文章目录
01 引言
本文参照官方文档来记录oracle cdc 的配置。
在本文开始前,需要先安装oracle,有兴趣的同学可以参考博主之前写的。
02 前提条件
如果要做oracle的实时同步,oracle数据库配置必须满足如下:
- oracle数据库启用日志归档;
- 定义具有适当权限的oracle用户;
- 被捕获的表或数据库上必须启用增量日志记录;
在官网的安装教程中,可以看到有两种数据库类型的配置,分别是:
| 类型 | 描述 | 版本 |
|---|---|---|
| 独立的数据库架构(non-cdb database) | 是传统的独立数据库架构,每个数据库实例包含所有的对象和数据 | oracle 11g以及之前的版本中使用 |
| 多租户数据库架构(cdb database) | 多租户架构的数据库,包含一个根容器和多个子容器(pdb),每个pdb可以看作是一个独立的数据库 | oracle 12c开始 |
因为 的是oracle11g,所以本文以独立的数据库架构(non-cdb database)的配置来讲解。
03 配置
3.1 启用日志归档
step1:进入容器:
docker exec -it oracle_11g bash
step2:以dba的权限登录数据库:
sqlplus /nolog
connect sys/system as sysdba
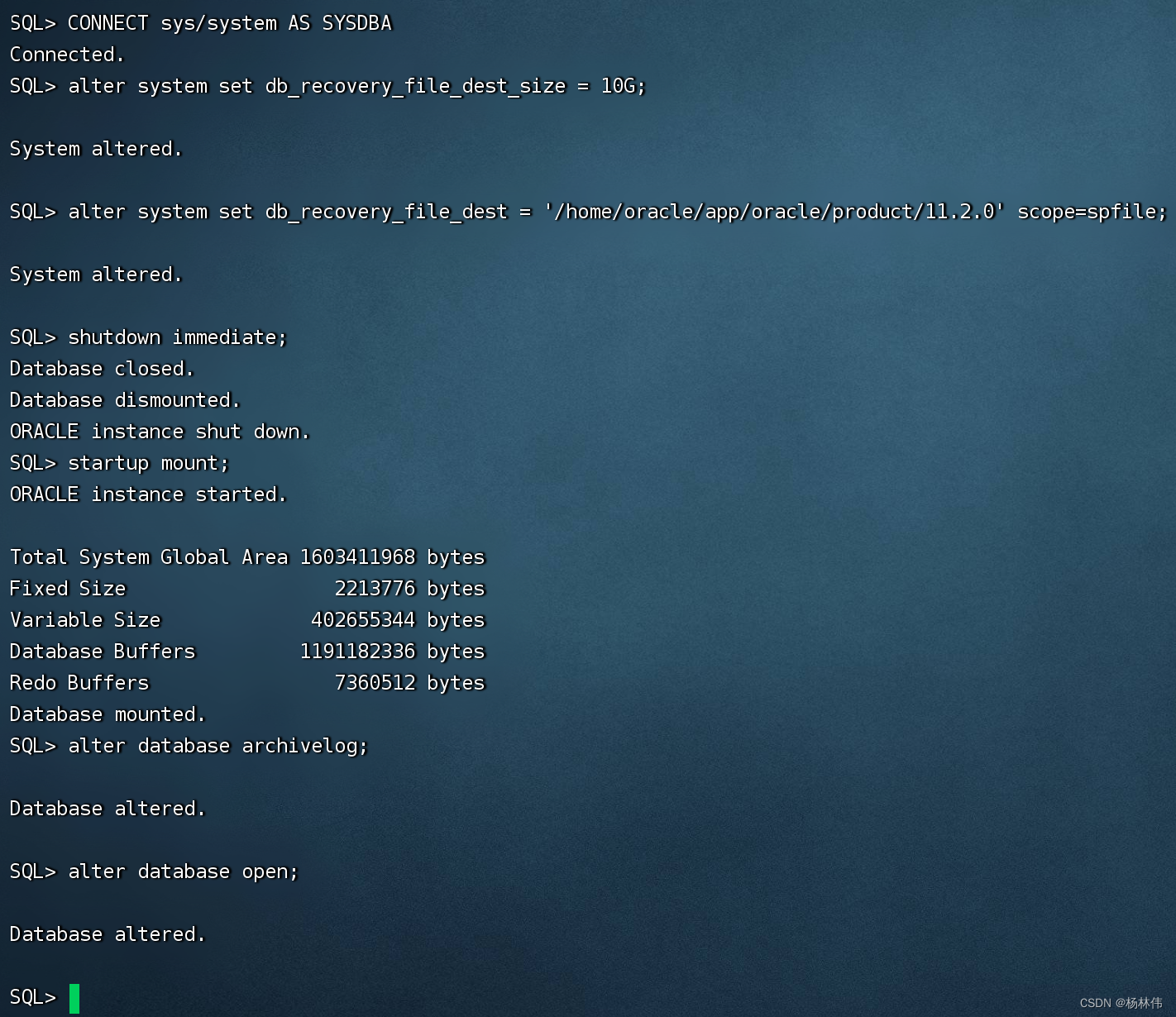
step3:启用日志归档:
-- 设置数据库恢复文件目标大小为10g
alter system set db_recovery_file_dest_size = 10g;
-- 设置数据库恢复文件目标路径
alter system set db_recovery_file_dest = '/home/oracle/app/oracle/product/11.2.0' scope=spfile;
-- 立即关闭数据库
shutdown immediate;
-- 以mount模式启动数据库
startup mount;
-- 启用数据库归档日志模式
alter database archivelog;
-- 打开数据库,允许用户访问
alter database open;
操作记录如下:
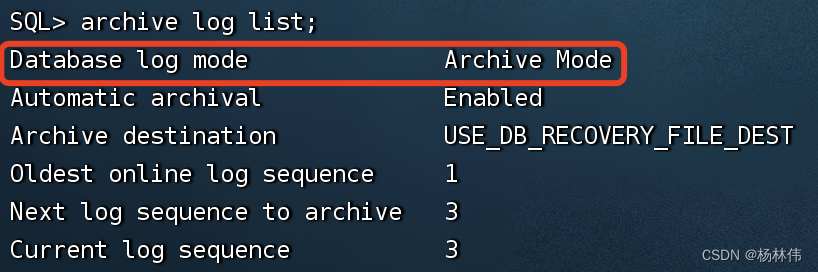
step4:查看日志归档是否启用(如果显示“archive mode”表示已经启用)
archive log list;
在/home/oracle/app/oracle/product/11.2.0目录也能看到数据库恢复文件(按日期分目录):

备注:
- 启用日志归档需要重启数据库。
- 归档日志将占用大量的磁盘空间,因此需要定期清理过期的日志。
3.2 用户赋权
step1:创建表空间(创建表空间是为了提供一个独立、可控、可扩展的存储区域,以供cdc工具捕获和管理数据库的增量数据,这对于实时同步和数据变更追踪非常重要,并为数据流和数据仓库等应用提供可靠的数据源。)
-- 以dba的权限登录数据库
