1. 准备工作
1. 开启并配置mysql的 binlog(mysql 8.0 默认开启)
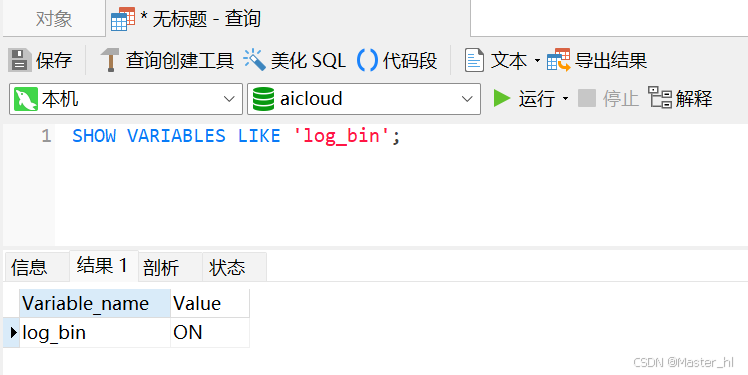
修改配置:c:\programdata\mysql\mysql server 8.0\my.ini
log-bin="helong-bin" binlog_format=row # 只能配置行模式, 因为 cannal 不具备将sql转化成数据的能力 binlog-do-db=aicloud # 监控 ai cloud 项目
如果要同步多个项目:
binlog-do-db=aicloud binlog-do-db=aicloud2 binlog-do-db=aicloud3
2. 重启mysql服务
3. 赋值数据同步权限
create user canal identified by 'canal'; grant select, replication slave, replication client on *.* to 'canal'@'%'; flush privileges;
4. 安装并配置 canal
下载地址:https://github.com/alibaba/canal/releases
① 修改canal.properties
canal.servermode=kafka canal.mq.servers=127.0.0.1:9092
canal 监控 binlog 日志,binlog 日志的传输默认使用 mysql 的复制协议(基于 tcp/ip),
可以使用写代码的方式直接从 mysql 服务器读取数据,此处使用本地 kafka 进行存储。
② 修改instance.properties
canal.instance.mysql.slaveid=100 # 大于 1 即可 canal.instance.master.address=127.0.0.1:3306 canal.mq.topic=ai-cloud-canal-to-kafka
slaveid 表示从节点 id,canal 的执行原理就是伪装成一个从库去主库同步数据
(主节点的 slaveid = 1)
address 配置连接本地的 mysql
topic 配置数据发送到 kafka 的某个主题下
5. 拷贝 jar 包到 lib
将 canal 下 plugin 下的所有 jar 包拷贝到 lib 目录下。
6. 删除 bin 目录下 startup.bat 里的参数
如果启动时报错:
unrecognized vm option 'permsize=128m'
error: could not create the java virtual machine.
error: a fatal exception has occurred. program will exit.
删除 -xx:permsize=128m 参数即可。
7. 启动 canal
打开 cmd ,cd 到 bin 目录下,输入 startup.bat 回车
2. 将需要缓存的数据存储 redis
此时我将这个查询列表接口的数据,存储在 redis 中:
/**
* 获取历史聊天记录(对话/绘图)
*
* @param type
* @return {@link responseentity }
*/
@requestmapping("/list")
public responseentity gethistorylist(integer type, integer model) {
string listcachekey = redisutil.getlistcachekey(securityutil.getcurrentuser().getuid(), model, type);
object list = redistemplate.opsforvalue().get(listcachekey);
if (objectutil.isnull(list)) {
lambdaquerywrapper<answer> querywrapper = new lambdaquerywrapper<>();
querywrapper.eq(answer::getuid, securityutil.getcurrentuser().getuid());
querywrapper.eq(answer::gettype, type);
querywrapper.eq(answer::getmodel, model);
querywrapper.orderbydesc(answer::getaid);
list<answer> answerlist = answerservice.list(querywrapper);
list<long> userids = answerlist.stream().map(answer::getuid).collect(collectors.tolist());
map<long, user> useridmap = userservice.selectbyids(userids).stream().collect(collectors.tomap(user::getuid, function.identity()));
list<answervo> answervolist = answerlist.stream().map(answer -> answervoutil.getlistanswervo(answer, useridmap)).collect(collectors.tolist());
// 缓存 1 天
redistemplate.opsforvalue().set(listcachekey, answervolist, 1, timeunit.days);
return responseentity.success(answervolist);
} else {
return responseentity.success(list);
}
}/**
* 查询列表存储 redis 缓存
*
* @param uid
* @param model
* @param type
* @return {@link string }
*/
public static string getlistcachekey(long uid, integer model, integer type) {
return "list_cache_key_" + uid + "_" + model + "_" + type;
}3. 监听 kafka topic 中数据并删除 redis 缓存
首先对数据库中需要缓存的数据进行一些修改操作:

此时,使用 kafka ui(下载地址划到最底下),刷新 kafka 对应 topic 下的 message,就可以看到当前所作出的修改:
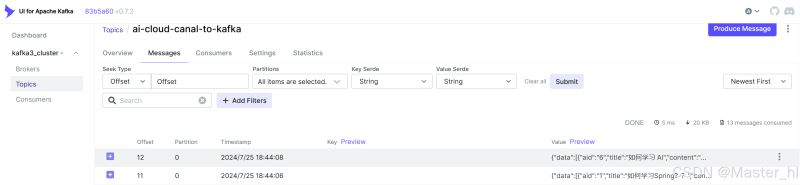
执行修改操作:将 “如何学习spring???”修改成 “如何学习spring??”
