目录
前言
在大数据的世界里,hadoop绝对是一个值得学习的框架。关于hadoop的知识,有很多博主和视频博主都做了很详细的教程,感兴趣的朋友甚至可以去官网看看。比如其分布式架构的实现,在这里都不在赘述,大家可以通过多种途径进行学习。
这篇博客出现得场景缘由是最近基于hbase2.4.11搭建完全分布式集群,集群的节点是3。至于为什么是3,主要是机器有限,而且是同一台物理主机上进行虚拟搭建的。hbase的底层存储是存放在hdfs中的,由此必须要安装hadoop。
众所周知,在完全分布式环境下,我们可以只在master节点上直接运行start-all.sh命令,整个集群都会自动启动。本文描述的是在hadoop3.1.3的完全分布式环境下,slave节点的datanode节点未能成功启动的问题以及通过修改配置来解决的办法,希望能帮助到遇到这个问题的朋友。请注意,由于不同的版本,可能解决办法不一致,请谨慎参考。博主就遇到过,在hadoop2.x的配置和hadoop3.x的配置不一致的问题。博文的参考仅限于hadoop3.x,如果您使用的不是这个系列的版本,那么您可以去别的地方寻找答案。
一、问题重现
1、查询hadoop版本
使用管理账号登录到系统,使用hadoop version可以查看版本。
[root@master bin]# hadoop version可以看到输出如下:
hadoop 3.1.3
source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
compiled by ztang on 2019-09-12t02:47z
compiled with protoc 2.5.0
from source with checksum ec785077c385118ac91aadde5ec9799
this command was run using /software/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
2、集群启动hadoop
登录master节点,进入hadoop的sbin目录,启动集群,参考命令如下:
[root@master bin]# cd /software/hadoop/sbin
[root@master sbin]# ./start-all.sh这里请注意,hadoop的安装目录,请根据实际目录进行修改,否则会影响运行。通常以上命令后会有以下输出。输出以下姓名就表示已经完成了hadoop的启动。
starting namenodes on [master]
上一次登录:三 12月 13 11:31:20 cst 2023pts/0 上
starting datanodes
上一次登录:三 12月 13 11:31:39 cst 2023pts/0 上
starting secondary namenodes [master]
上一次登录:三 12月 13 11:31:41 cst 2023pts/0 上
starting resourcemanager
上一次登录:三 12月 13 11:31:44 cst 2023pts/0 上
starting nodemanagers
上一次登录:三 12月 13 11:31:48 cst 2023pts/0 上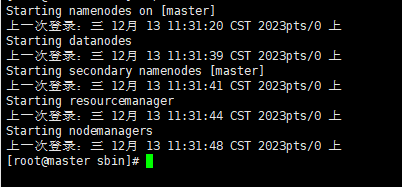
如果是正常的集群启动,那么master、slave1、slave2三台机器上都会有datanode进程。可以分别在三台机器上进行进程查询,这里使用jps命令。
master进程如下:
[root@master sbin]# jps
9351 namenode
1608 quorumpeermain
10537 jps
9755 secondarynamenode
10027 resourcemanager
10365 nodemanager
9535 datanode我们可以发现,master上,nodemanager、namenode、datanode服务都是正常的。然后登录到slave1和slave2两台服务器上,同样使用jps命令查看机器进程。
slave1上进程
[root@slave1 hadoop]# jps
4113 jps
1605 quorumpeermain同样的,在slave2上也是一样的问题,从节点的datanode并没有启动,这样子相当于集群启动失败。此时只有master一个节点进行对外提供服务,显然这不是很妙。
二、问题分析
其实出现这个问题的原因也比较简单,还是集群设置的问题。在进行大数据各个组件的学习时,一定要注意版本,不同的版本配置的方式不一样,有可能配置目录或者配置文件修改修改了。因此最好是按照官网的说明进行配置最好。本文描述的问题,是因为在hadoop3.x版本中,集群配置的设置文件是workers而不是slaves,slaves应该是之前的版本的集群配置。
三、hadoop3.x的集群配置
1、停止hadoop服务
执行以下命令,停止hadoop服务。
