此文章基于搭建好hadoop之后做的词频统计实验,以上是链接为搭建hadoop的教程
目录
1 hdfs 文件系统常用命令
# 显示hdfs根目录下的文件和目录列表
hadoop fs -ls /
# 创建hdfs目录
hadoop fs -mkdir /path/to/directory
# 将本地文件上传到hdfs
hadoop fs -put localfile /path/in/hdfs
# 将hdfs上的文件下载到本地
hadoop fs -get /path/in/hdfs localfile
# 显示hdfs上的文件内容
hadoop fs -cat /path/in/hdfs
# 删除hdfs上的文件或目录
hadoop fs -rm /path/in/hdfs
# 递归删除目录
hadoop fs -rm -r /path/in/hdfs
# 移动或重命名hdfs上的文件或目录
hadoop fs -mv /source/path /destination/path
# 复制hdfs上的文件或目录
hadoop fs -cp /source/path /destination/path
# 显示hdfs上文件的元数据
hadoop fs -stat %n /path/in/hdfs
# 设置hdfs上文件的权限
hadoop fs -chmod 755 /path/in/hdfs
# 设置hdfs上文件的所有者和所属组
hadoop fs -chown user:group /path/in/hdfs2 词频统计实验准备工作
2.1 启动hadoop 关闭防火墙
[root@hadoop ~]# start-all.sh
starting namenodes on [localhost]
starting datanodes
starting secondary namenodes [hadoop]
starting resourcemanager
starting nodemanagers
