文章较长,附目录,此次安装是在vm虚拟环境下进行。文章第一节主要是介绍hadoop与hadoop生态圈并了解hadoop三种集群的区别,第二节和大家一起下载,配置linux三种集群以及大数据相关所需的jdk,zookeeper,只需安装配置的朋友可以直接跳到文章第二节。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
目录
一、了解hadoop
hadoop
什么是hadoop

hadoop官网介绍
hadoop是一个由apache基金会所开发的分布式系统基础架构,是一个开源的框架,用于编写和运行分布式应用以处理大规模数据。它最初是从nutch项目中分离出来的,专门负责分布式存储以及分布式运算。hadoop的核心主要包含hdfs(hadoop distributed file system,分布式文件系统)和mapreduce(分布式数据处理模型)。
hdfs用于分布式存储海量数据,而mapreduce则用于数据的分布式处理,其本质是并行处理。hadoop的数据来源可以是任意类型的,它在处理半结构化和非结构化数据时与关系型数据库相比有更好的性能和灵活性。任何类型的数据最终都会转化成key/value的形式,这是hadoop的基本数据单元。
hadoop专为离线和大规模数据分析而设计,并不适合对少量记录进行随机在线处理的模式。在实际应用中,hadoop常被用于日志分析等任务,还可以与hive等工具配合使用以进一步提升数据处理能力。
总的来说,hadoop是一个可以更容易开发和运行处理大规模数据的软件平台,用户可以在不了解分布式底层细节的情况下,开发分布式程序。
hadoop的历史
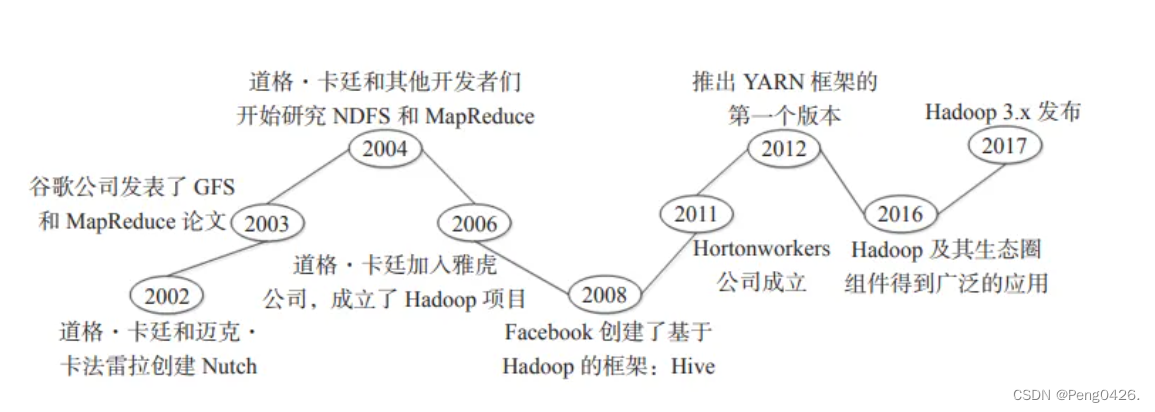
hadoop的历史
hadoop起源于apache nutch项目,始于2002年,是apache lucene的子项目之一 [2]。2004年,google在“操作系统设计与实现”(operating system design and implementation,osdi)会议上公开发表了题为mapreduce:simplified data processing on large clusters(mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的doug cutting等人开始尝试实现mapreduce计算框架,并将它与ndfs(nutch distributed file system)结合,用以支持nutch引擎的主要算法 [2]。由于ndfs和mapreduce在nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为hadoop。到了2008年年初,hadoop已成为apache的顶级项目,包含众多子项目,被应用到包括yahoo在内的很多互联网公司
hadoop的特点
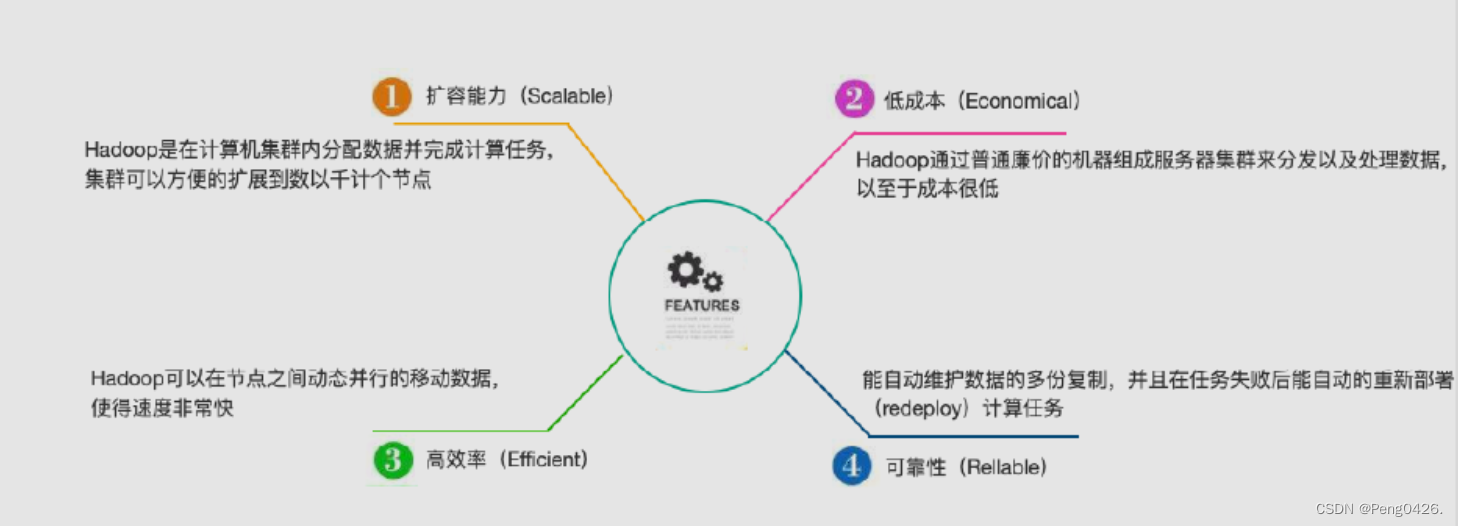
hadoop的特点
- 高可靠性:hadoop采用分布式存储,将数据备份多份并分发至不同的机器进行保存,避免了因机器宕机导致的数据丢失,从而保证了数据的安全性和可靠性。即使hadoop的某个计算元素或存储出现故障,也不会导致数据丢失。
- 高扩展性:hadoop是一个高度可扩展的系统,可以在集群间分配任务数据,方便地扩展到数以千计的节点。当现有集群的资源不足以完成数据处理和分析任务时,可以通过快速扩充集群规模进行扩容,从而加强集群的运算能力。
- 高效性:hadoop采用mapreduce编程模型,能够并行工作,以加快任务处理速度。它能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。相比传统的单台机器处理数据,hadoop的效率得到了极大的提升。
