文章目录
0 前言
rcnn在2013年在目标检测领域首次使用深度学习和卷积神经网络,他与alex net一起引爆了21世纪第二个十年计算机视觉领域的技术爆炸。
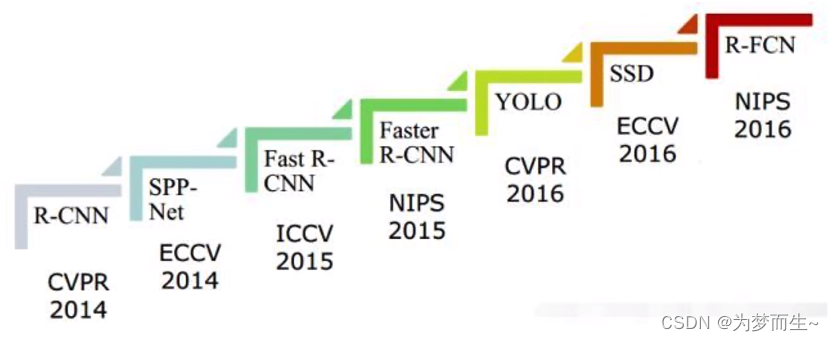
后续所有基于深度学习的目标检测——特别是两阶段目标检测算法。如fast rcnn faster r-cnn,都是在r-cnn上进行的迭代升级。
所以弄懂rcnn特别重要。甚至可以说,没弄懂rcn后边的算法根本就看不懂。
1 r-cnn
1.1 算法步骤
- 一张图像生成1k~2k个候选区域(使用selective search方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的svm分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
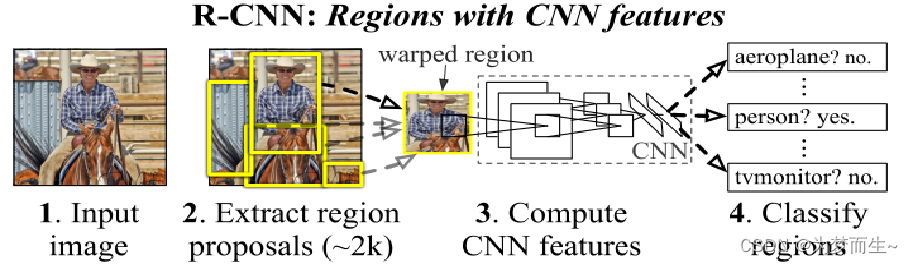
1.1.1 候选区域的生成
利用selective search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。

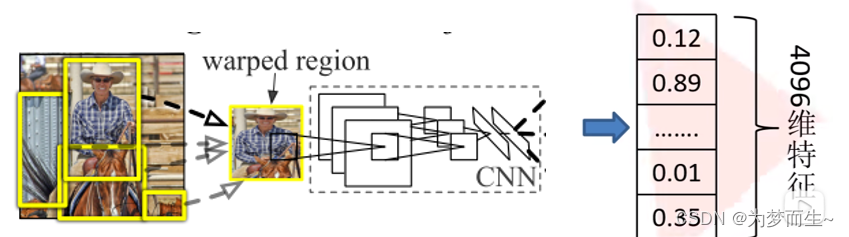
1.1.2 提取特征
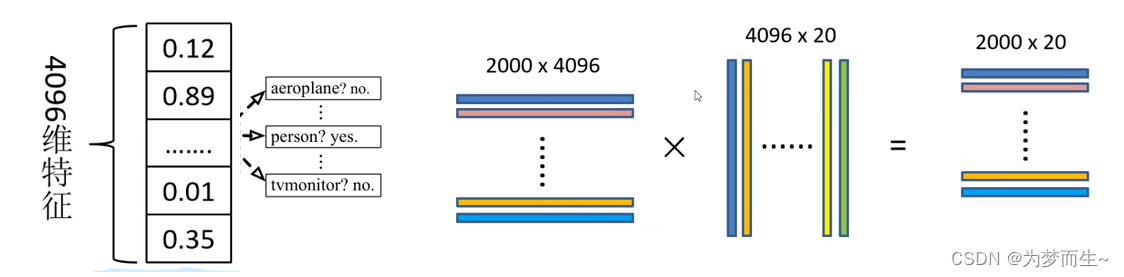
将2000候选区域缩放到227x227pixel,接着将候选区域输入事先训练好的alexnet cnn网络获取4096维的特征得到2000×4096维矩阵。
1.1.3 判定类别
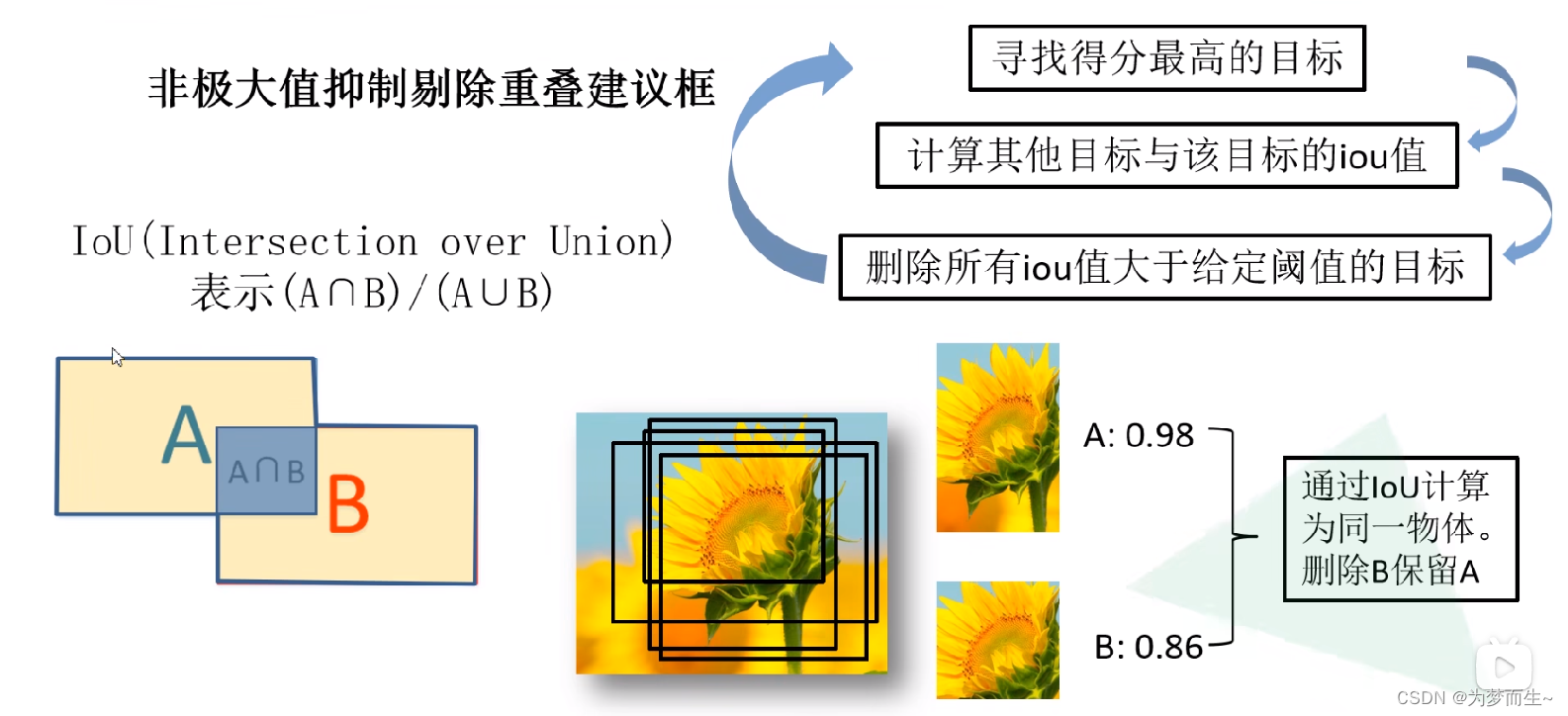
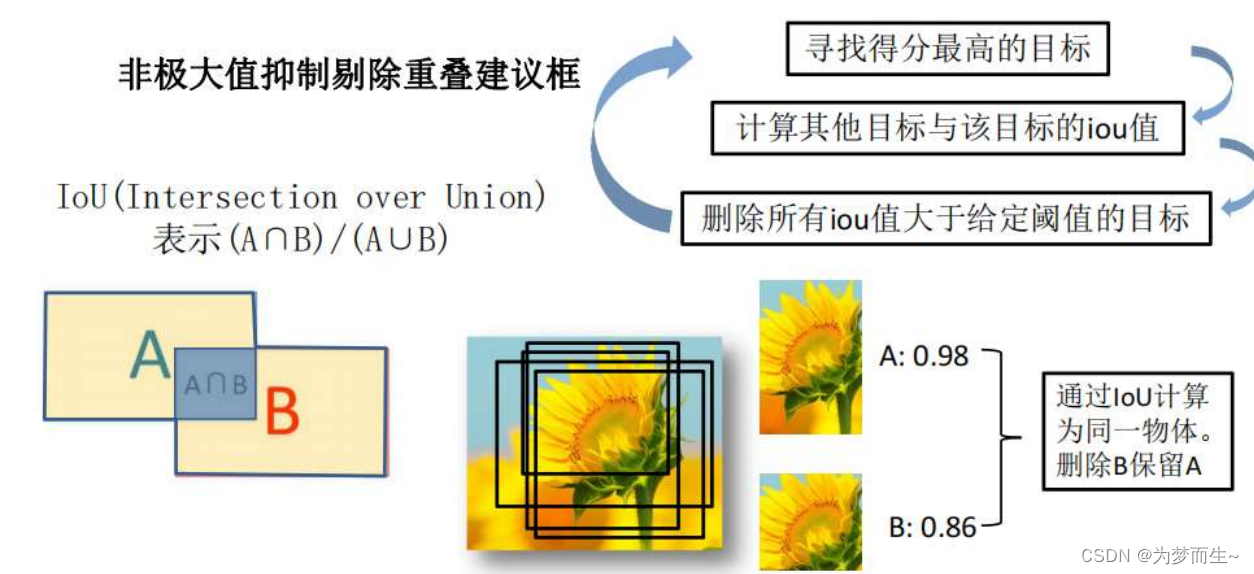
将2000×4096维特征与20个svm组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