[root@hadoop ~]# systemctl stop firewalld.service
2.2 查看图形化界面
查看ip地址
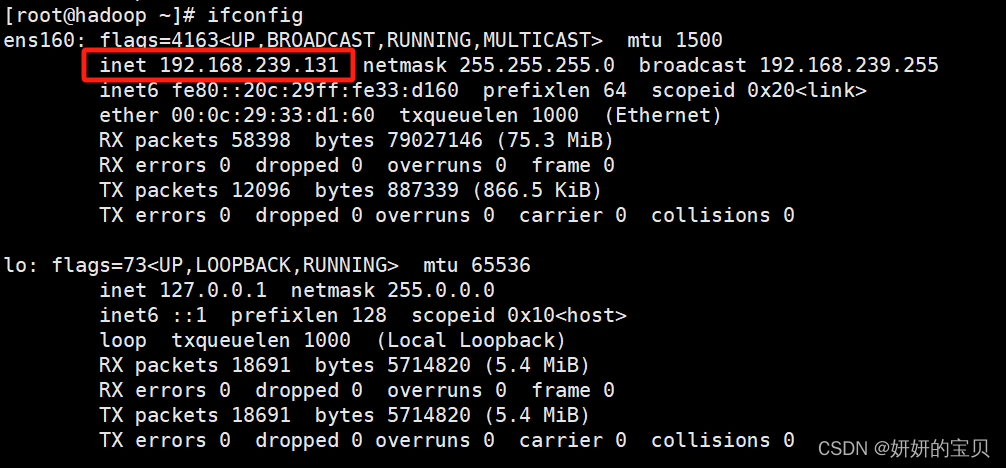
输入ip地址+9870
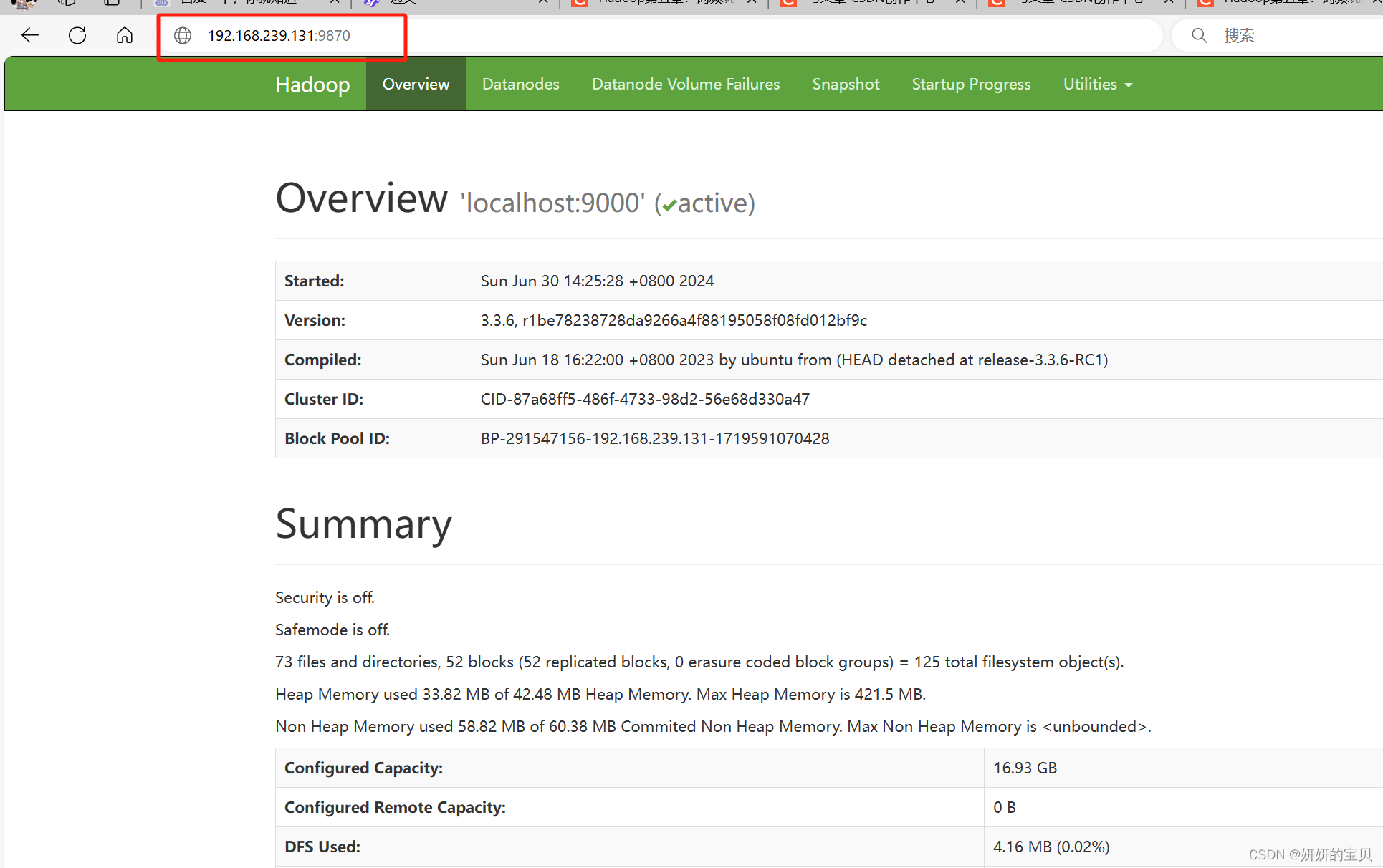
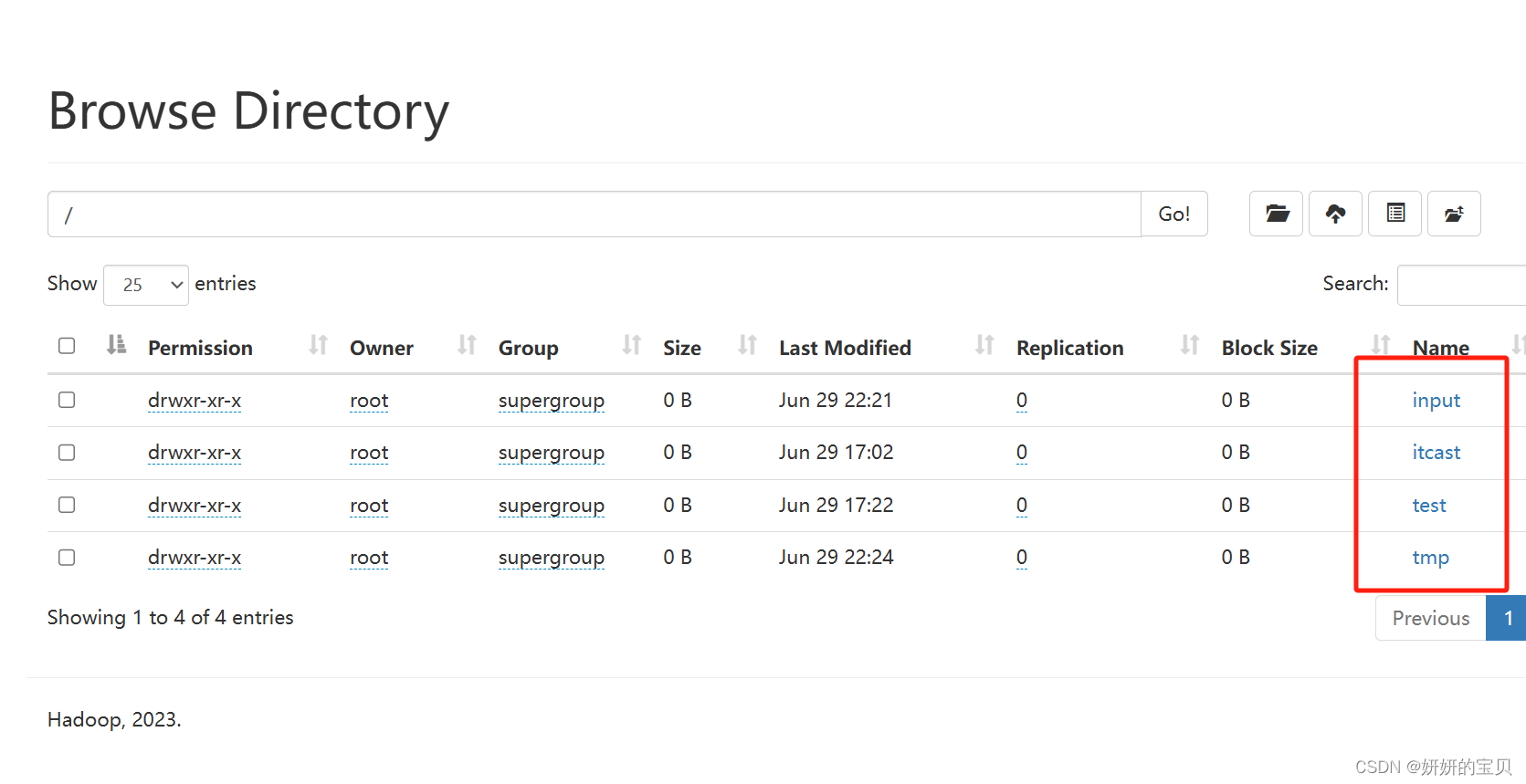
这是在hdfs文件系统上的文件
在虚拟机上使用命令同样也能看到

2.3 文件上传
网上随便找一篇英语短文,作为单词统计的文档

[root@hadoop ~]# mkdir /wordcount
[root@hadoop ~]# cd /wordcount/
[root@hadoop wordcount]# vim words2.txt
英语文章实例
在hdfs文件系统中根目录创建 input 目录
我这里目录已经创建过了所以会显示已存在
[root@hadoop wordcount]# hadoop fs -mkdir /input
mkdir: `/input': file exists

上传文件到hdfs文件系统
[root@hadoop wordcount]# hadoop fs -put /wordcount/words2.txt /input浏览器查看是否上传成功

2.4 配置hadoop的classpath
[root@hadoop wordcount]# hadoop classpath
/opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
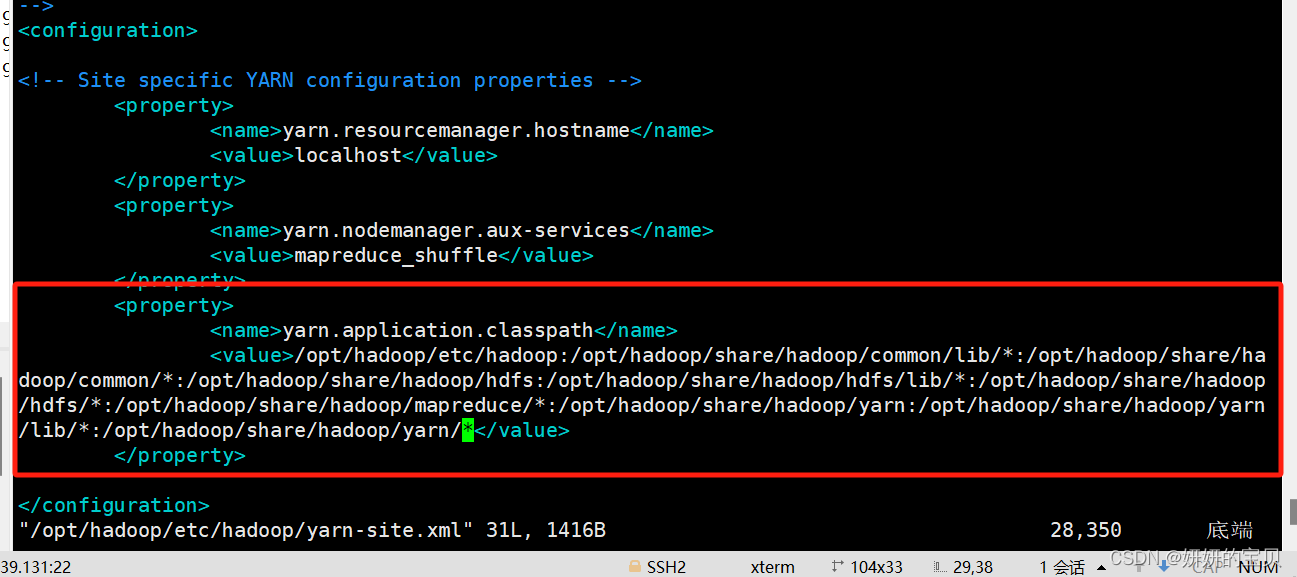
[root@hadoop wordcount]# vim /opt/hadoop/etc/hadoop/yarn-site.xml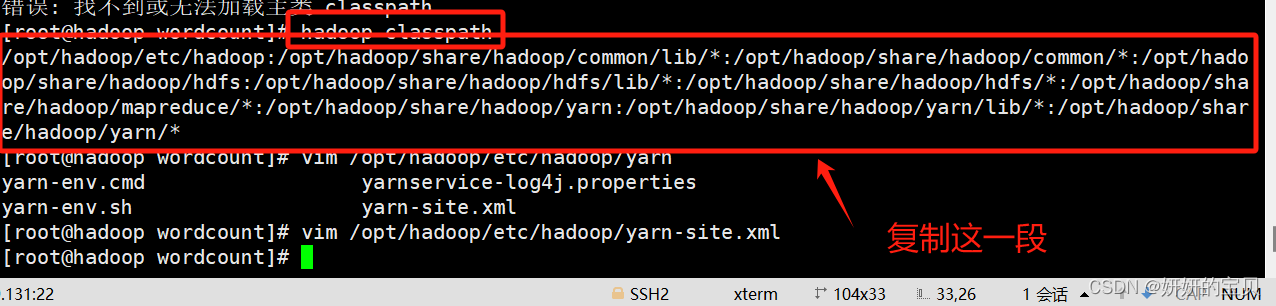
3 词频统计
在文件系统上有了文章可以开始词频统计了