- 高容错性:hadoop能够自动保存数据的多个副本,当某个节点宕机时,它可以自动地将副本复制给其他机器,保证数据的完整性。同时,hadoop能够自动将失败的任务重新分配,确保任务的顺利完成。
- 低成本:hadoop可以运行在廉价的机器上,集群可以将程序并发处理,从而降低成本,提高效率,是处理海量数据的最佳选择。
hadoop的生态系统
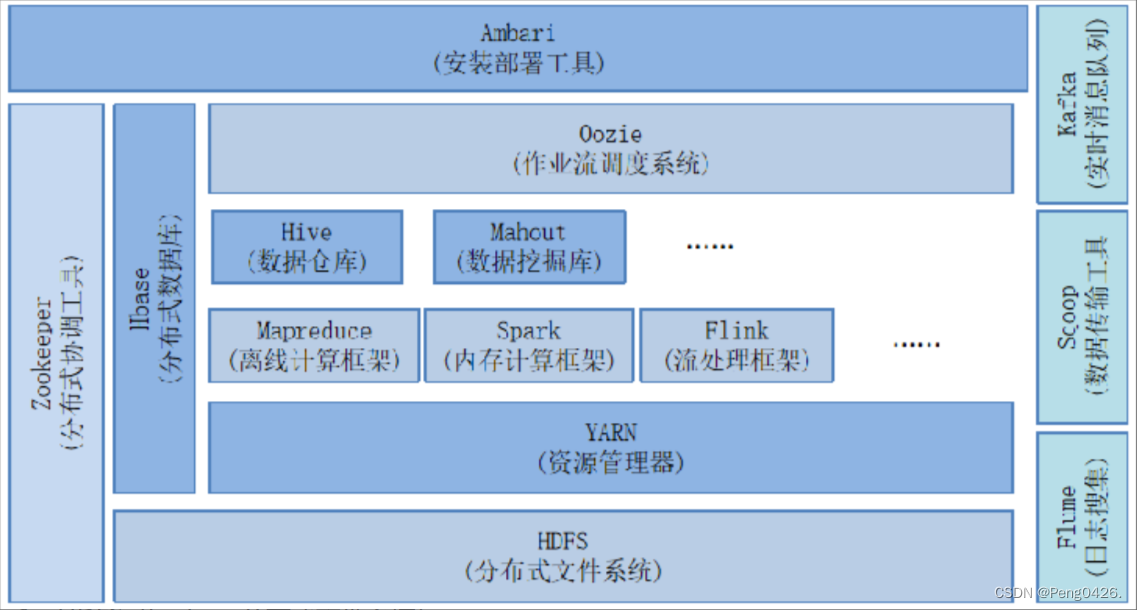
hadoop的生态系统
hadoop生态系统是大数据的核心,同时,hadoop也是大量工具的合集。它们一起协同完成特定的任务,组成hadoop的生态圈,在这里,我要讲的是hadoop生态系统的版本为2.x,如上图所示。
1.hdfs
hdfs是hadoop生态系统的核心组成部分之一,它是一个分布式文件系统,用于存储和管理大规模数据集。hdfs的设计目标是提供高吞吐量的数据访问,适合处理超大规模数据集。它通过将数据分块并分布在集群中的多个节点上来实现数据的分布式存储,同时提供数据复制和容错机制以确保数据的安全性和可靠性。
2.mapreduce
mapreduce是hadoop的另一个核心组件,它是一种编程模型和执行环境,用于处理和分析大规模数据集。mapreduce将复杂的数据处理任务分解为两个主要阶段:map阶段和reduce阶段。在map阶段,系统将数据划分为多个子集,并在集群中的节点上并行处理这些子集。在reduce阶段,系统对map阶段的结果进行汇总和合并,生成最终的处理结果。这种并行处理的方式大大提高了数据处理的速度和效率。
3.yarn
yarn是hadoop 2.0中引入的一个新的资源管理系统,它负责集群资源的调度和管理。yarn将资源管理和应用程序管理分离,使得hadoop集群能够同时运行多种类型的应用程序。yarn通过引入一个全局的资源管理器(resourcemanager)和多个节点管理器(nodemanager)来实现对集群资源的统一管理和调度。resourcemanager负责接收来自应用程序的任务请求,并根据集群的资源状况进行任务调度和分配。nodemanager则负责在节点上启动和管理任务执行容器(container),确保任务能够顺利执行。
4.hive
hive是一个构建在hadoop上的数据仓库工具,它提供了类似sql的查询语言hql,使得用户能够方便地进行数据分析和查询。hive将结构化数据存储在hdfs中,并通过mapreduce进行计算。它使得数据分析和处理变得更加简单和直观,尤其适合那些熟悉sql但不熟悉java编程的数据分析师和数据科学家。
5.hbase
hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,它运行在hdfs上,提供了高可靠性、高性能、列存储、可伸缩、实时读写等特性。hbase利用hadoop的hdfs作为其底层的存储支持,利用hadoop的mapreduce来处理hbase中的海量数据,从而提供高并发读写服务的能力。
此外,hadoop生态系统还不断扩展和演进,新的工具和组件不断涌现,以满足不同领域和场景的需求。这些工具和组件的协同工作,使得hadoop生态系统成为了一个强大而灵活的平台,能够处理和分析各种规模的数据集,为数据驱动的业务决策提供了有力的支持。
总的来说,hadoop的生态系统是一个庞大而复杂的集合,它提供了丰富的功能和工具,使得用户可以轻松地构建和部署分布式应用程序,以处理和分析大规模数据。随着技术的不断发展,hadoop生态系统将继续扩展和完善,为更多领域和场景提供强大的数据处理和分析能力。
6.oozie
oozie是一个java web应用程序,运行在java servlet容器中,用于管理hadoop作业的工作流。它使用数据库来存储工作流定义以及当前运行的工作流实例的状态和变量。oozie工作流是通过放置在控制依赖dag中的一组动作来定义的,这些动作包括hadoop的map/reduce作业、pig作业等,并指定了它们执行的顺序。
