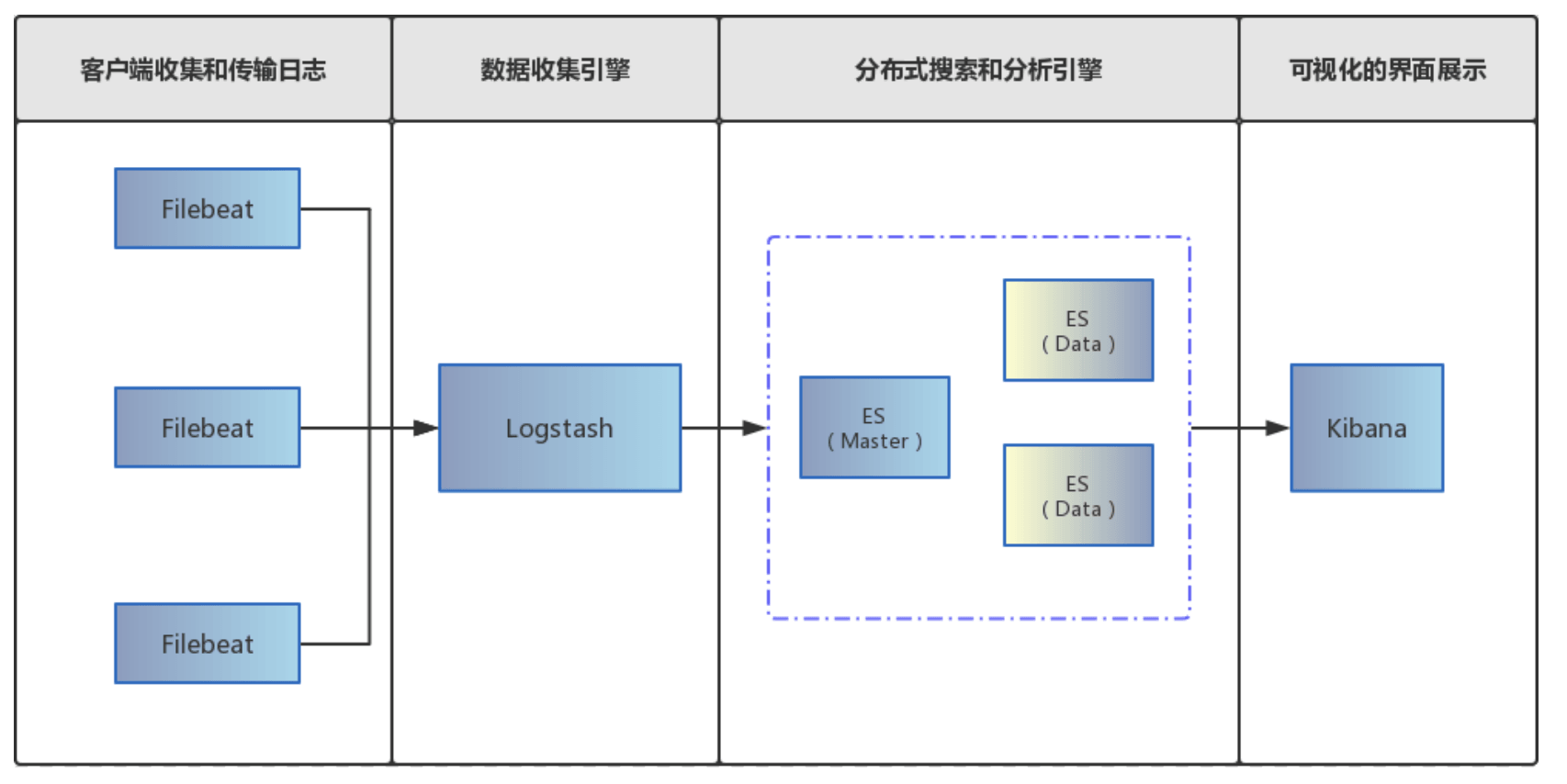
1、组件介绍
在elk stack中同时包括了elastic search、logstash、kibana以及filebeat;
各个组件的作用如下:
- filebeat:采集文件等日志数据;
- logstash:过滤日志数据;
- elastic search:存储、索引日志;
- kibana:用户界面;
各个组件之间的关系如下图所示:
2 、项目环境
因为elasticsearch是用java语言编写的,所以必须安装jdk的环境,并且是jdk 1.8以上。
# 安装
sudo yum install java-11-openjdk -y
# 安装完成查看java版本
java -version >>>: [root@vm-0-5-centos config]# java --version openjdk 11.0.16.1 2022-08-12 lts openjdk runtime environment (red_hat-11.0.16.1.1-1.el7_9) (build 11.0.16.1+1-lts) openjdk 64-bit server vm (red_hat-11.0.16.1.1-1.el7_9) (build 11.0.16.1+1-lts, mixed mode, sharing)
2.1 各个环境版本
- 操作系统:centos 7
- docker:20.10.18
- docker-compose:2.4.1
- elk version:7.4.2
- filebeat:7.4.2
- java:11.0.16.1
2.2 docker-compose变量配置
首先,在配置文件
.env中统一声明了es以及各个组件的版本:
.env
es_version=7.1.0 2.3 docker-compose服务配置
创建docker-compose的配置文件:
version: '3.4'
services:
elasticsearch:
image: "docker.elastic.co/elasticsearch/elasticsearch:${es_version}"
environment:
- discovery.type=single-node
volumes:
- /etc/localtime:/etc/localtime
- /elk/elasticsearch/data:/usr/share/elasticsearch/data
- /elk/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins
ports:
- "9200:9200"
- "9300:9300"
logstash:
depends_on:
- elasticsearch
image: "docker.elastic.co/logstash/logstash:${es_version}"
volumes:
- /elk/logstash/config/conf.d/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
ports:
- "5044:5044"
links:
- elasticsearch
kibana:
depends_on:
- elasticsearch
image: "docker.elastic.co/kibana/kibana:${es_version}"
volumes:
- /etc/localtime:/etc/localtime
# kibana.yml配置文件放在宿主机目录下,方便后续汉化
- /elk/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- "5601:5601"
links:
- elasticsearch
filebeat:
depends_on:
- elasticsearch
- logstash
image: "docker.elastic.co/beats/filebeat:${es_version}"
user: root # 必须为root
environment:
- strict.perms=false
volumes:
- /elk/filebeat/config/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
# 映射到容器中[作为数据源]
- /elk/filebeat/logs:/usr/share/filebeat/logs:rw
