前言
在我们项目的开发中啊,前端有时候会传送 excel 文件给后端(java)去解析,那我们作为后端该如何实现对 excel 文件的解析和数据读取呢?说到这我就不得不推荐 easyexcel 了!
easyexcel 介绍
引用下官方对于 easyexcel 介绍:easyexcel是一个基于java的、快速、简洁、解决大文件内存溢出的excel处理工具。他能让你在不用考虑性能、内存的等因素的情况下,快速完成excel的读、写等功能。
官方网址:easyexcel官方文档 - 基于java的excel处理工具 | easy excel
快速上手 easyexcel
前置工作
先创建一个 spring boot 工程,并在 pom.xml 文件添加 easyexcel 和 lombok 依赖。
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
<optional>true</optional>
</dependency>
<dependency>
<groupid>com.alibaba</groupid>
<artifactid>easyexcel</artifactid>
<version>3.1.1</version>
</dependency>知道表头
如果我们知道 excel 数据的表头,即每列数据的类型包括有多少列时就可以用此方法读取 excel 文件数据。
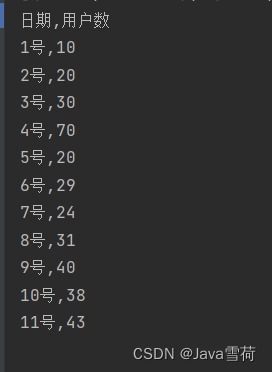
我们以下图数据为例,对改 excel 中的数据进行获取和处理。
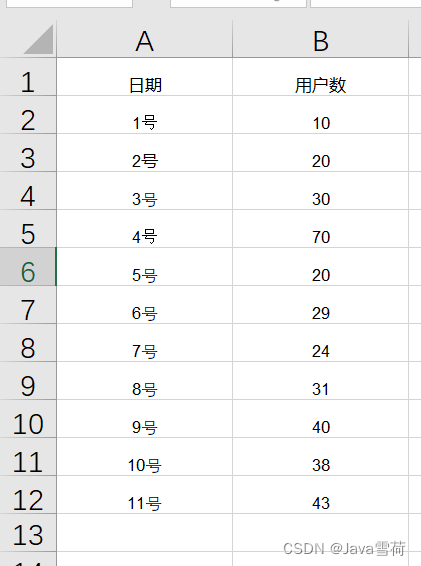
方法一:
首先我们创建一个名为 exceldata 的 java 对象,共有两个属性,分别是 date(日期列数据)和 usenum(用户列数据),每个属性对应 excel 每列某一行中的数据。那么很显而易见,每一行的数据就是一个 exceldata 对象,所有行的数据合起来就是一个泛型为 exceldata 的 exceldata 的集合。
@data
public class exceldata implements serializable {
/**
* 对应表格的日期列
*/
private string date;
/**
* 对应表格的用户数列
*/
private integer usernum;
}随后编写一个测试类,并在其中编写测试方法。
easyexcel 的 read 方法有很多中构造方法,其中 class head 就是表头类型,传入它还要传入 readlistener 监听器,以便在去读取每行数据时做些自定义操作。我们直接传入它的实现类实例,因为 pagereadlistener 支持逐页读取数据,通过读取指定行数的数据保证占用更少的内存。
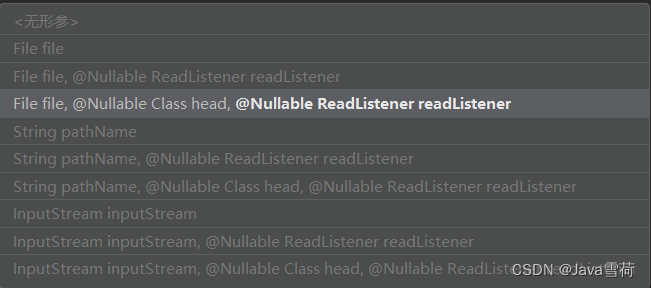
话不多说直接上代码:
/**
* 知道表头,并形成映射关系
*/
@test
public void doimportsformapping() throws filenotfoundexception{
// 读取 resource 目录下的 excel 文件(网站数据.xlsx)
file file = resourceutils.getfile("classpath:网站数据.xlsx");
// 创建一个 list 存储每行的数据,即 exceldata 对象
list<exceldata> list = new arraylist<>();
// 直接使用 easyexcel 的 read 方法,同时定义表头的类型,以便将列中数据映射为 exceldata 对象
easyexcel.read(file, exceldata.class, new pagereadlistener<exceldata>(datalist -> {
// 并且每行数据,并将其 add 至 list 中
for (exceldata exceldata : datalist) {
if (exceldata != null) {
list.add(exceldata);
}
}
})).exceltype(exceltypeenum.xlsx).sheet().doread(); // 指定 excel 的文件后缀,开始分析读取
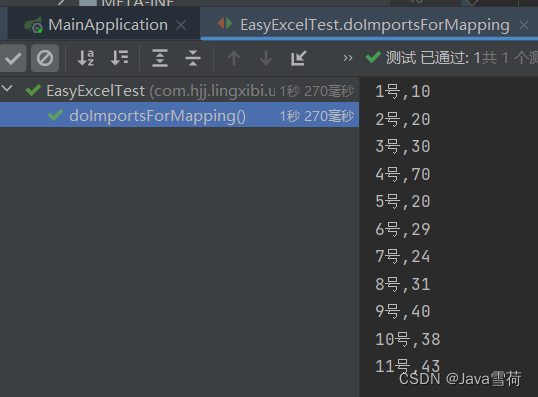
for (exceldata exceldata : list) {
system.out.println(exceldata.getdate() + "," + exceldata.getusernum());
}
}执行结果:
方法二:
方法一是直接一次性读取 excel 中的数据,缺少要读取的数据行数和一些自定义操作,所以我们在这里对上面的代码增强一下。
在此方法中我们通过匿名内部类的方式实现 readlistenser 接口,无需额外写一个类去实现 readlistener了。我们设置了一个临时存储的列表(大小为 2),当每次读取的数据(执行 invoke 方法)添加到临时存储表中。当其长度超过 2 时进行全部删除,在删除前我们可以将临时存储的列表存到数据库中,或进行一些其他的自定义操作。
doafterallanalysed 方法是分析并获取所有的数据后会执行的一个方法,我们可以在其中打上日志,表示 excel 所有数据已存入数据库中。
/**
* 知道表头,并形成映射关系
* @throws filenotfoundexception
*/
@test
