resnet网络简介
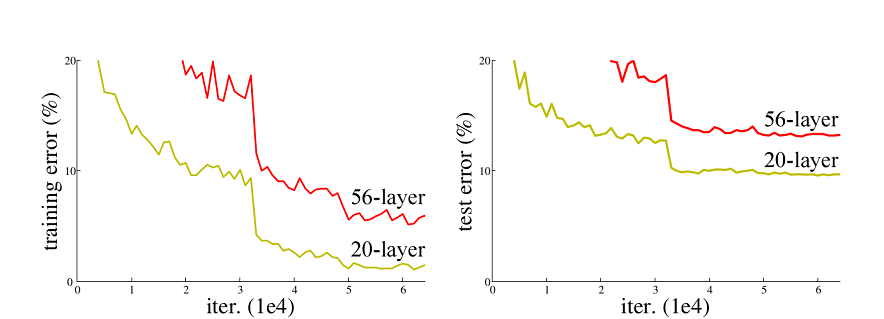
resnet50网络是由微软研究院的何恺明等人在2015年提出的,并在ilsvrc2015图像分类竞赛中获得了第一名。在resnet提出之前,传统的卷积神经网络依赖于层层堆叠的卷积层和池化层,但当网络深度增加时,会出现退化问题。如下图所示,在cifar-10数据集上,56层网络的训练误差和测试误差比20层网络更大,说明网络深度增加并未带来预期的性能提升。
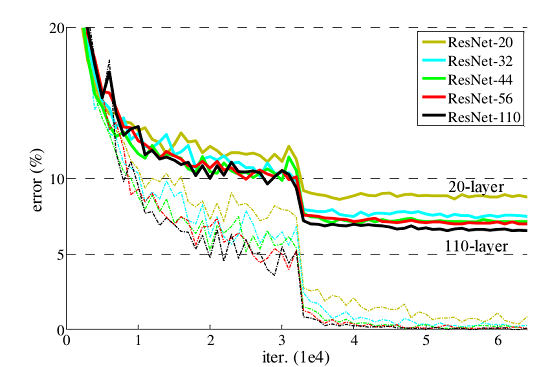
resnet通过引入残差网络结构(residual network)有效地减轻了退化问题,使得网络深度可以突破1000层。如下图所示,使用resnet网络的训练误差和测试误差随着网络层数的增加而减小。
数据集准备与加载
cifar-10数据集包含60000张32x32的彩色图像,分为10个类别,每类有6000张图像。数据集分为50000张训练图片和10000张评估图片。我们首先下载并解压数据集,然后使用mindspore.dataset.cifar10dataset接口加载数据集,并进行相关图像增强操作。
图像增强操作(如随机裁剪和水平翻转)有助于提高模型的泛化能力,避免过拟合。具体来说,随机裁剪可以模拟不同的拍摄角度和距离,水平翻转可以增加数据的多样性,这些操作可以使模型在训练过程中看到更多的图像变体,从而提高其在未知数据上的表现能力。
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./datasets-cifar10-bin", kind="tar.gz", replace=true)
下载后的数据集目录结构如下:
datasets-cifar10-bin/cifar-10-batches-bin
├── batches.meta.text
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
接下来,加载数据集并进行图像增强:
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
data_dir = "./datasets-cifar10-bin/cifar-10-batches-bin"
batch_size = 256
image_size = 32
workers = 4
num_classes = 10
def create_dataset_cifar10(dataset_dir, usage, resize, batch_size, workers):
data_set = ds.cifar10dataset(dataset_dir=dataset_dir, usage=usage, num_parallel_workers=workers, shuffle=true)
trans = []
if usage == "train":
trans += [vision.randomcrop((32, 32), (4, 4, 4, 4)), vision.randomhorizontalflip(prob=0.5)]
trans += [vision.resize(resize), vision.rescale(1.0 / 255.0, 0.0), vision.normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]), vision.hwc2chw()]
target_trans = transforms.typecast(mstype.int32)
data_set = data_set.map(operations=trans, input_columns='image', num_parallel_workers=workers)
data_set = data_set.map(operations=target_trans, input_columns='label', num_parallel_workers=workers)
data_set = data_set.batch(batch_size)
return data_set
dataset_train = create_dataset_cifar10(dataset_dir=data_dir, usage="train", resize=image_size, batch_size=batch_size, workers=workers)
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_cifar10(dataset_dir=data_dir, usage="test", resize=image_size, batch_size=batch_size, workers=workers)
step_size_val = dataset_val.get_dataset_size()
对cifar-10训练数据集进行可视化:
import matplotlib.pyplot as plt
import numpy as np
data_iter = next(dataset_train.create_dict_iterator())
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
print(f"image shape: {images.shape}, label shape: {labels.shape}")
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
image_trans = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(f"{classes[labels[i]]}")
plt.imshow(image_trans)
plt.axis("off")
plt.show()

构建resnet50网络
残差网络结构(residual network)是resnet网络的核心。resnet使用残差网络结构有效地减轻了退化问题,实现了更深的网络结构设计,提高了网络的训练精度。
构建残差网络结构