进行非极大值抑制处理
1.1.4 精细修正候选框的位置
对nms处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
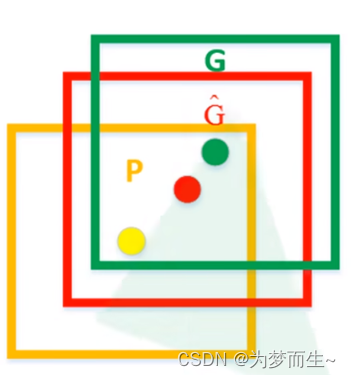
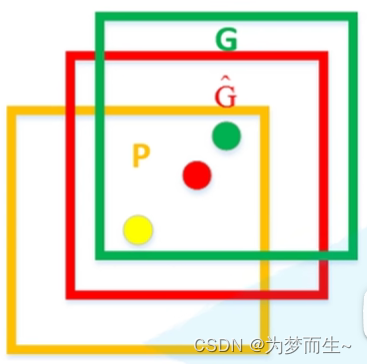
如图,黄色框口p表示建议框region proposal,绿色窗口g表示实际框ground truth,红色窗口 g ^ \hat{g} g^表示region proposal进行回归后的预测窗口,可以用最小二乘法解决的线性回归问题。
1.2 算法总结

r-cnn算法可以分为以下步骤:
- 候选区域生成:利用selective search算法在每张图像上生成约2000个候选区域。这些候选区域被认为是可能包含目标的区域。
- 特征提取:将每个候选区域缩放为227×227,然后输入到预训练的cnn网络中,提取出4096维的特征向量。这一步将每个候选区域转换为固定大小的向量。
- 分类和回归:对于每个候选区域,使用svm分类器进行分类,判断是否属于该类。然后使用回归器精细修正候选框的位置。
到后面我们会看到,这几个部分会不断融合,形成一个端到端的框架。
1.3 存在问题
- 测试速度慢:
测试一张图片约53s (cpu)。用selective search算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。 - 训练速度慢:
过程及其繁琐 - 训练所需空间大:
对于svm和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如vgg16,从voc07训练集上的5k图像上提取的特征需要数百gb的存储空间。
2 fast r-cnn

