目录
此为个人学习笔记,包含个人归纳总结以及结合了对网络资源的整理,初衷是为了自己复习巩固。如果能帮到各位是我的荣幸!
该总结参考了黑马教程,感兴趣的也可以去观看相关视频。第二章-01-[理解]为什么需要分布式存储_哔哩哔哩_bilibili
分布式文件系统hdfs安装篇
一、为什么海量数据需要分布式存储
假如某个文件有100tb,试想哪台服务器能存下这么大的文件?
所以我们会搭建分布式服务集群,将这100tb的文件分成几份,分别发送到不同的服务器上。
当然,分布式不仅仅是解决了能存的问题, 多台服务器协同工作带来的也是性能的横向扩展。
也相当于是磁盘写入效率、传输效率的大大增加。
数据量太大,单机存储能力有上限,需要靠数量来解决问题。
数量的提升带来的是网络传输、磁盘读写、cpu、内存等各方面的综合提升。 分布式组合在一起可以达到1+1>2的效果。
二、 分布式的基础架构分析
数量多,在现实生活中往往带来的不是提升,而是:混乱。
众多的服务器一起工作,是如何高效、不出问题呢?
大数据体系中,分布式的调度主要有2类架构模式:去中心化模式和中心化模式。
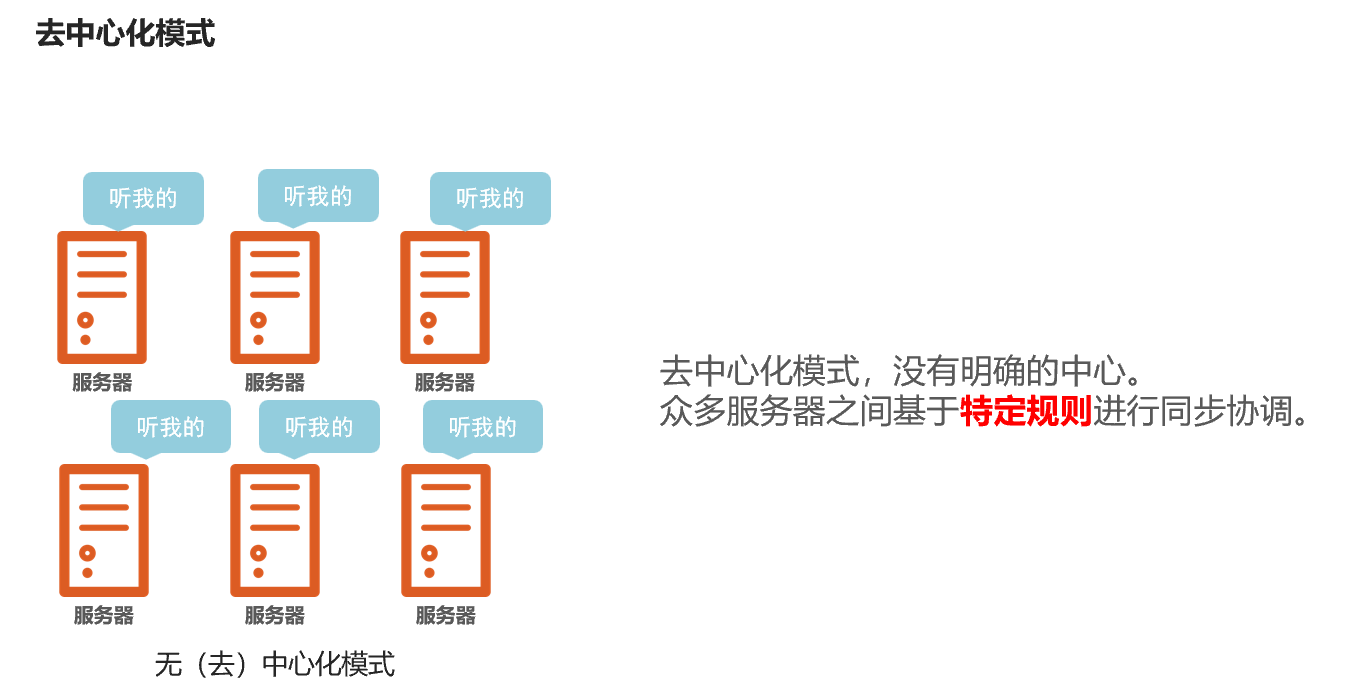
-
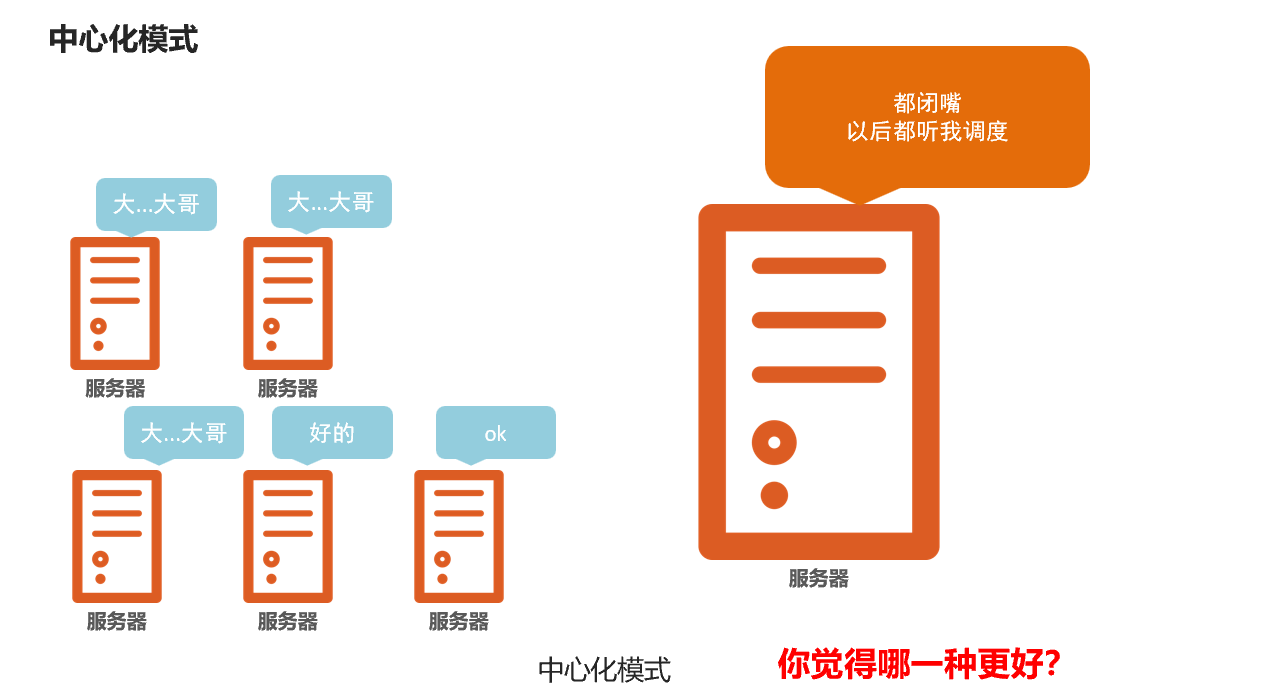
大数据框架,大多数的基础架构上,都是符合:中心化模式的。
即:有一个中心节点(服务器)来统筹其它服务器的工作,统一指挥,统一调派,避免混乱。