7.mahout
在hadoop生态圈中,mahout起到了提供可扩展机器学习算法实现的重要作用。它帮助开发人员更加方便快捷地创建智能应用程序,通过利用hadoop的分布式计算框架,mahout将原本运行于单机上的机器学习算法转化为了mapreduce模式,从而提升了算法可处理的数据量和处理性能。这使得mahout能够有效地扩展到云中,利用云计算的优势进行大规模数据处理和分析。
8.spark
在hadoop的生态圈中,apache spark担当着至关重要的角色。作为一个快速、通用的大规模数据处理引擎,spark补充并扩展了hadoop的能力,为用户提供了更为强大和灵活的数据处理工具。
9.flink
apache flink是一个开源的流处理框架,其核心是一个用java和scala编写的分布式流数据流引擎,以对无界和有界数据流进行有状态计算。flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
flink的出现代表了数据处理技术的进步。作为第三代大数据引擎(第一代为hadoop,第二代为spark),flink在实时计算方面有着显著的优势。虽然其设计初衷是为实时计算而设计,但由于其计算引擎的强大,也可以进行离线计算
10.zookeeper
zookeeper是一个开源的分布式协调服务,其设计目标是将那些复杂的且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一些简单的接口提供给用户使用。它主要为分布式应用提供协调服务,确保在分布式系统中的各个部分能够协同工作。
在zookeeper中,并没有沿用传统的master/slave概念,而是引入了leader、follower、observer三种角色。其中,leader是领导者,负责进行投票的发起和决议,更新系统状态;follower是跟随者,用于接收客户端请求并转发给leader,在选举过程中参与投票;observer是观察者,可以接收客户端请求并转发给leader,但不参与投票过程,通常用于提高读取性能。
二、下载安装包
jdk官网下载地址
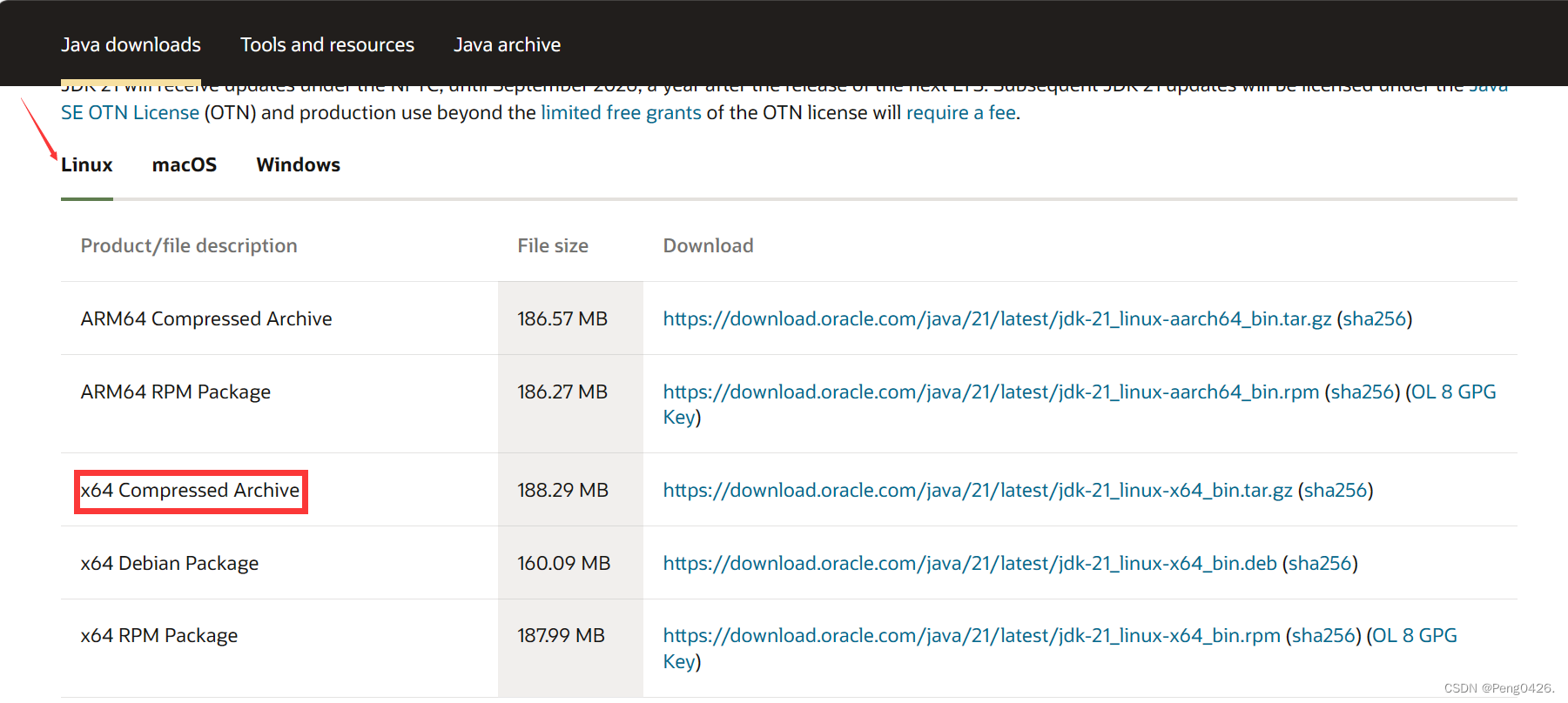
这里我选择下载的是一个linux中的免安装版本,大家可根据自己的需求选择版本,但一定要选择各组件相互兼容的版本。
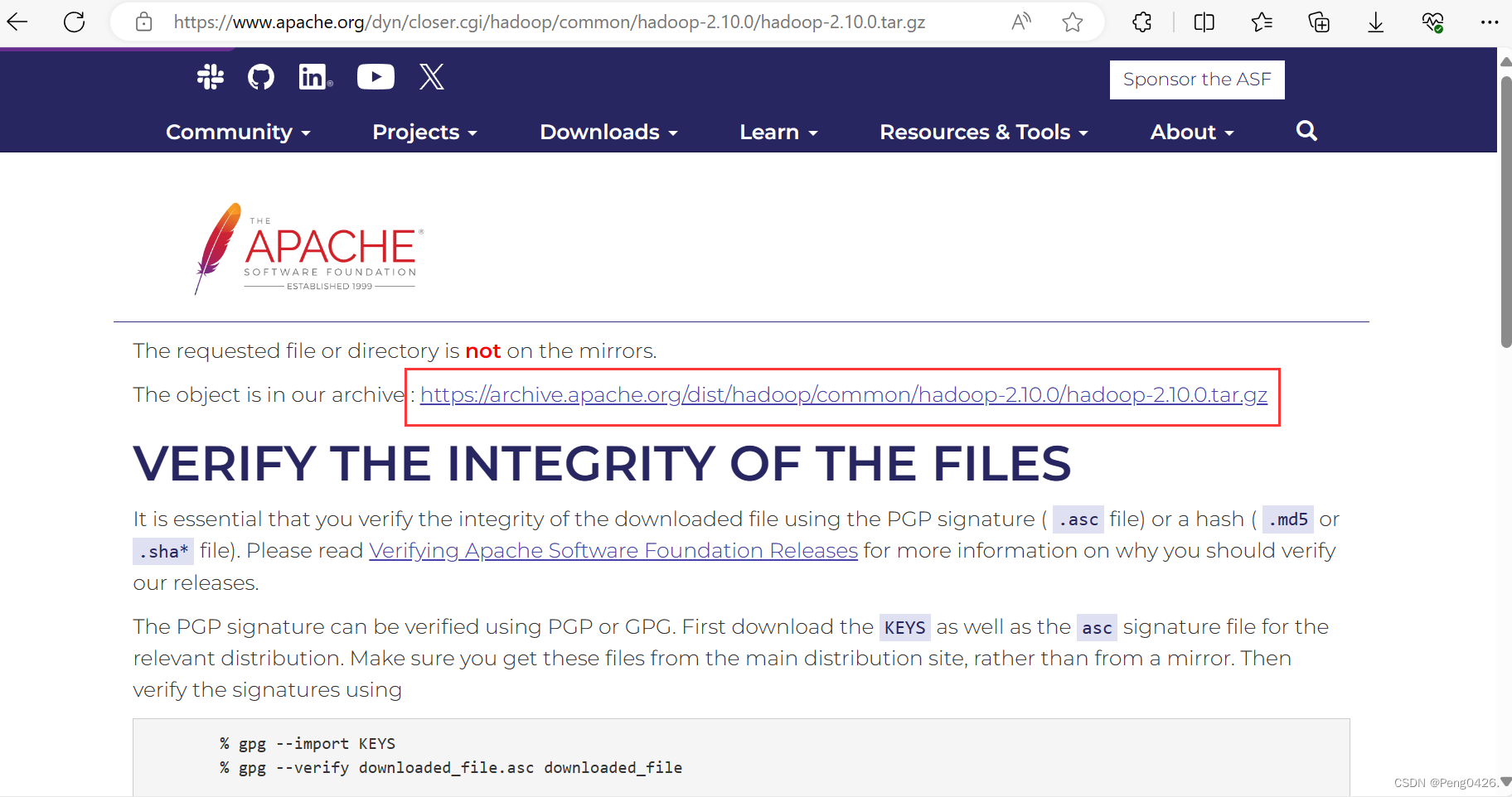
hadoop官网下载地址
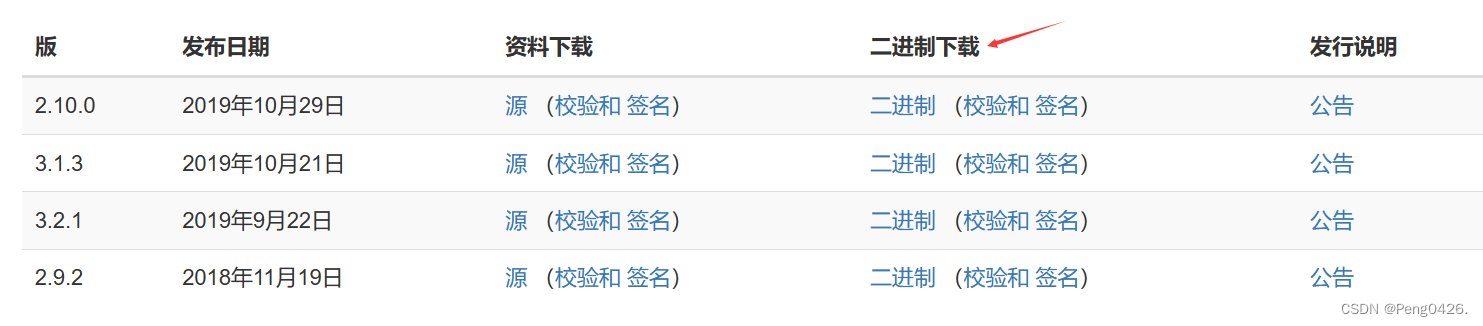
zookeeper官网下载地址
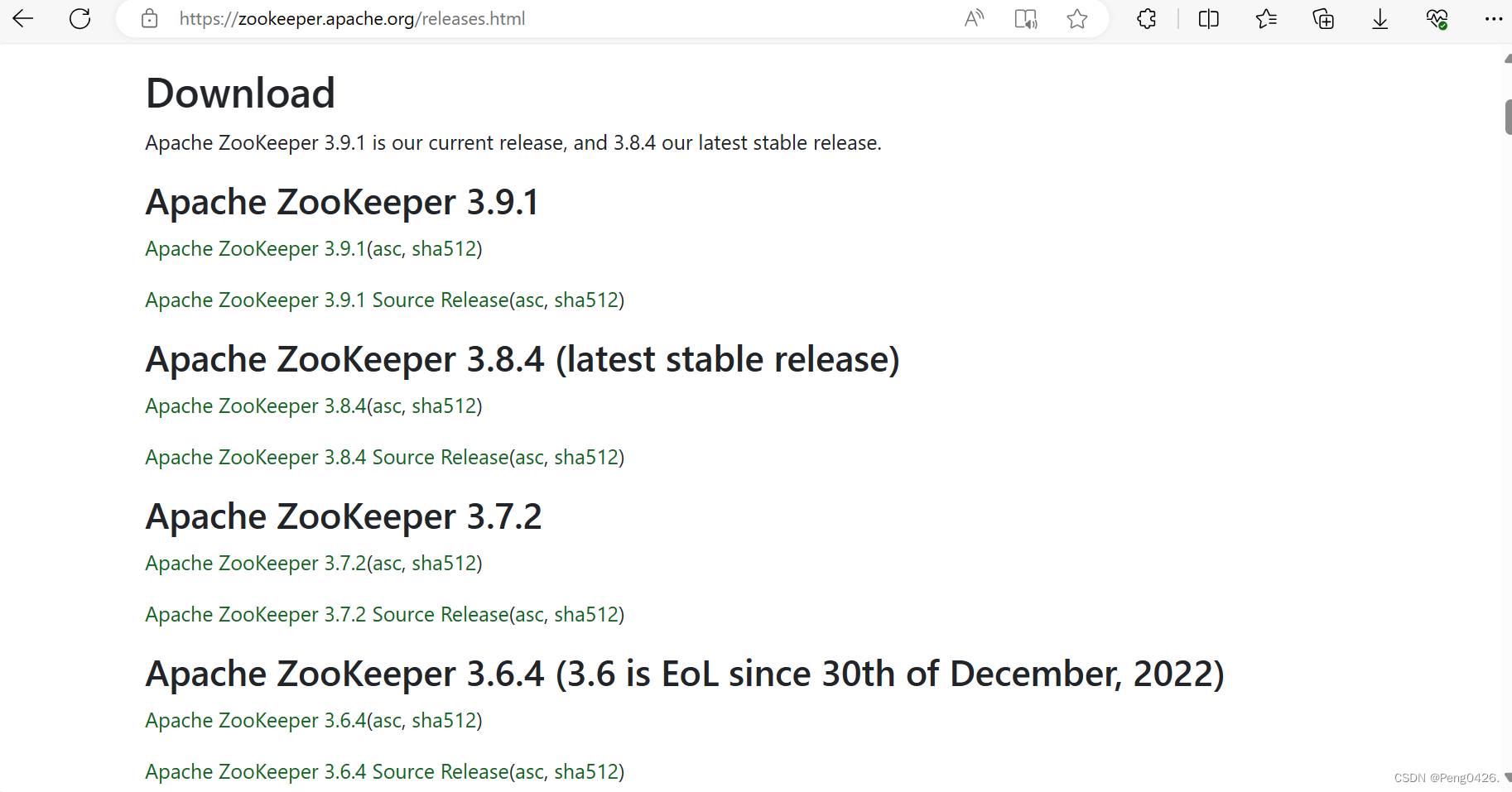
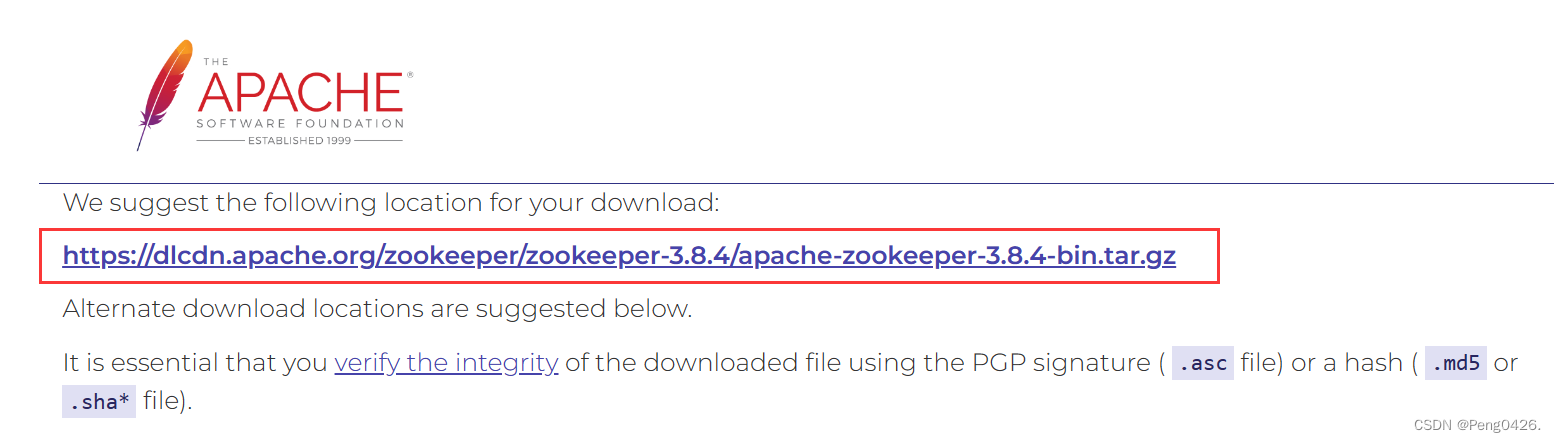
以上安装包,选择自己需要的版本下载即可
三、hadoop集群搭建
我使用的主机、从机名称分别为bigdata01,bigdata02,bigdata03,jdk版本为jdk-8u171, hadoop版本为hadoop-2.7.5,zookeeper版本为zookeeper-3.4.5,解压到opt下,如有主机从 机名称,ip,版本,路径与我不一致的,更改成自己的即可。zookeeper我会在高可用中配置, 其他两种直接套即可。
#将下载的压缩包上传到downloads中并解压到opt下
tar -zxvf /root/downloads/hadoop-2.7.5.tar.gz -c /opt/
tar -zxvf /root/downloads/jdk-8u171-linux-x64.tar.gz -c /opt/
vim /etc/profile
#在配置文件结尾添加以下内容
export java_home=/opt/jdk1.8.0_171
export hadoop_home=/opt/hadoop-2.7.5