3.1 方法一:使用hadoop自带的jar包文件
查看jar包放在哪个目录下了
[root@hadoop wordcount]# find $hadoop_home/ -name mapreduce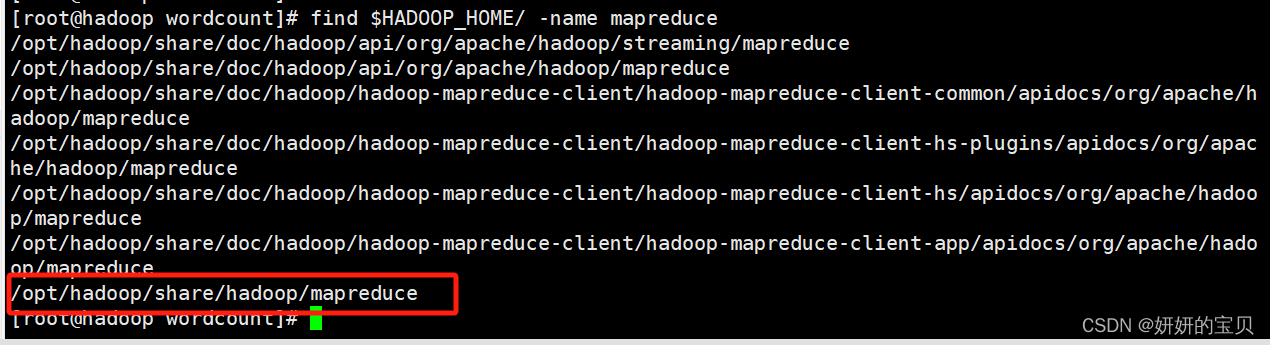
移动到这个目录下
[root@hadoop wordcount]# cd /opt/hadoop/share/hadoop/mapreduce/
[root@hadoop mapreduce]# ls
hadoop-mapreduce-client-app-3.3.6.jar hadoop-mapreduce-client-nativetask-3.3.6.jar
hadoop-mapreduce-client-common-3.3.6.jar hadoop-mapreduce-client-shuffle-3.3.6.jar
hadoop-mapreduce-client-core-3.3.6.jar hadoop-mapreduce-client-uploader-3.3.6.jar
hadoop-mapreduce-client-hs-3.3.6.jar hadoop-mapreduce-examples-3.3.6.jar
hadoop-mapreduce-client-hs-plugins-3.3.6.jar jdiff
hadoop-mapreduce-client-jobclient-3.3.6.jar lib-examples
hadoop-mapreduce-client-jobclient-3.3.6-tests.jar sources
找到一个叫hadoop-mapreduce-examples-3.3.6.jar 的文件
这个文件是hadoop自带的专门做词频统计的jar包
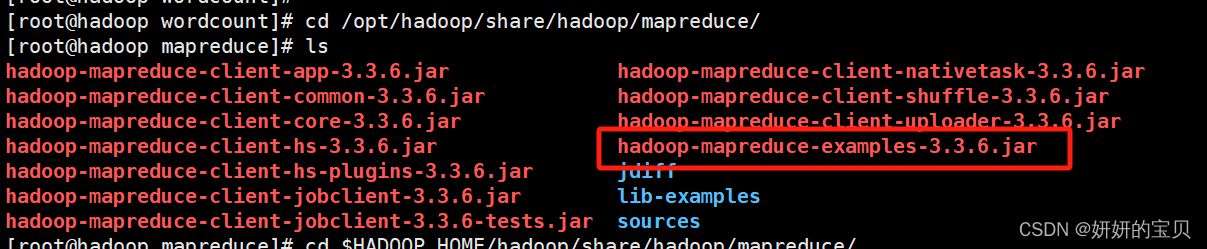
选择jar包运行java程序对文章进行词频统计
