深度学习是人工智能领域的一个重要分支,它在图像识别、语音识别、自然语言处理等方面取得了显著的进展。
学习任一门知识都应该先从其历史开始,把握了历史,也就抓住了现在与未来 。
那么深度学习到底是经历了一段怎样的发展过程呢?下面我们就来了解一下深度学习发展史。
1940s-1950s:早期神经网络概念
1943年,warren mcculloch和walter pitts发表论文“a logical calculus of the ideas immanent in nervous activity”(神经活动中内在思想的逻辑演算),建立了神经网络和数学模型,称为mcp模型。奠定了神经网络和数学模型的基础。
mcp当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。如下图所示:

图:mcp模型
1949年,donald hebb提出了hebbian学习规则,该规则表明,如果神经元a在接收到神经元b的输入后,持续发放输出,那么神经元a与神经元b之间的连接强度将增强:
hebb学习规则与“条件反射”机理一致,并且已经得到了神经细胞学说的证实。hebbian学习规则为神经元连接强度的学习机制提供了理论支持。
1950s-1960s:感知机和早期模型
1958年,计算机科学家frank rosenblatt提出了两层神经元组成的神经网络,称之为感知器(perceptrons),使用mcp模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。
1969年,marvin minsky和seymour papert在他们的书《perceptrons》中指出感知器本质上是一种线性模型,只能处理线性分类问题,就连最简单的xor(异或)问题都无法正确分类。

图:异或(xor)问题:没有一条直线能将绿点和红点分开
1980s-1990s:多层感知机和反向传播
1985年,geoffrey hinton等人发表论文a learning algorithm for boltzmann machines,提出了受限玻尔兹曼机 (rbm)。一种用于无监督学习的随机神经网络。可用于特征提取、降维。后来成为深度信念网络的组成块进而流行。
1986年,geoffrey hinton 发明了适用于多层感知器(mlp)的bp(backpropagation)算法,并采用sigmoid进行非线性映射,有效解决了非线性分类和训练的问题。该方法引起了神经网络的第二次热潮。
1989年,yann lecun等人发表论文backpropagation applied to handwritten zip code recognition(反向传播应用于手写邮政编码识别),使用bp算法训练卷积神经网络(cnn)用于手写数字识别。

图:cnn模型
1990s-2000:深度学习领域的形成期
1990年,jeffrey elman发表论文finding structure in time提出 srns(也叫 elman networks),其核心概念就是今天所熟知的循环神经网络(rnn)。
1991年,sepp hochreiter在他的毕业论文中阐述了梯度消失问题,当梯度通过深度神经网络中的各层反向传播时,它们往往会变得非常小,导致较早的层训练速度非常慢或完全不训练。这个问题在循环神经网络(rnn)和深度前馈网络中尤其严重。
1993年,geoffrey hinton发表论文autoencoders, minimum description length and helmholtz free energy,发表了关于自编码器(autoencoders)的研究,自编码器的概念至少在1993年之前就已经存在并被学术界所探讨。
1997年,sepp hochreiter和jürgen schmidhuber发表了论文long short-term memory,为了解决rnn的梯度消失问题,提出了lstm。
1998年,yann lecun等人发表论文gradient-based learning applied to document recognition,改进了之前的cnn,提出了lenet-5,专为mnist 数据集手写数字识别而设计,lenet-5 引入了卷积、池化和激活函数的使用等关键概念,这些概念已成为现代深度学习的基础。
2000s:深度学习的复兴
2006年,geoffrey hinton等人发表论文a fast learning algorithm for deep belief nets,提出深度信念网络(dbn)。这篇论文被认为是近代的深度学习方法的开始。
同年,还是geoffrey hinton等人发表论文reducing the dimensionality of data with neural networks,提出深度自编码器。以上这两篇论文都提出深层网络训练中梯度消失问题的解决方案:逐层贪心预训练,即通过无监督预训练对权值进行初始化+有监督训练微调。
还是2006 年,nvidia 推出 cuda框架,利用 gpu 的并行处理能力,将 gpu 用作通用并行计算设备,以加速各种计算任务,而不仅限于图形处理。cuda框架大大提升了深度学习算法的效率。
2010s:深度学习的突破与普及
2012年,alex krizhevsky、ilya sutskever和geoffrey hinton的alexnet在imagenet 大规模视觉识别挑战赛 (ilsvrc)中取得了巨大成功,首次采用relu激活函数,从根本上解决了梯度消失问题,于是抛弃了预训练+微调的方法,完全采用有监督训练。alexnet展示了卷积神经网络 (cnn) 的强大功能,并标志着计算机视觉的转折点,普及了深度学习技术。
2013年12月19日,google deepmind发表论文playing atari with deep reinforcement learning,提出了deep q-network (dqn),将深度学习与强化学习相结合。dqn通过使用卷积神经网络 (cnn) 估计q值,成功在atari游戏中实现了超越人类的表现。dqn对人工智能和自动化控制系统产生了深远影响。
2013年12月20日,kingma和welling发表论文auto-encoding variational bayes,提出了变分自编码器(vae),展示了一种结合贝叶斯推理和深度学习的生成模型。vae通过编码器-解码器结构学习数据的潜在表示,并能够生成新样本。vae在图像生成、异常检测、数据压缩等领域取得显著成果。其创新方法为生成模型提供了概率框架,推动了深度学习在生成任务中的应用和发展。
2014年6月10日,ian goodfellow等人发表论文generative adversarial nets提出生成对抗网络(gan),在图像生成、图像修复、超分辨率等领域取得了显著成果,为生成模型带来了新的方向。