export path=$path:$java_home/bin:$hadoop_home/bin:$hadoop_home/sbin
#刷新配置文件
source /etc/profile
#查看java jdk、hadoop是否可用
java -version
hadoop version先将主机关机,克隆两个从机(右击主机虚拟机 > 管理 > 克隆)
vim /etc/hosts
#配置hosts文件,删除原有内容,添加主机从机名称和ip地址(ifconfig查看)
192.168.67.128 bigdata01
192.168.67.129 bigdata02
192.168.67.130 bigdata03
scp /etc/hosts/ root@bigdata02:/etc
scp /etc/hosts/ root@bigdata03:/etc
#配置ssh免密登录
ssh-keygen -t rsa
cd ~/.ssh/
cat ./id_rsa.pub >> ./authorized_keys
scp ./authorized_keys root@bigdata02:/.ssh
scp ./authorized_keys root@bigdata03:/.ssh
ssh-copy-id s1的ip
ssh-copy-id s1的ip
自此,选择跟着一搭建就是伪分布式,跟着二搭建就是完全分布式
一、伪分布式搭建
vim /opt/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
#在文件结尾添加下面代码
export java_home=/opt/jdk1.8.0_171
vim /opt/hadoop-2.7.5/etc/hadoop/core-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<name>fs.defaultfs</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.5/tmp</value>
</property>
vim /opt/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<name>ds.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.5/tmp/dfs/data</value>
</property>
cd /opt/hadoop-2.7.5/sbin
hdfs namenode -format
./start-all.sh
jps
#主机出现namenode,datanode即成功
二、完全分布式搭建
vim /opt/hadoopha/etc/hadoop/hadoop-env.sh
#在文件末尾添加下面代码
export java_home=/opt/jdk1.8.0_171
vim /opt/hadoop-2.7.5/etc/hadoop/core-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<name>fs.defaultfs</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.5/tmp</value>
</property>
vim /opt/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.5/tmp/dfs/data</value>
</property>
vim /opt/hadoop-2.7.5/etc/hadoop/yarn-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
