1、目的
clip + ddpm进行text-to-image生成
2、数据
(x, y),x为图像,y为相应的captions;设定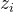 和
和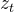 为clip的image和text embeddings
为clip的image和text embeddings
3、方法
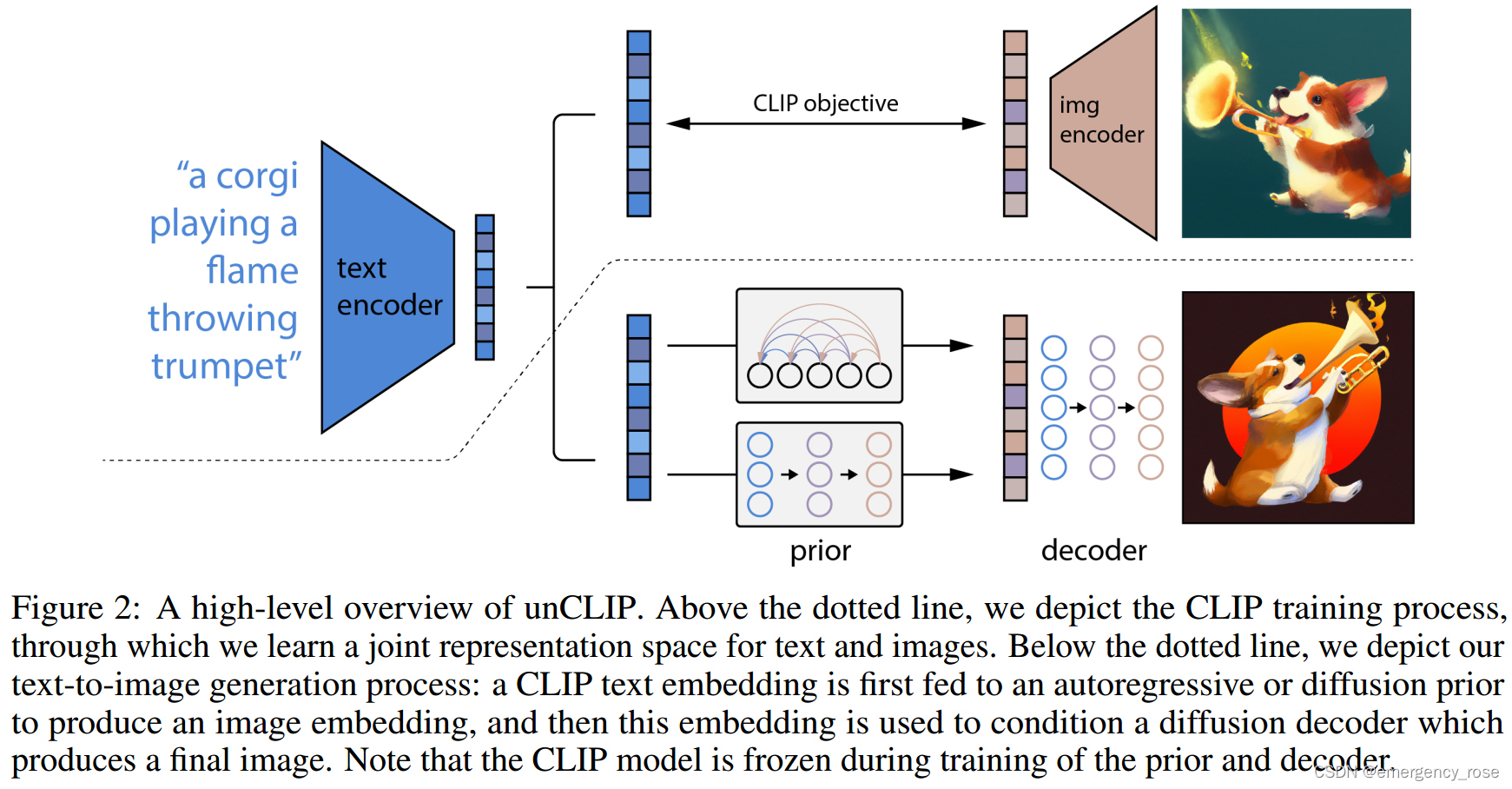
![]()
1)clip
学习图像和文本的embedding;在训练prior和decoder时固定该部分参数
2)prior model 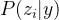
从给定的文本caption(或clip text embedding)中生成clip image embedding
-> autoregressive (ar) prior
用pca对clip image embeddings降维(1024 - 319),然后排序和数值化

将text caption和clip text embedding编码为sequence的prefix
-> diffusion prior
decoder-only transformer
casual attention mask with causal attention mask on a sequence (encoded text, clip text embedding, embedding for the diffusion timestep, noised clip image embedding, final embedding whose output from the transformer is used to predict the unnoised clip image embedding)
同时生成两个,选择与的点积更大的那一个
不预测 ,而是直接预测
,而是直接预测
![]()
3)clip image embedding decoder 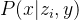
-> 用diffusion models、以clip image embeddings作为条件生成图像(可能会用到text caption)。直接将embedding作为采样起点效果不佳。
-> 映射和添加clip embeddings到existing timestep embedding
-> 将clip embedding映射到4个额外的context token中,和glide text encoder的输出并联
-> 因为是clip image encoder的逆过程,因此本文的方法也被称为unclip
-> 尝试沿用glide中的text conditioning,但作用不大
-> 训练细节
10%的概率随机设置clip embedding(或learned embedding)为0,实现classifier-free guidance;50%的概率随机去除text caption
两个upsample网络,64x64 - 256x256 - 1024x1024;第一个上采样阶段采用gaussian blur,第二个上采样阶段采用bsr degradation;训练时随机裁剪1/4大小的图像,推理时则用正常大小;只用spatial convolution,不用attention层;网络为unconditional admnets
-> 备选方案:直接用caption或者text embeddings作为条件,不用prior

4、应用
1)non-deterministic,给定一个image embedding,可以生成多个图像
 2)通过插值image embedding,可以对生成图像进行插值
2)通过插值image embedding,可以对生成图像进行插值
![]()

3)通过插值text embedding,可以对生成图像进行插值
![]()
![]()

4)可以有效抵挡clip容易受到影响的typographic attack

5、局限性
1)对于不同物品和属性的关联能力不如glide。因为clip embedding本身不关联物品和属性,而decoder也会mix up属性和物品

2)无法写出连贯的文本。因为clip本身不编码拼写信息,bpe编码也会模糊单词的拼写

3)无法生成复杂场景中的细节。因为模型在低分辨率下训练,然后再上采样

4)生成效果越好,制造欺骗性或有害图片的能力就更大

发表评论