残差网络结构由两个分支构成:一个主分支,一个shortcuts(图中弧线表示)。主分支通过堆叠一系列的卷积操作得到,shortcuts从输入直接到输出,主分支输出的特征矩阵 f ( x ) f(x) f(x)加上shortcuts输出的特征矩阵 x x x得到 f ( x ) + x f(x)+x f(x)+x,通过relu激活函数后即为残差网络最后的输出。
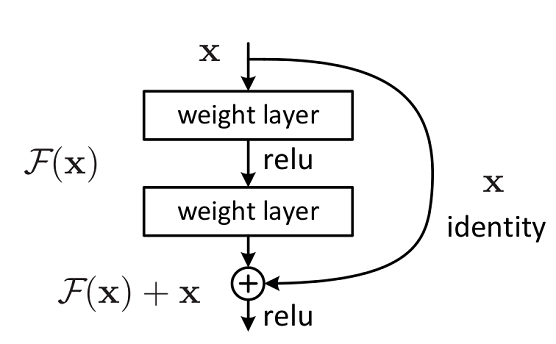
残差网络结构主要有两种:building block和bottleneck。
building block
building block结构图如下图所示,主分支有两层卷积网络结构:
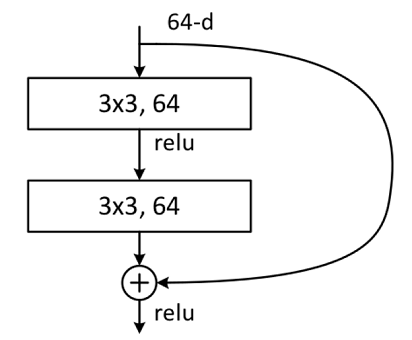
代码实现如下:
from typing import type, union, list, optional
import mindspore.nn as nn
from mindspore.common.initializer import normal
weight_init = normal(mean=0, sigma=0.02)
gamma_init = normal(mean=1, sigma=0.02)
class residualblockbase(nn.cell):
expansion: int = 1
def __init__(self, in_channel: int, out_channel: int, stride: int = 1, norm: optional[nn.cell] = none, down_sample: optional[nn.cell] = none) -> none:
super(residualblockbase, self).__init__()
if not norm:
self.norm = nn.batchnorm2d(out_channel)
else:
self.norm = norm
self.conv1 = nn.conv2d(in_channel, out_channel, kernel_size=3, stride=stride, weight_init=weight_init)
self.conv2 = nn.conv2d(in_channel, out_channel, kernel_size=3, weight_init=weight_init)
self.relu = nn.relu()
self.down_sample = down_sample
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm(out)
if self.down_sample is not none:
identity = self.down_sample(x)
out += identity
out = self.relu(out)
return out
bottleneck
bottleneck结构图如下图所示:
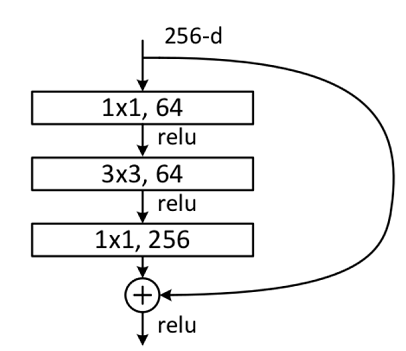
代码实现如下:
class residualblock(nn.cell):
expansion = 4
def __init__(self, in_channel: int, out_channel: int, stride: int = 1, down_sample: optional[nn.cell] = none) -> none:
super(residualblock, self).__init__()
self.conv1 = nn.conv2d(in_channel, out_channel, kernel_size=1, weight_init=weight_init)
self.norm1 = nn.batchnorm2d(out_channel)
self.conv2 = nn.conv2d(out_channel, out_channel, kernel_size=3, stride=stride, weight_init=weight_init)
self.norm2 = nn.batchnorm2d(out_channel)
self.conv3 = nn.conv2d(out_channel, out_channel * self.expansion, kernel_size=1, weight_init=weight_init)
self.norm3 = nn.batchnorm2d(out_channel * self.expansion)
self.relu = nn.relu()
self.down_sample = down_sample
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.norm3(out)
if self.down_sample is not none:
identity = self.down_sample(x)
out += identity
out = self.relu(out)
return out
构建resnet50网络
resnet50网络通过引入残差网络结构(residual block和bottleneck)有效地减轻了深层网络中的退化问题。我们通过定义这些残差块,逐层构建resnet50网络。残差块的核心思想是通过引入快捷连接(shortcut connection),使得网络能够学习到输入和输出之间的残差(residual),而不是直接学习复杂的映射函数。这种设计使得梯度更容易在深层网络中传播,从而缓解了梯度消失问题,使得更深的网络能够被成功训练。
resnet50网络的层结构如下图所示:
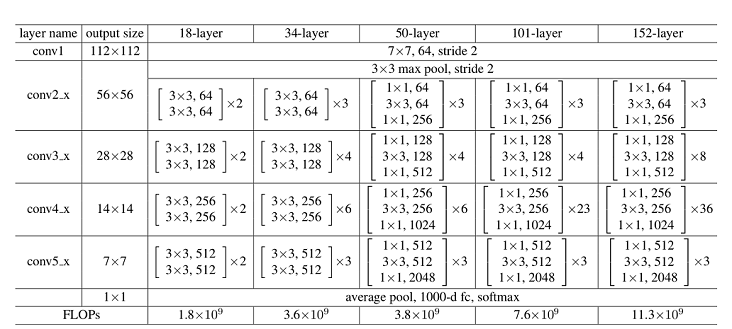
代码实现如下:
def make_layer(last_out_channel, block: type[union[residualblockbase, residualblock]], channel: int, block_nums: int, stride: int = 1):
down_sample = none