这种模式,也被称之为:一主多从模式,简称主从模式(master and slaves)
-
三、 hdfs的基础架构
-
hdfs是hadoop三大组件(hdfs、mapreduce、yarn)之一。
-
全称是:hadoop distributed file system(hadoop分布式文件系统)。
-
它是hadoop技术栈内提供的分布式数据存储解决方案。
-
可以在多台服务器上构建存储集群,存储海量的数据。
-
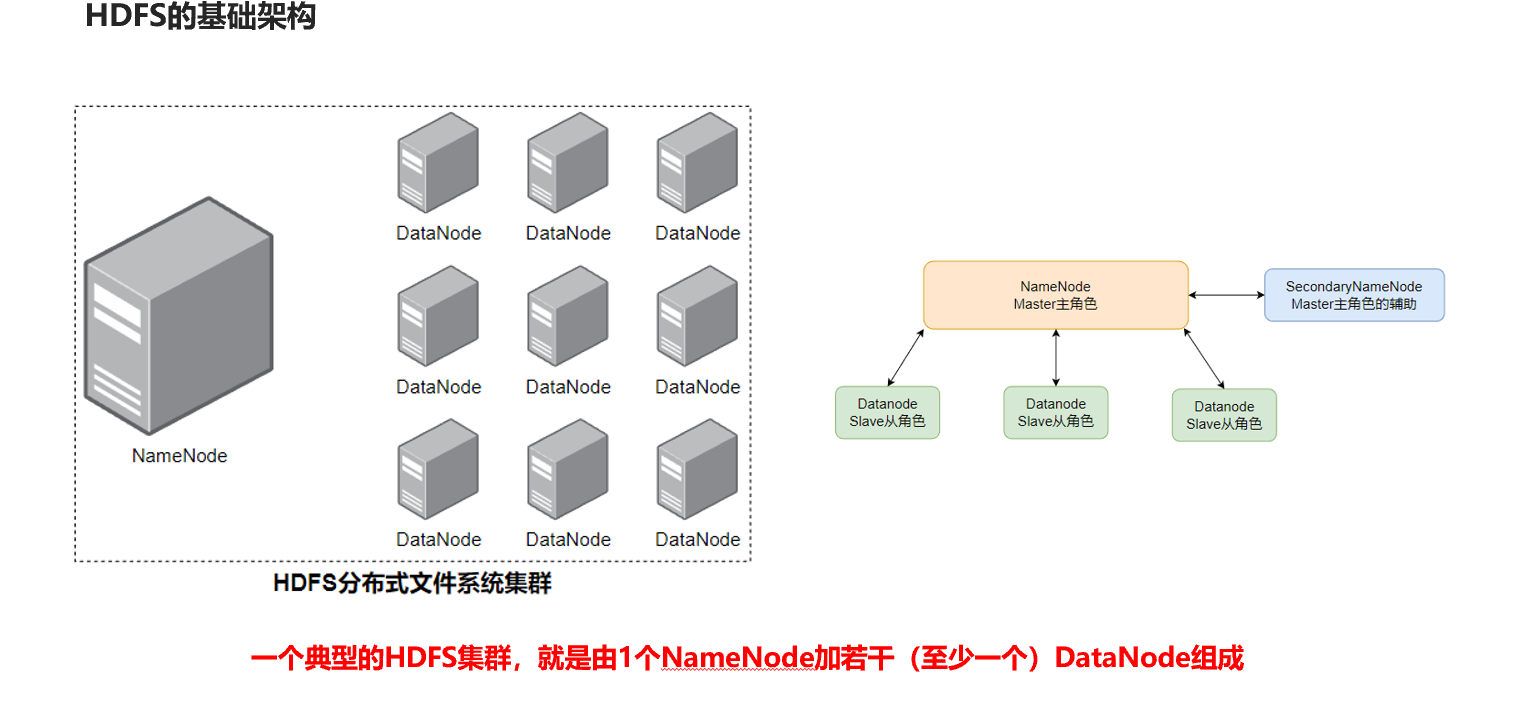
hdfs是一个典型的主从模式架构
-
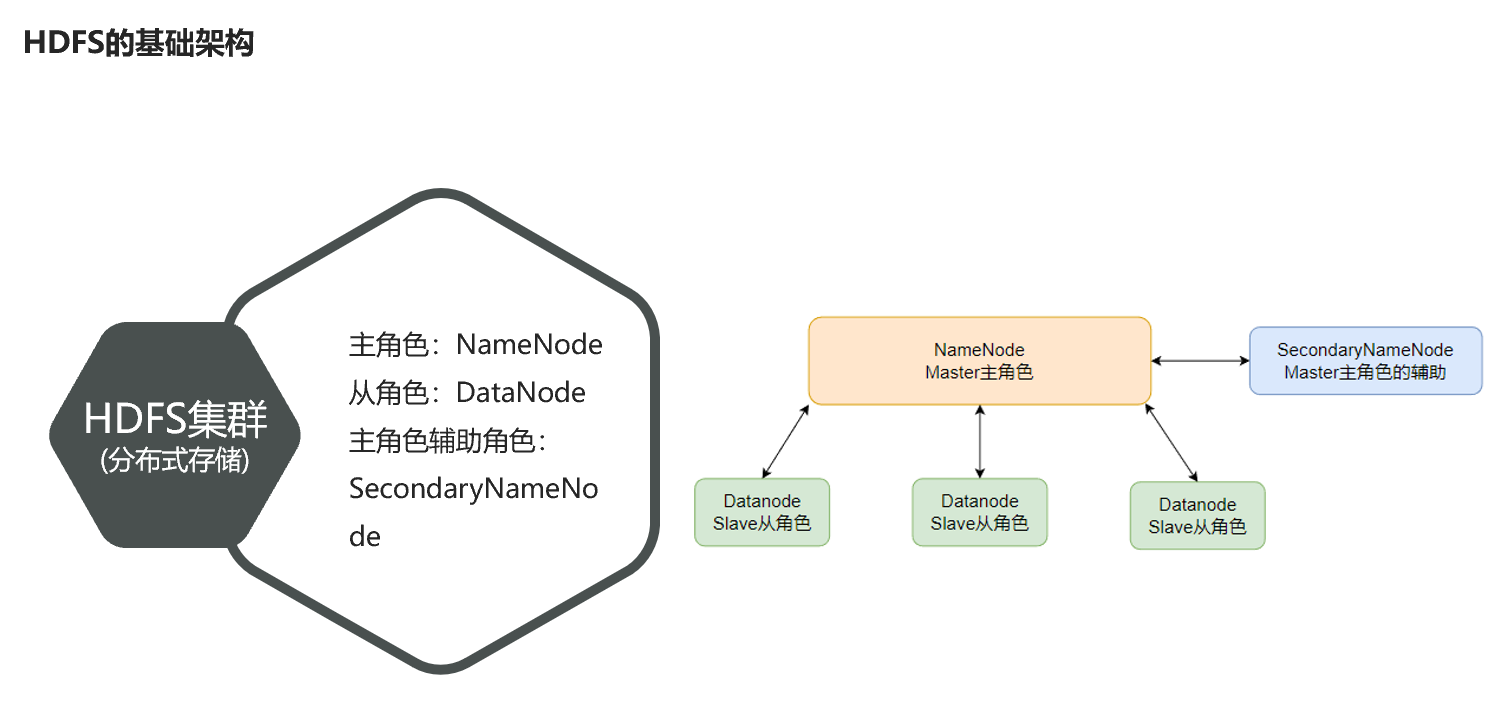
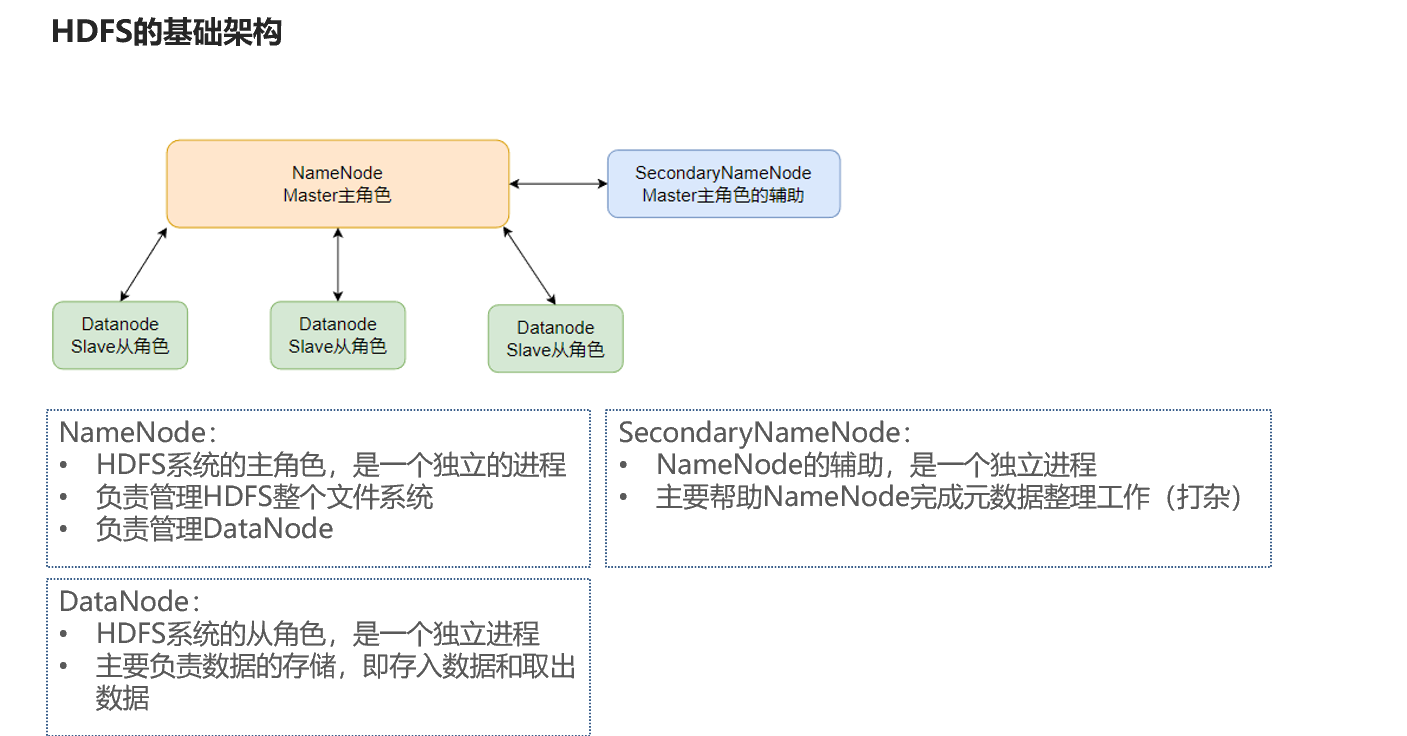
namenode:主角色,管理hdfs集群和datanode角色
-
datanode:从角色,负责数据的存储
-
secondarynamenode:辅助角色,协助namenode整理元数据
-
-
四 hdfs集群环境部署
-
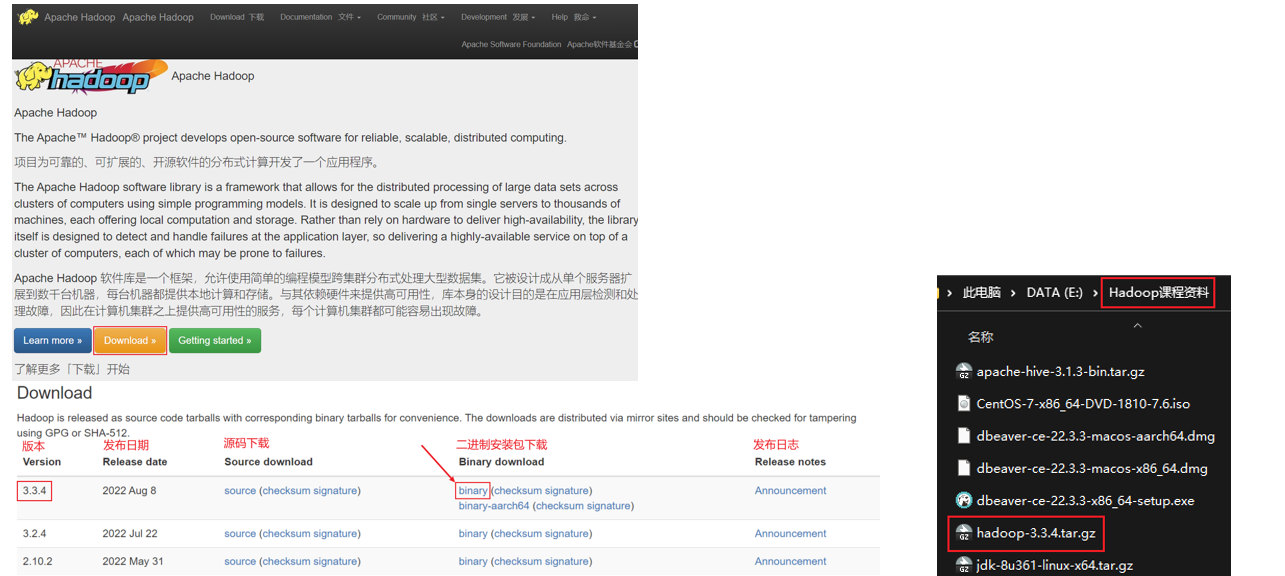
4.1 下载安装包
-
官方网址:https://hadoop.apache.org,课程使用当前最新的发行版:3.3.4版。
-
-
-
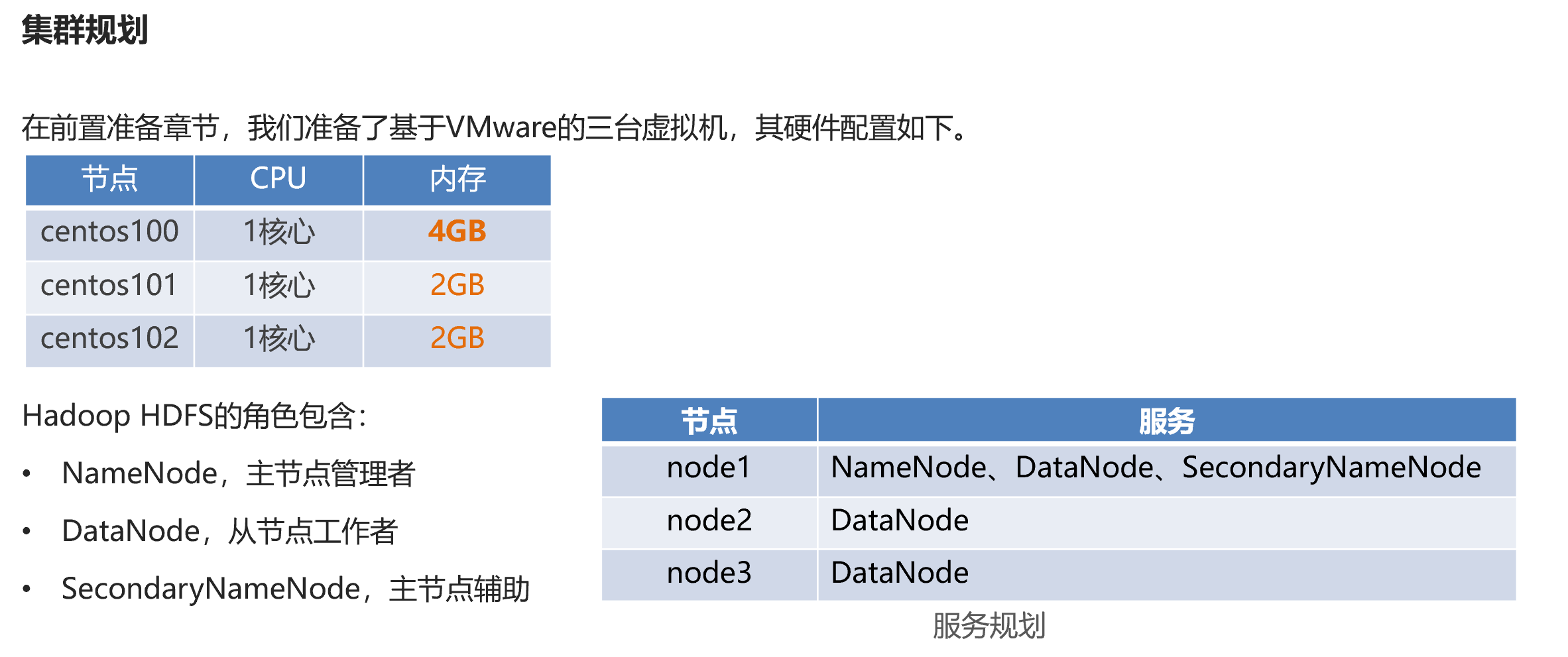
4.2 集群规划
4.3 上传解压
-