2.1 算法步骤
- 一张图像生成1k~2k个候选区域(使用selective search方法)
- 将图像输入网络得到相应的特征图,将ss算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过roi pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
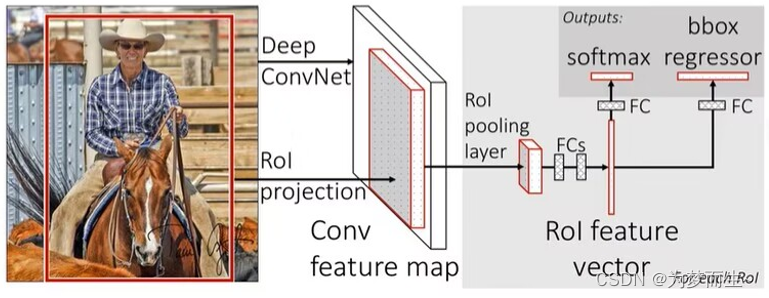
2.2 与fast r-cnn的区别
2.2.1 共享卷积层
r-cnn依次将候选框区域输入卷积神经网络得到特征。
fast-rcnn将整张图像送入网络,紧接着从特征图像上提取相应的候选区域。这些候选区域的特征不需要再重复计算。

2.2.2 roi pooling
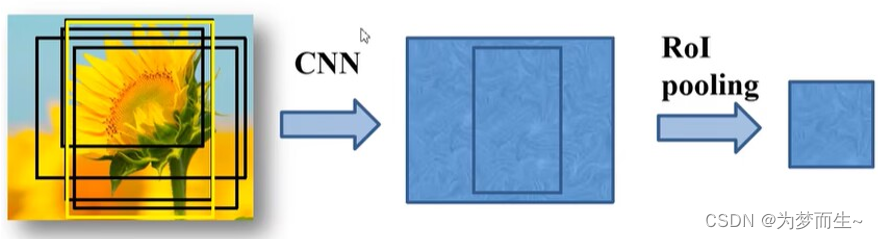
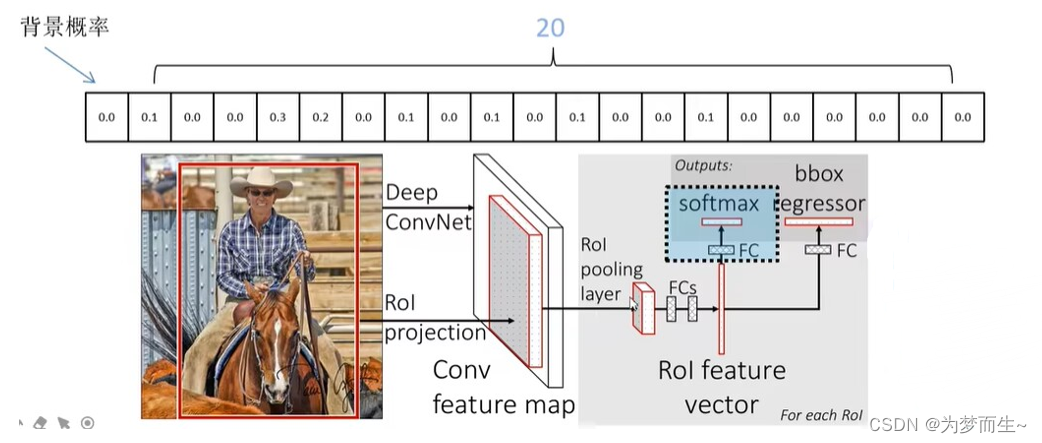
2.2.3 分类器和边界框回归器
该网络的框架是这样的:
- 首先将图像输入到cnn网络得到feature map
- 再根据共享卷积层的映射关系对应到相应的特征矩阵
- 之后通过roi pooling层缩放为7×7大小的矩阵
- 然后进行展平处理,在经过两个全连接层之后,得到feature vector
- 在feature vector的基础上,再并联两个全连接层
- 一个是分类器用于分类概率的预测,另一个回归器用于边界框回归参数的预测
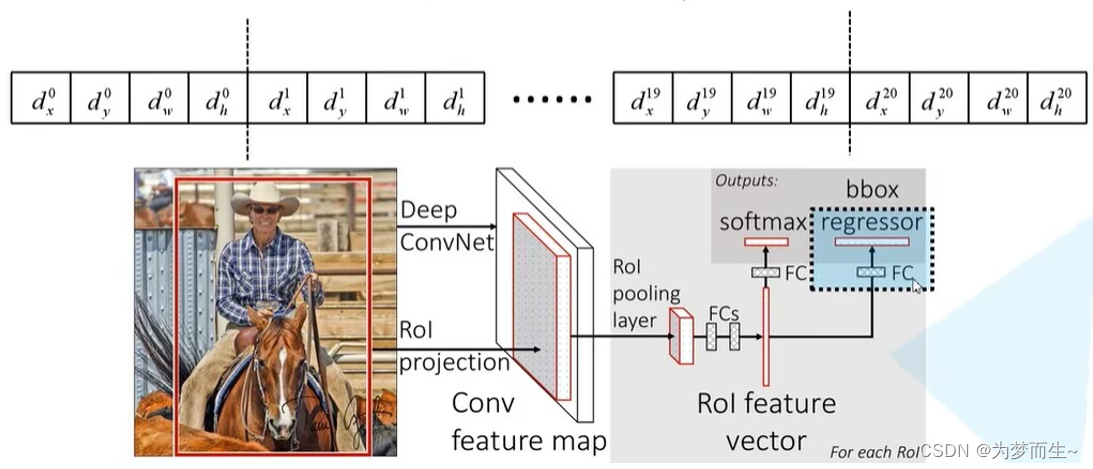
回归的具体计算如下图所示:
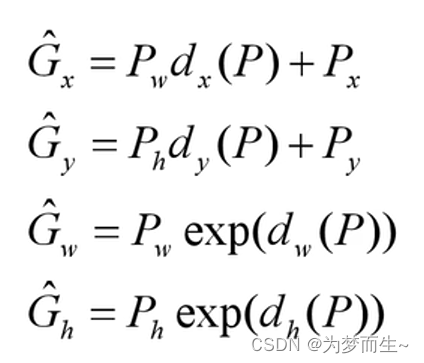
p
x
,
p
y
,
p
w
,
p
h
p_x,p_y,p_w,p_h
px,py,pw,ph分别为候选框的中心x,y坐标,以及宽高
g