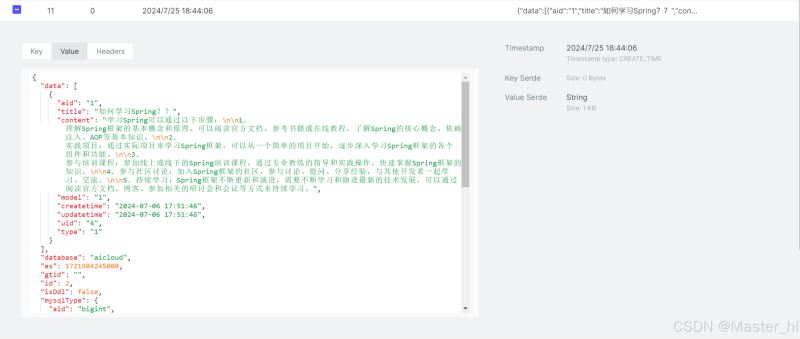
执行删除操作:
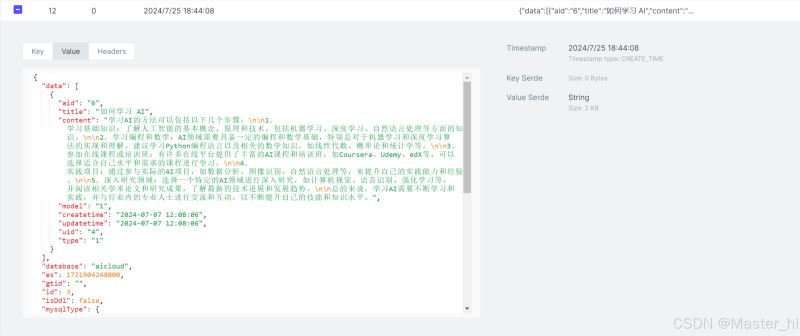
由此可见,对数据库的每一个修改操作,都是对应固定格式的一个数据,所以可以监听对应的 topic 并针对 data 中的数据进行一个提取,得到一个 cachekey,然后删除对应的缓存,使得下一次的查询去访问数据库,并同步缓存。
【代码示例】
/**
* canal 监控 binlog 日志,将修改的数据存储 kafka topic 中
* 监听 kafka topic 中的数据
*
* @param data
* @param ack
* @throws jsonprocessingexception
*/
@kafkalistener(topics = {kafkaconstant.canal_topic})
public void canallisten(string data, acknowledgment ack) throws jsonprocessingexception {
hashmap<string, object> map = objectmapper.readvalue(data, hashmap.class);
if (map.isempty()) {
ack.acknowledge();
return;
}
// 匹配上对应的数据库和数据表
if (kafkaconstant.target_database.equals(map.get(kafkaconstant.database_key).tostring()) &&
kafkaconstant.target_table.equals(map.get(kafkaconstant.table_key).tostring())) {
// 更新缓存
list<map<string, object>> list = (list<map<string, object>>) map.get(kafkaconstant.data_key);
if (!collectionutils.isempty(list)) {
for (map<string, object> answermap : list) {
string answerlistcachekey = redisutil.getlistcachekey(
long.valueof(answermap.get("uid").tostring()),
integer.parseint(answermap.get("model").tostring()),
integer.parseint(answermap.get("type").tostring()));
// 删除缓存,让下一次查询走数据库,并同步缓存
redistemplate.delete(answerlistcachekey);
}
}
}
// 手动确认应答
ack.acknowledge();
}/** * canal 同步数据到 kafka */ public static final string canal_topic = "ai-cloud-canal-to-kafka"; /** * 数据库,缓存数据一致性的 */ public static final string database_key = "database"; public static final string table_key = "table"; public static final string data_key = "data"; public static final string target_database = "aicloud"; public static final string target_table = "answer";
【补充】
kafka ui 下载地址:https://github.com/provectus/kafka-ui/tags
修改配置
kafka:
clusters:
- name: kafka3_cluster
bootstrapservers: 127.0.0.1:9092以上就是使用canal和kafka解决mysql与缓存的数据一致性问题的详细内容,更多关于mysql与缓存的数据一致性的资料请关注代码网其它相关文章!

发表评论