请确认已经完成前置准备中的服务器创建、固定ip、防火墙关闭、hadoop用户创建、ssh免密、jdk部署等操作。
-
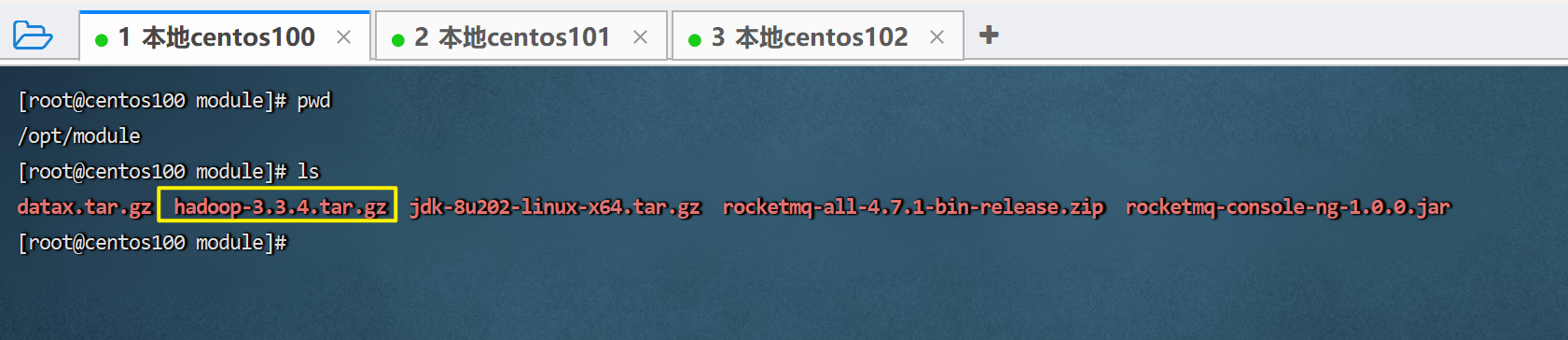
1. 上传hadoop安装包到centos100节点中
-
-
2. 解压缩安装包到/opt/software/hadoop/中
-
tar -zxvf hadoop-3.3.4.tar.gz -c /opt/software/hadoop/
-
3. 进入hadoop-3.3.4内

各个文件夹含义如下
-
bin,存放hadoop的各类程序(命令)
-
etc,存放hadoop的配置文件
-
include,c语言的一些头文件
-
lib,存放linux系统的动态链接库(.so文件)
-
libexec,存放配置hadoop系统的脚本文件(.sh和.cmd)
-
licenses-binary,存放许可证文件
-
sbin,管理员程序(super bin)
-
share,存放二进制源码(java jar包)
4.4 配置hdfs集群
配置hdfs集群,我们主要涉及到如下文件的修改:
- workers: 配置从节点(datanode)有哪些
- hadoop-env.sh: 配置hadoop的相关环境变量
- core-site.xml: hadoop核心配置文件
- hdfs-site.xml: hdfs核心配置文件
这些文件均存在与$hadoop_home/etc/hadoop文件夹中。
