如何对gpt-3.5、gpt-4、bard、文心一言、通义千问的水平进行排序?
在聊技术原理之前我们来先看看几个产品的团队背景
一、团队背景
1.1、chatgpt

chatgpt团队的成员大多具有计算机科学、人工智能、自然语言处理、机器学习等相关领域的高等教育背景,有些还拥有博士学位。他们来自世界各地,有美国、加拿大、英国、法国、德国、中国、印度等国家的人才。
团队成员绝大多数拥有名校学历,且具有全球知名企业工作经历。包括谷歌、facebook、微软、斯坦福大学、加州大学伯克利分校、麻省理工学院、剑桥大学、哈佛大学和佐治亚理工学院、清华大学等。

1.2、google bard

bard是应对openai开发的chatgpt的崛起而开发的,它的团队背景也是非常强大。团队成员来自世界各地,拥有不同的教育背景、工作经验和技术能力。团队成员的平均工作经验为 15 年,其中许多成员在大型科技公司工作,如 google、facebook等。团队成员毕业院校也都是顶尖院校如斯坦福大学、麻省理工学院、清华大学、北京大学、牛津大学、剑桥大学等。
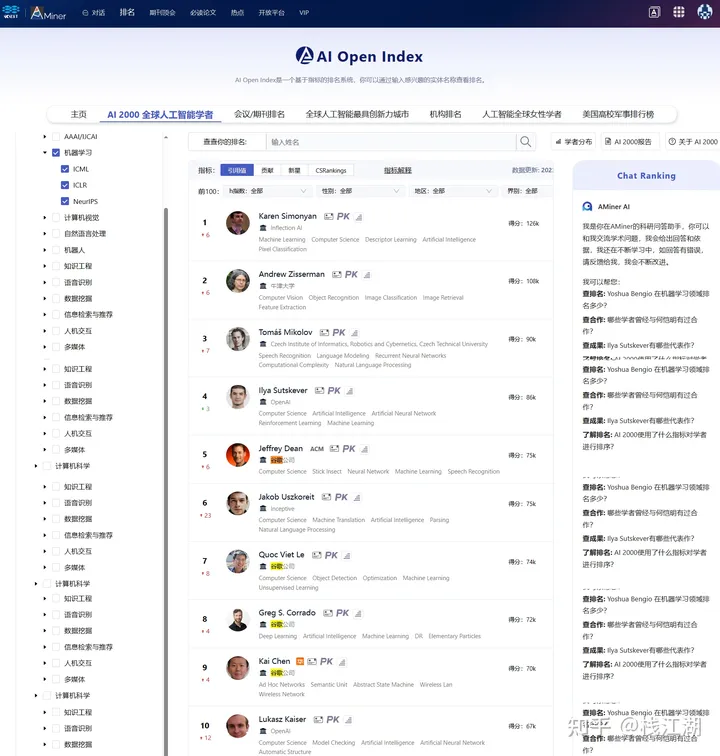
在排名中也可以看到大多数是google公司的成员。虽然当时bard为了追赶chatgpt,推出的太过仓促而翻车。当时2023年2月8日google巴黎举行直播展示bard后,google的股价下跌了8%,相当于市值损失1000亿美元,虽然出现了小插曲,但在ai界google的地位还是不低的。谷歌在人工智能领域拥有强大的技术实力,拥有大量的人工智能人才。开发了许多具有突破性的人工智能技术,如 tensorflow、tpu、gemini 等。这些技术在人工智能领域的各个领域得到了广泛应用。
1.3、文心一言

"文心一言"是由百度公司的自然语言处理团队开发的。这个团队的核心成员来自于清华大学、卡内基梅隆大学、谷歌等国内外顶尖高校及公司。
我没有在网上查到百度官方公开的文心一言团队的情况,但从以下这个方面也可以了解到一个大概情况。
百度开设了百度奖学金,百度奖学金于2013年设立至今,作为目前国内ai领域资助金额与含金量最高的学术奖学金之一,在业界取得了可观的影响力,该项目的获得者也在人工智能的各个领域已崭露头角。

