概述
surging是一款开源的微服务引擎,包含了rpc服务治理,中间件,以及多种外部协议来解决各个行业的业务问题,在日益发展的今天,业务的需求也更加复杂,单一语言也未必能抗下所有,所以在多语言行业解决方案优势情况下,那么就需要多语言的协同研发,而对于协同研发环境下,统一配置的网关,多语言访问调用必然会涉及到需要数据缓存的问题,那么怎么做到跨网关跨语言缓存降级呢?那么将在此篇文章中进行讲解。
如何创建拦截器
继承iinterceptor ,创建拦截,如下代码所示
public class logproviderinterceptor : iinterceptor
{
public async task intercept(iinvocation invocation)
{
await invocation.proceed();
var result = invocation.returnvalue;
}
}
服务引擎针对于iinterceptor 扩展了cacheinterceptor用来做缓存拦截,如以下代码所示
public class cacheproviderinterceptor : cacheinterceptor
{
public override async task intercept(icacheinvocation invocation)
{
}
}
如何使用缓存拦截器
通过设置特性metadatas.servicecacheintercept配置缓存拦截,如以下代码所示
[metadatas.servicecacheintercept(metadatas.cachingmethod.get, key = "getuser_{0}_{1}", l2key = "getuser_{0}_{1}",enablel2cache =true, cachesectiontype = "ddlcache", mode = metadatas.cachetargettype.redis, time = 480)]
在处理业务的修改,删除方法时候,需要移除依赖的缓存,那么可以设置correspondingkeys,如以下代码所示
[metadatas.servicecacheintercept(cachingmethod.remove, "getuser_id_{0}", "getusername_name_{0}", cachesectiontype = sectiontype.ddlcache, mode = cachetargettype.redis)]
如何设置缓存key
1.比如缓存设置为getuserbyid_{0}, 传递的参数是int 类型,值为2199 ,那么产生的key就是getuserbyid_2199.
2.比如缓存设置为getuser_{0}_{1},传递的参数是usermodel类型,传递为new usermodel{ userid=2199,name="fanly" }值,那么产生的key就是getuser_fanly_2199. 标识cachekeyattribute特性以生成缓存key, 并且设置sortindex排序依次生成。
public class usermodel
{
[cachekey(1)]
public int userid { get; set; }
[cachekey(2)]
public string name { get; set; }
public int age { get; set; }
}
创建拦截模块
通过以下代码,把拦截器注入到服务引擎中
public class interceptemodule : systemmodule
{
public override void initialize(cplatformcontainer serviceprovider)
{
base.initialize(serviceprovider);
}
/// <summary>
/// inject dependent third-party components
/// </summary>
/// <param name="builder"></param>
protected override void registerbuilder(containerbuilderwrapper builder)
{
base.registerbuilder(builder);
builder.addclientintercepted(typeof(cacheproviderinterceptor),typeof(logproviderinterceptor));
}
}
如何跨语言调用中开启缓存拦截降级
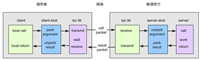
在surging 是调用分为二种
1.基于接口创建代理调用,可以作为同一语言的互相调用,性能上比第二种基于routepath要快,但是具有高耦合性
var userproxy = servicelocator.getservice<iserviceproxyfactory>().createproxy<iuserservice>("user");
2.基于routepath调用,可以作为跨语言调用,性能上比第一种基于接口创建代理要慢,但是具有低耦合性
dictionary<string, object> model = new dictionary<string, object>();
model.add("name", name);
string path = "api/hello/say";
string result =await _serviceproxyprovider.invoke<object>(model, path, null);
而在服务调用下,因为业务模型参数在基于routepath调用情况,做不到模型参数解析,只能支持单一参数和无参数的缓存拦截调用,而基于接口创建代理调用是可以支持业务模型缓存调用的,在以下特征情况下就需要在metadatas.servicecacheintercept特性下开启enablestagecache,代码如下
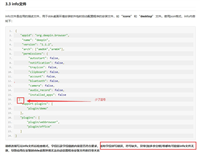
[metadatas.servicecacheintercept(metadatas.cachingmethod.get, key = "getdictionary", l2key = "getdictionary", enablel2cache = true, cachesectiontype = "ddlcache", mode = metadatas.cachetargettype.redis, time = 480, enablestagecache = true)]
通过以上的代码,运行后,在注册中心注册的服务路由下可以看到拦截器元数据,这样在其它语言通过元数据可以构造服务消费者的缓存拦截降级。

以下是基于二种调用的缓存结果存储redis中

如何处理缓存k/v 中value 过大
缓存中间件redis是一种高性能的内存数据库,用于存储键值对的数据结构。当value的大小超过一定限制时,一般超过10k就会影响查询的性能。这时候使用一二级缓存来解决,一级缓存用redis 存储标记,标记缓存是否失效,二级缓存用本地缓存存储,当标记失效不存在后,会远程调用服务,返回结果添加一级缓存标记,返回结果添加到二级缓存。
提示:大家可以按照自己的业务需求,研发缓存拦截,不一定非要使用cacheproviderinterceptor,按照cacheproviderinterceptor一二级缓存进行构建研发
总结
社区版:https://github.com/fanliang11/surging,如果需要其它版本,请联系作者。
发表评论