论文摘要
软件漏洞对互联网会造成灾难性的影响,类似codered和slammer这类的蠕虫病毒可以在数小时甚至数分钟内危害数十万台主机,造成巨大的损失。为了抵御这种互联网攻击,需要一种能够快速且自动的攻击检测和过滤机制。
这篇论文提出了一种动态污点分析工具taintcheck用于自动检测通过内存重写进行漏洞利用的大多数网络攻击,该工具不需要对源码进行特殊编译,而是在程序运行时执行二进制重写来实现动态污点分析。研究和实验表明taintcheck可以检测多种类型的漏洞利用且都没有产生误报,基于该工具还可以改进对攻击行为的自动签名生成。
1 背景介绍
蠕虫病毒能够在短时间内快速攻击大量的互联网主机,为应对这类安全风险需要有一种自动检测和防御机制。首先,这种自动检测应该很容易部署,且有较低的误报和漏报,能够检测大多数漏洞。其次,一旦新的漏洞利用被发现,能够计算出攻击签名进行高效筛选,检查后续网络流量中是否含有类似攻击。
为了做到上述要求,需要如下两个关键技术:
- 细颗粒度的攻击检测器
将攻击检测的方法粗略地分为两种类型:粗颗粒度的和细颗粒度的。其中,粗颗粒度的方法检测异常的行为,例如网络端口扫描,关键系统调用,敏感请求内容等,这些技巧简单实用且屏蔽了复杂的程序架构。而细颗粒度的方法则深入到程序内部,了解引起漏洞的原因,提供更加详细的信息,掌握该漏洞是如何被利用的,从而构建模式以规避更多类似的攻击手段。
- 自动化的攻击签名工具
由于细颗粒度的检测器是十分昂贵的,不太可能在每一台主机上都进行部署。一旦新的利用攻击被发现,主机需要能够快速地进行筛选和识别。传统的基于载荷内容的攻击签名,通常采用手动构造签名维护一个数据库,需要利用检测器来自动地分析漏洞利用以及生成攻击签名。
这篇论文开发的动态污点分析工具taintcheck,可以在不需求源码的条件下,可靠地检测大多数针对内存的重写攻击,并且没有发现已知的误报,同时允许基于攻击签名生成实现自动化的语义分析。
2 taintcheck设计
攻击者想要程序错误执行,会让程序接收其特殊构造的值,而不是来源于可信的输入。论文将来自于外部的不可信的输入,及其通过算术运算派生的数据都标记为tainted,然后监控程序执行来跟踪被污染数据的传播。传统方法通过检测攻击者是否对关键内存部分进行重写来发现攻击,污点分析则是追踪被污染的数据是否相关的重写函数调用来发现攻击,因而可以检测更大范围的攻击类型。
2.1 工具模型
taintcheck将程序运行在虚拟机环境中,依靠valgrind工具来执行动态污点分析。valgrind是一个开源的仿真器,可用于进行内存调试和性能分析,它设计了一种与精简指令集类似的指令系统ucode,用于进行程序运行时插桩和代码分析。