^
x
,
g
^
y
,
g
^
w
,
g
^
h
\hat{g}_x,\hat{g}_y,\hat{g}_w,\hat{g}_h
g^x,g^y,g^w,g^h分别为最终预测的边界框中心x,y坐标,以及宽高
2.2.4 损失函数
它的损失函数分为分类损失和边界框回归损失

- p是分类器预测的softmax概率分布 p = ( p 0 , … , p k ) p=(p_0,…,p_k) p=(p0,…,pk)
- u对应目标真实类别标签
- t u t^u tu对应边界框回归器预测的对应类别u的回归参数 t x u , t y u , t w u , t h u t^u_x,t^u_y,t^u_w,t^u_h txu,tyu,twu,thu
- v对应真实目标的边界框回归参数 v x , x y , v w , v h v_x,x_y,v_w,v_h vx,xy,vw,vh
其中,分类损失在原论文中说的是使用log损失 l c l s ( p , u ) = − log p u l_{c l s}(p, u)=-\log p_{u} lcls(p,u)=−logpu
边界框回归损失为:
l
l
o
c
(
t
u
,
v
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
smooth
l
1
(
t
i
u
−
v
i
)
smooth
l
1
(
x
)
=
{
0.5
x
2
if
∣
x
∣
<
1
∣
x
∣
−
0.5
otherwise
\begin{array}{l} l_{l o c}\left(t^{u}, v\right)=\sum_{i \in\{x, y, w, h\}} \operatorname{smooth}_{l_{1}}\left(t_{i}^{u}-v_{i}\right) \\ \operatorname{smooth}_{l_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right. \end{array}