sqlplus /nolog
connect sys/system as sysdba
-- 创建一个名为"logminer_tbs"的表空间
-- 指定表空间的数据文件路径为"/home/oracle/app/oracle/product/11.2.0/logminer_tbs.dbf",其中"/home/oracle/app/oracle/product/11.2.0"是数据文件存储的目录,"logminer_tbs.dbf"是数据文件的文件名
-- 设置表空间的初始大小为25mb
-- 如果数据文件已经存在且可重用,将其重用,否则创建一个新的数据文件
-- 启用表空间的自动扩展功能,即当表空间空间不足时,自动增加数据文件的大小
-- 设置表空间的最大允许大小为无限,即表空间可以无限制地自动扩展
create tablespace logminer_tbs datafile '/home/oracle/app/oracle/product/11.2.0/logminer_tbs.dbf' size 25m reuse autoextend on maxsize unlimited;

可以看到在“/home/oracle/app/oracle/product/11.2.0”目录里已经创建了logminer_tbs.dbf文件:

step2:创建用户并赋予权限
-- 创建一个名为"flinkuser"的用户,密码为"flinkpw",将其默认表空间设置为"logminer_tbs",并在该表空间上设置无限配额。
create user flinkuser identified by flinkpw default tablespace logminer_tbs quota unlimited on logminer_tbs;
-- 允许"flinkuser"用户创建会话,即允许该用户连接到数据库。
grant create session to flinkuser;
-- (不支持oracle 11g)允许"flinkuser"用户在多租户数据库(cdb)中设置容器。
-- grant set container to flinkuser;
-- 允许"flinkuser"用户查询v_$database视图,该视图包含有关数据库实例的信息。
grant select on v_$database to flinkuser;
-- 允许"flinkuser"用户执行任何表的闪回操作。
grant flashback any table to flinkuser;
-- 允许"flinkuser"用户查询任何表的数据。
grant select any table to flinkuser;
-- 允许"flinkuser"用户拥有select_catalog_role角色,该角色允许查询数据字典和元数据。
grant select_catalog_role to flinkuser;
-- 允许"flinkuser"用户拥有execute_catalog_role角色,该角色允许执行一些数据字典中的过程和函数。