ps:$hadoop_home是后续我们要设置的环境变量,其指代hadoop安装文件夹即/export/server/hadoop
进入安装目录下的etc/hadoop目录。这里面存放了hadoop的配置。编辑workers文件。
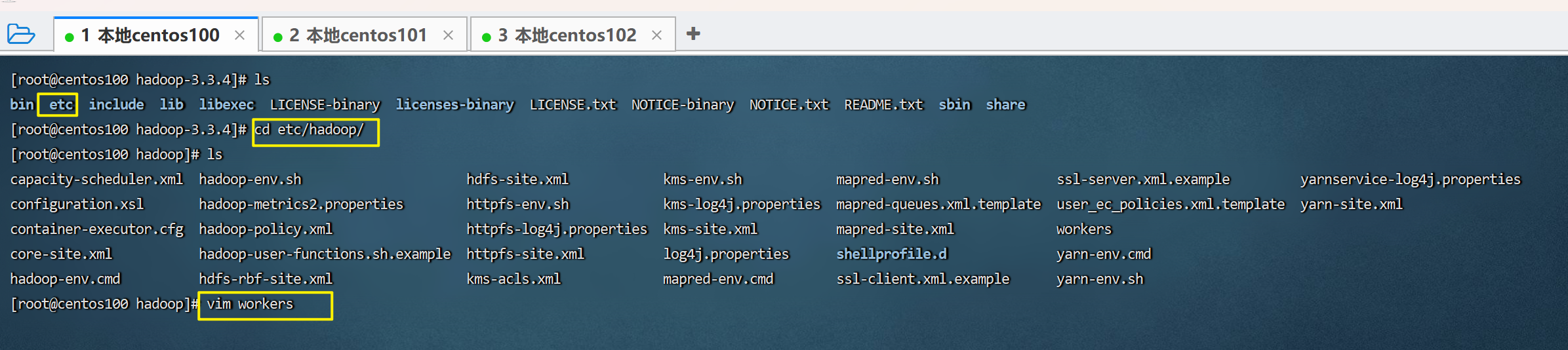
设置为我们的服务器名称,表示集群记录了这三个节点。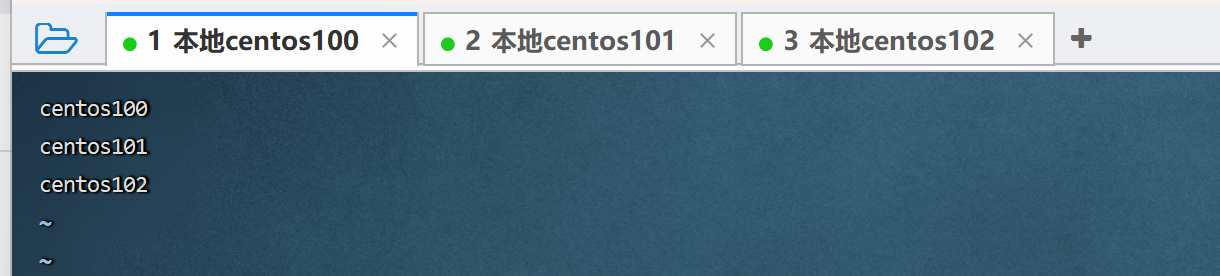
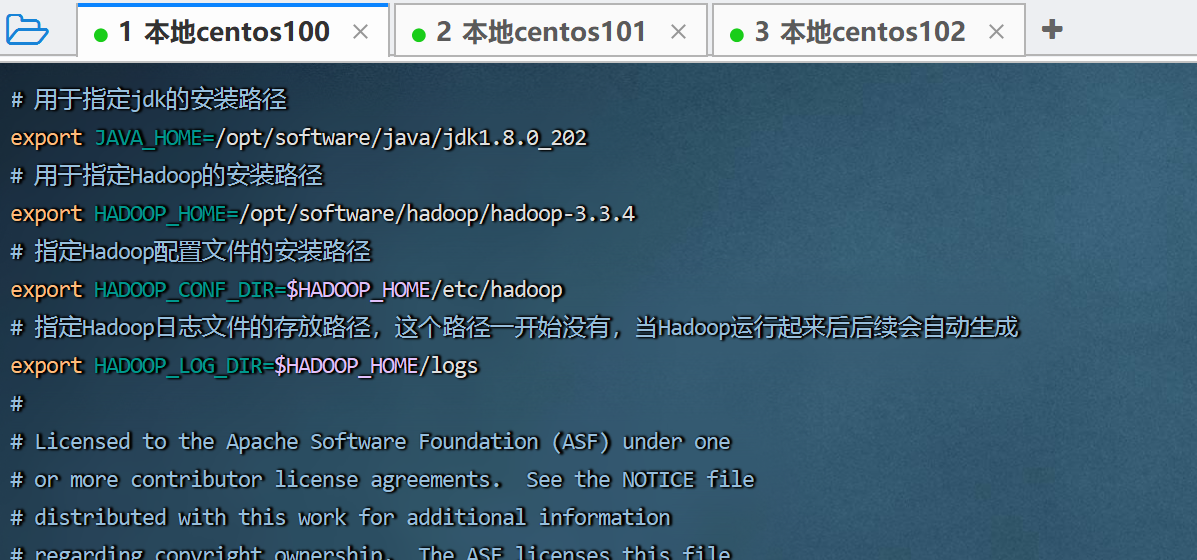
这个文件是hadoop在运行时需要使用到的一些环境变量
# 填入如下内容
export java_home=/opt/software/jdk
export hadoop_home=/opt/software/hadoop/hadoop-3.3.4
export hadoop_conf_dir=$hadoop_home/etc/hadoop
export hadoop_log_dir=$hadoop_home/logs
-

-
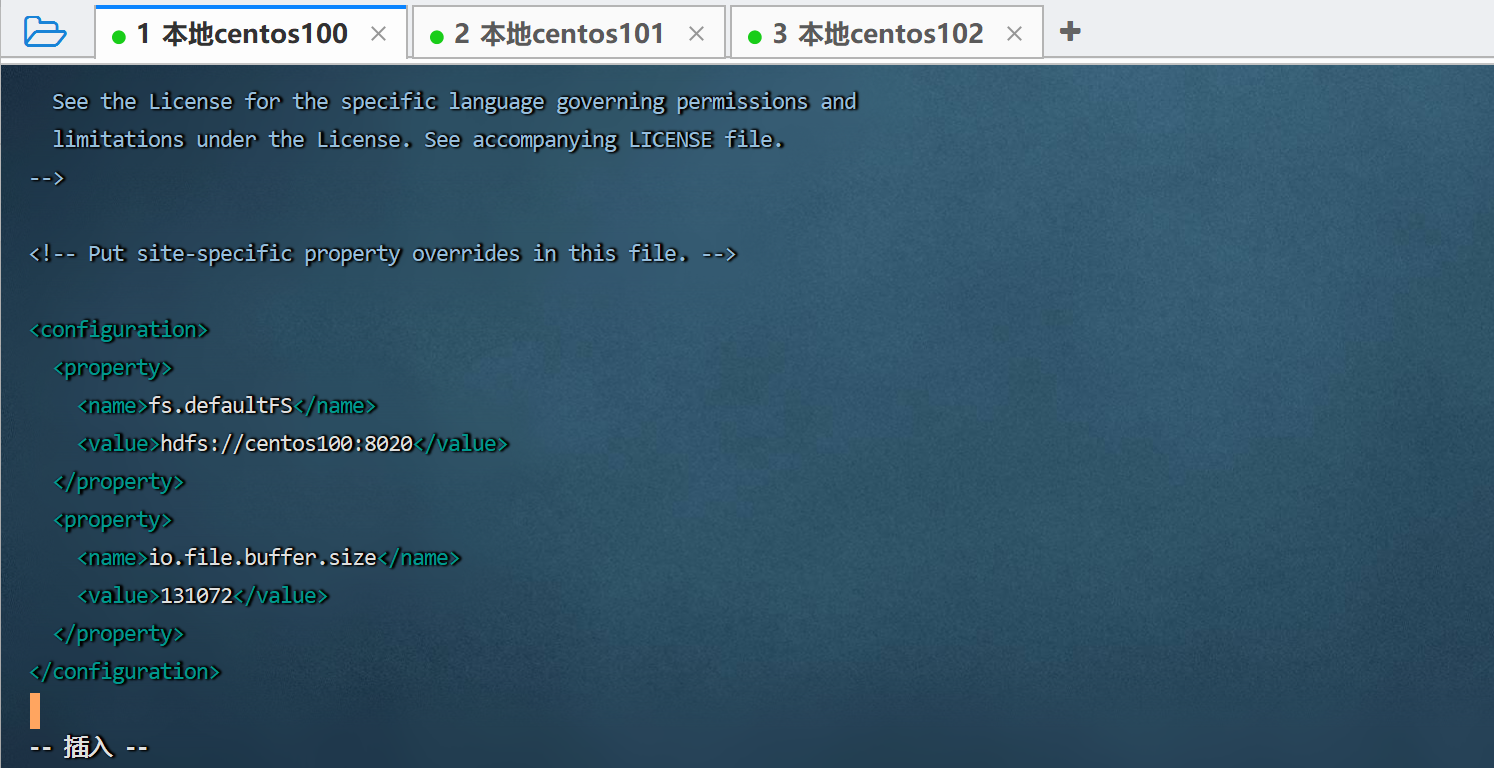
hadoop的核心配置文件,主要配置hdfs文件系统的网络通讯地址和io操作文件缓冲区大小。
-
端口号一般大家都是用的8020,一般不建议更改。
<configuration>
<property>
<name>fs.defaultfs</name>