[root@master sbin]# ./stop-all.sh
stopping namenodes on [master]
上一次登录:三 12月 13 11:08:17 cst 2023pts/0 上
stopping datanodes
上一次登录:三 12月 13 11:31:13 cst 2023pts/0 上
stopping secondary namenodes [master]
上一次登录:三 12月 13 11:31:14 cst 2023pts/0 上
stopping nodemanagers
上一次登录:三 12月 13 11:31:16 cst 2023pts/0 上
stopping resourcemanager
上一次登录:三 12月 13 11:31:18 cst 2023pts/0 上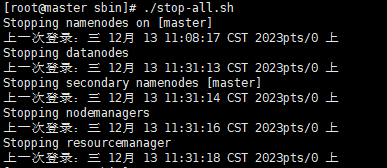
2、配置workers
![]()
capacity-scheduler.xml hadoop-env.cmd hadoop-user-functions.sh.example httpfs-signature.secret kms-log4j.properties mapred-env.sh slaves workers yarn-site.xml
configuration.xsl hadoop-env.sh hdfs-site.xml httpfs-site.xml kms-site.xml mapred-queues.xml.template ssl-client.xml.example yarn-env.cmd
container-executor.cfg hadoop-metrics2.properties httpfs-env.sh kms-acls.xml log4j.properties mapred-site.xml ssl-server.xml.example yarn-env.sh
core-site.xml hadoop-policy.xml httpfs-log4j.properties kms-env.sh mapred-env.cmd shellprofile.d user_ec_policies.xml.template yarnservice-log4j.properties首先使用cat命令查看默认的配置,
cat workers可以看到workers的内容如下:
localhost即默认的情况下,hadoop在本机启动,不加入分布式集群,因此无法随着集群的启动而启动。所以我们要把机器加入到集群环境中,在workers文件中,将master、slave1、slave2追加进去。
vi workersmaster
slave1
slave2配置完成后,可以使用scp命令复制到slave1和slave2节点,也可以使用同样的方式进行修改。修改完成后保存相应配置。最后到master的机器上,重启集群。
[root@master sbin]# ./start-all.shstarting namenodes on [master]
上一次登录:三 12月 13 11:31:20 cst 2023pts/0 上
starting datanodes
上一次登录:三 12月 13 11:31:39 cst 2023pts/0 上
starting secondary namenodes [master]
上一次登录:三 12月 13 11:31:41 cst 2023pts/0 上
starting resourcemanager
上一次登录:三 12月 13 11:31:44 cst 2023pts/0 上
starting nodemanagers
上一次登录:三 12月 13 11:31:48 cst 2023pts/0 上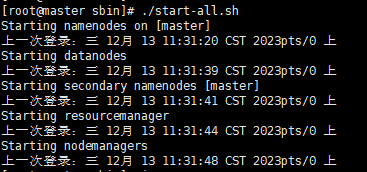
3、从节点检测
在master节点上运行start-all.sh后,分别在slave1、slave2两台机器上进行进程检测。执行命令如下:
[root@slave1 hadoop]# jps
3841 datanode
4145 jps
1605 quorumpeermain
3960 nodemanager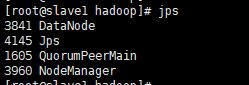
我们发现,datanode和nodemanager进程都已经正常启动,slave2也是一样的。由此,hadoop3.x集群服务完全启动。
4、webui监控
除了使用命令行的方式监控hadoop,其内部也提供了webui的监控方式。
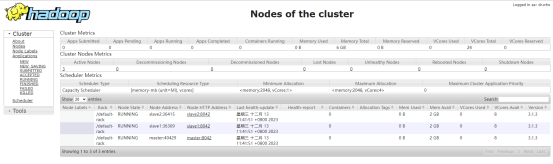

总结
以上就是本文的主要内容,本文描述的是在hadoop3.1.3的完全分布式环境下,slave节点的datanode节点未能成功启动的问题以及通过修改配置来解决的办法,希望能帮助到遇到这个问题的朋友。行文仓促,有很多不当之处,请朋友们批评指正。





发表评论