本文介绍了在mindspore标准格式下进行cuda算子开发的方法和流程,可以让开发者在现有的ai框架下仍然可以调用基于cuda实现的高性能的算子。并且,除了常规的数值计算之外,在mindspore框架下,我们还可以通过实现一个bprop函数,使得我们手写的这个cuda算子也可以使用mindspore框架本身自带的自动微分-端到端微分技术。
技术背景
当今众多的基于python的ai框架(如mindspore、pytorch等)给了开发者非常便利的编程的条件,我们可以用python的简单的语法写代码,然后由框架在后端自动编译成可以在gpu上高效计算的程序。而对于一些定制化比较高的算法,mindspore也支持了相关的接口,允许开发者自己开发相应的cuda算子(需要统一接口),然后编译成.so动态链接库,再用mindspore内置的函数加载为本地算子。本文针对这种方案写一个简单的示例。
程序结构
本地自己手写一个cuda算子,一般至少需要两个文件和一个nvcc的环境,最好是在安装完成mindspore的gpu版本之后,再尝试cuda算子的引入。具体mindspore的安装方法,可以参考mindspore官网,这里不做赘述。我这里使用的环境是10.1版本的nvcc:
$ nvcc -v nvcc: nvidia (r) cuda compiler driver copyright (c) 2005-2019 nvidia corporation built on sun_jul_28_19:07:16_pdt_2019 cuda compilation tools, release 10.1, v10.1.243 $ python3 -m pip show mindspore name: mindspore version: 2.1.0 summary: mindspore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. home-page: https://www.mindspore.cn author: the mindspore authors author-email: contact@mindspore.cn license: apache 2.0 location: /home/dechin/anaconda3/envs/mindspore-latest/lib/python3.7/site-packages requires: numpy, protobuf, pillow, astunparse, scipy, psutil, asttokens, packaging required-by:
需要准备的两个文件,一个是cuda算子本身的.cu文件,另一个是用来调用cuda算子的.py文件。操作流程是:先按照自己的需求写好cuda算子,然后用nvcc进行编译,编译输出为.so的动态链接库,然后在python脚本中使用mindspore.ops.custom生成相应的算子。在mindspore2.1之后的版本中,对于本地cuda算子的调用定义了统一的接口,其格式为:
extern "c" int customfunc(int nparam, void **params, int *ndims, int64_t **shapes, const char **dtypes, void *stream, void *extra);
具体方法可以参考官网的这一篇文档说明。这样的话,在.cu文件中至少有两个函数,一个是原本用于计算的kernel函数,另一个是用于统一标准接口的customfunc函数。需要说明的是,旧版本的mindspore是没有这样的规范的,所以旧版本的算子没有customfunc函数也能够用nvcc编译,但是无法在新版本的mindspore中调用。
一维张量求和
我们用一个一维的张量求和的示例来演示一下如何在本地写一个可以用mindspore来调用的cuda算子,一维张量求和的算法是比较简单的:
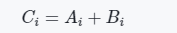
那么对应的cuda算子的代码如下所示:
// custom_add.cu
// nvcc --shared -xcompiler -fpic -o custom_add.so custom_add.cu
// 常量,一般可以放在.cuh头文件中
constexpr int threads = 1024;
// 用于cuda计算的kernel函数
__global__ void customaddkernel(float *input1, float *input2, float *output, size_t size) {
auto idx = blockidx.x * threads + threadidx.x;
if (idx < size) {
// 逐元素操作,cuda算子的基本写法
output[idx] = input1[idx] + input2[idx];
}
}
// 标准算子接口
extern "c" int customadd(int nparam, void **params, int *ndims, int64_t **shapes, const char **dtypes, void *stream,
void *extra) {
cudastream_t custream = static_cast<cudastream_t>(stream);
// 输出变量的位置
constexpr int output_index = 2;
// 传入的参数都是指针形式
float *input1 = static_cast<float *>(params[0]);
float *input2 = static_cast<float *>(params[1]);
float *output = static_cast<float *>(params[2]);
// 获取输入张量的大小
int size = shapes[output_index][0];
// gpu运算中的block和thread,一般要求block*thread大于或者等于size即可