图:gan模型
2014年6月24日,google deepmind发表recurrent models of visual attention,使得注意力机制(attention mechanism)开始受到广泛关注。该论文采用了循环神经网络(rnn)模型,并集成了注意力机制来处理图像分类任务,开创了将注意力机制应用于深度学习模型的先河。
2014年9月1日,dzmitry bahdanau、kyunghyun cho 和 yoshua bengio 发表论文neural machine translation by jointly learning to align and translate,将注意力机制(attention mechanism)引入机器翻译,以提高长序列处理能力。它在机器翻译的历史中标志着一个重要的转折点。
2015年5月18日,ronneberger等人发表论文u-net: convolutional networks for biomedical image segmentation,提出了u-net,u-net采用对称的u形架构,通过跳跃连接融合不同层次的特征信息,实现高精度的分割。其设计有效解决了小样本问题,广泛应用于医学影像分析、遥感图像处理等领域,对图像分割任务的发展产生了深远影响。
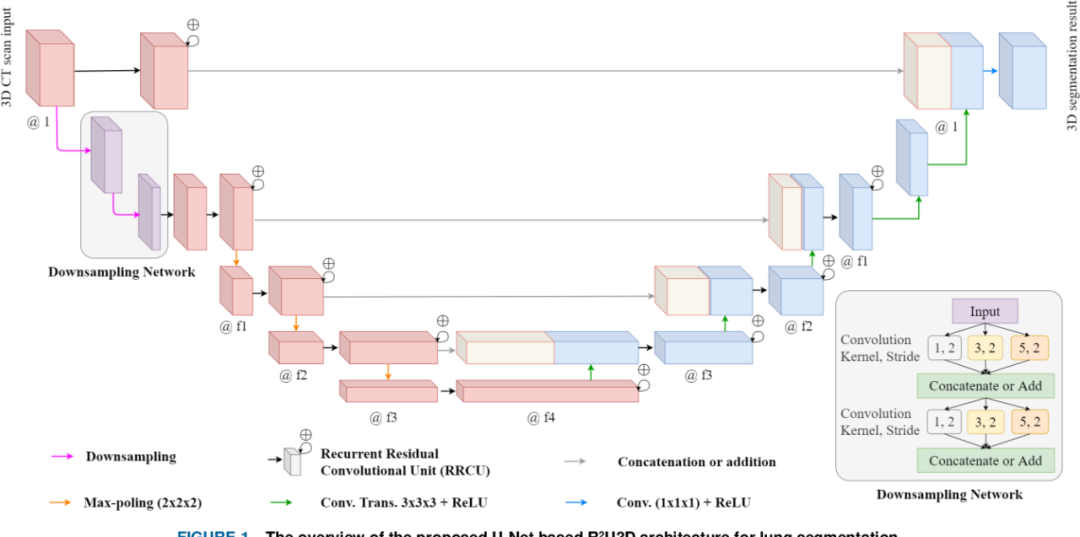
图:u-net
2015年12月10日,何凯明等人发表论文deep residual learning for image recognition,提出了resnet(残差网络),展示了一种通过残差连接解决深层神经网络训练难题的方法。resnet在ilsvrc 2015竞赛中获得冠军,显著提高了深度学习模型的性能和可训练性。其创新架构允许构建更深的网络,推动了图像识别、目标检测等计算机视觉任务的发展,成为深度学习领域的重要基石。
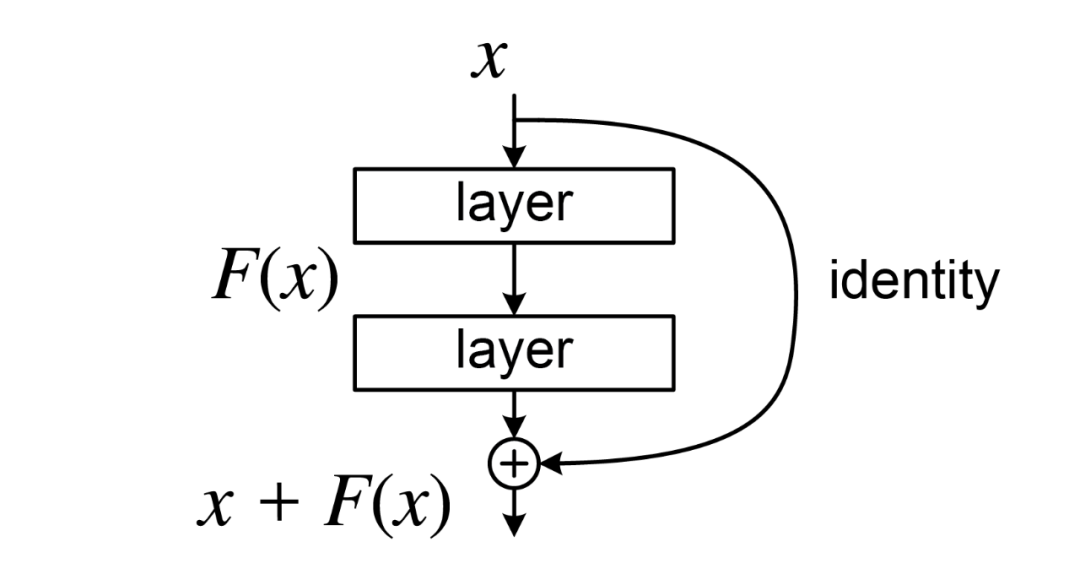
图:resnet
2015年-2016年,google,facebook相继推出tensorflow、pytorch 和 keras,极大地促进了深度学习研究和应用的发展,使得复杂的神经网络模型的开发和训练变得更加便捷和高效。
2016年:google deepmind开发的alphago击败了围棋世界冠军李世石,展示了深度强化学习的潜力。
2017年,google brain发表了attention is all you need,提出了transformer,彻底放弃了传统的循环神经网络(rnn)和卷积神经网络(cnn)结构,转而完全采用注意力机制来执行机器翻译任务。这一创新犹如火星撞地球一般迅速横扫了整个自然语言处理学术界。彻底改变了自然语言处理(nlp)领域。对后续的bert、gpt等模型产生了深远影响。
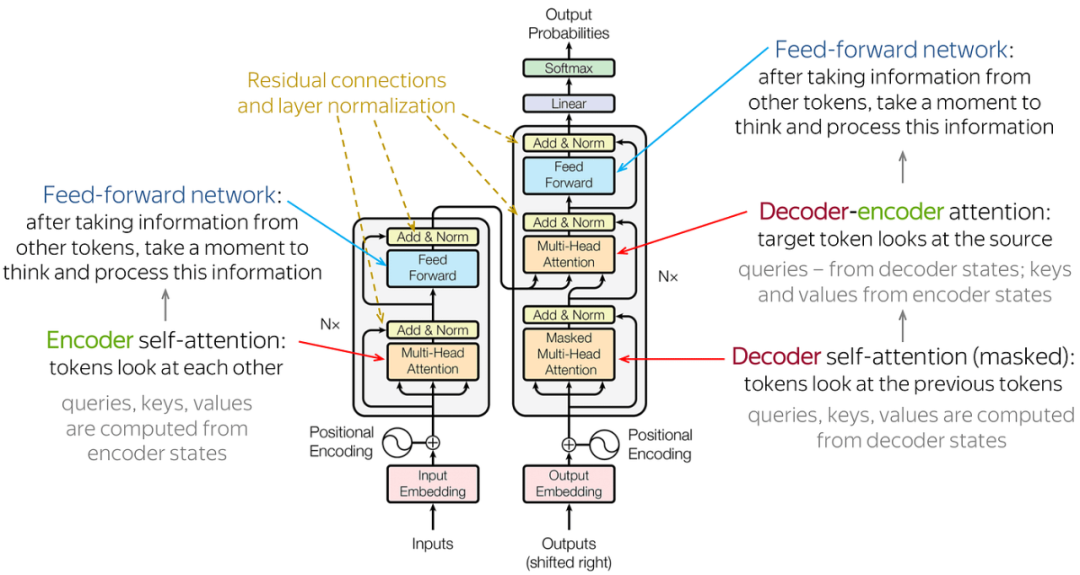
图:transformer
2018年6月,openai 发表了improving language understanding by generative pre-training,提出了gpt,这是一个具有里程碑意义的大规模预训练模型。
2018年10月11日,google ai language发表了bert: pre-training of deep bidirectional transformers for language understanding,提出了bert,gpt 和 bert,它们分别使用自回归语言建模和自编码语言建模作为预训练目标。所有后续的大规模预训练模型都是这两个模型的变体。