[root@hadoop mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.6.jar wordcount /input/words2.txt /output
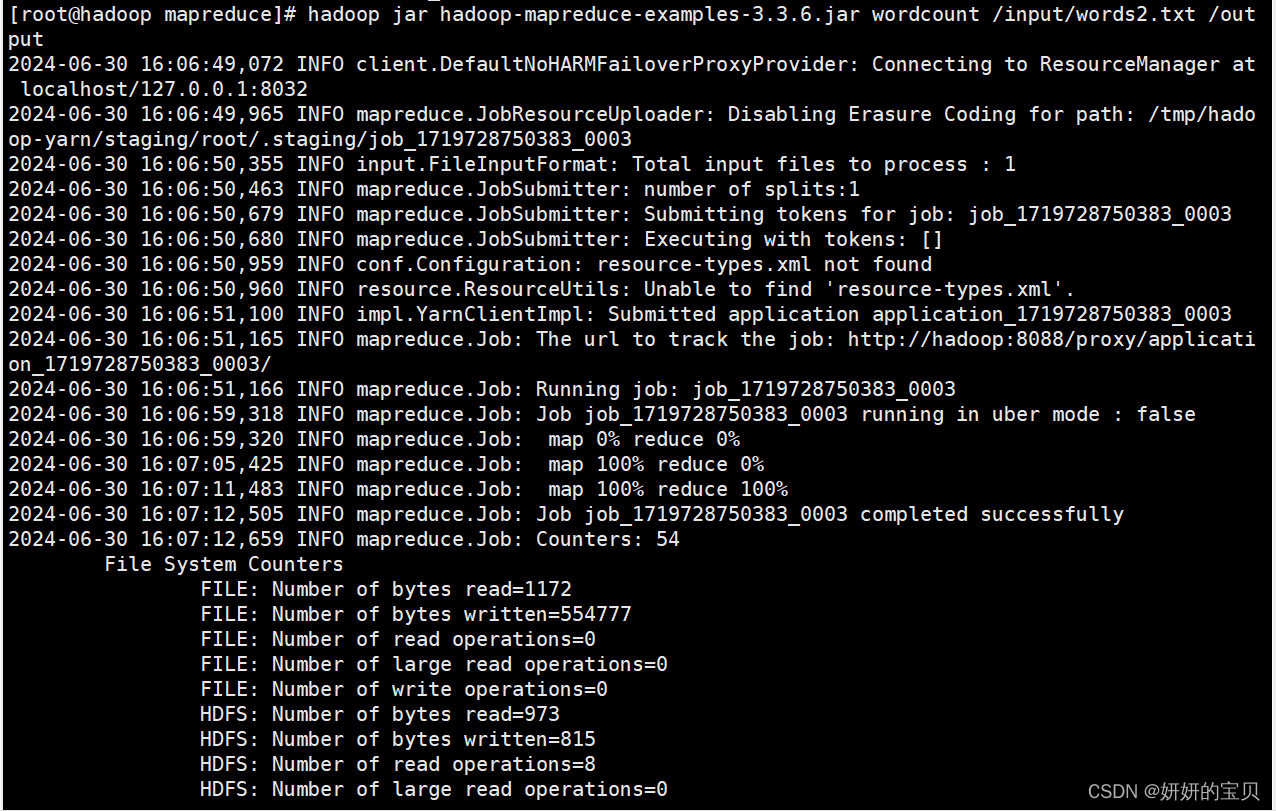
查看根目录多出了个output目录,点击他
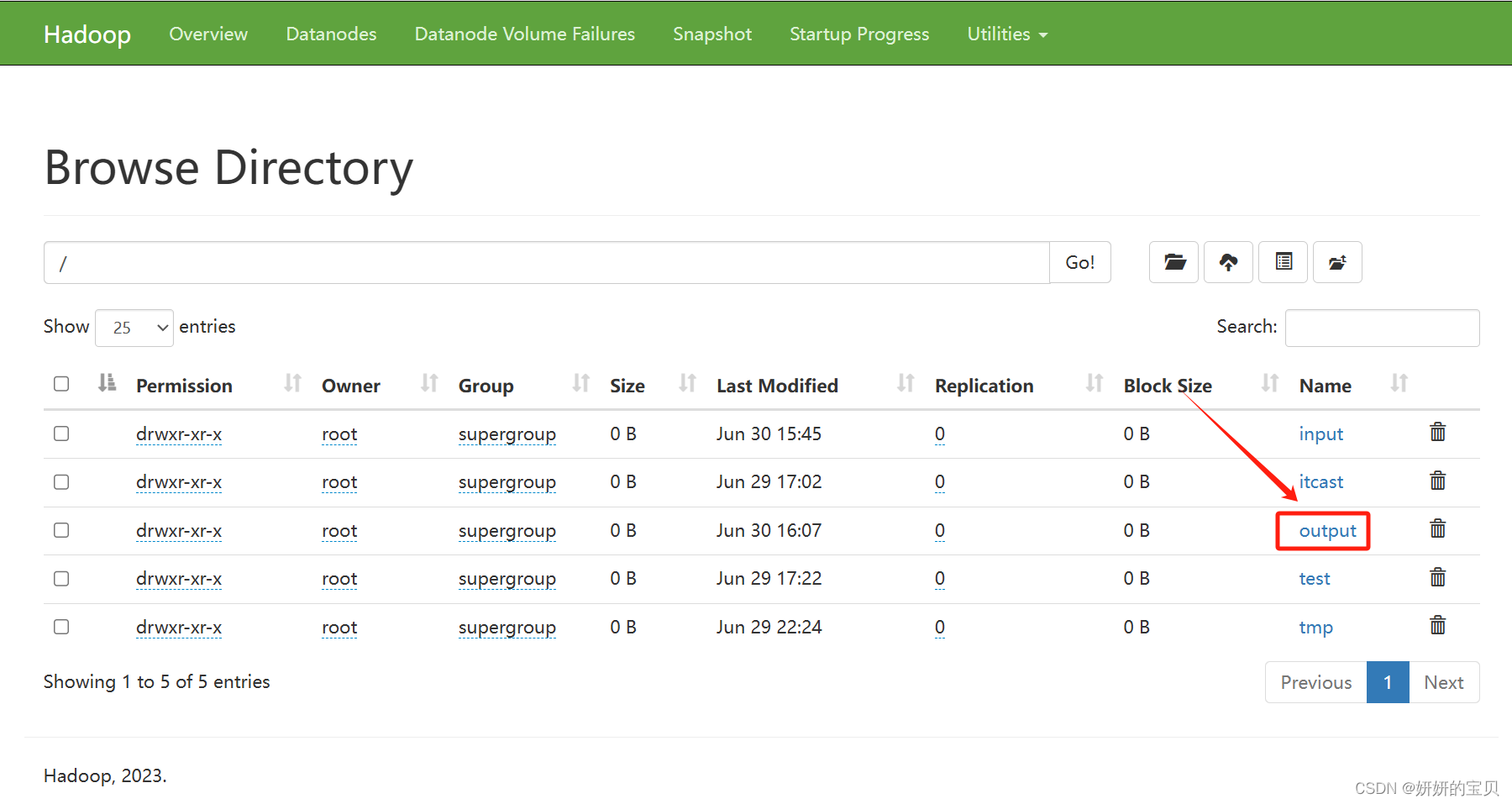
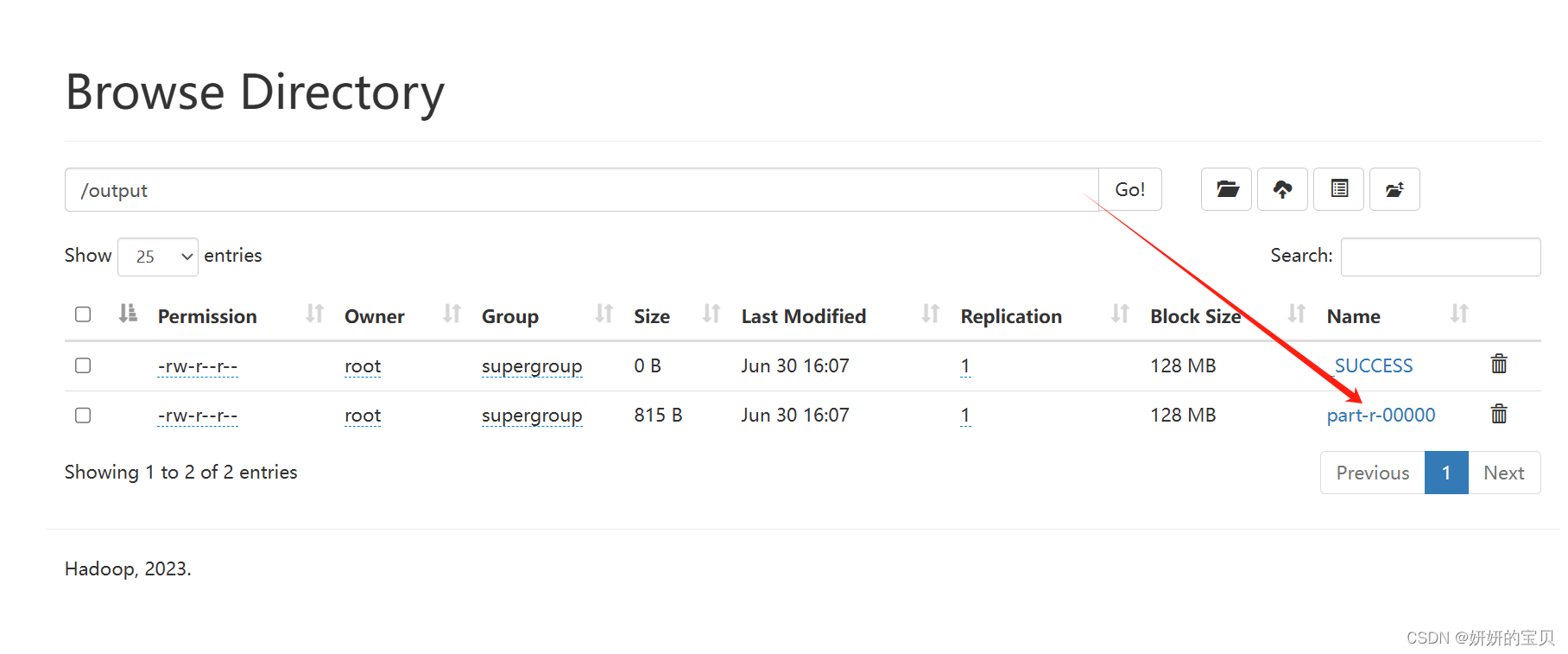
得出结果
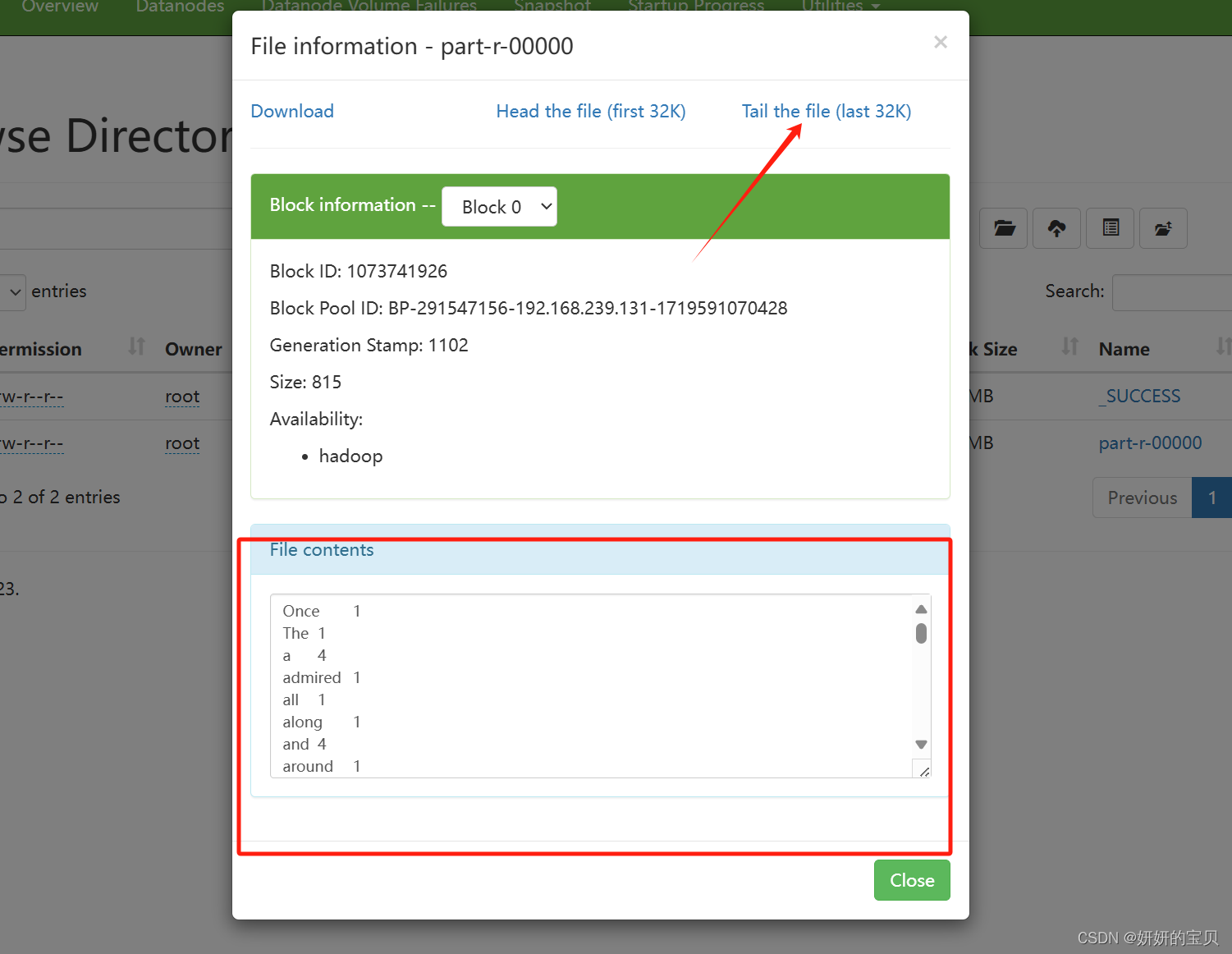
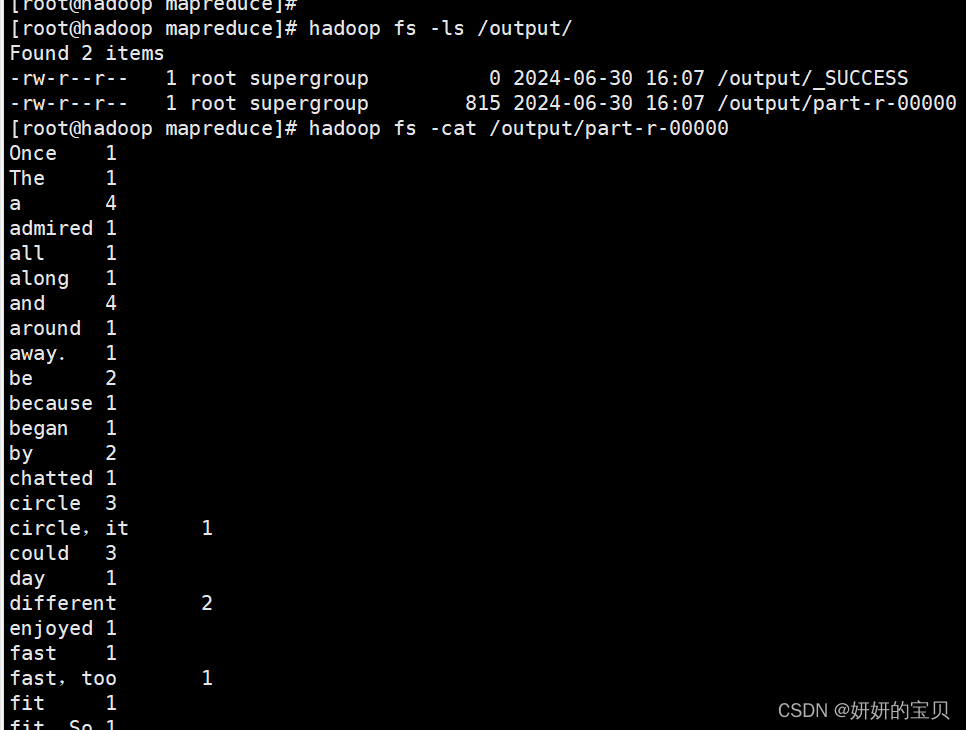
同样在虚拟机上也可查看
3.2 方法二:编写java程序打包jar包
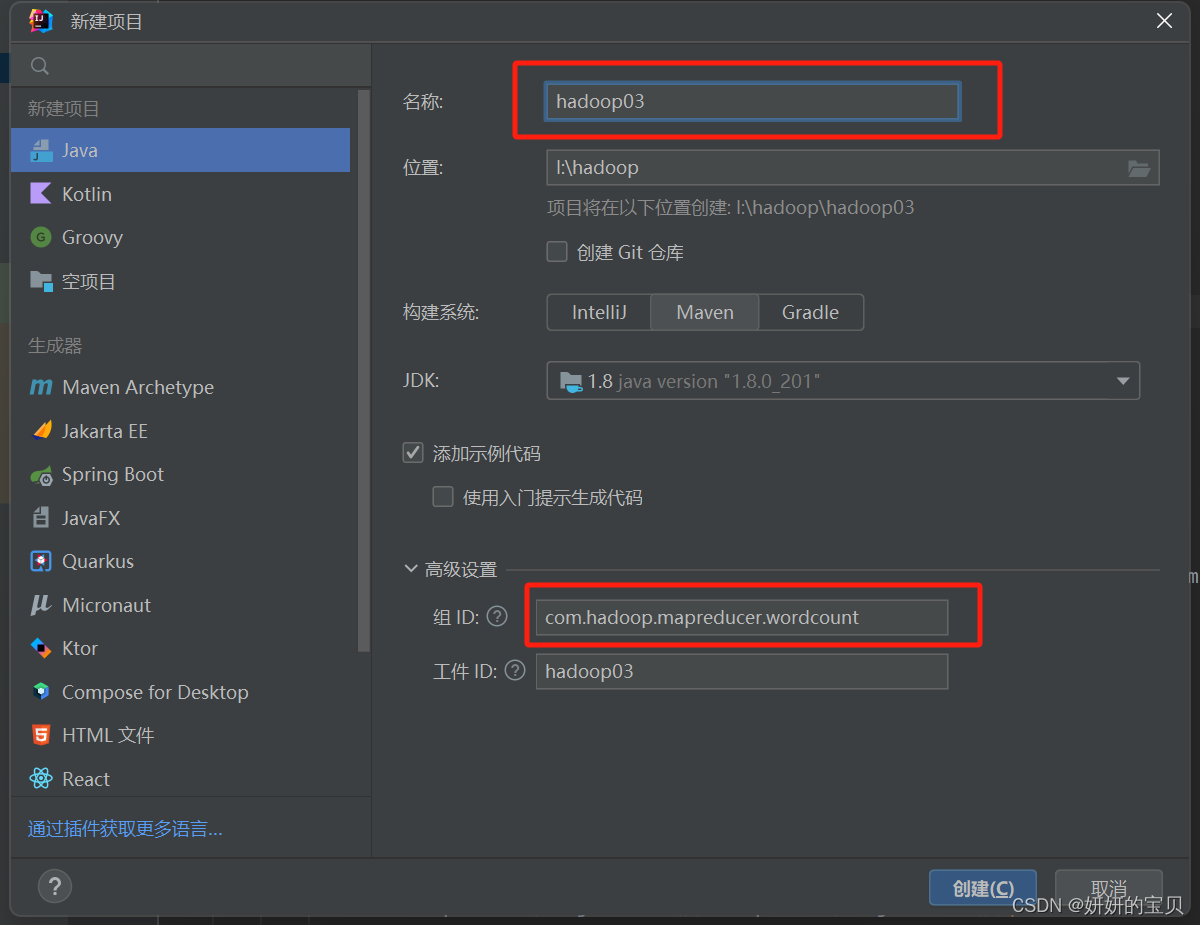
使用的软件为idea
新建项目
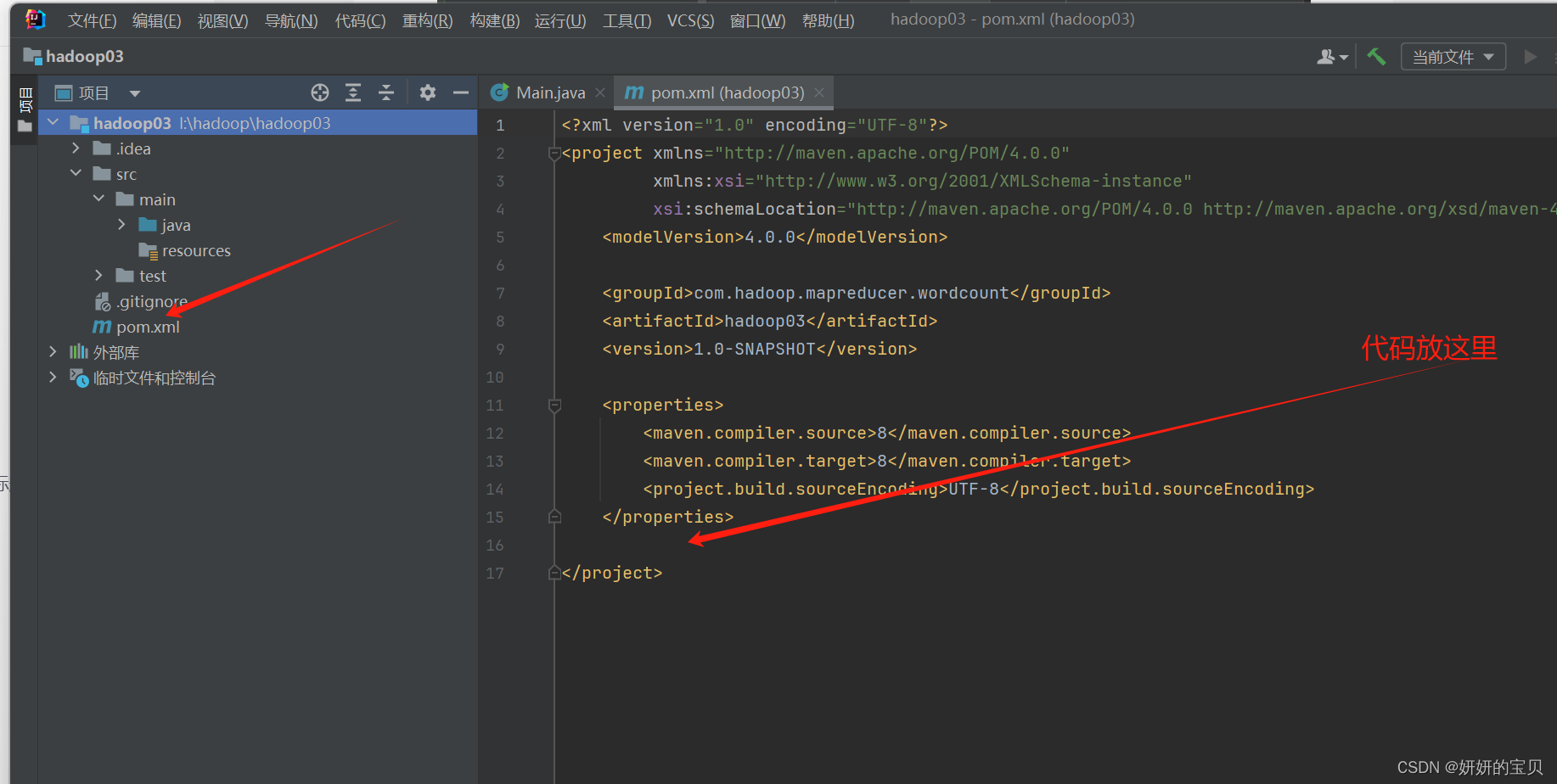
将以下代码插入pom.xml 中
<dependencies>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-client</artifactid>
<version>3.3.2</version>
</dependency>
<dependency>
<groupid>junit</groupid>
<artifactid>junit</artifactid>
<version>4.13.2</version>
</dependency>
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-log4j12</artifactid>
<version>1.7.36</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactid>maven-compiler-plugin</artifactid>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactid>maven-assembly-plugin</artifactid>