lloc(tu,v)=∑i∈{x,y,w,h}smoothl1(tiu−vi)smoothl1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
2.3 算法总结

该算法首先还是使用selective search寻找候选框
但是后面的特征提取,分类和回归已经融入到了一个网络,进一步提高了速度。
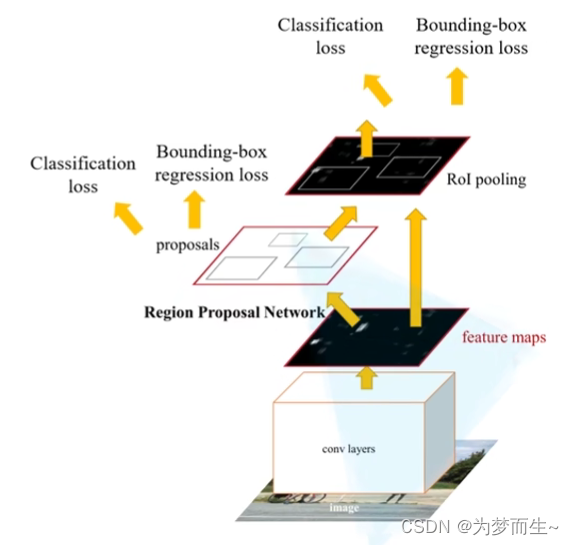
3 faster r-cnn

3.1 算法步骤
- 将图像输入网络得到相应的特征图
- 使用rpn结构生成候选框,将rpn生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过roi pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
实际上就是rpn+fast r-cnn
所以,接下来只需要详细介绍一下rpn网络结构
3.2 rpn
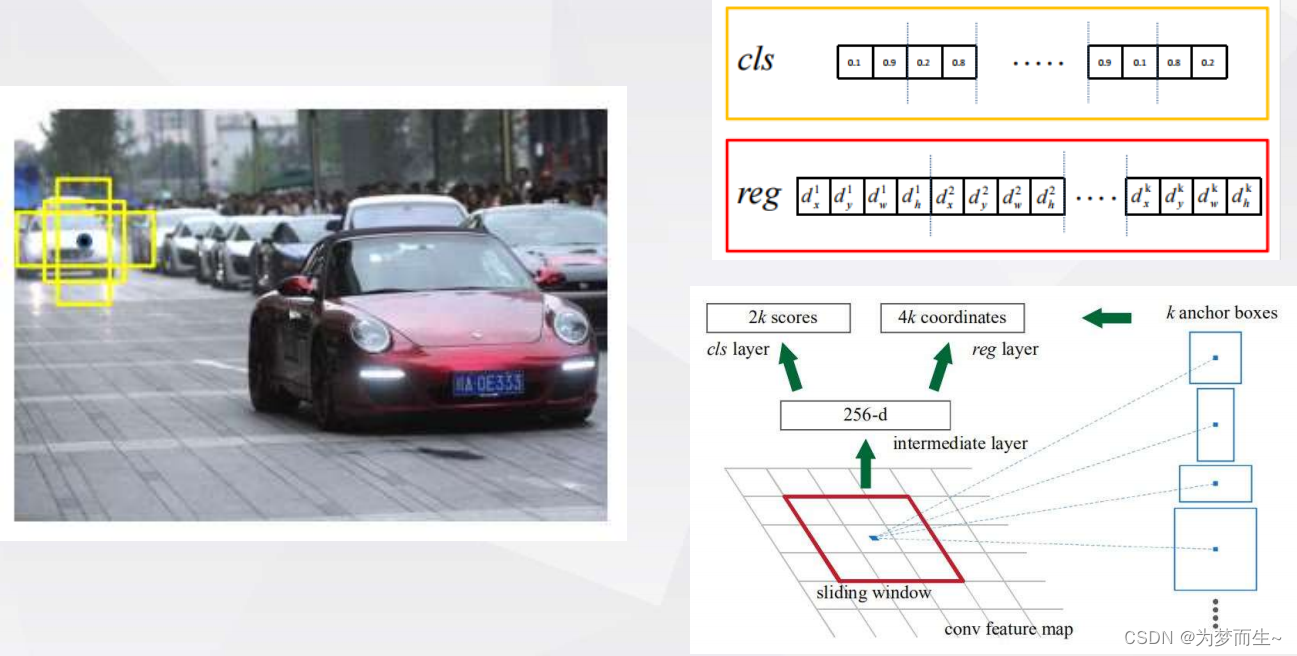
原论文给出的rpn网络的结构:
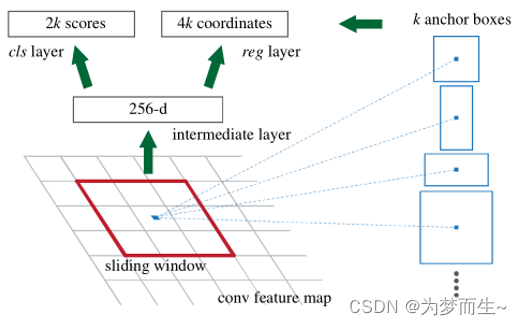
- 该网络使用滑动窗口在feature map上面进行滑动,每次滑动时都会生成一系列候选框(即anchors)
- 输出的通道数为256-d,再分别连接两个1x1conv,输出2k个score和4k个坐标,
- 对于k个anchor,得出2k个预测概率和4k个边界框回归参数
- 分类概率分别为前景和背景的概率,边界框回归参数还是fast r-cnn提到的那四个
- 向量的维度与backbone有关,这里使用zf网络所以是256维,如果是vgg16,那就是512维
