一、sqlalchemy介绍
sqlalchemy 是 python sql 工具包和对象关系映射器,为应用程序开发人员提供 sql 的全部功能和灵活性。
sqlalchemy支持sqlite、postgresql、oracle、mysql、mariadb、microsoft sql server等多种数据库。
二、sqlalchemy安装

我安装的版本是:sqlalchemy==2.0.29。注意sqlalchemy2.x以上的版本和1.x版本差别还是挺大的,注意版本。
因为sqlalchemy不能直接操作数据库,还需要python中的pymysql第三方库,所以还需要安装pymysql

pymysql==1.1.0.
三、创建测试数据库
创建一个用于测试的数据库
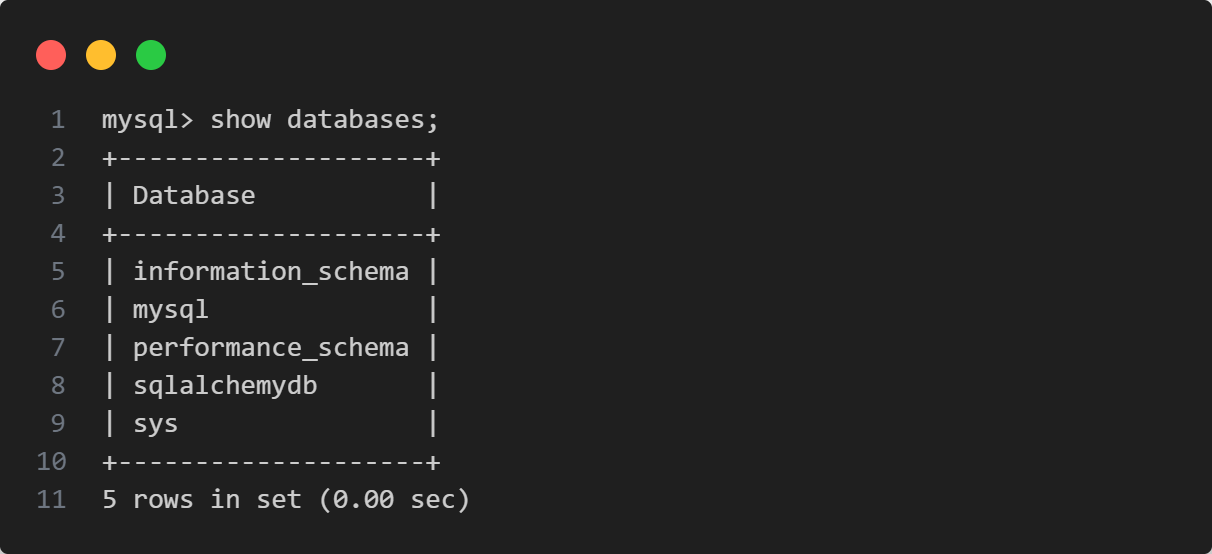
其中sqlalchemydb就是测试数据库
四、封装sqlalchemydb类
在python项目根目录下创建一个sqlalchemy_db.py文件,当然你也可以在其他目录下创建。其中内容如下:

说明1:该文件sqlalchemy_db.py的作用是封装一个sqlalchemy的类,为实例化sqlalchemy对象做准备
说明2:self.engine是连接数据的引擎设置,只有设置了engine,我们才能通过sqlalchemy对象操作数据库
说明3:self.session可以理解为数据库的操作对象,我们对数据库的操作都是基于该session实现的。
说明4:engine参数解释
- 参数url:sqlalchemy要连接的数据库地址,其格式为:数据库类型+数据库驱动://数据库用户:数据库密码@数据库地址:端口号/数据库名称?编码方式
- 参数convert_unicode:按照指定的编码方式对字符串进行编码解码
- 参数isolation_level:设置事务的隔离界别
- 参数pool_recycle:设置回收链接的时间,单位毫秒
- 参数pool_pre_ping:每次连接前预先ping一下
- 参数pool_size: 链接池中保持数据库连接的数量,默认是5
- 参数max_overflow :当链接池中的连接数不够用的时候,允许额外再创建的最大链接数量,默认是10
- pool_timeout:排队等数据库链接时的超时时间
说明5:scoped_session创建的session是线程安全的。
五、创建model模型
5.1 sqlalchemy支持的数据类型
- integer:整形
- string:字符串
- float:浮点型
- decimal:定点型
- boolean:bool
- date:日期类型
- datetime:日期+时间类型
- time:时间类型
- enum:枚举类型
- text:文本类型
- longtext:长文本类型
5.2 sqlalchemy字段常用的约束
- default:默认值
- nullable:是否可空
- primary_key:是否为主键
- unique:是否唯一
- autoincrement:是否自动增长
- name:该属性在数据库中的映射字段
5.3 创建测试的model.py文件
在项目的根目录或者你需要的地方创建一个model.py文件,内容如下:
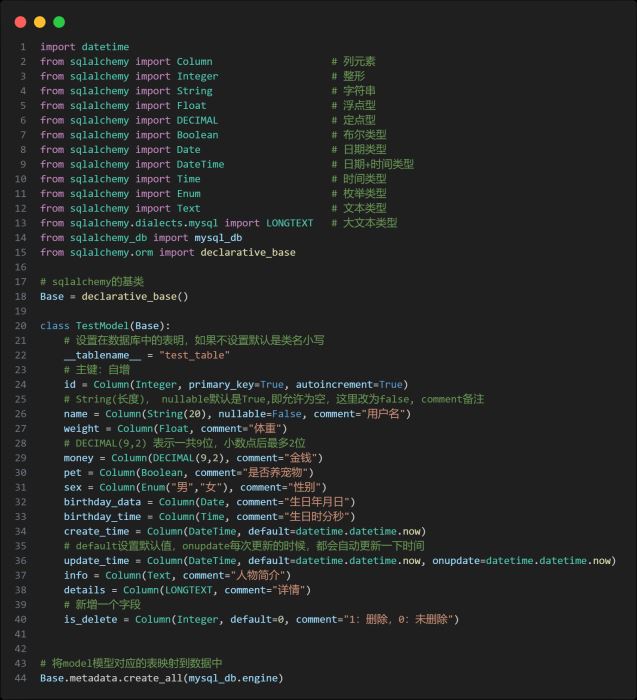
说明1:为了测试效果,我们在这个model类中尽可能的多展示了不同字段的使用
说明2:base.metadata.create_all() 会将我们的模型自动映射到数据库中,当然也可以手动去数据库中创建表
说明3:我们写好的这个model类暂时还没有使用呢 。
六、创建测试文件
在项目根目录下或者你需要的地方创建一个test.py文件,内容如下:

这时我们在test.py中就只引入mysql_db和testmodel,其他的先不写,然后使用python test.py运行该脚本,就会发现我们的model模型,已经同步到数据库中了

七、添加测试数据
7.1 单条添加数据
修改test.py文件如下,然后python test.py执行

执行之后,我们去数据库查看结果如下:

说明1:create_time,update_time,is_delete都是有默认值的字段,如果不设置,会自动显示默认值。
说明2:money字段总长度时9位,但是可以少于9位,不能多于9位,小数部位不足时补0
7.2 批量添加数据
再来演示一下批量增加数据,代码如下还是在test.py中

执行后的结果如下:

八、修改删除
8.1 修改
刚才已经演示了增加数据的代码,下面我们看一下修改,代码如下,还是在test.py文件中
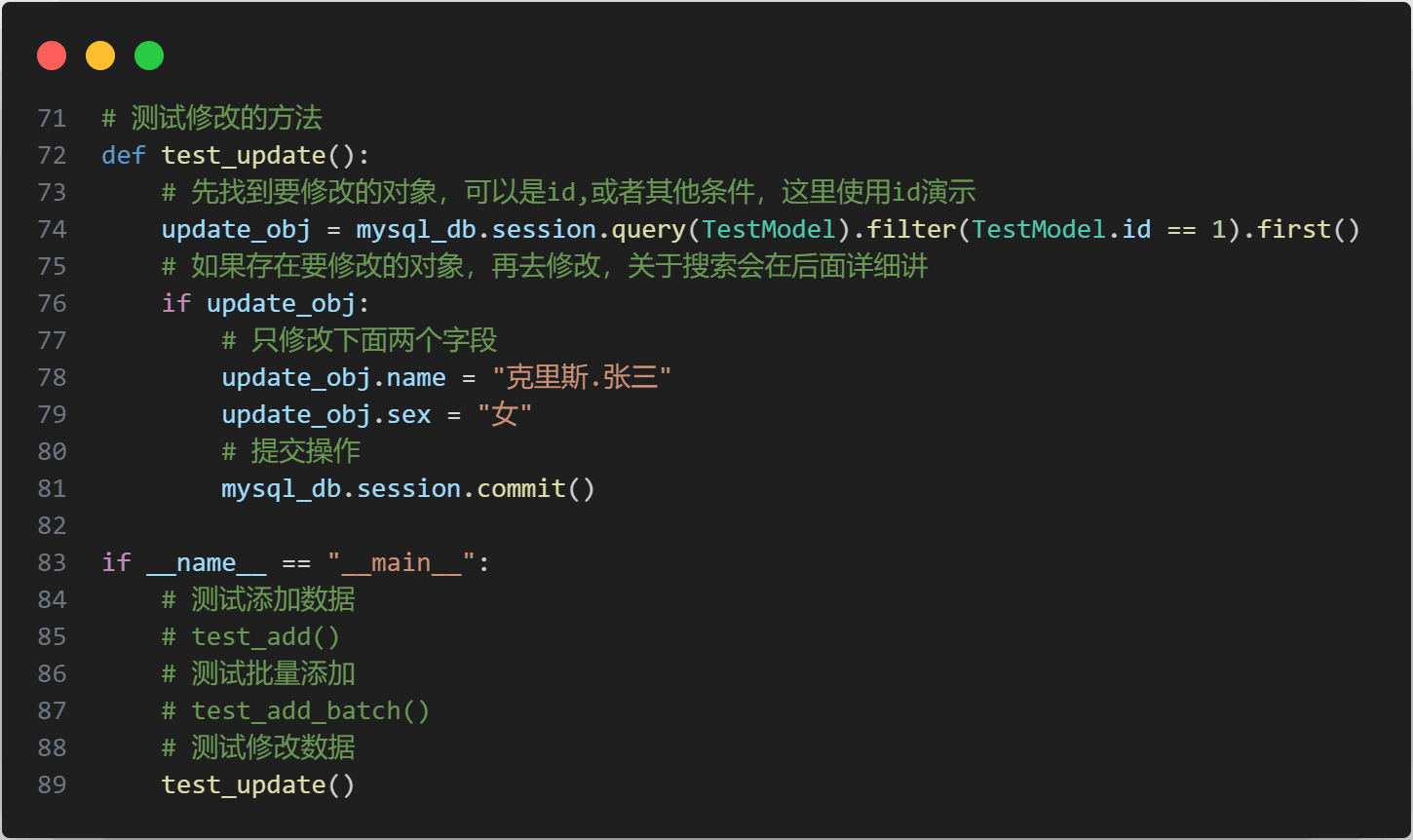
查看一下数据库