<value>hdfs://centos100:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
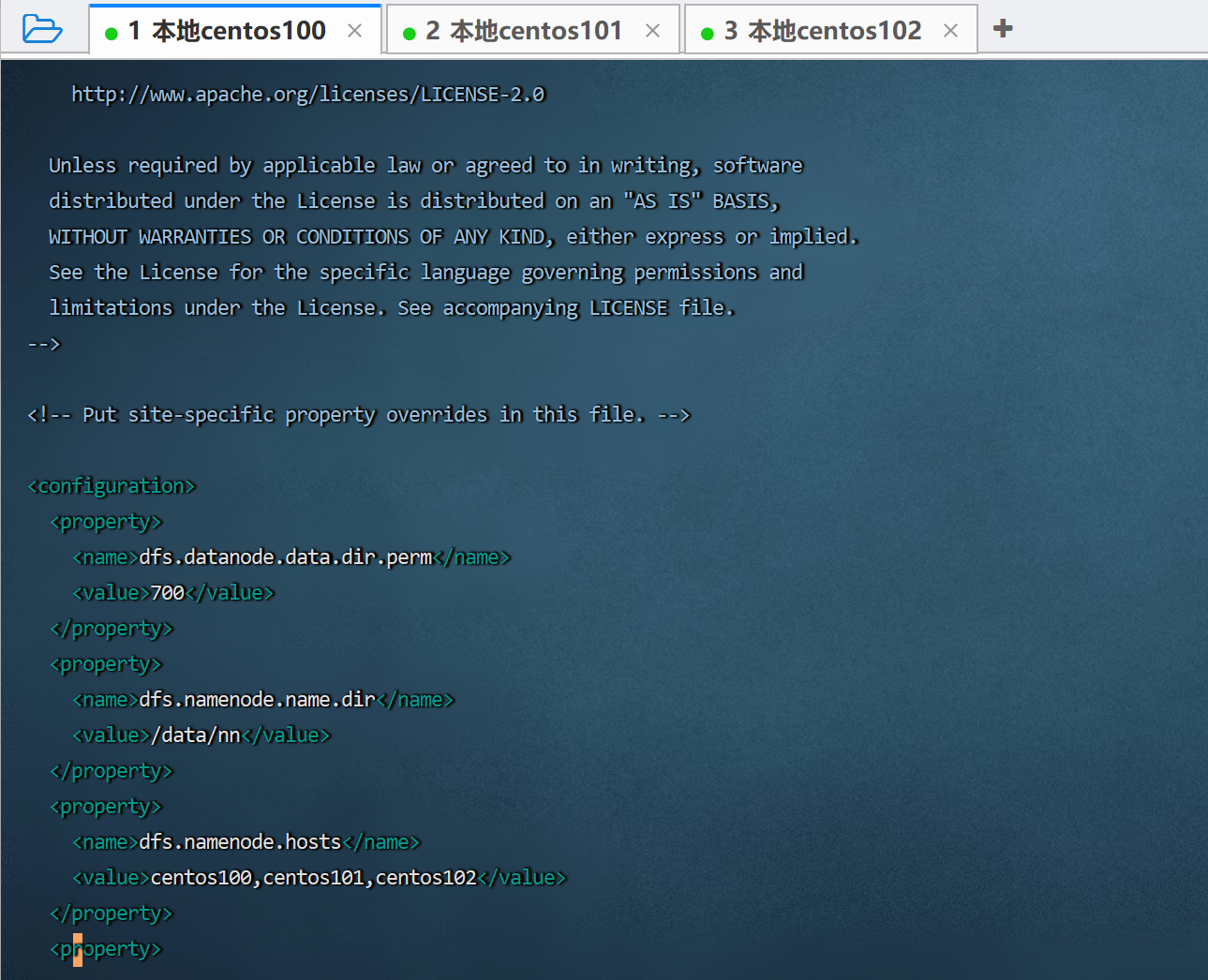
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>centos100,centos101,centos102</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>-

-

4.5 准备数据目录
-
刚刚配置文件种规定了namenode和datanode的文件存储位置,但是还没有创建该目录。所以接下来我们需要创建目录。
-
在centos100节点:
-
mkdir -p /data/nn mkdir /data/dn在centos101节点和centos102节点:
-
mkdir -p /data/dn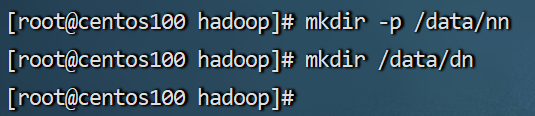
-
4.6 分发hadoop到其他服务器
刚才我们安装、配置都是在centos100这台服务器上的,但是centos101和centos102这两台都还没有安装过hadoop,显然是不行的。
所以,我们可以通过分发的方式,将hadoop分发到centos101和centos102这两台服务器上。
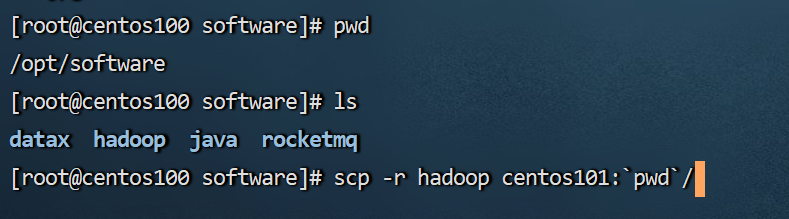
