val str = ""
printstring(str) { s ->
println("lambda start")
if (s.isempty()) return@printstring
println(s)
println("lambda end")
}
println("main end")
}
这里定义了一个叫作printstring()的高阶函数,用于在lambda表达式中打印传入的字符串参数。但是如果字符串参数为空,那么就不进行打印。注意,lambda表达式中是不允许直接使用return关键字的,这里使用了return@printstring的写法,表示进行局部返回,并且不再执行lambda表达式的剩余部分代码。现在我们就刚好传入一个空的字符串参数,运行程序,打印结果如图所示。
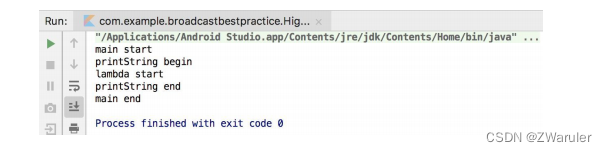
可以看到,除了lambda表达式中return@printstring语句之后的代码没有打印,其他的日志是正常打印的,说明return@printstring确实只能进行局部返回。但是如果我们将printstring()函数声明成一个内联函数,那么情况就不一样了,如下所示:
inline fun printstring(str: string, block: (string) -> unit) {
println("printstring begin")
block(str)
println("printstring end")
}
fun main() {
println("main start")
val str = ""
printstring(str) { s ->
println("lambda start")
if (s.isempty()) return
println(s)
println("lambda end")
}
println("main end")
}
现在printstring()函数变成了内联函数,我们就可以在lambda表达式中使用return关键字了。此时的return代表的是返回外层的调用函数,也就是main()函数,如果想不通为什么的话,可以回顾一下在上一小节中学习的内联函数的代码替换过程(return语句直接替换到main()函数中了,终止了main()函数的允许)。现在重新运行一下程序,打印结果如图6.17所示。
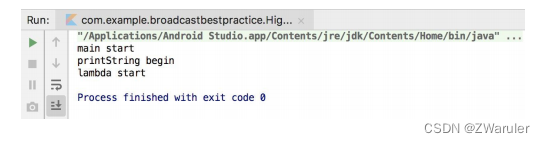
将高阶函数声明成内联函数是一种良好的编程习惯,事实上,绝大多数高阶函数是可以直接声
明成内联函数的,但是也有少部分例外的情况。观察下面的代码示例:
inline fun runrunnable(block: () -> unit) {
val runnable = runnable {
block()
}
runnable.run()
}
这段代码在没有加上inline关键字声明的时候绝对是可以正常工作的,但是在加上inline关
键字之后就会提示如图所示的错误。

这个错误出现的原因解释起来可能会稍微有点复杂。首先,在runrunnable()函数中,我们创建了一个runnable对象,并在runnable的lambda表达式中调用了传入的函数类型参数。而lambda表达式在编译的时候会被转换成匿名类的实现方式,也就是说,上述代码实际上是在匿名类中调用了传入的函数类型参数。而内联函数所引用的lambda表达式允许使用return关键字进行函数返回,但是由于我们是在匿名类中调用的函数类型参数,此时是不可能进行外层调用函数返回的,最多只能对匿名类中的函数调用进行返回,因此这里就提示了上述错误。
也就是说,如果我们在高阶函数中创建了另外的lambda或者匿名类的实现,并且在这些实现中调用函数类型参数,此时再将高阶函数声明成内联函数,就一定会提示错误。那么是不是在这种情况下就真的无法使用内联函数了呢?也不是,比如借助crossinline关键字就可以很好地解决这个问题:
inline fun runrunnable(crossinline block: () -> unit) {
val runnable = runnable {
block()
}
runnable.run()
}
可以看到,这里在函数类型参数的前面加上了crossinline的声明,代码就可以正常编译通过了。
那么这个crossinline关键字又是什么呢?前面我们已经分析过,之所以会提示错误,就是因为内联函数的lambda表达式中允许使用return关键字,和高阶函数的匿名类实现中不允许使用return关键字之间造成了冲突。而crossinline关键字就像一个契约,它用于保证在内联函数的lambda表达式中一定不会使用return关键字,这样冲突就不存在了,问题也就巧妙地解决了。
声明了crossinline之后,我们就无法在调用runrunnable函数时的lambda表达式中使用return关键字进行函数返回了,但是仍然可以使用return@runrunnable的写法进行局部返回。总体来说,除了在return关键字的使用上有所区别之外,crossinline保留了内联函数的其他所有特性。
1.5 总结
高阶函数就是参数中有函数类型参数的函数. 在调用时由于会产生额外的接口创建资源消耗,为了避免此缺点,引入inline内联函数的概念, 通过在编译时进行代码替换来避免额外的资源消耗.
内联函数中的函数类型参数不能像普通参数那样随意传递到其他函数中(因为编译时进行了代码替换,实际中并不存在此函数类型参数了),所以为了解决此缺点,引入noinline关键字,表示对内联函数中的函数类型参数并不进行代码替换.
crossinline关键字是为了解决在高阶内联函数中,创建了另外的lambda或者匿名类的实现,并且在这些实现中调用函数类型参数导致的错误(主要是内联函数进行代码替换导致的return关键字的使用问题).


发表评论