public void doimportsformappingbyinnerclass() throws filenotfoundexception{
file file = resourceutils.getfile("classpath:网站数据.xlsx");
easyexcel.read(file, exceldata.class, new readlistener<exceldata>() {
// 单次缓存的数据量
public static final int batch_count = 2;
// 临时存储的列表
private list<exceldata> cacheddatalist = listutils.newarraylistwithexpectedsize(batch_count);
@override
public void invoke(exceldata exceldata, analysiscontext analysiscontext) {
cacheddatalist.add(exceldata);
getdata(exceldata);
if (cacheddatalist.size() >= batch_count) {
cacheddatalist = listutils.newarraylistwithexpectedsize(batch_count);
}
}
@override
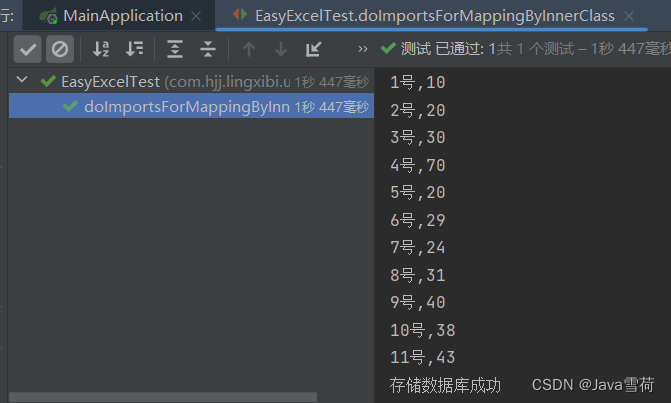
public void doafterallanalysed(analysiscontext analysiscontext) {
system.out.println("存储数据库成功");
}
private void getdata(exceldata exceldata) {
system.out.println(exceldata.getdate() + "," + exceldata.getusernum());
}
}).exceltype(exceltypeenum.xlsx).sheet().doread();
}执行结果:
不知道表头
方法三:
上面的两种方法都是我们知道表头,包括列的类型和列数量的情况下对 excel 文件进行数据获取的。那我们不知道表头信息,又该如何操作呢?
我们依赖利用 easyexcel 的 read 方法,和前面的步骤大差不差,只不过这次参数少了,如果你还要获取表头即表格的第一行数据,还可通过 headrownumber 方法指定首行编号为 0。
此时返回的是一个 list<map<integer, string>> 集合,其中 map 的 键对应表格的列编号(从 0 开始),值就是对应某一行某一列的值,list 的索引代表某一行的数据。调用 map 对象的 values() 方法即可直接获取某一行数据的集合,list<map<integer, string>> 就是所有行数据的集合。我们这说可能不太直观,我把它打印出来给你们看就很简单明了了。
[{0=日期, 1=用户数}, {0=1号, 1=10}, {0=2号, 1=20}, {0=3号, 1=30}, {0=4号, 1=70}, {0=5号, 1=20}, {0=6号, 1=29}, {0=7号, 1=24}, {0=8号, 1=31}, {0=9号, 1=40}, {0=10号, 1=38}, {0=11号, 1=43}]代码如下:
@test
public void doimport() throws filenotfoundexception {
list<map<integer, string>> list = null;
file file = resourceutils.getfile("classpath:网站数据.xlsx");
try {
list = easyexcel.read(file)
.exceltype(exceltypeenum.xlsx)
.sheet()
.headrownumber(0)
.doreadsync();
} catch (exception e) {
throw new runtimeexception("读取 excel 文件失败");
}
stringbuilder stringbuilder = new stringbuilder();
for (int i=0;i<list.size();i++) {
// 转为 linkedhashmap 主要是为了保证读取的数据和表格顺序一致
linkedhashmap<integer, string> linkedhashmap = (linkedhashmap) list.get(i);
list<string> datalist = linkedhashmap.values().stream()
.filter(objectutils::isnotempty).collect(collectors.tolist());
stringbuilder.append(stringutils.join(datalist, ",")).append("\n");
}
system.out.println(stringbuilder.tostring());
}执行结果:
总结
如果知道表头并且数据量较小,就用方法一,如果数据量较大或者想添加一些自定操作就用方法二。如果不知道表头并且想要读取表头的信息就用方法三。
到此这篇关于java实现读取excel文件功能的文章就介绍到这了,更多相关java读取excel文件内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论