<configuration>
<descriptorrefs>
<descriptorref>jar-with-dependencies</descriptorref>
</descriptorrefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>插入之后点击

添加以下内容
log4j.rootlogger=info, stdout
log4j.appender.stdout=org.apache.log4j.consoleappender
log4j.appender.stdout.layout=org.apache.log4j.patternlayout
log4j.appender.stdout.layout.conversionpattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.fileappender
log4j.appender.logfile.file=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.patternlayout
log4j.appender.logfile.layout.conversionpattern=%d %p [%c] - %m%n编写java类
代码如下
wordcountdriver
package com.hadoop.mapreducer.wordcount;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.intwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.lib.input.fileinputformat;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
import java.io.ioexception;
public class wordcountdriver {
public static void main(string[] args) throws ioexception, interruptedexception, classnotfoundexception {
//1.获取job
configuration conf = new configuration();
job job = job.getinstance(conf);
//2.设置jar包路径
job.setjarbyclass(wordcountdriver.class);
//3.关联mapper和reducer
job.setmapperclass(wordcountmapper.class);
job.setreducerclass(wordcountreducer.class);
//4.设置map输出kv类型
job.setmapoutputkeyclass(text.class);
job.setmapoutputvalueclass(intwritable.class);
//5.设置最终输出kv类型
job.setoutputkeyclass(text.class);
job.setoutputvalueclass(intwritable.class);
//6.设置输入路径和输出路径
fileinputformat.setinputpaths(job,new path(args[0]));
fileoutputformat.setoutputpath(job,new path(args[1]));
//7.提交job
boolean result = job.waitforcompletion(true);
system.exit(result?0:1);
}
}wordcountmapper