cd /opt/hadoop-2.7.5/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vim /opt/hadoop-2.7.5/etc/hadoop/mapred-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
scp -r /opt/hadoop-2.7.5/ root@bigdata02:/opt/
输入 yes
scp -r /opt/hadoop-2.7.5/ root@bigdata03:/opt/
输入 yes
cd /opt/hadoop-2.7.5/sbin
hdfs namenode -format
start-all.sh
#三个节点分别jps
jps
#主机上出现nodemanager、namenode、resourcemanager、datanode
从机1出现nodemanager、secondarynamenode、datanode
从机2出现datanode、nodemanager
即配置成功
三、高可用搭建+zookeeper
tar zxvf /root/downloads/jdk-8u171-linux-x64.tar.gz -c/opt/
tar zxvf /root/downloads/zookeeper-3.4.5.tar.gz -c/opt/
tar zxvf /root/downloads/hadoop-2.7.5.tar.gz -c/opt/
vim /etc/profile
export java_home=/opt/jdk1.8.0_171
export hadoop_home=/opt/hadoopha
export path=$path:$java_home/bin:$hadoop_home/bin:$hadoop_home/sbin
export zookeeper_home=/opt/zookeeper
export path=$path:$zookeeper_home/bin
mv /opt/zookeeper-3.4.5/ /opt/zookeeper
mv /opt/hadoop-2.7.5/ /opt/hadoopha
cd /opt/zookeeper
mkdir data && mkdir logs
#克隆bigdata02,bigdata03
vim /etc/hosts
192.168.67.128 bigdata01
192.168.67.129 bigdata02
192.168.67.130 bigdata03
#(根据实际ip改变)
scp -r /etc/hosts @bigdata02:/etc/
scp -r /etc/hosts @bigdata03:/etc/
#(接yes和密码)
#免密登录
ssh-keygen -t rsa
cd ~/.ssh/
cat ./id_rsa.pub >> ./authorized_keys
scp ./authorized_keys root@bigdata02:/.ssh
scp ./authorized_keys root@bigdata03:/.ssh
ssh-copy-id bigdata02
ssh-copy-id bigdata03
echo 1 > /opt/zookeeper/data/myid
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
vim /opt/zookeeper/conf/zoo.cfg
修改datadir=/opt/zookeeper/data
末尾添加:
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
scp -r /opt/zookeeper root@bigdata02:/opt/