3.2.1 anchor
在rpn网络中,每个anchor都对应一个特征图上的点,这个点称为anchor的中心点。以这个中心点为基准,根据设定的尺度和长宽比,在特征图上生成一个矩形框,这个矩形框就是anchor。因此,anchor的数量和特征图的大小以及设定的尺度和长宽比有关。
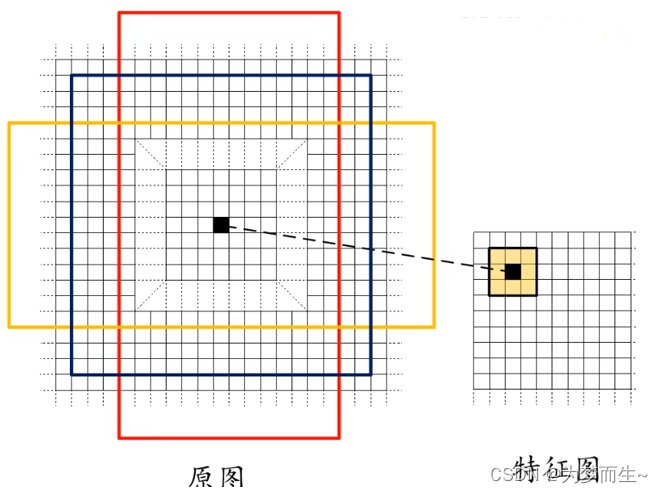
rpn网络中的anchor具有两个重要的作用:
- 一是用于生成候选区域(proposals),即可能包含目标物体的区域;
- 二是用于训练rpn网络,使其能够区分正样本和负样本,并对候选区域进行边框回归,调整其位置和大小。
anchor三种尺度(面积){1282,2562,5122}
anchor三种比例{ 1:1, 1:2, 2:1 }
每个位置在原图上都对应有3x3=9 anchor
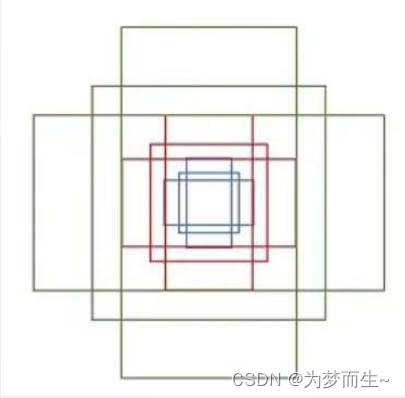
对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于rpn生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,iou设为0.7,这样每张图片只剩2k个候选框。
3.2.2 iou
通过不断优化网络参数,rpn网络可以逐渐学习到如何区分正样本和负样本,并对候选区域进行准确的边框回归。

对于如何确定正负样本,原论文给出了这样的定义:
- 首先,与ground-truth的交并比大于0.7的anchor为正样本
- 其次,如果所有ground-truth与anchor的交并比都小于0.7,选择与ground-truth有最大交并比的anchor作为正样本
- 最后,选择与ground-truth的交并比小于0.3的anchor为负样本
3.2.3 损失函数
原论文中给出的损失函数:

- p i p_i pi表示第i个anchor预测为真实标签的概率
- p i ∗ p_i^* pi∗当为正样本时为1,当为负样本时为0
- t i t_i ti表示预测第i个anchor的边界框回归参数
- t i ∗ t_i^* ti∗表示第i个anchor对应的gt box
- n c l s n_{cls} ncls表示一个mini-batch中的所有样本数量256
- n r e g n_{reg} nreg表示anchor位置的个数(不是anchor个数)约2400
分类损失:
分类损失在原论文中给出的是一个softmax cross entropy
l c l s = − log ( p i ) l_{cls}=-\log (p_i) lcls=−log(pi)
- p i p_i pi表示第i个anchor预测为真实标签的概率
边界框回归损失:
这一部分与fast r-cnn的边界框回归损失是一样的
论文中给出的是smooth l1损失
l
reg
(
t
i
,
t
i
∗
)
=
∑
i
smooth
l
1
(
t
i
−
t
i
∗
)
t
i
=
[
t
x
,
t
y
,
t
w
,
t
h
]
t
i
∗
=
[
t
x
∗
,
t
y
∗
,
t
w
∗
,
t
h
∗
]
\begin{array}{l} l_{\text {reg }}\left(t_{i}, t_{i}^{*}\right)=\sum_{i} \operatorname{smooth}_{l_{1}}\left(t_{i}-t_{i}^{*}\right) \\ t_{i}=\left[t_{x}, t_{y}, t_{w}, t_{h}\right] \quad t_{i}^{*}=\left[t_{x}^{*}, t_{y}^{*}, t_{w}^{*}, t_{h}^{*}\right] \end{array}