grant execute_catalog_role to flinkuser;
-- 允许"flinkuser"用户查询任何事务。
grant select any transaction to flinkuser;
-- (不支持oracle 11g)允许"flinkuser"用户进行数据变更追踪(logminer)。
-- grant logmining to flinkuser;
-- 允许"flinkuser"用户创建表。
grant create table to flinkuser;
-- 允许"flinkuser"用户锁定任何表。
grant lock any table to flinkuser;
-- 允许"flinkuser"用户修改任何表。
grant alter any table to flinkuser;
-- 允许"flinkuser"用户创建序列。
grant create sequence to flinkuser;
-- 允许"flinkuser"用户执行dbms_logmnr包中的过程。
grant execute on dbms_logmnr to flinkuser;
-- 允许"flinkuser"用户执行dbms_logmnr_d包中的过程。
grant execute on dbms_logmnr_d to flinkuser;
-- 允许"flinkuser"用户查询v_$log视图,该视图包含有关数据库日志文件的信息。
grant select on v_$log to flinkuser;
-- 允许"flinkuser"用户查询v_$log_history视图,该视图包含有关数据库历史日志文件的信息。
grant select on v_$log_history to flinkuser;
-- 允许"flinkuser"用户查询v_$logmnr_logs视图,该视图包含有关logminer日志文件的信息。
grant select on v_$logmnr_logs to flinkuser;
-- 允许"flinkuser"用户查询v_$logmnr_contents视图,该视图包含logminer日志文件的内容。
grant select on v_$logmnr_contents to flinkuser;
-- 允许"flinkuser"用户查询v_$logmnr_parameters视图,该视图包含有关logminer的参数信息。
grant select on v_$logmnr_parameters to flinkuser;
-- 允许"flinkuser"用户查询v_$logfile视图,该视图包含有关数据库日志文件的信息。
grant select on v_$logfile to flinkuser;
-- 允许"flinkuser"用户查询v_$archived_log视图,该视图包含已归档的数据库日志文件的信息。
grant select on v_$archived_log to flinkuser;
-- 允许"flinkuser"用户查询v_$archive_dest_status视图,该视图包含有关归档目标状态的信息。
