前言
随着学习的深入,感觉愈发缺乏满足感。刚好看到微信语音转文字的功能,经网上查询,发现可以使用 qt + 百度语音识别技术 实现这一功能。当然,由于使用的 qt 和 百度语音识别,那么看不到一些具体的底层实现,但操作起来相对比较简单。俗话说:“没吃过猪肉,还没见过猪跑?”,我打算先看看别人已有的技术,搬过来跑一下,然后再进行深入学习,同时也可以复习一下 qt 相关知识。文章如有写错或者代码可优化,欢迎大家指正!
qt 采集麦克风 pcm 音频裸数据
基础知识
pcm(pulse code modulation,脉冲编码调制)⾳频数据是未经压缩的⾳频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准数字⾳频数据。
描述pcm数据的6个参数:
- sample rate : 采样频率。8khz(电话)、44.1khz(cd)、48khz(dvd)。
- sample size : 量化位数。通常该值为16-bit。
- number of channels : 通道个数。常⻅的⾳频有⽴体声(stereo)和单声道(mono)两种类型,⽴体声包含左声道和右声道。另外还有环绕⽴体声等其它不太常⽤的类型。
- sign : 表示样本数据是否是有符号位,⽐如⽤⼀字节表示的样本数据,有符号的话表示范围为-128 ~127,⽆符号是0 ~ 255。有符号位16bits数据取值范围为-32768~32767。
- byte ordering : 字节序。字节序是little-endian还是big-endian。通常均为little-endian。
- integer or floating point : 整形或浮点型。⼤多数格式的pcm样本数据使⽤整形表示,⽽在⼀些对精度要求⾼的应⽤⽅⾯,使⽤浮点类型表示pcm样本数据(浮点数 float值域为 [-1.0, 1.0])。
环境配置
第一步: 新建一个qwidget项目
第二步: 项目名与存放路径自选(然后一直下一步)
第三步: 在.pro文件中添加模块
第四步: 新建一个c++ class(因为采集麦克风只是一个小功能,我们还有其他的功能),名字可自取。这里类名我起的是 audiocapture
代码
audiocapture.h
#ifndef audiocapture_h
#define audiocapture_h
#include <qobject>
#include <qaudioinput>
#include <qfile>
#include <qmessagebox>
class audiocapture : public qobject
{
q_object
public:
explicit audiocapture(qobject *parent = nullptr);
void startcapture(qstring filename); //开始录音,文件名由调用者传入
void stopcapture(); //结束录音
~audiocapture(); //析构函数,释放相关资源
signals:
private:
qaudioinput *paudioinput; //录音对象
qfile *pfile; //存取文件
};
#endif // audiocapture_h
audiocapture.cpp
#include "audiocapture.h"
audiocapture::audiocapture(qobject *parent) : qobject(parent)
{
//初始化
paudioinput = nullptr;
pfile = nullptr;
}
//开始录音
void audiocapture::startcapture(qstring filename)
{
//打开默认的音频输入设备
qaudiodeviceinfo audiodeviceinfo = qaudiodeviceinfo::defaultinputdevice();
//判断本地是否有录音设备
if(audiodeviceinfo.isnull() == false)
{
/* 创建文件并打开 */
pfile = new qfile;
pfile->setfilename(filename);
pfile->open(qiodevice::writeonly | qiodevice::truncate);
// 设置音频文件格式
qaudioformat format;
// 设置采样频率,常见的有16000、44100、48000
format.setsamplerate(16000);
// 设置通道数,单声道、双声道、5.1声道
format.setchannelcount(1);
// 设置每次采样得到的样本数据位值,8位、16位
format.setsamplesize(16);
// 设置编码方法
format.setcodec("audio/pcm");
// 判断当前设备设置是否支持该音频格式
if(audiodeviceinfo.isformatsupported(format) == null)