taintcheck设计了3个组件,图1展示了攻击检测流程。额外的exploit analyzer组件收集分析过程的信息,当成功检测到攻击之后,会利用这些信息自动化生成攻击签名。
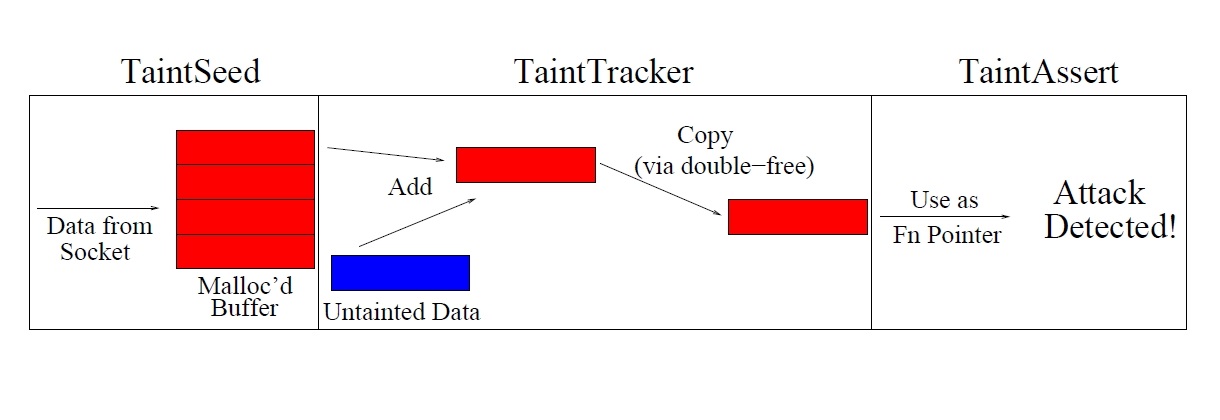
- taintseed
taintseed组件将不可信来源的输入数据标记为被污染的,内存中的每个字节,包括寄存器、堆栈等,都对应一个4字节的影子内存空间,用于存储指向taint数据结构的指针,或设置为空(表示没有被污染)。
当内存被标记为被污染时,taintseed组件会分配一个taint数据结构,记录系统调用号、当前栈的快照、被写入的数据副本,然后返回地址写入到影子内存空间中,这些信息在成功检测到攻击时被exploit analyzer组件使用。
- tainttracker
tainttracker组件跟踪每一个操作数据的指令,决定其指令执行完成之后的结果是否被污染。在valgrind中,ucode指令集被划分为了3类:数据移动指令(例如load、store、move、push、pop等),算术指令(例如add、sub、xor等),和其他(例如nop、jmp等)。基本策略是:对于数据移动指令,被污染的来源数据一定会导致目标数据也被污染,对于数据操作指令,只要其中任意一个来源数据被污染,则目标数据也被污染。
一些特殊的例子需要被注意到,例如"xor eax, eax"指令,其功能用于将寄存器清空置为0,则该操作应当使得对应的结果不被标记为污染,类似的操作还有"sub eax, eax"等。为了跟踪污染数据的传播,tainttracker组件会在对应的数据移动指令和算术指令之前进行插桩,将指令执行结果对应的影子内存空间也指向一个taint数据结构,记录其被污染的来源数据,从而构成一条污染传播链条,这些信息在成功检测到攻击时被exploit analyzer组件使用。
- taintassert
taintassert组件设置断言,检测某种攻击发生时调用的关键函数,其输入数据是否被污染,若断言为真则表明该攻击被检测到。放置断言的目标包括跳转地址,格式化字符串,系统调用参数,指定应用或库检查函数。
断言的设置用于在关键部位,检查可能导致攻击数据传播。例如,跳转或返回的地址被污染,使得程序被攻击者控制执行任意命令;格式化字符串printf中的特殊说明符%n,会让攻击者控制输出敏感数据;系统调用参数被污染,攻击者可以构造关键命令来执行系统调用
一旦taintassert组件检测到污染数据的使用违背了安全策略,则可以将此次执行看作是一次漏洞利用,exploit analyzer组件利用taintseed组件和tainttracker组件收集到的信息来自动化地计算攻击签名,同时可以回溯攻击产生的数据污染传播路径。
2.2 安全分析