grant select on v_$archive_dest_status to flinkuser;
3.3 表或数据库上启用增量日志记录(supplemental log)
在讲解oracle之前,很有必要先了解oracle的逻辑结构。
3.3.1 oracle 逻辑结构
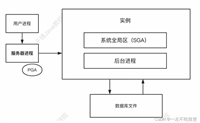
oracle在逻辑结构中,分别是如下的结构:数据库实例 => 表空间 => 数据段(表) => 区 => 块。
- 数据库实例:前面的,在启动容器时,已经指定了oracle的数据库实例的唯一id,每个oracle数据库实例都有一个唯一的sid,也就是说,安装的时候,已经创建好了一个“helowin”数据库实例了。
- 表空间:在 “用户赋权”的第1步骤,可以看出已经创建了“logminer_tbs”表空间(create tablespace logminer_tbs…)
相关的查询sql:
-- 以dba的权限登录数据库
sqlplus /nolog
connect sys/system as sysdba
-- 查询数据库实例名称
select name from v$database;
-- 查询所有表空间名称
select tablespace_name from dba_tablespaces;
结果如下:
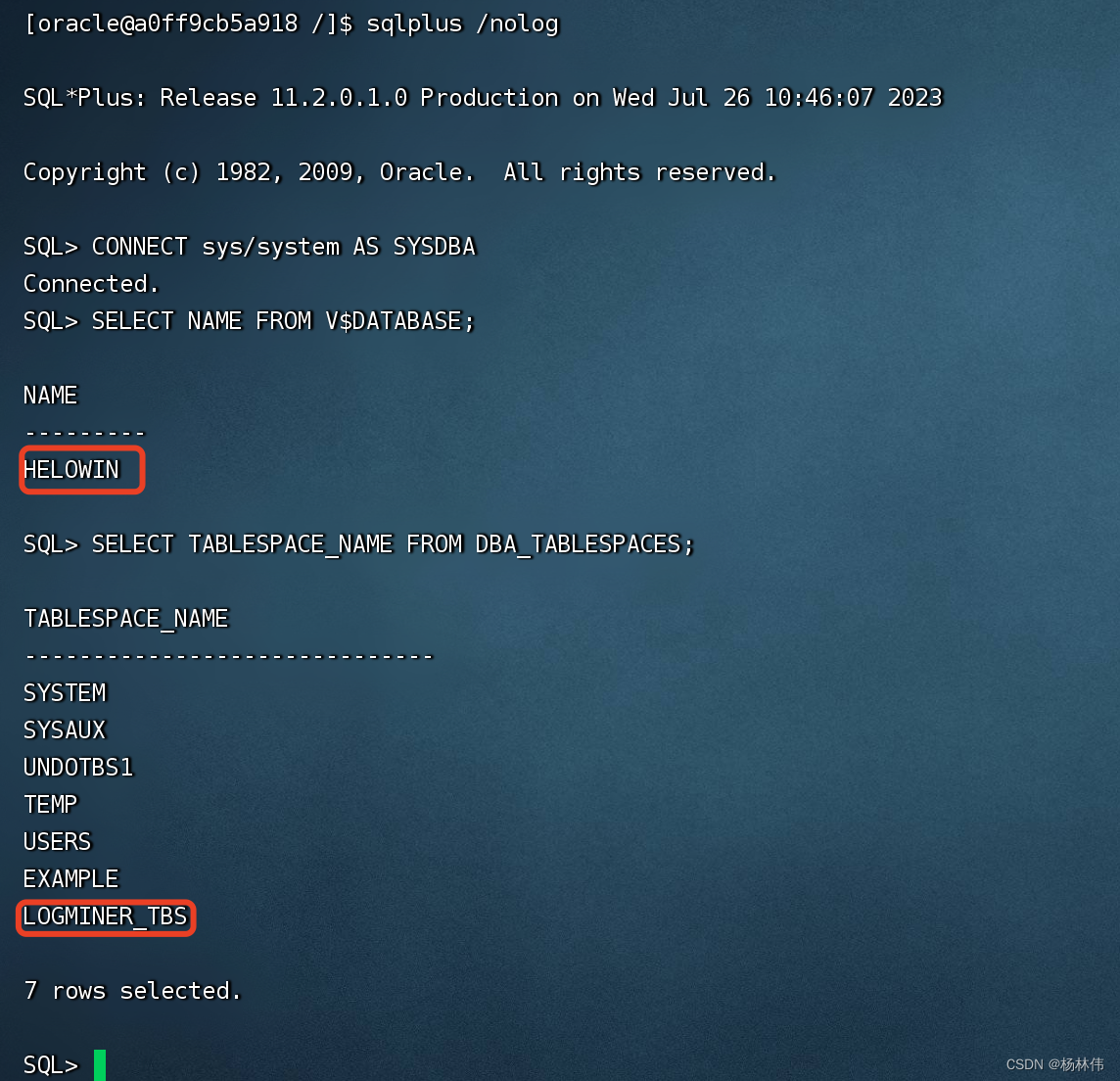
ok,接下来就可以进入“logminer_tbs”表空间去创建表了。
3.3.2 创建表
在logminer_tbs表空间下的flinkuser用户下创建customers表:
-- 切换至flinkuser用户
sqlplus /nolog
connect flinkuser/flinkpw
-- 创建customers表
create table customers (
customer_id number primary key,
customer_name varchar2(50),
email varchar2(100),
phone varchar2(20)
) tablespace logminer_tbs;
查看表是否创建成功:
-- 查看logminer_tbs表空间下的所有表
select tablespace_name, table_name from user_tables
where tablespace_name = 'logminer_tbs';
可以看到表创建成功:

3.3.3 启用增量日志
切换至sys用户,以dba的权限登录数据库,为表和数据库启用增量日志:
-- 以dba的权限登录数据库
sqlplus /nolog
connect sys/system as sysdba
-- 为logminer_tbs表空间下的customers表启用增强日志记录
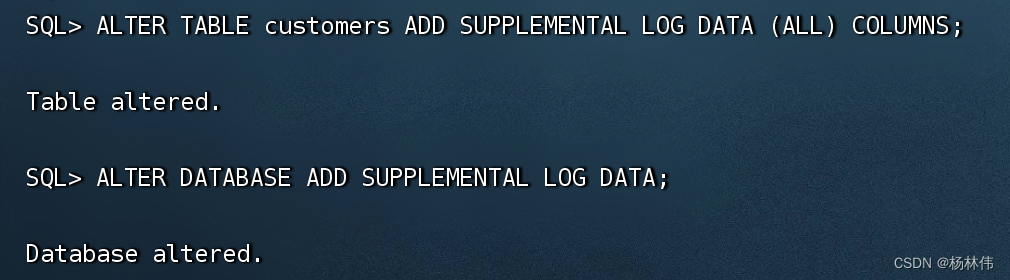
alter table flinkuser.customers add supplemental log data (all) columns