lreg (ti,ti∗)=∑ismoothl1(ti−ti∗)ti=[tx,ty,tw,th]ti∗=[tx∗,ty∗,tw∗,th∗]
smooth
l
1
(
x
)
=
{
0.5
x
2
if
∣
x
∣
<
1
∣
x
∣
−
0.5
otherwise
\operatorname{smooth}_{l_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right.
smoothl1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
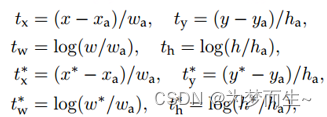
- p i ∗ p_i^* pi∗当为正样本时为1,当为负样本时为0
- t i t_i ti表示预测第i个anchor的边界框回归参数
- t i ∗ t_i^* ti∗表示第i个anchor对应的gt box
3.3 faster r-cnn的训练
现在的很多地方都是直接采用rpn loss+ fast r-cnn loss的联合训练方法
原始的训练方法是这样的:
- 利用imagenet预训练分类模型初始化前置卷积网络层参数,并开始单独训练rpn网络参数;
- 固定rpn网络独有的卷积层以及全连接层参数,再利用lmagenet预训练分类模型初始化前置卷积网络参数,并利用rpn网络生成的目标建议框去训练fast rcnn网络参数。
- 固定利用fast rcnn训练好的前置卷积网络层参数,去微调rpn网络独有的卷积层以及全连接层参数。
- 同样保持固定前置卷积网络层参数,去微调fast rcnn网络的全连接层参数。最后rpn网络与fast rcnn网络共享前置卷积网络层参数,构成一个统一网络。
3.4 算法总结

在faster r-cnn中,这四个部分都融合到了一个网络当中,实现了端对端的训练过程



发表评论