- /elk/filebeat/data:/usr/share/filebeat/data:rw
# 将指定容器连接到当前连接,可以设置别名,避免ip方式导致的容器重启动态改变的无法连接情况
links:
- logstash3、在services中声明了四个服务
- elasticsearch
- logstash
- kibana
- filebeat
3.1 elasticsearch服务
创建docker容器挂在的目录
注意:chmod -r 777 /elk/elasticsearch 要有访问权限
mkdir -p /elk/elasticsearch/config/ mkdir -p /elk/elasticsearch/data/ mkdir -p /elk/elasticsearch/plugins/ echo "http.host: 0.0.0.0">>/elk/elasticsearch/config/elasticsearch.yml
在elasticsearch服务的配置中有几点需要特别注意:
discovery.type=single-node:将es的集群发现模式配置为单节点模式;/etc/localtime:/etc/localtime:docker容器中时间和宿主机同步;/docker_es/data:/usr/share/elasticsearch/data:将es的数据映射并持久化至宿主机中;/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins:将插件挂载到主机;/elk/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:将配置文件挂载到主机;
3.2 logstash服务
创建docker容器挂在的目录
注意:chmod -r 777 /elk/logstash 要有访问权限
mkdir -p /elk/logstash/config/conf.d
在logstash服务的配置中有几点需要特别注意:
/elk/logstash/config/conf.d/logstash.conf:/usr/share/logstash/pipeline/logstash.conf:将宿主机本地的logstash配置映射至logstash容器内部;
下面是logstash的配置,在使用时可以自定义logstash.conf:
input {
# 来源beats
beats {
# 端口
port => "5044"
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "test"
}
stdout { codec => rubydebug }
}在这里我们将原来tcp收集方式修改为由filebeat上报,同时固定了索引为test;
3.3 kibana服务
创建docker容器挂在的目录
注意:chmod -r 777 /elk/kibana 要有访问权限
mkdir -p /elk/kibana/config
在kibana服务的配置中有几点需要特别注意:
/elk/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml:配置es的地址;/etc/localtime:/etc/localtime:docker容器中时间和宿主机同步;
修改 kibana.yml 配置文件,新增(修改)配置项i18n.locale: "zh-cn"
[root@vm-0-5-centos ~]# cd /mydata/kibana/config [root@vm-0-5-centos config]# cat kibana.yml # default kibana configuration for docker target server.name: kibana server.host: "0" elasticsearch.hosts: [ "http://elasticsearch:9200" ] xpack.monitoring.ui.container.elasticsearch.enabled: true i18n.locale: "zh-cn" # 设置为中文 [root@vm-0-5-centos config]#
3.4 filebeat服务
注意:chmod -r 777 /elk/filebeat 要有访问权限
创建docker容器挂在的目录