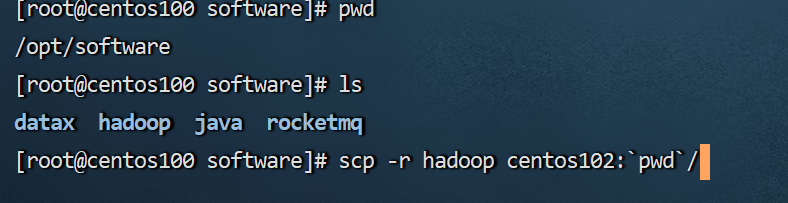
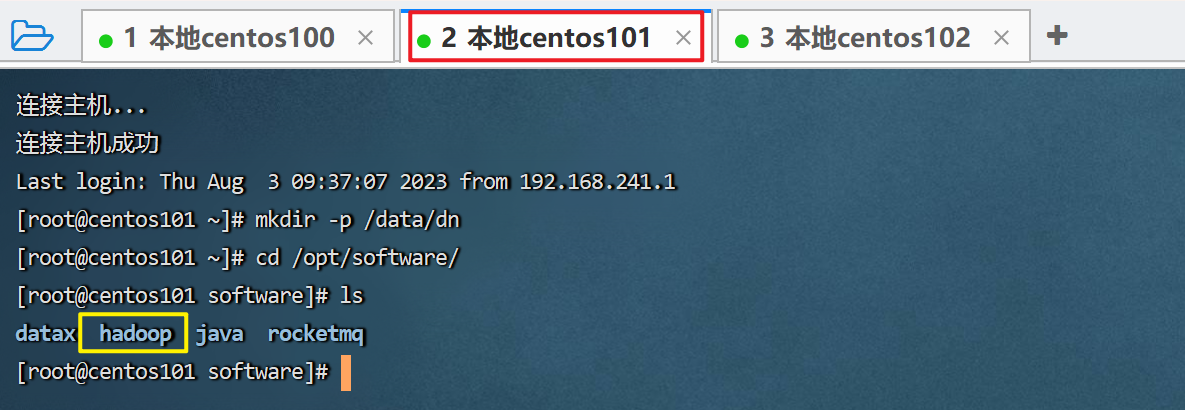
执行的时间可能比较长,要耐心等待。
执行完毕后,我们去centos101和centos102这两台服务器看看,分发过来没。
4.7 配置环境变量
我们操作hadoop的可执行命令,需要进入到它的bin目录下,然后执行对应的命令。
但是我们觉得这样太麻烦了,能不能在任何地方都可以直接执行命令呢,当然可以。
这需要我们配置环境变量。
修改/etc/profile文件
vim /etc/profileexport hadoop_home=/opt/software/hadoop/hadoop-3.3.4 export path=$path:$hadoop_home/bin:$hadoop_home/sbin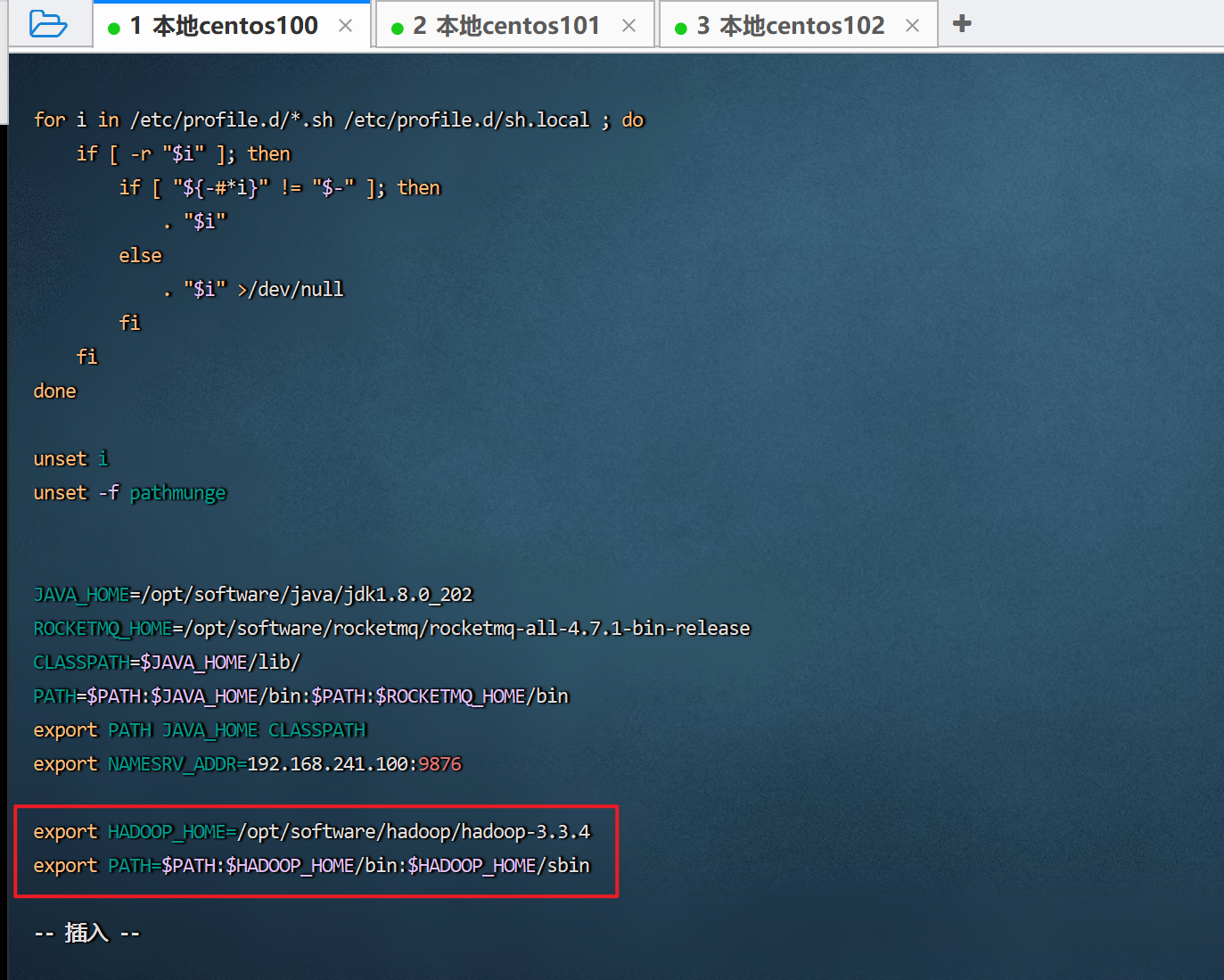
让环境变量生效
source /etc/profile
然后在另外两台服务器中都同样配置一下。
4.8 为普通用户授权
hadoop部署的准备工作基本完成
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个hadoop服务
所以,现在需要对文件权限进行授权。
ps:请确保已经提前创建好了hadoop用户(前置准备章节中有讲述),并配置好了hadoop用户之间的免密登录