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.sequentialcell([
nn.conv2d(last_out_channel, channel * block.expansion, kernel_size=1, stride=stride, weight_init=weight_init),
nn.batchnorm2d(channel * block.expansion, gamma_init=gamma_init)
])
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
in_channel = channel * block.expansion
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
return nn.sequentialcell(layers)
from mindspore import load_checkpoint, load_param_into_net
class resnet(nn.cell):
def __init__(self, block: type[union[residualblockbase, residualblock]], layer_nums: list[int], num_classes: int, input_channel: int) -> none:
super(resnet, self).__init__()
self.relu = nn.relu()
self.conv1 = nn.conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
self.norm = nn.batchnorm2d(64)
self.max_pool = nn.maxpool2d(kernel_size=3, stride=2, pad_mode='same')
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
self.avg_pool = nn.avgpool2d()
self.flatten = nn.flatten()
self.fc = nn.dense(in_channels=input_channel, out_channels=num_classes)
def construct(self, x):
x = self.conv1(x)
x = self.norm(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
def _resnet(model_url: str, block: type[union[residualblockbase, residualblock]], layers: list[int], num_classes: int, pretrained: bool, pretrained_ckpt: str, input_channel: int):
model = resnet(block, layers, num_classes, input_channel)
if pretrained:
download(url=model_url, path=pretrained_ckpt, replace=true)
param_dict = load_checkpoint(pretrained_ckpt)
load_param_into_net(model, param_dict)
return model
def resnet50(num_classes: int = 1000, pretrained: bool = false):
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./loadpretrainedmodel/resnet50_224_new.ckpt"
return _resnet(resnet50_url, residualblock, [3, 4, 6, 3], num_classes, pretrained, resnet50_ckpt, 2048)
模型训练与评估
使用预训练的resnet50模型进行微调可以加速训练过程并提高模型性能。预训练模型是在大规模数据集(如imagenet)上训练得到的,这意味着它已经学习到了很多有用的特征。通过在cifar-10数据集上进行微调,我们可以在保留这些预训练特征的基础上,进一步优化模型以适应新的数据。我们定义了优化器和损失函数,通过逐个epoch打印训练的损失值和评估精度,监控模型的训练过程,并保存评估精度最高的模型。学习率的选择和调整(如使用余弦退火学习率)也是训练过程中的关键因素,它可以帮助模型逐步收敛到一个更优的解。
我们将使用预训练的resnet50模型进行微调。调用resnet50构造resnet50模型,并设置pretrained参数为true,将会自动下载resnet50预训练模型,并加载预训练模型中的参数到网络中。然后定义优化器和损失函数,逐个epoch打印训练的损失值和评估精度,并保存评估精度最高的ckpt文件到当前路径的./bestcheckpoint下。
network = resnet50(pretrained=true)
in_channel = network.fc.in_channels
fc = nn.dense(in_channels=in_channel, out_channels=10)
network.fc = fc
num_epochs = 5
lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001, total_step=step_size_train * num_epochs, step_per_epoch=step_size_train, decay_epoch=num_epochs)
opt = nn.momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)
loss_fn = nn.softmaxcrossentropywithlogits(sparse=true, reduction='mean')