历年有包括清华大学、浙江大学任意、哈尔滨工业大学、上海交通大学、北京理工大学魏、麻省理工学院、斯坦福大学、卡内基梅隆大学、悉尼科技大学等等在内的院校均有学生获奖。他们多年深耕专业领域,覆盖人工智能机器翻译、自然语言处理、任务型对话系统、图神经网络等多个ai专业领域。
- 技术原理
2.1、语言模型
- gpt(generative pre-trained transformer)
gpt 模型的全称是“generative pre-trained transformer”,就是“基于 transformer 的生成式预训练模型”。它是一种使用深度学习技术的自然语言处理(nlp)模型。gpt系列由openai(开放人工智能)开发,它使用了transformer架构,该架构在处理序列数据(如文本)时表现出色。
- lamda(language model for dialogue applications)
bard 使用的语言模型是基于谷歌自己的 lamda(对话应用程序语言模型)。
lamda 的全称是“language model for dialogue applications”,就是“对话应用程序语言模型”。lamda 是一种大型语言模型,由 google ai 创建。它是在一个庞大的数据集上训练的,包括文本和代码,能够生成文本,翻译语言,编写不同类型的创意内容,并以信息丰富的方式回答您的问题。 语言模型使用的是transformer架构。
- 文心一言(ernie bot)
文心一言,英文名是ernie bot,它是百度打造的一款人工智能大语言模型,它具备跨模态、跨语言的深度语义理解与生成能力。文心一言有五大能力,分别是文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成。 语言模型使用的是transformer架构。
2.2、技术原理

可以看到几个产品都有transformer的影子,也就是gpt中的t,以下就简单介绍一下技术原理。
chatgpt大概的技术原理流程:
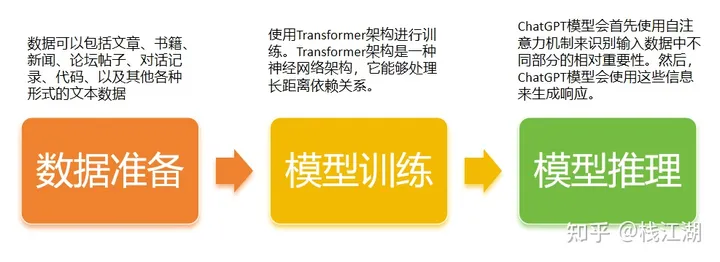
- 数据准备:首先需要准备大量的文本和代码数据,这些数据将用于训练chatgpt模型。
- 模型训练:chatgpt模型使用transformer架构进行训练。transformer架构的核心是自注意力机制,它使模型能够识别和重视输入数据中不同部分的相对重要性。
- 模型推理:在接收到用户输入后,chatgpt模型会使用transformer架构来生成响应。
可以看到transformer是所有模型的核心,哪么什么是transformer架构呢?
transformer是google ai在2017年提出的一种自然语言处理模型架构。transformer架构的核心是自注意力机制,它使模型能够识别和重视输入数据中不同部分的相对重要性。这种机制的引入,不仅提高了模型处理长文本的能力,也让其在理解语境和语义关系方面更为高效和准确。
transformer架构的原理论文是"attention is all you need",这篇论文由vaswani等人在2017年发表。