{
format = audiodeviceinfo.nearestformat(format);
}
// 创建录音对象
paudioinput = new qaudioinput(format, this);
// 开始录音
paudioinput->start(pfile);
}
else
{
// 没有录音设备
qmessagebox::information(null, tr("record"), tr("current no record device"));
}
}
void audiocapture::stopcapture()
{
if(paudioinput != null)
{
// 停止录音
paudioinput->stop();
}
if(pfile != null)
{
// 关闭文件
pfile->close();
delete pfile;
pfile = nullptr;
}
}
audiocapture::~audiocapture()
{
//释放资源
if(paudioinput != nullptr)
{
delete paudioinput;
paudioinput = nullptr;
}
if(pfile != nullptr)
{
delete pfile;
pfile = nullptr;
}
}
widget.h
#ifndef widget_h
#define widget_h
#include <qwidget>
#include "audiocapture.h"
qt_begin_namespace
namespace ui { class widget; }
qt_end_namespace
class widget : public qwidget
{
q_object
public:
widget(qwidget *parent = nullptr);
~widget();
private slots:
void on_startptn_clicked(); // 点击start按钮后触发的槽函数
void on_stopptn_clicked(); // 点击stop按钮后触发的槽函数
private:
ui::widget *ui; //操作界面上的相关控件
audiocapture myaudiocapture; //录音功能封装对象
};
#endif // widget_h
widget.cpp
#include "widget.h"
#include "ui_widget.h"
widget::widget(qwidget *parent)
: qwidget(parent)
, ui(new ui::widget)
{
ui->setupui(this);
ui->startptn->setenabled(true); //start按钮初始化可用
ui->stopptn->setenabled(false); //stop按钮初始化不可用
}
widget::~widget()
{
delete ui;
}
//点击start按钮后触发的槽函数
void widget::on_startptn_clicked()
{
qstring filepath = ui->filepath->text(); //获取用户输入地址
/* 判断用户是否输入地址 */
if(filepath == "")
{
qmessagebox::information(null, "information", "please input the filepath to save!");
return;
}
/* 点击start后禁用start,开放stop按钮 */
ui->startptn->setenabled(false);
ui->stopptn->setenabled(true);
myaudiocapture.startcapture(filepath); //开始录音
}
//点击stop按钮后触发的槽函数
void widget::on_stopptn_clicked()
{
/* 点击stop后禁用stop,开放start按钮 */
ui->startptn->setenabled(true);
ui->stopptn->setenabled(false);
myaudiocapture.stopcapture(); //结束录音
}
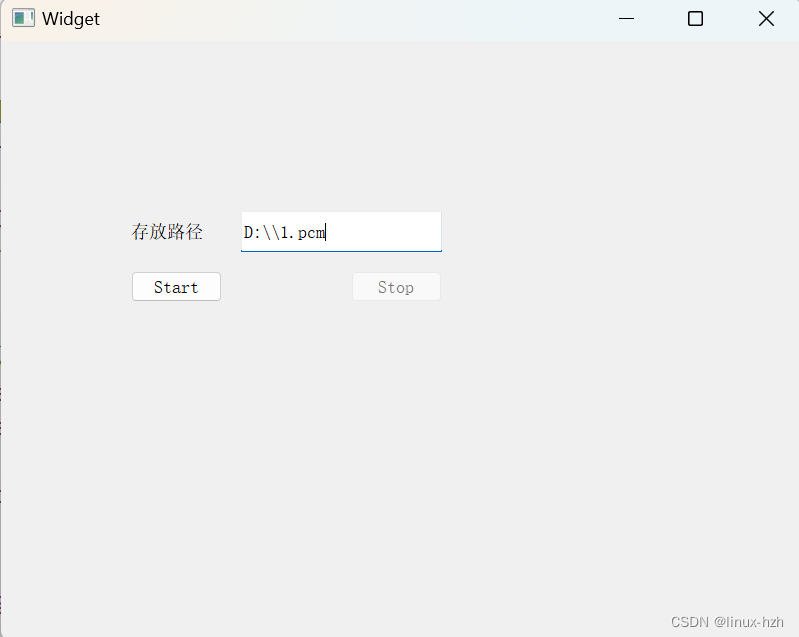
运行时界面ui(仅供测试,不够美观)
播放 pcm 数据
由于vlc播放器无法直接播放pcm音频裸数据,这里使用ffplay来播放(也可使用代码播放)
这里的参数设置需与代码中的设置一样,否则音效不对。
使用 qaudiooutput 来播放 pcm 音频数据
主要代码
//设置音频输出格式
qaudioformat fmt;
//设置采样率
fmt.setsamplerate(44100);
//设置采样位数
fmt.setsamplesize(16);
//设置声道数
fmt.setchannelcount(1);
//设置解码方式