scp -r /opt/zookeeper root@bigdata03:/opt/
02虚拟机下:echo 2 > /opt/zookeeper/data/myid
03虚拟机下:echo 3 > /opt/zookeeper/data/myid
三个节点下:
systemctl stop firewalld.service
zkserver.sh start
zkserver.sh status
cd /opt/hadoopha/
mkdir tmp
scp -r /opt/hadoopha/tmp @bigdata02:/opt/hadoopha/
scp -r /opt/hadoopha/tmp @bigdata03:/opt/hadoopha/
vim /opt/hadoopha/etc/hadoop/hadoop-env.sh
#在文件末尾添加下面代码
export java_home=/opt/jdk1.8.0_171
vim /opt/hadoopha/etc/hadoop/core-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<!--指定hdfs的通信地址-->
<name>fs.defaultfs</name>
<value>hdfs://ns1</value>
</property>
<property>
<!--指定hadoop运行时产生文件的存储路径(即临时目录)-->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopha/tmp</value>
</property>
<property>
<!--指定zookeeper地址(2181端口参考zoo.cfg配置文件) -->
<name>ha.zookeeper.quorum</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
vim /opt/hadoopha/etc/hadoop/hdfs-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<!--指定hdfs的nameservices为ns1,需要与core-site.xml保持一致-->
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<!--ns1下面设置2个namenode,分别是nn1,nn2-->
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<!--设置nn1的rpc通信地址-->
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>bigdata01:9000</value>
</property>
<property>
<!--设置nn1的http通信地址-->
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>bigdata01:50070</value>
</property>
<property>
<!--设置nn2的rpc通信地址-->
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>bigdata02:9000</value>
</property>
<property>
<!--设置nn2的http通信地址-->
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>bigdata02:50070</value>
</property>
<property>
<!--设置namenode的元数据在journalnode上的存放位置-->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata01:8485;bigdata02:8485;bigdata03:8485/ns1</value>