图:bert
2020s:深度学习的扩展与应用
2020年10月22日,google团队发表an image is worth 16x16 words: transformers for image recognition at scale,提出了vision transformer(vit),虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在cv领域应用的里程碑著作,也引爆了后续相关研究。
2021年2月26日,openai发表了learning transferable visual models from natural language supervision,提出了clip,通过对比学习方法,将图像与自然语言文本进行配对,实现了多模态学习。具备零样本学习能力。为多模态ai的研究和应用奠定了基础,推动了图像生成、理解和交互等领域的发展。
2021年7月15日和7月22日,google deepmind在natrue分别发表论文highly accurate protein structure prediction with alphafold,highly accurate protein structure prediction for the human proteome,发布了alphafold 2,alphafold 2在第十四届国际蛋白质结构预测竞赛(casp)上取得惊人的准确度,多数预测模型与实验测得的蛋白质结构模型高度一致,引起举世瞩目。对生物医学研究、药物设计和生命科学产生了深远影响。
2022年12月20日,stability ai发表论文high-resolution image synthesis with latent diffusion models,发布了完全开源的stable diffusion,展示了一种利用扩散过程生成图像的方法,是ai绘画领域的一个核心模型,能够进行文生图(txt2img)和图生图(img2img)等图像生成任务。