8.2 删除
可以看到姓名和性别已经修改成功。再来测试一下删除数据
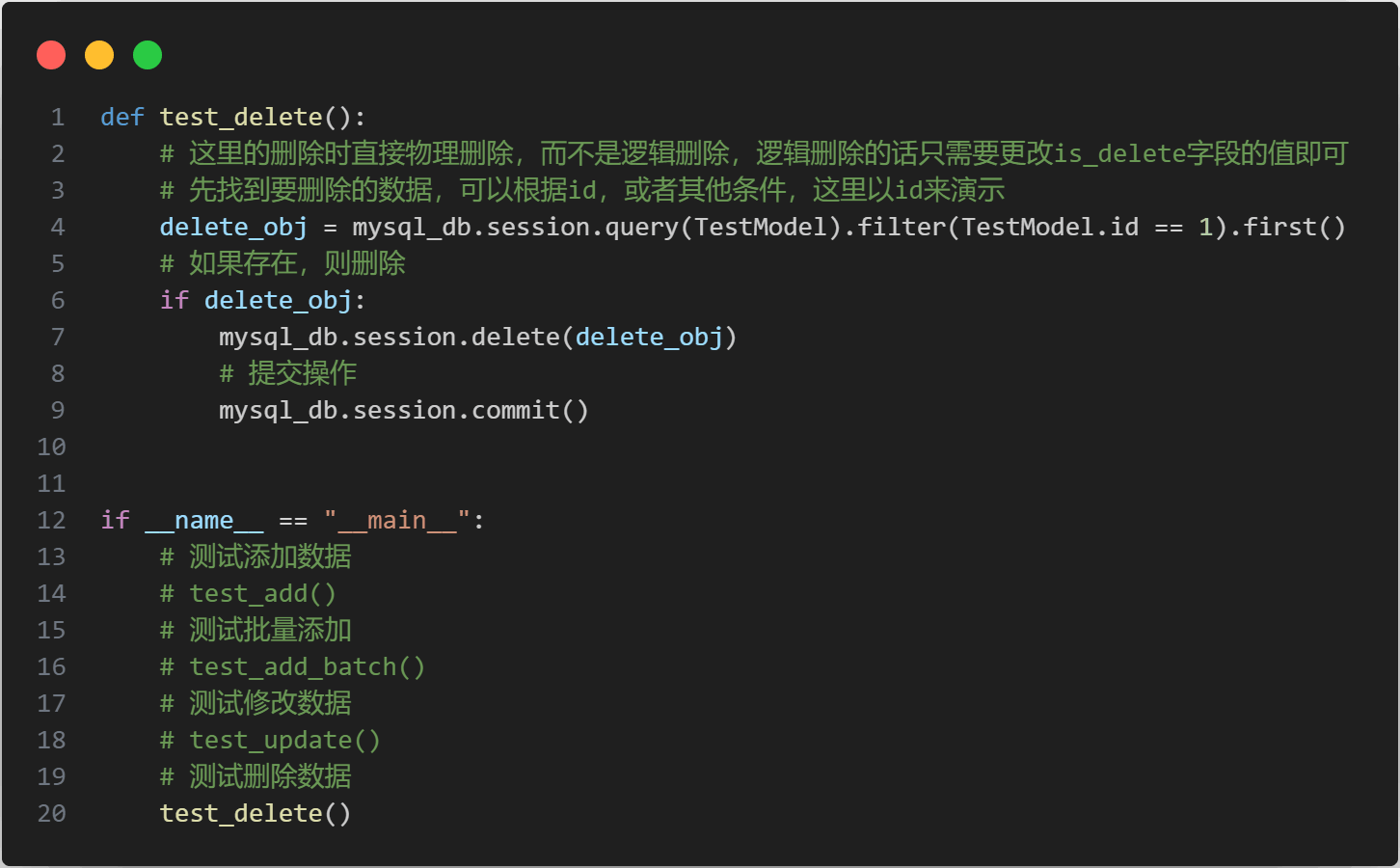

可以看出,数据库中已经没有id=1的数据了
九、查询
在进行查询测试之前,先往数据库中添加一下测试数据

9.1 query关键字
在做查询的时候我们通常query关键字,它类似于sql中select 关键字,query参数通常可以填写三类参数
- model模型对象:指定查找这个模型中所有的字段
- model模型对象中的属性:可以指定只查找某个model中的几个属性字段
- 聚合函数:func.count(统计行的数量),func.avg(求平均数),func.max(求最大值),func.min(求最小值),func.sum(求和)

查看一下打印结果

说明1:在做查询的时候 .first() 表示查询第一个满足条件的数据
说明2:在做查询的时候 .all() 表示查询所有数据
说明3:如果不是查询全部字段,只查询部分字段或者聚合函数的话,结果返回的是一个元组,通过下标取数据即可
9.2 filter关键字
过滤是数据提取的一个很重要的功能,以下对一些常用的过滤条件进行解释,并且这些过滤条件都是只能通过filter方法实现,常用的方法有
- 相等: ==
- 不相等: !=
- 模糊查询:like(%xx$)
- 包含:in_()
- 不包含:~ in_() 注意 ~不是直接加在in前面的,注意看代码示例
- 空:==none 或者 is_(none)
- 不为空: !=none 或者 isnot(none)
- 并且: and_()或者也可以使用逗号连接多个条件
- 或者:or_()

打印结果如下:

9.3分页查询
方式1:使用limit+offset实现
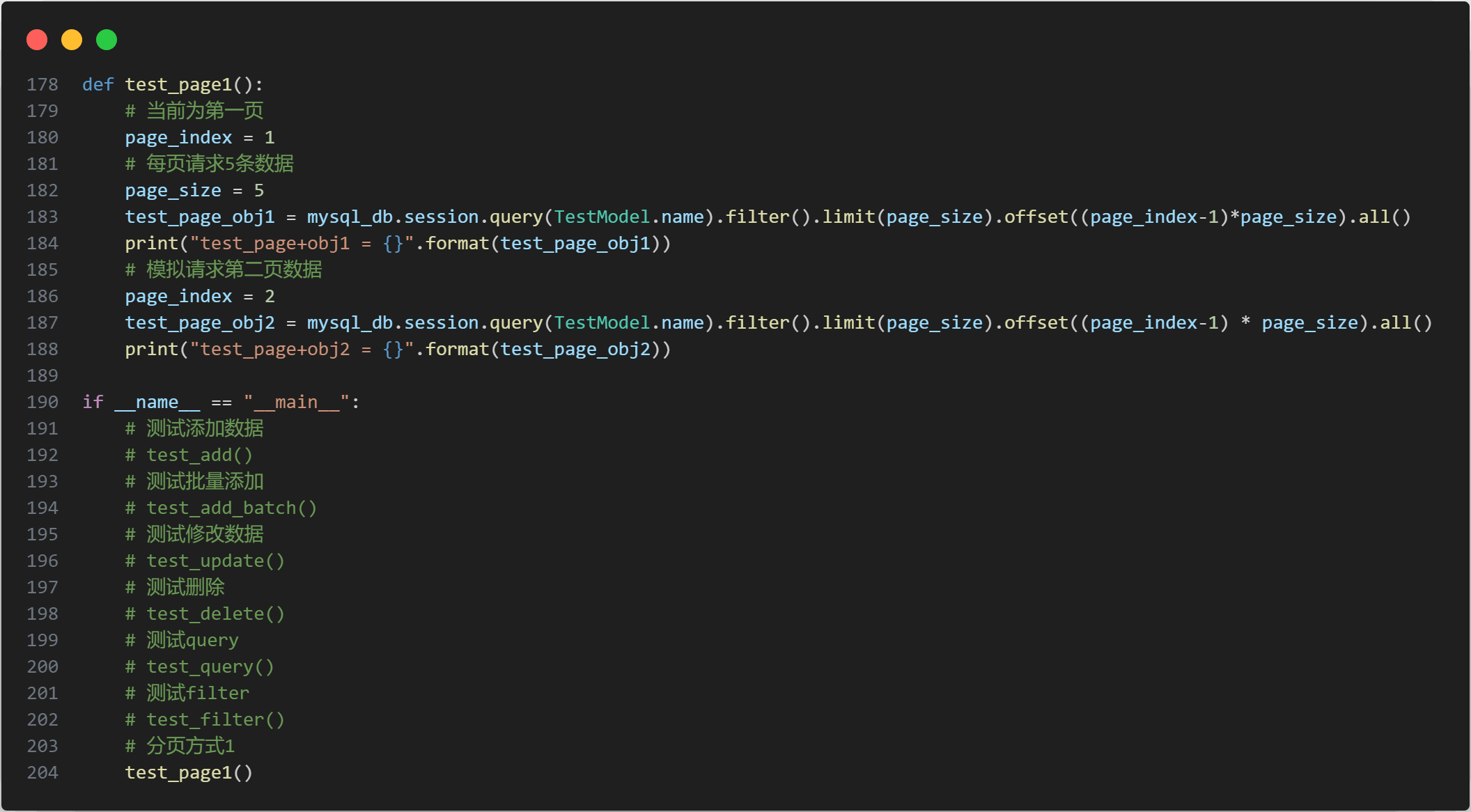
查询结果为:

方式2:使用slice

输出结果为:

十、排序

输出结果为:

侯哥语录:我曾经是一个职业教育者,现在是一个自由开发者。我希望我的分享可以和更多人一起进步。分享一段我喜欢的话给大家:"我所理解的自由不是想干什么就干什么,而是想不干什么就不干什么。当你还没有能力说不得时候,就努力让自己变得强大,拥有说不得权利。"
到此这篇关于sqlalchemy详解的文章就介绍到这了,更多相关sqlalchemy详解内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论