</property>
<property>
<!--指定journalnode存放edits日志的目录位置-->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoopha/tmp/dfs/journal</value>
</property>
<property>
<!--开启namenode失败自动切换-->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!--配置失败自动切换实现方式-->
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider</value>
</property>
<property>
<!--配置隔离机制-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--设置使用隔离机制时需要的ssh免登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
vim /opt/hadoopha/etc/hadoop/yarn-site.xml
#在<configuration></configuration>里添加下面代码
<property>
<!--设置resourcemanager在哪个节点上-->
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
<property>
<!--reducer取数据的方法是mapreduce_shuffle-->
<!--指定nodemanager启动时加载server的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.shufflehandler</value>
</property>
cd /opt/hadoopha/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
cd
vim /opt/hadoopha/etc/hadoop/mapred-site.xml
<property>
<!--指定mr(mapreduce)框架使用yarn方式-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
vim /opt/hadoopha/etc/hadoop/slaves
bigdata01
bigdata02
bigdata03
scp -r /opt/hadoopha root@bigdata02:/opt/
scp -r /opt/hadoopha root@bigdata03:/opt/
三个节点启动zookeeper,查看状态
zkserver.sh start
zkserver.sh status
jps查看进程
hadoop-daemon.sh start journalnode
主节点下:
hdfs namenode -format
scp -r /opt/hadoopha/tmp/dfs @bigdata02:/opt/hadoopha/tmp/
hadoop-daemon.sh start namenode
另外一个namenode节点下(从节点1):
hdfs namenode -bootstrapstandby
hadoop-daemon.sh start namenode
主节点下:
hdfs zkfc -formatzk 格式化
启动服务:
start-dfs.sh
start-yarn.sh
查看进程:
jps
jps下
bigdata01 -- namenode、datanode、nodemanager、resourcemanager、