fmt.setcodec("audio/pcm");
// 设定字节序,以小端模式播放音频文件
fmt.setbyteorder(qaudioformat::littleendian);
// 设定采样类型。根据采样位数来设定。
fmt.setsampletype(qaudioformat::unsignedint);
// 创建qaudiooutput对象并初始化
qaudiooutput *out = new qaudiooutput(fmt);
// 调用start函数后,返回qiodevice对象的地址
qiodevice *io = out->start();
//获取设备播放一个周期所需要的字节数
int size = out->periodsize();
//创建缓冲区
char *buf = new char[size];
//以二进制只读方式打开pcm文件
file *fp = fopen("d:/1.pcm", "rb");
//判断是否读到末尾
while(!feof(fp))
{
//判断空闲空间是否小于一个周期的大小,如果是则说明cpu处理速度太快,得等一等。
if(out->bytesfree() < size)
{
qthread::msleep(1);
continue;
}
int len = fread(buf, 1, size, fp);
//判断是否成功读入
if(len <= 0)
{
break;
}
//这里相当于写入到电脑声卡的缓冲区,接下来的工作由声卡完成,与我们无关
io->write(buf, len);
}
fclose(fp); //关闭文件
//资源释放
if(null != buf)
{
delete buf;
buf = null;
}
if(null != out)
{
delete out;
out = null;
}
语音识别
百度智能云网址: https://cloud.baidu.com/product/speech.html?track=cf3e1b9d08c41e54e7f0ace5828291cce549454e8c470208
第一步: 点击右上角控制台,并完成登录
第二步: 点击右上角三条杠,然后选中语音技术
第三步: 概览中点击免费尝鲜
第四步: 选中短语音识别-普通话,然后左下角点击0元领取(这里我已经领过了,所以没有这个选项了)

第五步: 点击应用列表,然后创建应用,应用名称随意,应用归属选择个人即可,然后添加一些描述,创建即可(这里我昨天实验时创建过一个了)
第六步: 复制 apikey 和 secretkey

整个语音识别的逻辑分析
第一步: qt中使用qaudioinput进行麦克风采集pcm音频数据
第二步: 通过http的post方式将音频数据提交给百度后台进行语音识别
第三步: 百度返回识别后的数据,将数据显示到文本框中。
语音识别
网络请求主要代码
bool httppost::postmsg(qstring url, qmap<qstring, qstring> headerdata, qbytearray requestdata, qbytearray &replydata)
{
//发送请求的对象
qnetworkaccessmanager manager;
//请求对象
qnetworkrequest request;
request.seturl(url);
//设置请求参数
qmapiterator<qstring, qstring> it(headerdata);
while(it.hasnext())
{
it.next();
request.setrawheader(it.key().tolatin1(),it.value().tolatin1());
}
qnetworkreply *reply = manager.post(request, requestdata);
qeventloop loop;
//一旦服务器返回,reply会发出信号
connect(reply, &qnetworkreply::finished, &loop, &qeventloop::quit);
loop.exec();
//死循环,reply发出信号,结束循环
//判断是否响应成功
if(reply != nullptr && reply->error() == qnetworkreply::noerror)
{
replydata = reply->readall();
qdebug() << replydata;
return true;
}
else
{
qdebug() << "请求失败";
return false;
}
}
百度的接口相关设置
//获取access_token相关
const qstring baidutokenurl = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=%1&client_secret=%2&";
const qstring client_id = 刚才复制的apikey;
const qstring client_secret = 刚才复制的secretkey;