- 漏报分析(false negative)
如果攻击者可以让敏感数据被它所控制,但是该数据又没有被标记为污染,则漏报事件发生。这种情况通常是由于某个数据不通过算术指令派生,但依旧被不可信的来源数据间接影响。举例如下代码:
if (x == 0) y = 0;
else if (x == 1) y = 1;
语义上与y = x相同,但通过条件判断间接影响。还有执行编码操作的程序,通过一个表将输入映射到输出,同样会将污染路径中断,导致漏报产生。
- 误报分析(false positive)
如果被污染的数据执行了一个非法路径被检测到攻击,但实际上并没有对程序产生实际的攻击效果,则误报事件发生。这种情况通常是由于该程序本身含有一个检查器,对被污染的数据进行了过滤,确保了其操作的安全。例如,打印函数printf的特殊说明符%n,用于获取已经输出的字符数量,在被调用之前参数通过过滤函数做了限制,因此不会输出敏感数据导致成功攻击。
2.3 性能评估
以运行apache web服务为例,请求大小为1kb到10mb的静态网页,测试使用不同工具的响应时间,下图2显示了每种请求类型的性能开销。
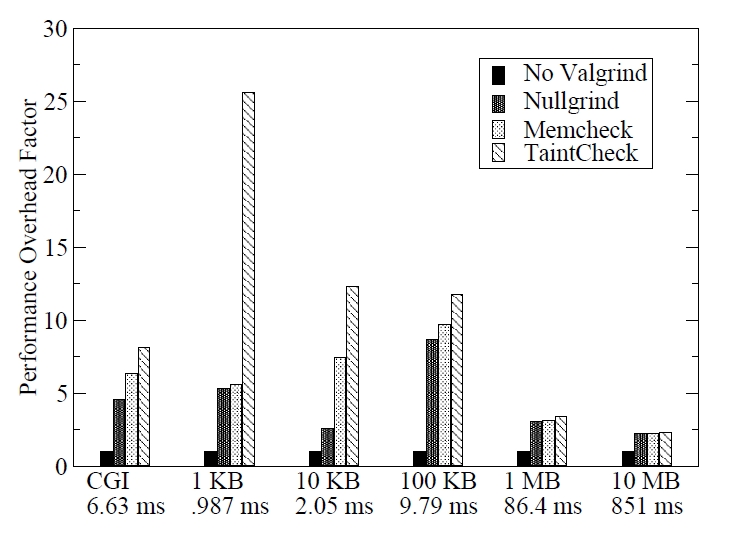
可以很明显的看到,使用动态污点分析开销是比较大的。其他的性能比较结果可以看原始论文,这里不再详细介绍。
3 taintcheck应用
论文的后半部分主要在描述所设计的taintcheck工具可以如何使用,给出了多种潜在的应用场景。
- 新攻击检测
在单独使用中,可以结合其他更加快速的检测器以降低误报率。或者部署在蜜罐中使用,用于监控网络服务。更多的,还可以分布式部署以提高检测效率。
- 自动化分析
一旦检测到攻击,可以利用污染传播的路径自动计算出攻击签名,图3给出了这种使用场景和部署方式。还可以使用该工具去做分类器或者签名验证器,详细内容可以看原始论文。
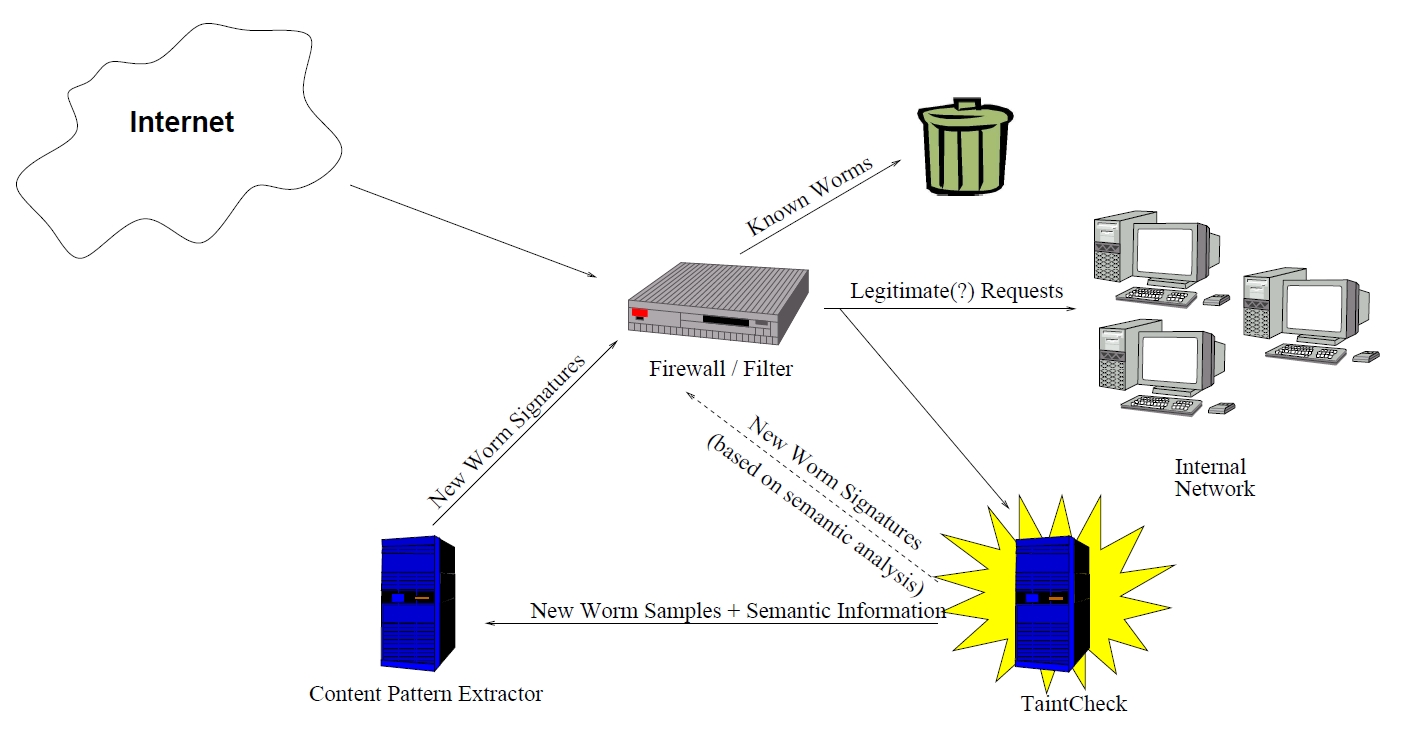
作者对于如何使用动态污点分析技术给了很大篇幅去畅想,不过随着时间的推移可以明显看到这种技术在漏洞检测中发挥的作用。目前,动态污点分析技术主要用于做数据流分析,其性能开销较大,无法直接关联漏洞,各位先进工具仅是将其作为方法链中的一环叠加使用。
4 dfsan标签传播
与taintcheck类似,llvm框架从3.4版本开始引入了数据流分析工具(dataflowsanitizer,dfsan),它通过pass对源码在编译阶段进行插桩,结合动态库来给数据分配标签并进行污点标记,并记录指令执行过程中被污染数据的传播。
4.1 早期实现
在llvm 3.4.x版本中,dfsan将标签值存储在2字节的影子内存中,最多支持 2 16 2^{16} 216 个标签数量,dfsan.h文件对标签和标签信息定义如下:
typedef u16 dfsan_label;
struct dfsan_label_info {
dfsan_label l1;
dfsan_label l2;
const char *desc;
void *userdata;
};
同时定义了一张映射表来指向标签的数据结构,dfsan.cc文件头部声明了一个数组如下:
static const uptr knumlabels = 1 << (sizeof(dfsan_label) * 8);
static atomic_dfsan_label __dfsan_last_label;
static dfsan_label_info __dfsan_label_info[knumlabels];
当两个数据进行操作时,标签会进行合并,然后生成一个新的标签指向操作结果。新标签信息里会记录其操作数来源,部分源码如下:
dfsan_label __dfsan_union(dfsan_label l1, dfsan_label l2) {
...
dfsan_label label = 0;
...
} else {
label =
atomic_fetch_add(&__dfsan_last_label, 1, memory_order_relaxed) + 1;
check_ne(label, kinitializinglabel);
__dfsan_label_info[label].l1 = l1;
__dfsan_label_info[label].l2 = l2;
}
...
return label;
}
标签的传播本质上形成了一颗二叉树,因此可以通过回溯轻易地找出任意两个标签是否存在传播路径。若来源标签被污染,则传播路径上的所有标签都被污染。
4.2 当前实现
在llvm 16.x版本中,dfsan优化了之前的实现,将标签值定义为1个字节大小,仅支持最多8个标签数量。标签的合并操作简化为异或操作,dfsan.cpp文件中源码如下:
dfsan_union(dfsan_label l1, dfsan_label l2) {
return l1 | l2;
}
于是,在官方文档中推荐标签的定义为1,2,4,8,…,128,数据相应标签的比特位为1,则说明数据被对应标签的来源数据污染,但是数据传播的中间过程被省略。
学习笔记
tanitcheck用4字节来记录标签信息,dfsan早期实现用了2个字节记录标签信息,而在当前实现中仅用1个字节的比特位来设置标签。动态污点分析技术确实有它的局限性,更适合于做数据流分析,也会有一些论文会使用它来定位输入的哪些部分更能引起程序错误。最后,附上文献引用和doi链接:





发表评论