journalnode、quorumpeermain、dfszkfailovercontroller
bigdata02 -- namenode、datanode、nodemanager、
journalnode、quorumpeermain、dfszkfailovercontroller
bigdata03 -- datanode、nodemanager、
journalnode、quorumpeermain
即可安装成功
关机前关闭集群服务:
stop-yarn.sh
stop-dfs.sh
浏览器打开查看
http://192.168.67.130:50070/
http://192.168.67.128:50070
根据实际ip地址查看
拓展、hadoop 与 hpcc的区别
- 架构与中间件:
- hadoop是一个开源的分布式计算平台,其核心组件包括hdfs(分布式文件系统)和mapreduce(编程模型)。它通常通过命令行或api与应用程序进行交互。
- hpcc则提供了更为丰富的中间件,包括ecl代码仓库、ecl服务器、esp服务器(提供认证、日志记录等功能)以及dali服务器(用作存储任务工作单元信息和为分布式文件系统提供名字服务)等。这些中间件为hpcc提供了更多的灵活性和功能。
- 扩展性:
- hadoop在理论上可以扩展到数千个节点,但在实际部署中,随着集群规模的增大,管理和维护的复杂性也会增加。
- hpcc被设计为可以灵活地运行在一个到几千个节点上,并且在实际应用中,较小的节点数量就可以提供与hadoop集群相当的处理性能。然而,集群的大小可能取决于分布式文件系统的整体存储需求。
- 性能:
- 在基准测试中,hpcc在某些场景下表现出比hadoop更高的性能。例如,在排序基准测试中,hpcc平台在高性能的400个节点系统上102秒内对1tb的数据完成排序,而相同硬件配置下的hadoop则需要25分钟28秒。
- 然而,性能的比较也取决于具体的任务、数据分布以及硬件配置等因素,因此在实际应用中可能会有所不同。
- 生态系统与集成:
- hadoop拥有庞大的生态系统和丰富的工具集,包括hive(数据仓库工具)、pig(数据流语言)、hbase(分布式数据库)等,使得用户可以方便地进行各种数据处理和分析任务。
- hpcc也提供了一套工具和接口,用于管理和监视其配置和环境。然而,与hadoop相比,其生态系统可能相对较小,工具和集成选项可能有限。
- 社区与支持:
- hadoop作为开源项目的代表,拥有庞大的社区和广泛的行业支持。这使得hadoop在问题解决、功能更新和文档完善等方面通常能够得到及时的响应。
- hpcc的社区规模和支持情况可能因具体产品而异。在选择平台时,了解社区的活跃度和支持力度是非常重要的。
hadoop的优势:
- 广泛的行业认可和应用:hadoop已经在多个行业得到了广泛的应用,包括金融、电商、医疗、科研等。众多企业已经成功地将hadoop集成到他们的数据分析和处理流程中,并取得了显著的成果。这种广泛的行业认可和应用进一步推动了hadoop的普及和发展。
- 可扩展性和灵活性:hadoop的分布式架构使其能够处理大规模的数据集,并且具有良好的可扩展性。无论是处理结构化、半结构化还是非结构化数据,hadoop都能提供高效的解决方案。同时,hadoop的灵活性也使得它能够适应不同的业务场景和需求。
- 成本效益:hadoop是一个开源项目,可以免费使用和修改。这使得企业能够以较低的成本构建和维护大数据处理平台。此外,hadoop的硬件要求相对较低,可以使用普通的商用硬件进行部署,进一步降低了企业的成本负担。
总结:虽然hadoop比hpcc来说,有强大的生态系统、广泛的行业认可、可扩展性和灵活性以及成本效益等方面的优势,但选择适合的大数据处理和分析工具时,应根据具体的需求、数据规模、处理速度要求以及资源限制等因素进行综合考虑。



发表评论