transformer 遵循以下的架构:
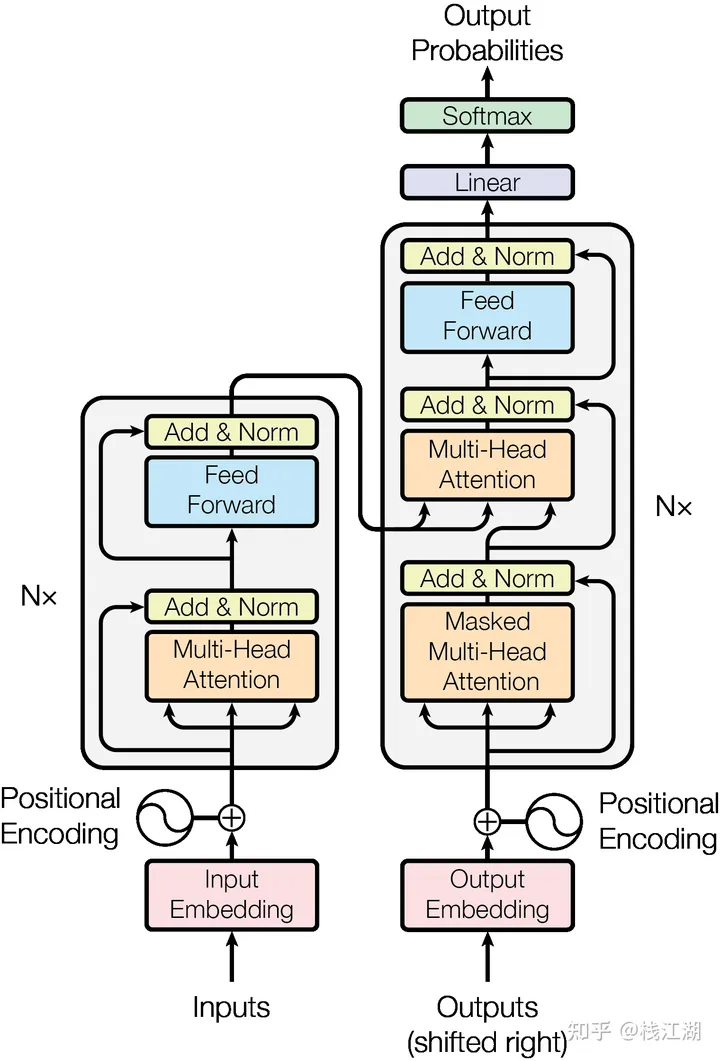
transforme架构主要包括:
- 编码器(encoder):负责理解输入文本,为每个输入构造对应的语义表示(语义特征)。
- 解码器(decoder):负责生成输出,使用编码器输出的语义表示结合其他输入来生成目标序列。
- 自注意力机制(attention mechanism):用于计算输入数据中不同部分之间的关系。
三、使用情况
3.1、文字类
我用一个知乎中知友问的一个问题:“汉字中带氵偏旁但与水无关的字”
1)chatgpt3.5
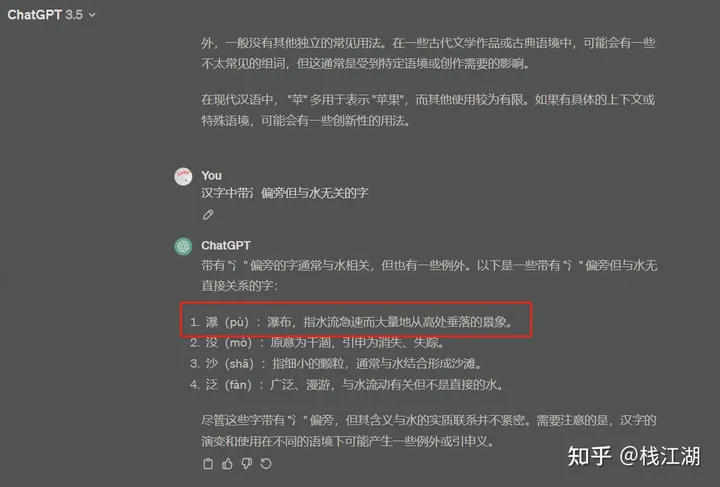
“瀑”我感觉还是与水有关,其它几个字到是都对的。
2)chatgpt4