图:diffusion model
2022年7月12日,david holz发布了midjourney,一个基于生成对抗网络(gans)和深度学习的ai平台,通过用户提供的文本描述生成高质量图像。
2022年11月30日,openai发布了gpt-3.5,其产品chatgpt瞬间成为全球爆品。引起了全球学术界和工业界的大语言模型热潮。以chatgpt为代表的大语言模型向世人展露出了前所未有的能力。一大波大语言、多模态的预训练模型如雨后春笋般迅速出现。

图:chatgpt
以后有机会专门出一期大模型的介绍。
2023年12月1日,albert gu和tri dao发表了论文mamba: linear-time sequence modeling with selective state spaces,提出了mamba,这是一种新的不同于transformer的处理长序列数据的神经网络架构,能够在保持高效率的同时,提供出色的性能。对于需要处理大量数据的应用场景,如自然语言处理、语音识别和生物信息学等领域,具有重要的实际应用价值。
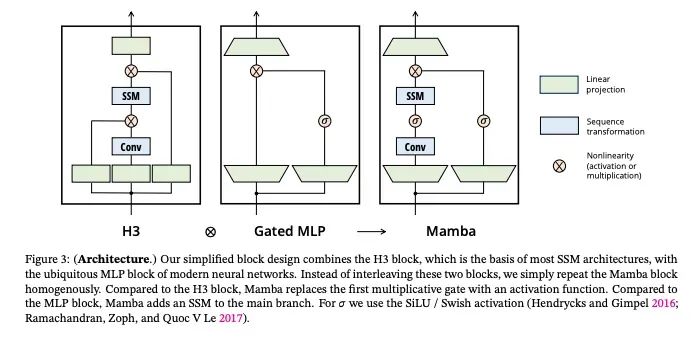
图:mamba
2024年2月18日,openai发布了sora,一种通过文本生成视频的模型,结合了先进的transformer和gan架构,更多地使用了clip,实现了高质量的文本到视频生成。

图:sora生成的视频
2024年5月8日,deepmind发表论文accurate structure prediction of biomolecular interactions with alphafold 3,提出了alphafold 3,以前所未有的精确度成功预测了所有生命分子(蛋白质、dna、rna、配体等)的结构和相互作用。与现有的预测方法相比,alphafold 3 发现蛋白质与其他分子类型的相互作用最高提高了一倍。

图:alphafold 3生成的蛋白质结构
综上所述,本文详细介绍了深度学习领域从1940年代至今的演变历程,涵盖了早期神经网络模型、感知器、多层感知机、反向传播算法、循环神经网络、自编码器、深度信念网络、生成对抗网络、transformer等重要里程碑。
然而,本文仍有一些不足之处和未尽事宜。比如,有文献指出1970年seppo linnainmaa率先发表了反向传播算法,但本文采用了较为普遍的说法,将其归功于geoffrey hinton。hinton本人也在2019年澄清,他并非反向传播算法的发明者,而是将其发扬光大的重要推动者。
此外,由于深度学习近年来发展迅猛,本文未能涵盖深度学习在各个行业和新兴研究领域的最新整合进展和趋势。也未能涵盖近两年各大企业和学术机构的大模型产品,希望未来能有更多的研究和讨论,进一步完善和深化对这一领域的理解。
欢迎关注我的微信公众号!!!会不断分享统计学、机器学习和生物信息学的知识和学习笔记!↓↓↓↓↓↓↓↓↓↓↓↓




发表评论