package com.hadoop.mapreducer.wordcount;
import org.apache.hadoop.io.intwritable;
import org.apache.hadoop.io.longwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.mapper;
import java.io.ioexception;
public class wordcountmapper extends mapper<longwritable,text,text, intwritable> {
//为了节省空间,将k-v设置到函数外
private text outk=new text();
private intwritable outv=new intwritable(1);
@override
protected void map(longwritable key, text value, mapper<longwritable, text, text, intwritable>.context context) throws ioexception, interruptedexception {
//获取一行输入数据
string line = value.tostring();
//将数据切分
string[] words = line.split(" ");
//循环每个单词进行k-v输出
for (string word : words) {
outk.set(word);
//将参数传递到reduce
context.write(outk,outv);
}
}
}
wordcountreducer
package com.hadoop.mapreducer.wordcount;
import org.apache.hadoop.io.intwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.reducer;
import java.io.ioexception;
public class wordcountreducer extends reducer<text, intwritable,text,intwritable> {
//全局变量输出类型
private intwritable outv = new intwritable();
@override
protected void reduce(text key, iterable<intwritable> values,context context) throws ioexception, interruptedexception { //设立一个计数器
int sum=0;
//统计单词出现个数
for (intwritable value : values) {
sum+=value.get();
}
//转换结果类型
outv.set(sum);
//输出结果
context.write(key,outv);
}
}可能会出现报红
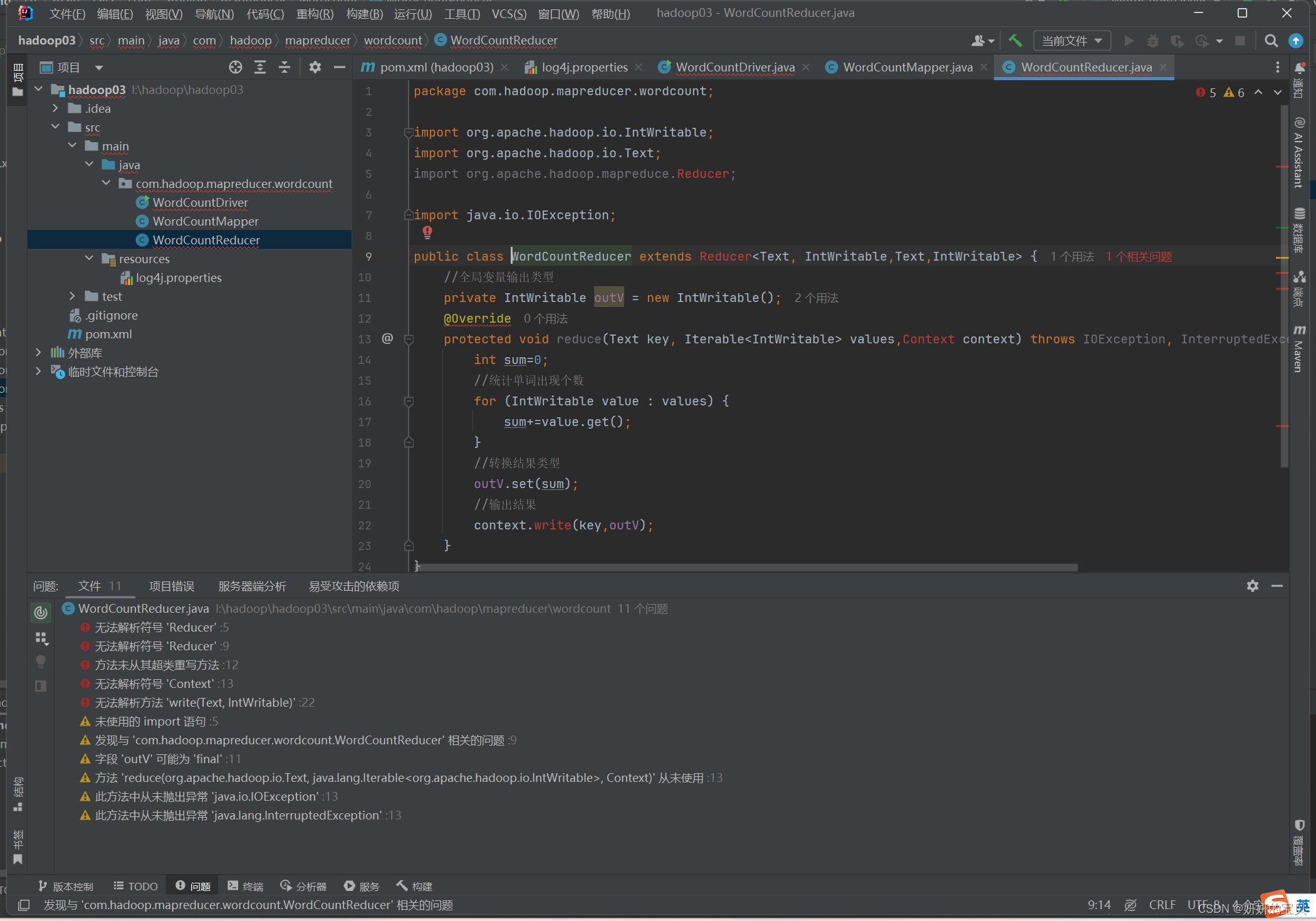
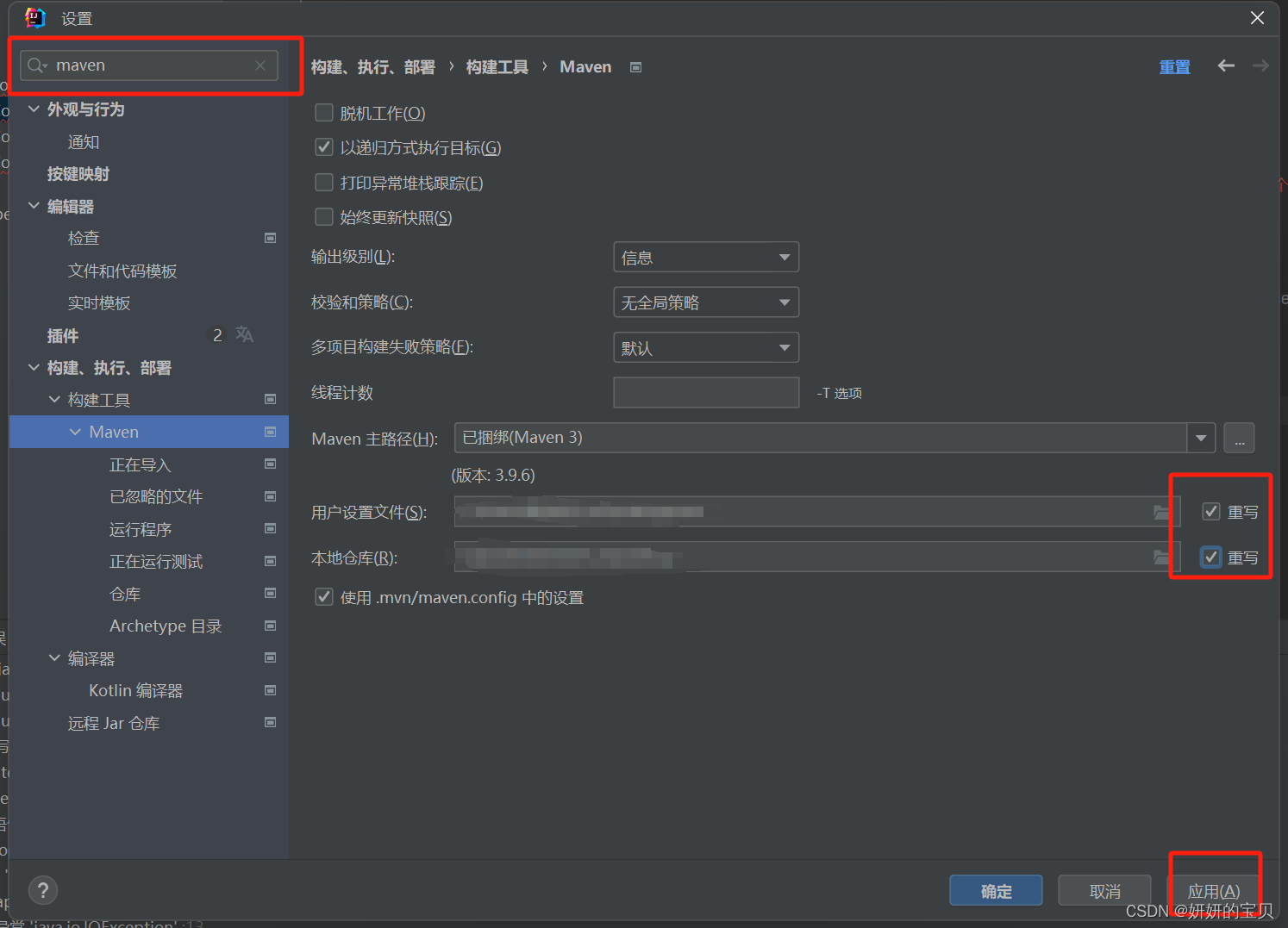
打包jar包

这时候会出现两个jar包使用第一个就可以了
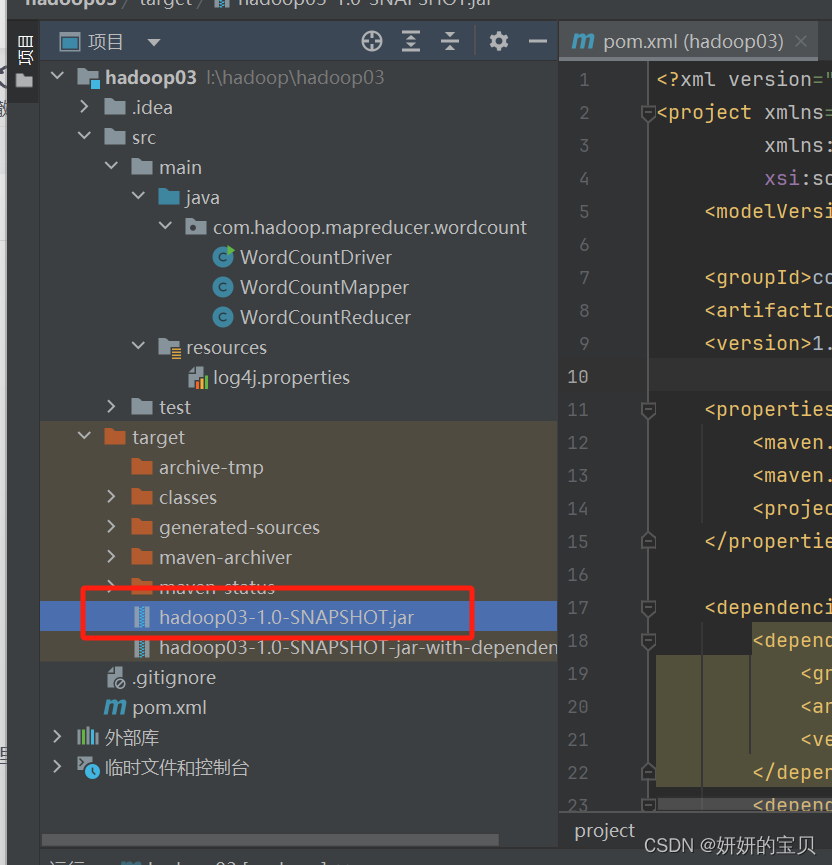
将jar包移动到linux下
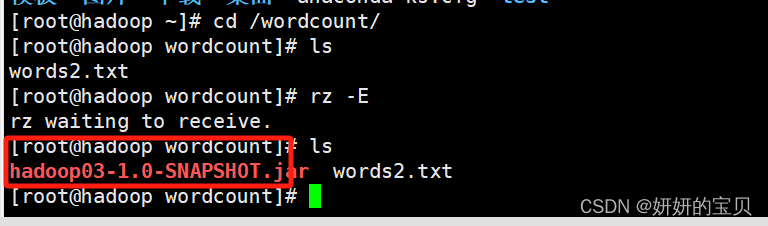
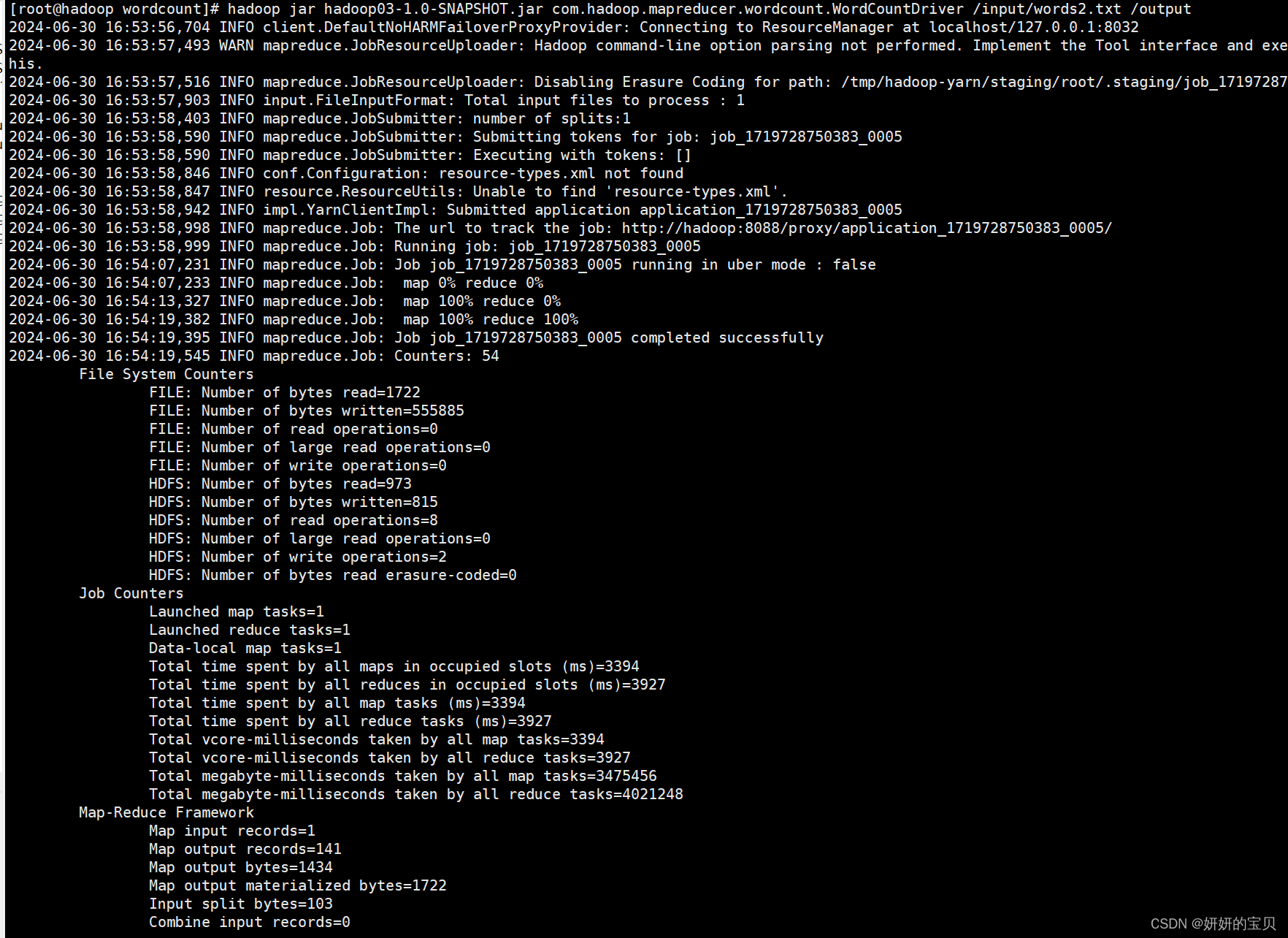
[root@hadoop wordcount]# hadoop jar hadoop03-1.0-snapshot.jar com.hadoop.mapreducer.wordcount.wordcountdriver /input/words2.txt /output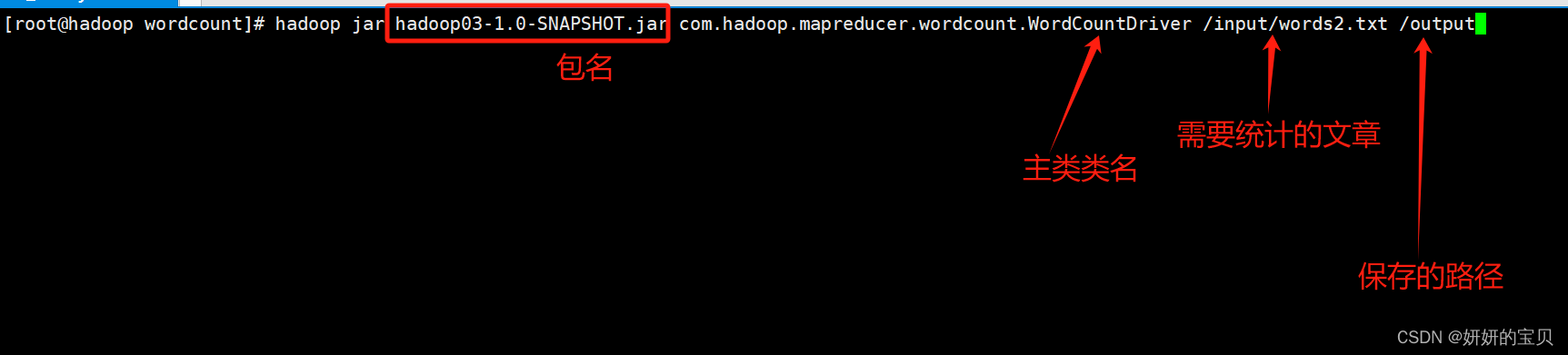
执行成功
动图演示





发表评论