感觉gpt4还是比较正确的没有出现特别错的字。当然也有知友开玩笑说“法”是与水有关的,并且这里的水最深,呵呵。。。。
3)google bard
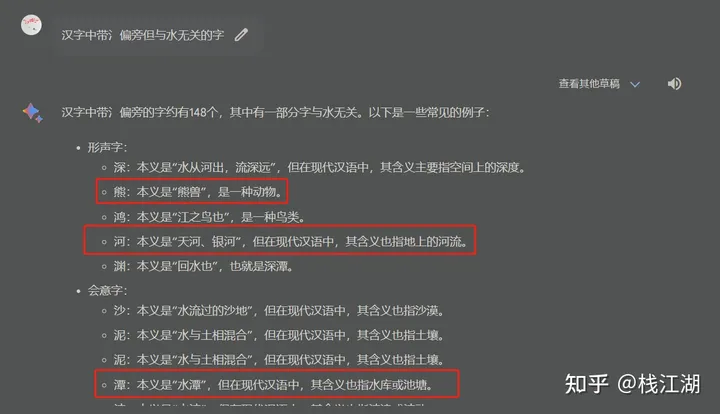
这里还是出现了不少有问题的汉字,当然bard汉语知识库说是使用的百度文心并不是它自己的。当时也爆出不少新闻也有不少截图。不过最近问bard说使用的是google自己的。
4)文心一言
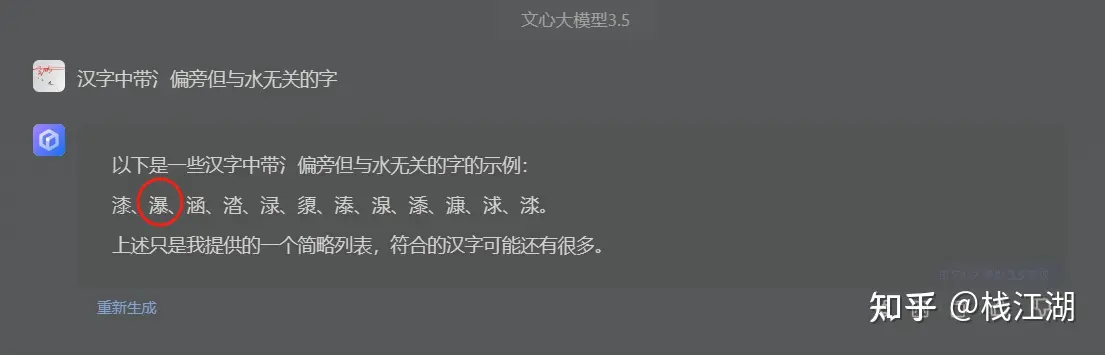
文心在汉字上应该会有优势,不过还是出现了“瀑”字,不过文心列出的汉字还是比其它产品较多的,还都是对的。相比其它产品它的汉字处理能力应该是较强的,不过回答的就比较草率了点,在这方面的能力还是相对差了点。
当然我问的问题都是没有增加一些修饰的,如果增加相应的修饰会回答的更加准确。
从这个问题的回答来看:
chatgpt4 > chatgpt3.5 > 文心一言3.5 > google bard
3.2、绘图类
1)chatgpt4
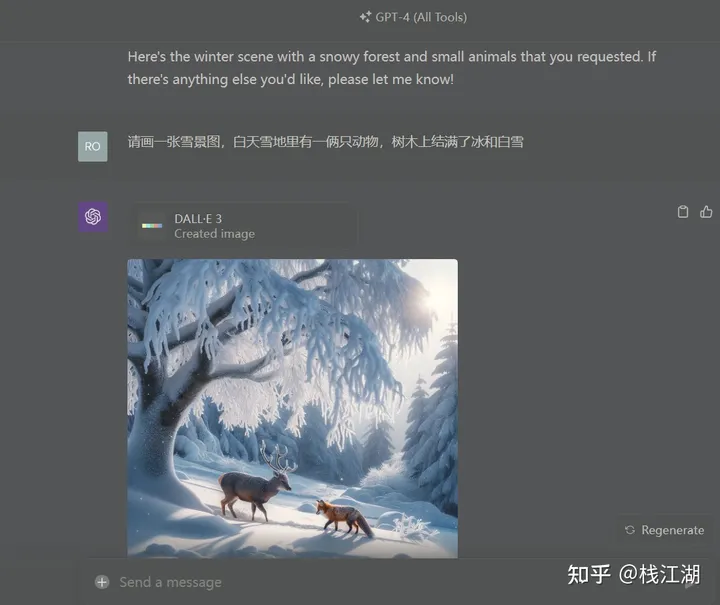