mkdir -p /elk/filebeat/config mkdir -p /elk/filebeat/logs mkdir -p /elk/filebeat/data
在filebeat服务的配置中有几点需要特别注意
配置user: root和环境变量strict.perms=false:如果不配置可能会因为权限问题无法启动;
volumes: - - /elk/filebeat/config/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro + - <your_log_path>/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro - - /elk/filebeat/logs:/usr/share/filebeat/logs:rw + - <your_log_path>:/usr/share/filebeat/logs:rw - - /elk/filebeat/data:/usr/share/filebeat/data:rw + - <your_data_path>:/usr/share/filebeat/logs:rw
同时还需要创建filebeat配置文件:
filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
# 容器中目录下的所有.log文件
- /usr/share/filebeat/logs/*.log
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.dashboards.enabled: false
setup.kibana:
host: "http://kibana:5601"
# 直接传输至es
#output.elasticsearch:
# hosts: ["http://es-master:9200"]
# index: "filebeat-%{[beat.version]}-%{+yyyy.mm.dd}"
# 传输至logstash
output.logstash:
hosts: ["logstash:5044"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~上面给出了一个filebeat配置文件示例,实际使用时可以根据需求进行修改;
4、使用方法
4.1 方法一
使用前必看:
① 修改elk版本
可以修改在.env中的es_version字段,修改你想要使用的elk版本;
② logstash配置
修改logstash.conf为你需要的日志配置;
③ 修改es文件映射路径
修改docker-compose中elasticsearch服务的volumes,将宿主机路径修改为你实际的路径:
volumes: - /etc/localtime:/etc/localtime - - /docker_es/data:/usr/share/elasticsearch/data + - [your_path]:/usr/share/elasticsearch/data
并且修改宿主机文件所属:
sudo chown -r 1000:1000 [your_path]
④ 修改filebeat服务配置
修改docker-compose中filebeat服务的volumes,将宿主机路径修改为你实际的路径:
volumes:
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- - /elk/filebeat/logs:/usr/share/filebeat/logs:rw
+ - <your_log_path>:/usr/share/filebeat/logs:rw
- - /elk/filebeat/data:/usr/share/filebeat/data:rw
+ - <your_data_path>:/usr/share/filebeat/logs:rw⑤ 修改filebeat配置
修改filebeat.yml为你需要的配置;
filebeat配置文件详情参见如下:
[vagrant@localhost filebeat-7.7.1]$ vi filebeat.yml
###################### filebeat configuration example #########################
#=========================== filebeat inputs =============================
filebeat.inputs:
# each - is an input. most options can be set at the input level, so
#每个-是一个输入。大多数选项可以在输入级别设置,因此
# you can use different inputs for various configurations.
#您可以为各种配置使用不同的输入。
# below are the input specific configurations.
#下面是特定于输入的配置。
- type: log
# change to true to enable this input configuration.
#更改为true以启用此输入配置。
enabled: true
# paths that should be crawled and fetched. glob based paths.
#应该被爬取的路径。基础路径。
paths:
#可配置多个路径
- /home/vagrant/apache-tomcat-9.0.20/logs/catalina.*.out
#- c:\programdata\elasticsearch\logs\*
# exclude lines. a list of regular expressions to match. it drops the lines that are
#排除线路。要匹配的正则表达式列表。它去掉了
# matching any regular expression from the list.
#匹配列表中的任何正则表达式。
#exclude_lines: ['^dbg']
# include lines. a list of regular expressions to match. it exports the lines that are
#要匹配的正则表达式列表。它导出
# matching any regular expression from the list.
#匹配列表中的任何正则表达式。
#include_lines: ['^info','^err', '^warn']
# exclude files. a list of regular expressions to match. filebeat drops the files that
#排除的文件。要匹配的正则表达式列表。filebeat删除的文件
# are matching any regular expression from the list. by default, no files are dropped.
#匹配列表中的任何正则表达式。默认情况下,没有文件被删除。
#exclude_files: ['.gz$']
# optional additional fields. these fields can be freely picked
#可选的附加字段。这些字段可以自由选择
# to add additional information to the crawled log files for filtering
#添加附加信息到抓取的日志文件进行过滤
#fields:
# level: debug
# review: 1
### multiline options
# multiline can be used for log messages spanning multiple lines. this is common
# multiline可用于记录跨多行的消息。这是常见的
# for java stack traces or c-line continuation
#用于java堆栈跟踪或c行延续
# the regexp pattern that has to be matched. the example pattern matches all lines starting with [
#必须匹配的regexp模式。示例模式匹配以[开头的所有行
multiline.pattern: ^\[
# defines if the pattern set under pattern should be negated or not. default is false.
#定义模式下的模式集是否应该被否定。默认是false
multiline.negate: true
# match can be set to "after" or "before". it is used to define if lines should be append to a pattern
#match可以设置为“after”或“before”。它用于定义是否应该将行追加到模式中
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
#在之前或之后匹配的,或者只要模式没有基于negate匹配。
# note: after is the equivalent to previous and before is the equivalent to to next in logstash
#注意:在logstash中,after等同于previous, before等同于next
multiline.match: after
#============================= filebeat modules ===============================
filebeat.config.modules:
# glob pattern for configuration loading
#配置加载的glob模式
path: ${path.config}/modules.d/*.yml
# set to true to enable config reloading
#设置为true可重新加载配置
reload.enabled: false
# period on which files under path should be checked for changes
#应该检查path下的文件是否有更改的时间段
#reload.period: 10s
#==================== elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
#================================ general =====================================
# the name of the shipper that publishes the network data. it can be used to group
#应该检查path下文件更改的时间段#发布网络数据的托运人的名称。它可以用来分组
# all the transactions sent by a single shipper in the web interface.
#由一个托运人在web interfac中发送的所有事务
#name:
# the tags of the shipper are included in their own field with each
#每个托运人的标签都包含在它们自己的字段中
# transaction published.
#事务发表。
#tags: ["service-x", "web-tier"]
# optional fields that you can specify to add additional information to the
#属性中添加附加信息的可选字段
# output.
#fields:
# env: staging
#============================== dashboards =====================================
# these settings control loading the sample dashboards to the kibana index. loading
#这些设置控制将样例指示板加载到kibana索引。加载
# the dashboards is disabled by default and can be enabled either by setting the
#仪表板在默认情况下是禁用的,可以通过设置
# options here or by using the `setup` command.
#选项或使用' setup '命令。
#setup.dashboards.enabled: false
# the url from where to download the dashboards archive. by default this url
#下载仪表板归档文件的url。默认情况下,这个url
# has a value which is computed based on the beat name and version. for released
#有一个基于节拍名称和版本计算的值。对发布的
# versions, this url points to the dashboard archive on the artifacts.elastic.co
#版本号,此url指向工件.elastic.co上的仪表板存档
# website.
#setup.dashboards.url:
#============================== kibana =====================================
# starting with beats version 6.0.0, the dashboards are loaded via the kibana api.
#从beats 6.0.0版本开始,仪表板是通过kibana api加载的。
# this requires a kibana endpoint configuration.
#这需要kibana端点配置。
setup.kibana:
# kibana host
# scheme and port can be left out and will be set to the default (http and 5601)
# in case you specify and additional path, the scheme is required: http://localhost:5601/path
# ipv6 addresses should always be defined as: https://[2001:db8::1]:5601
host: "192.168.0.140:5601"
# kibana space id
# id of the kibana space into which the dashboards should be loaded. by default,
# the default space will be used.
#space.id:
#============================= elastic cloud ==================================
# these settings simplify using filebeat with the elastic cloud (https://cloud.elastic.co/).
# the cloud.id setting overwrites the `output.elasticsearch.hosts` and
# `setup.kibana.host` options.
# you can find the `cloud.id` in the elastic cloud web ui.
#cloud.id:
# the cloud.auth setting overwrites the `output.elasticsearch.username` and
# `output.elasticsearch.password` settings. the format is `<user>:<pass>`.
#cloud.auth:
#================================ outputs =====================================
# configure what output to use when sending the data collected by the beat.
#配置在发送由节拍收集的数据时使用的输出。
#-------------------------- elasticsearch output ------------------------------
#output.elasticsearch:
# array of hosts to connect to.
#hosts: ["192.168.0.140:9200"]
# protocol - either `http` (default) or `https`.
#protocol: "https"
# authentication credentials - either api key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
#----------------------------- logstash output --------------------------------
output.logstash:
# the logstash hosts
hosts: ["192.168.0.140:5044"]
# optional ssl. by default is off.
# list of root certificates for https server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# certificate for ssl client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# client certificate key
#ssl.key: "/etc/pki/client/cert.key"
#================================ processors =====================================
# configure processors to enhance or manipulate events generated by the beat.
#配置处理器以增强或操纵节拍生成的事件。
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
#================================ logging =====================================
# sets log level. the default log level is info.
# available log levels are: error, warning, info, debug
#logging.level: debug
# at debug level, you can selectively enable logging only for some components.
# to enable all selectors use ["*"]. examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]
#============================== x-pack monitoring ===============================
# filebeat can export internal metrics to a central elasticsearch monitoring
# cluster. this requires xpack monitoring to be enabled in elasticsearch. the
# reporting is disabled by default.
# set to true to enable the monitoring reporter.
#monitoring.enabled: false
# sets the uuid of the elasticsearch cluster under which monitoring data for this
# filebeat instance will appear in the stack monitoring ui. if output.elasticsearch
# is enabled, the uuid is derived from the elasticsearch cluster referenced by output.elasticsearch.
#monitoring.cluster_uuid:
# uncomment to send the metrics to elasticsearch. most settings from the
# elasticsearch output are accepted here as well.
# note that the settings should point to your elasticsearch *monitoring* cluster.
# any setting that is not set is automatically inherited from the elasticsearch
# output configuration, so if you have the elasticsearch output configured such
# that it is pointing to your elasticsearch monitoring cluster, you can simply
# uncomment the following line.
#monitoring.elasticsearch:
#================================= migration ==================================
# this allows to enable 6.7 migration aliases
#migration.6_to_7.enabled: true4.2 方法二
cd elk #修改run.sh里面的es_host、log_host、kb_host chmod +x ./run.sh #使脚本具有执行权限 ./run.sh #执行脚本
5、启动
随后使用docker-compose命令启动:
docker-compose up -d creating network "docker_repo_default" with the default driver creating docker_repo_elasticsearch_1 ... done creating docker_repo_kibana_1 ... done creating docker_repo_logstash_1 ... done creating docker_repo_filebeat_1 ... done
到此这篇关于docker中通过docker-compose部署elk的文章就介绍到这了,更多相关docker-compose部署elk内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论