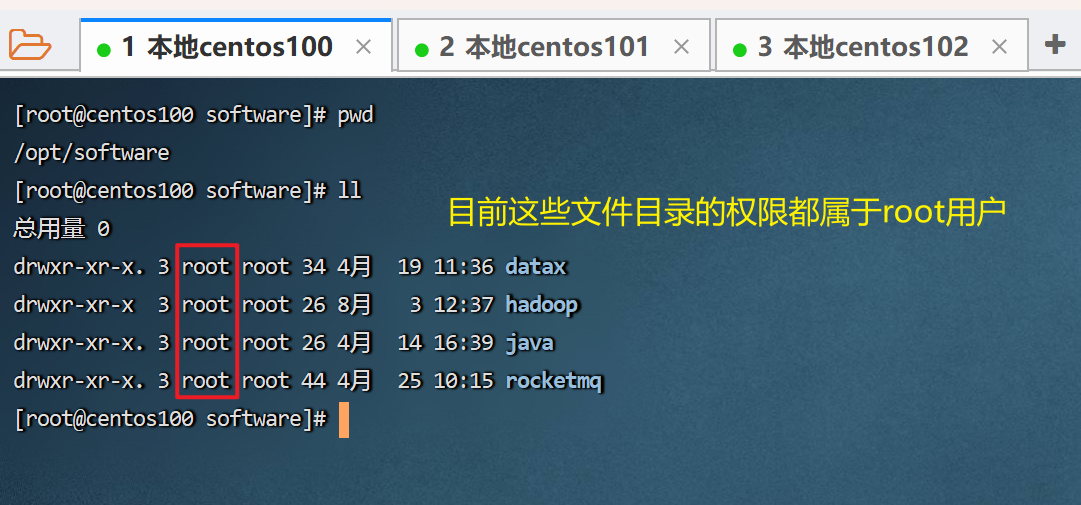
以root身份,在centos100、centos101、centos102三台服务器上均执行如下命令:
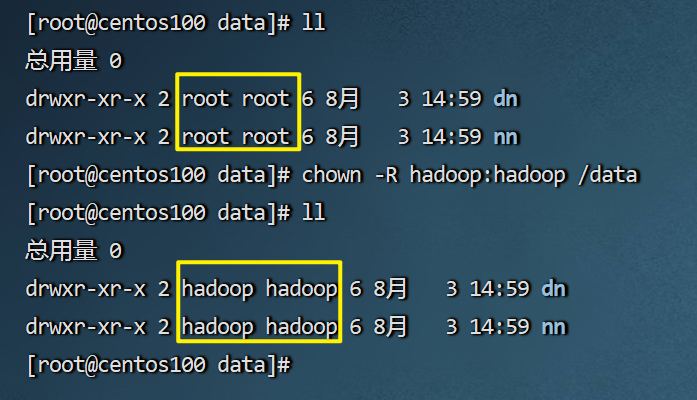
# 以root身份,在三台服务器上均执行 chown -r hadoop:hadoop /data chown -r hadoop:hadoop /opt-r 表示对子文件夹全部执行更改
前一个hadoop表示账号,冒号后的hadoop表示hadoop账户组
最后是要授权的路径
-
4.9 对整个文件系统进行格式化
- 前期准备全部完成,现在对整个文件系统执行初始化。
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
-
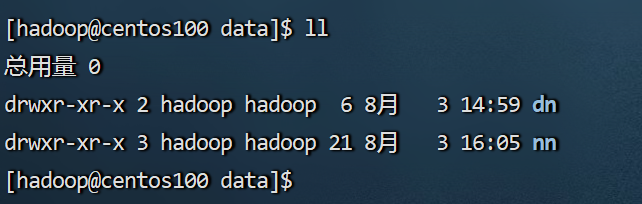
可以发现执行完成后,这个文件中就有数据了。
-
至于这些文件是什么,后续再说。
-
4.10 启动、停止hdfs集群
- 下面我们以hadoop用户,在centos100上通过命令可以一键启动停止整个hdfs集群。
-
# 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh # 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行 /opt/oftware/hadoop/hadoop-3.3.4/sbin/start-dfs.sh /opt/oftware/hadoop/hadoop-3.3.4/sbin/stop-dfs.sh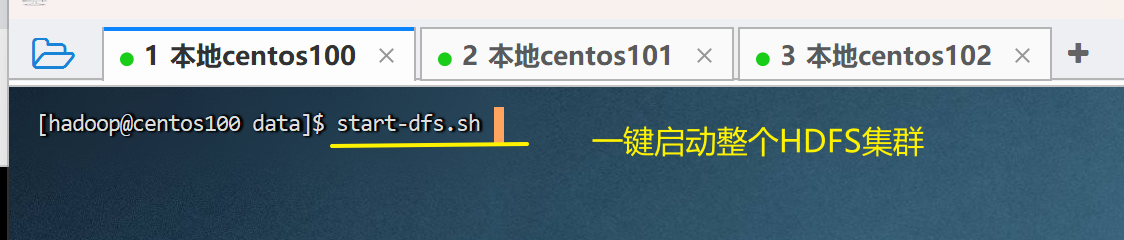
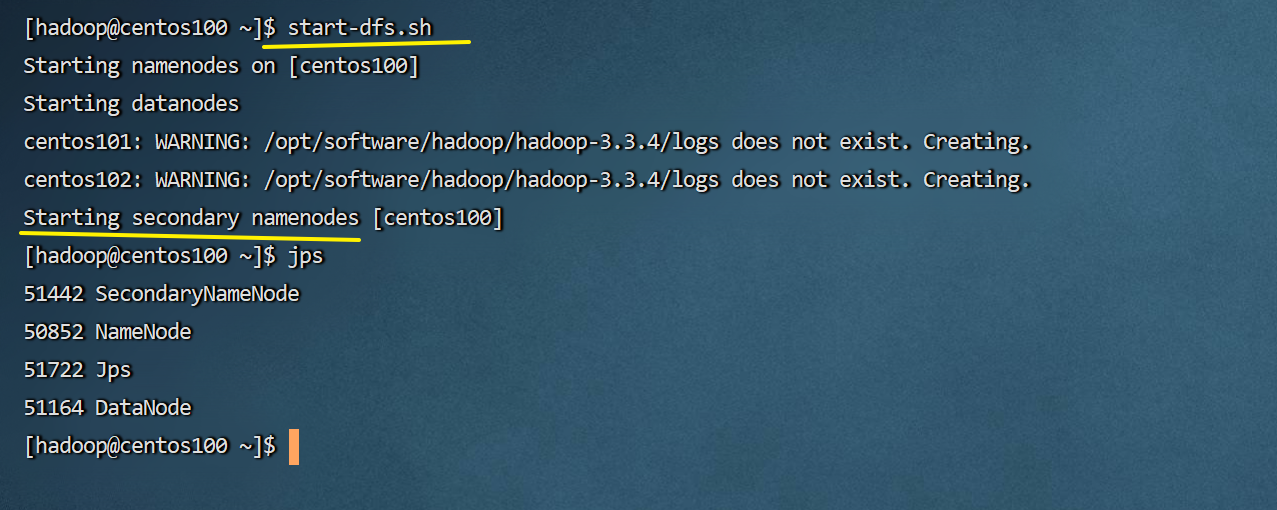
-
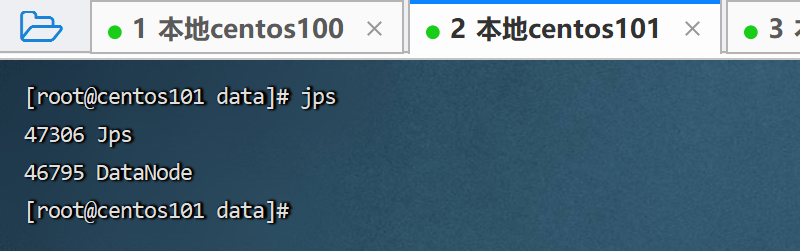
通过jps去另外两台服务器查看一下,也启动成功了。
-
-
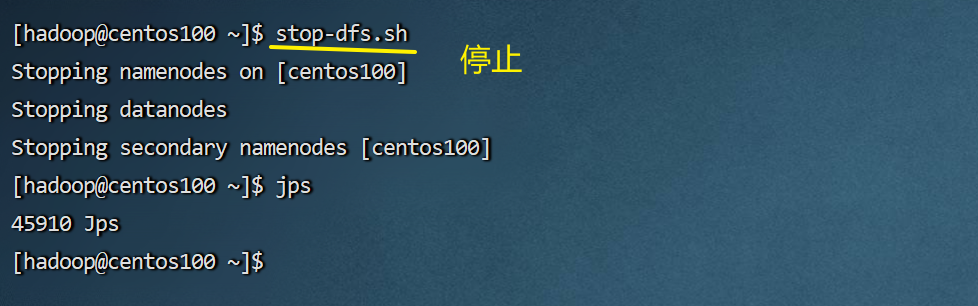
停止hdfs集群试试。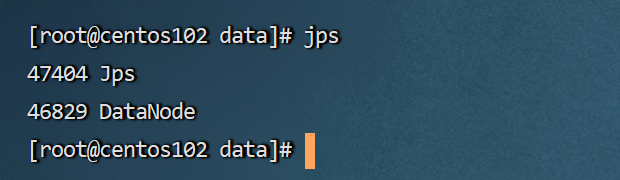
-
4.11 查看hdfs webui
-
我们先不要关闭集群。然后通过web访问centos100这台服务器的9870端口,即可查看hdfs的web可视化页面。
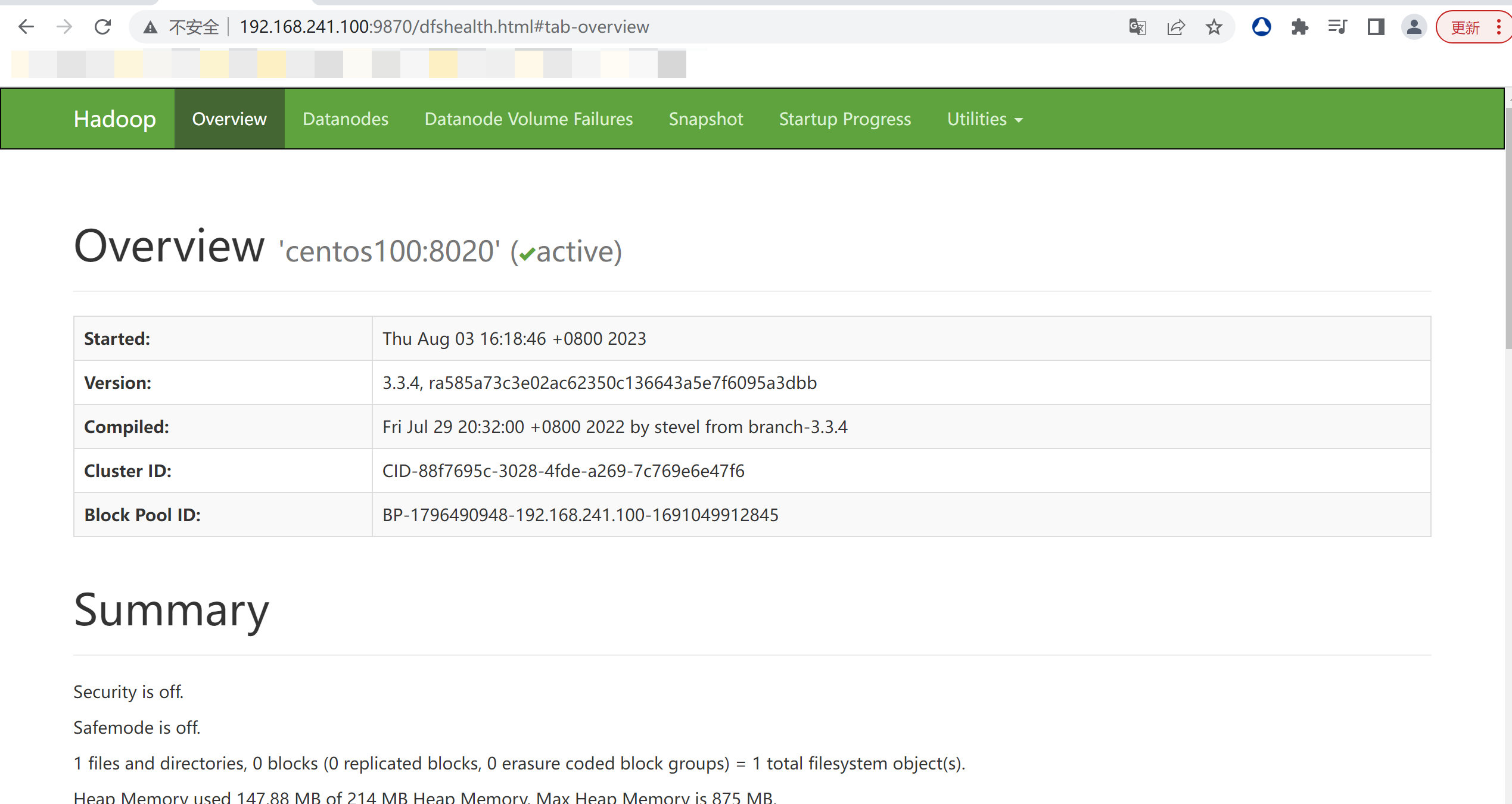
当然了,如果windows系统配置了host文件,将这几个ip地址映射了服务名,也可以直接用域名:9870的方式打开。


-
-
五、虚拟机快照
- 为了避免服务器出问题,导致我们辛辛苦苦搭建的集群崩溃掉。我们最好做一下快照保存。这样即使后面我们误操作,导致服务器崩溃掉,也可以恢复到我们当前这个阶段。
- 好了,这部分内容暂时就梳理到这里。我们下个阶段见!


发表评论