def forward_fn(inputs, targets):
logits = network(inputs)
loss = loss_fn(logits, targets)
return loss
grad_fn = ms.value_and_grad(forward_fn, none, opt.parameters)
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
import os
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
best_acc = 0
best_ckpt_dir = "./bestcheckpoint"
best_ckpt_path = "./bestcheckpoint/resnet50-best.ckpt"
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
import mindspore.ops as ops
def train(data_loader, epoch):
losses = []
network.set_train(true)
for i, (images, labels) in enumerate(data_loader):
loss = train_step(images, labels)
if i % 100 == 0 or i == step_size_train - 1:
print('epoch: [%3d/%3d], steps: [%3d/%3d], train loss: [%5.3f]' % (epoch + 1, num_epochs, i + 1, step_size_train, loss))
losses.append(loss)
return sum(losses) / len(losses)
def evaluate(data_loader):
network.set_train(false)
correct_num = 0.0
total_num = 0.0
for images, labels in data_loader:
logits = network(images)
pred = logits.argmax(axis=1)
correct = ops.equal(pred, labels).reshape((-1, ))
correct_num += correct.sum().asnumpy()
total_num += correct.shape[0]
acc = correct_num / total_num
return acc
print("start training loop ...")
for epoch in range(num_epochs):
curr_loss = train(data_loader_train, epoch)
curr_acc = evaluate(data_loader_val)
print("-" * 50)
print("epoch: [%3d/%3d], average train loss: [%5.3f], accuracy: [%5.3f]" % (epoch+1, num_epochs, curr_loss, curr_acc))
print("-" * 50)
if curr_acc > best_acc:
best_acc = curr_acc
ms.save_checkpoint(network, best_ckpt_path)
print("=" * 80)
print(f"end of validation the best accuracy is: {best_acc: 5.3f}, save the best ckpt file in {best_ckpt_path}", flush=true)

可视化模型预测
通过可视化模型对测试数据集的预测结果,我们可以直观地了解模型的分类效果。预测正确的标签以蓝色显示,预测错误的标签以红色显示,有助于发现模型的不足之处。这种可视化方法不仅可以帮助我们评估模型的性能,还可以用于诊断模型的错误。例如,如果模型在某些特定类别上表现不佳,我们可以进一步分析这些类别的特征,并采取相应的措施(如增加这些类别的训练数据或进行更有针对性的图像增强)来改进模型。
import matplotlib.pyplot as plt
def visualize_model(best_ckpt_path, dataset_val):
num_class = 10
net = resnet50(num_class)
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
data = next(dataset_val.create_dict_iterator())
images = data["image"]
labels = data["label"]
outputs = net(images)
preds = outputs.argmax(axis=1)
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
plt.figure(figsize=(15, 10))
for i in range(6):
plt.subplot(2, 3, i + 1)
image_trans = np.transpose(images[i].asnumpy(), (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
plt.imshow(image_trans)
plt.axis("off")
color = "blue" if preds[i] == labels[i] else "red"
plt.title(f"pred: {classes[preds[i]]}\ntrue: {classes[labels[i]]}", color=color)
plt.show()
visualize_model(best_ckpt_path, dataset_val)
通过上述代码,我们可以可视化模型对cifar-10测试数据集的预测结果。预测正确的标签会以蓝色显示,预测错误的标签会以红色显示。

发表评论