//普通话测试
const qstring baiduspeechurl = "http://vop.baidu.com/server_api?dev_pid=1537&cuid=%1&token=%2";
语音识别主要代码
qstring speechrecognition::speechidentify(qstring filename)
{
//获取token
qstring tokenurl = qstring(baidutokenurl).arg(client_id).arg(client_secret);
qmap<qstring, qstring> headers;
headers.insert(qstring("content-type"), qstring("audio/pcm;rate=16000"));
qbytearray requestdata; //发送的内容
qbytearray replydata; //服务器返回的内容
httppost httputil; //封装的网络请求类
bool success = httputil.postmsg(tokenurl, headers, requestdata, replydata);
//判断是否请求成功
if(success)
{
qstring key = "access_token";
//获取到access_token(通过json数据格式解析)
accesstoken = getjsonvalue(replydata, key);
qdebug() << "----------------" << endl;
qdebug() << accesstoken << endl;
}
else return "";
//语言识别
qstring baiduspeech = qstring(baiduspeechurl.arg("laptop-71ln9b3q").arg(accesstoken));
//把文件转化为qbytearray
qfile file;
file.setfilename(filename);
file.open(qiodevice::readonly);
requestdata = file.readall();
file.close();
replydata.clear();
//再次发起http请求
bool result = httputil.postmsg(baiduspeech, headers,requestdata,replydata);
//判断是否请求成功
if(result == true)
{
qstring key = "result";
qstring text = getjsonvalue(replydata,key); //获取识别后的文字
return text;
}
else
{
qmessagebox::warning(null, "识别提示", "识别失败");
return "";
}
}
qstring speechrecognition::getjsonvalue(qbytearray ba, qstring key)
{
qjsonparseerror parseerror;
qjsondocument jsondocument = qjsondocument::fromjson(ba, &parseerror);
if(parseerror.error == qjsonparseerror::noerror)
{
if(jsondocument.isobject())
{
//jsondocument转化成json对象
qjsonobject jsonobj = jsondocument.object();
//判断是否包含key
if(jsonobj.contains(key))
{
qjsonvalue jsonval = jsonobj.value(key);
if(jsonval.isstring()) //字符串
{
return jsonval.tostring();
}
else if(jsonval.isarray()) //数组
{
qjsonarray arr = jsonval.toarray();
qjsonvalue jv = arr.at(0);
return jv.tostring();
}
}
}
}
return "";
}
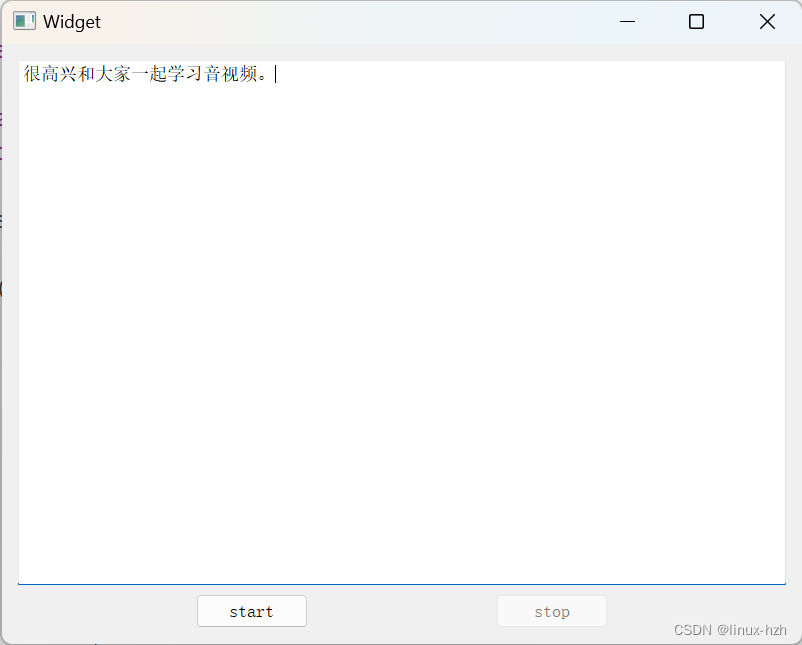
效果展示
当点击start按钮后,语音描述"很高兴和大家一起学习音视频"
点击stop后,文本框内显示文字"很高兴和大家一起学习音视频"
过程中的一些坑(个人遇到的主要的坑)
- 音频采样参数必须一致,否则百度只会识别出嗯嗯嗯等一系列奇怪的词语
- 注意采样频率目前百度语音识别支持16000,使用其他的如44100/48000等会报错
- 注意.pro文件中要添加network模块,否则根本发送不出去,也就是说百度根本收不到,奇怪的是qt没给我直接报错,虽然没有提示,但也还是一点一点写了,结果发现根本没发送出去。



发表评论