2)文心一言
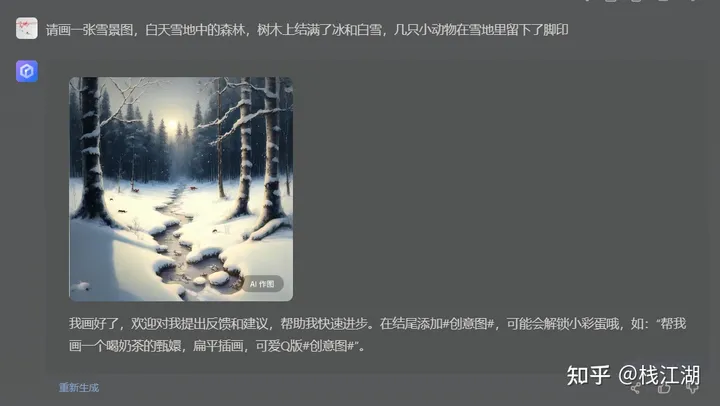
3)copilot(bing)
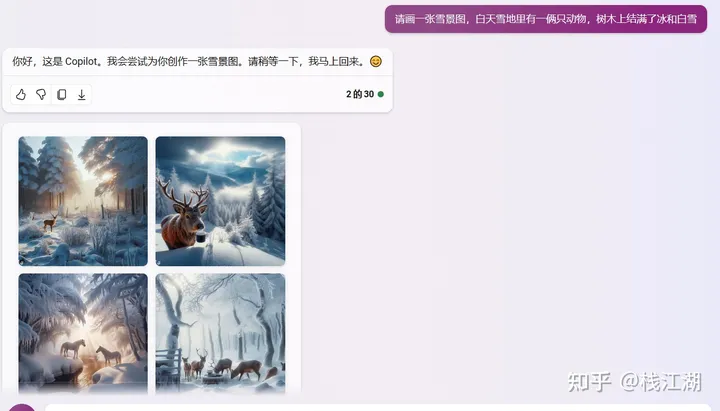
四、总结排名
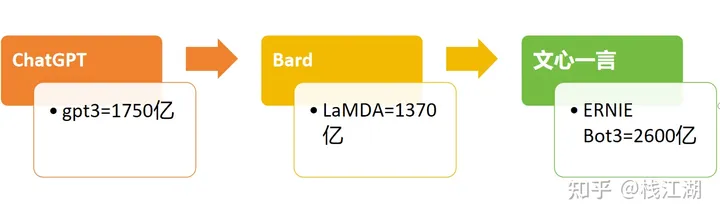
从语言模型参数量来看文心一言是最大的,之前出idc报告中也说文心一言超gpt3.5,当然数据只是个参考还得看使用情况。另外gpt4、palm、ernie bot4的参数量网上有很多版本大概都在万亿级的样子。
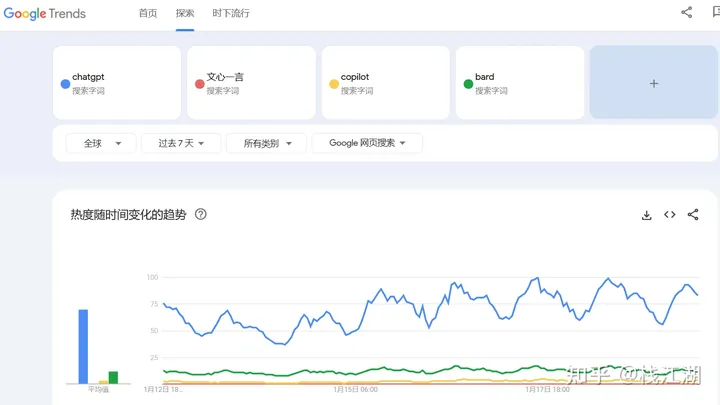
以下是全球对chatgtp、google bard、文心一言、new bing(copilot)的关注情况,chatgtp是遥遥领先的。
最后总结一下:
- 如果主要关注文字处理的话
chatgpt4>chatgpt3.5>google bard>文心一言 - 如果主要关注实时信息、互联网数据、绘图等
copilot>chatgpt4>chatgpt3.5>google bard>文心一言

发表评论