-- 为数据库启用增强日志记录:
alter database add supplemental log data;
操作成功:
04 flink sql
注意:源表的字段定义、schema-name以及table-name都要大写,否则无法同步。
-- 创建oracle cdc源表table_source_oracle,从oracle数据库中读取数据
create table table_source_oracle (
customer_id int,
customer_name string,
email string,
phone string,
primary key (customer_id) not enforced
)
with (
'connector' = 'oracle-cdc',
'hostname' = '10.194.183.120',
'port' = '30026',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'helowin',
'schema-name' = 'flinkuser',
'table-name' = 'customers'
)
-- 创建mysql jdbc接收表table_sink_mysql,将数据写入到mysql数据库
create table table_sink_mysql (
customer_id int,
customer_name string,
email string,
phone string,
primary key (customer_id) not enforced
)
with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.194.183.120:30025/test',
'username' = 'root',
'password' = 'root',
'table-name' = 'customers'
);
-- 将table_source_oracle表的数据插入到table_sink_mysql表中
insert into table_sink_mysql select * from table_source_oracle;
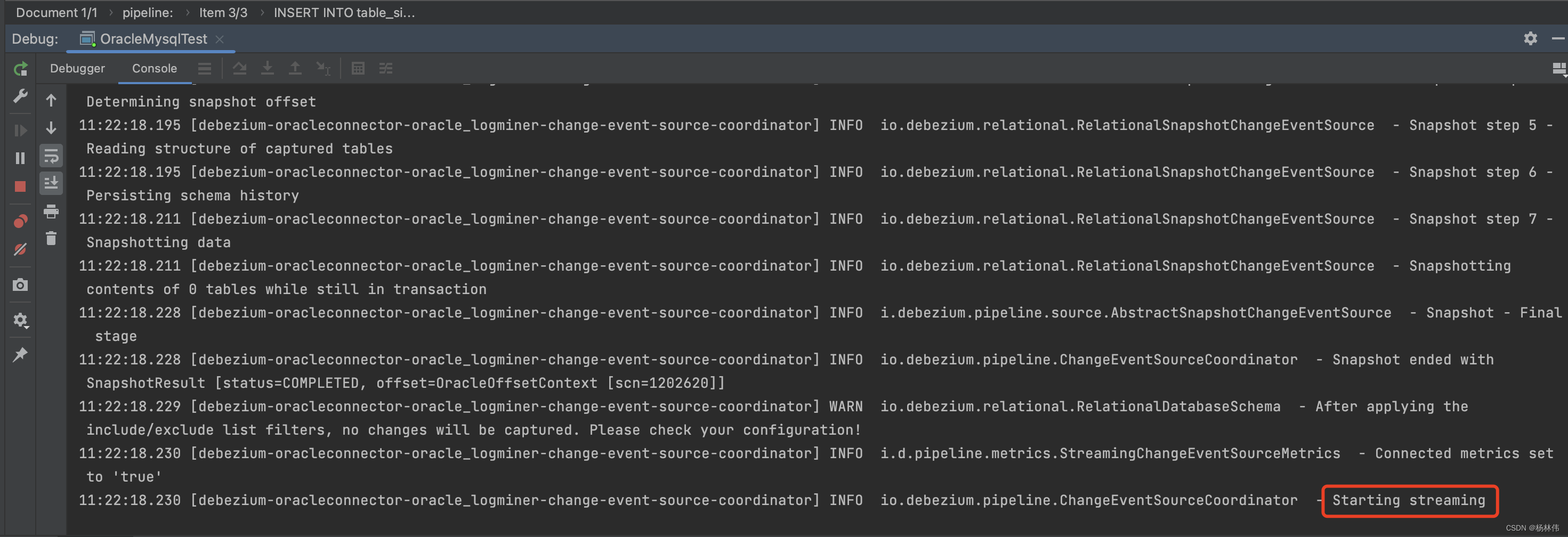
执行flinksql后,可以看到控制台没有报错,程序已经正常启动:
往customers插入一条数据:
-- 切换至flinkuser用户
sqlplus /nolog
connect flinkuser/flinkpw
-- 插入数据
insert into customers (customer_id, customer_name, email, phone)
values (1, 'dumas', 'dumas@example.com', '123-456-7890');

可以看到,已经写入成功了:

05 其它问题
虽然能做同步了,但是感觉还是有很多坑的,比如控制台会报错:
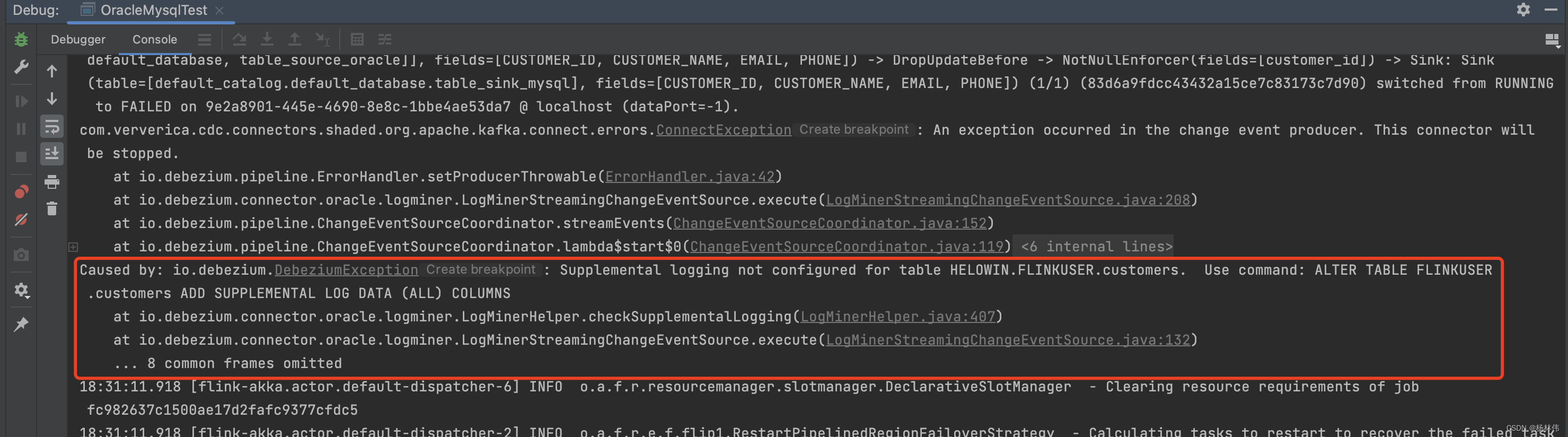
解决方式:在 create 语句中加上
'debezium.database.tablename.case.insensitive'='false'
还有数据延迟较大,也是在create语句加上:
'debezium.log.mining.strategy'='online_catalog',
'debezium.log.mining.continuous.mine'='true'
所以,最终的flink sql如下:
-- 创建oracle cdc源表table_source_oracle,从oracle数据库中读取数据
create table table_source_oracle (
customer_id int,
customer_name string,
email string,
phone string,
primary key (customer_id) not enforced
)
with (
'connector' = 'oracle-cdc',
'hostname' = '10.194.183.120',
'port' = '30026',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'helowin',
'schema-name' = 'flinkuser',
'table-name' = 'customers',
'debezium.database.tablename.case.insensitive'='false',
'debezium.log.mining.strategy'='online_catalog',
'debezium.log.mining.continuous.mine'='true'
);
-- 创建mysql jdbc接收表table_sink_mysql,将数据写入到mysql数据库
create table table_sink_mysql (
customer_id int,
customer_name string,
email string,
phone string,
primary key (customer_id) not enforced
)
with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.194.183.120:30025/test',
'username' = 'root',
'password' = 'root',
'table-name' = 'customers'
);
-- 将table_source_oracle表的数据插入到table_sink_mysql表中
insert into table_sink_mysql select * from table_source_oracle;
06 文末
本文主要讲解了flink oracle cdc实时同步的所有步骤,希望能帮助到大家,谢谢大家的阅读,本文完!



发表评论