int blocks = ceil(size / threads) + 1;
// 调用kernel函数
customaddkernel<<<blocks, threads, 0, custream>>>(input1, input2, output, size);
return 0;
}值得注意的是,上述customadd函数中的params有3个输入,但是实际上其中一个是返回值,这也是mindspore对于标准接口的设定,不需要我们额外传入一个变量。保存好上述的cuda算子代码之后,可以用如下指令直接编译成python可以调用的动态链接库:
$ nvcc --shared -xcompiler -fpic -o custom_add.so custom_add.cu
编译完成后,会在当前目录下生成一个新的.so文件,然后就可以在python代码中进行调用:
# test_custom_ops.py
# python3 test_custom_ops.py
import mindspore as ms
from mindspore import ops, tensor, context
ms.set_context(device_target="gpu", mode=context.graph_mode)
t1 = tensor([1., 2., 3.], ms.float32)
t2 = tensor([3., 2., 1.], ms.float32)
customadd = ops.custom("./custom_add.so:customadd",
out_shape=[t1.shape[0]],
out_dtype=ms.float32,
func_type="aot"
)
res = customadd(t1, t2)
ops.print_(res)上述的customadd就是我们导入的基于cuda算子来写的本地mindspore算子,并且这种算子还可以使用mindspore进行注册,这样就不需要每次使用都去加载这个动态链接库,感兴趣的童鞋可以自己研究一下算子注册的方法。上述python代码的运行结果如下:
$ python3 test_custom_ops.py tensor(shape=[3], dtype=float32, value= [ 4.00000000e+00, 4.00000000e+00, 4.00000000e+00])
可见跟我们预期的结果是一致的,那么就完成了一个本地cuda算子的实现和调用。
自定义算子反向传播
在前面的章节里面我们已经实现了一个本地的一维张量求和算子,但是这还不是一个完整的算子实现,因为我们在ai框架中一般要求算子可自动微分,光实现一个算子是不完整的,因此这里我们再通过bprop函数,来实现一下自定义算子的反向传播:
# test_custom_ops.py
# python3 test_custom_ops.py
import mindspore as ms
from mindspore import ops, tensor, context
from mindspore import nn, grad
ms.set_context(device_target="gpu", mode=context.graph_mode)
t1 = tensor([1., 2., 3.], ms.float32)
t2 = tensor([3., 2., 1.], ms.float32)
customadd = ops.custom("./custom_add.so:customadd",
out_shape=[t1.shape[0]],
out_dtype=ms.float32,
func_type="aot"
)
为了自动微分,我们需要定义一个cell类来封装我们的自定义算子:
class add(nn.cell):
# 反向传播函数
def bprop(self, x, y, out, dout):
return (y, )
# 计算函数
def construct(self, x, y):
return customadd(x, y)
# 把cell类加载为custom_add函数
custom_add = add()
# 计算求和结果
res = custom_add(t1, t2)
# 计算自动微分结果
res_g = grad(custom_add, grad_position=(0, ))(t1, t2)
print(res)
print(res_g)在这个代码中,主要就是增加了一个cell类和两个新的函数bprop和construct,分别用于计算函数的反向传播和正向值,代码运行的结果如下:
$ python3 test_custom_ops.py [4. 4. 4.] [3. 2. 1.]
当然,这里我们没有再额外写一个用于返回反向传播值的cuda算子,但是原则上对于较为复杂的函数,是需要自己手动写一个用于求微分数值的cuda算子的。
总结概要
本文介绍了在mindspore标准格式下进行cuda算子开发的方法和流程,可以让开发者在现有的ai框架下仍然可以调用基于cuda实现的高性能的算子。并且,除了常规的数值计算之外,在mindspore框架下,我们还可以通过实现一个bprop函数,使得我们手写的这个cuda算子也可以使用mindspore框架本身自带的自动微分-端到端微分技术。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/mindspore-cuda.html
作者id:dechinphy
更多原著文章:https://www.cnblogs.com/dechinphy/
请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html
到此这篇关于mindspore导入cuda算子的文章就介绍到这了,更多相关mindspore导入cuda内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论