在实际业务中,我们常常需要统计工作日(周一至周五) 的访问量、订单量或用户活跃度,而剔除周末数据。mysql 提供了多种日期函数来实现这一需求,但不同方案在可读性、性能、索引利用上差异显著。本文将从基础方法到高级优化,系统讲解如何高效统计工作日数据,并提供生产级建议。
一、业务场景与挑战
假设有一张访问记录表 visits:
create table visits (
id int primary key auto_increment,
visit_date datetime not null, -- 访问时间
user_id int,
page varchar(100)
);
需求:统计每天(或某时间段内)工作日的人次,且要求查询高效、支持大数据量。
挑战:
visit_date是datetime类型,包含时分秒。- 直接对日期字段使用
weekday()等函数会导致索引失效。 - 数据量百万级以上时,全表扫描不可接受。
二、基础查询方法对比
mysql 提供多个函数用于判断星期几,各有特点:
| 函数 | 返回值范围 | 周一对应值 | 周日对应值 | 特点 |
|---|---|---|---|---|
weekday(date) | 0 ~ 6 | 0 | 6 | 以周一为起点,适合“周一到周五”判断(<=4) |
dayofweek(date) | 1 ~ 7 | 2 | 1 | 以周日为起点,判断工作日需 between 2 and 6 |
dayname(date) | 字符串 (‘monday’…) | ‘monday’ | ‘sunday’ | 可读性好,但分组/过滤时需字符串比较 |
date_format(date, '%w') | 0 ~ 6(周日=0) | 1 | 0 | 兼容性一般,周日为0需注意 |
推荐使用 weekday(),因为其返回值直接对应“周一=0,周五=4”,条件 <=4 语义清晰。
方法1:使用 weekday() 函数
select
date(visit_date) as visit_day,
count(*) as visit_count
from visits
where weekday(visit_date) <= 4 -- 0~4 周一到周五
group by date(visit_date)
order by visit_day;
优点:简单直观。
缺点:weekday(visit_date) 无法使用 visit_date 上的普通索引。
方法2:使用 dayofweek() 函数
select
date(visit_date) as visit_day,
count(*) as visit_count
from visits
where dayofweek(visit_date) between 2 and 6 -- 2=周一,6=周五
group by date(visit_date);
两者性能相近,但 weekday 更贴近中国人“周一为一周第一天”的习惯。
方法3:增加星期名称列(可读性优先)
select
date(visit_date) as visit_day,
case weekday(visit_date)
when 0 then '周一'
when 1 then '周二'
when 2 then '周三'
when 3 then '周四'
when 4 then '周五'
else '周末'
end as weekday_cn,
count(*) as visit_count
from visits
where weekday(visit_date) <= 4
group by date(visit_date);
三、性能优化方案
当数据量达到百万级且查询频繁时,必须解决 函数导致索引失效 的问题。以下按优化程度递增给出三种方案。
3.1 方案一:范围过滤 + 函数计算(小数据量可用)
如果查询时间范围较小(如一周),mysql 会先根据 visit_date 的索引过滤出该周数据,再计算 weekday。此时性能尚可。
-- 假设查询2025-05-12到2025-05-18这一周的数据 select date(visit_date), count(*) from visits where visit_date between '2025-05-12 00:00:00' and '2025-05-18 23:59:59' and weekday(visit_date) <= 4 group by date(visit_date);
3.2 方案二:虚拟列 + 函数索引(mysql 8.0+)
mysql 8.0 支持函数索引,可以直接在表达式上创建索引,无需修改表结构。
-- 创建函数索引(直接对 weekday(visit_date) 建立索引) create index idx_visit_weekday on visits ((weekday(visit_date)));
查询时索引会自动生效:
select date(visit_date), count(*) from visits where weekday(visit_date) <= 4 group by date(visit_date);
注意:函数索引要求 mysql 8.0.13+,并且函数必须标记为 deterministic(如 weekday 本身是确定性的)。
3.3 方案三:存储生成列(虚拟列) + 普通索引(兼容更广)
对于 mysql 5.7 或需要兼容更广泛版本的场景,可以增加一个虚拟列存储星期几,并对该列建立索引。
-- 添加虚拟列(不占用额外存储,实时计算) alter table visits add column weekday_val tinyint generated always as (weekday(visit_date)) stored; -- 或 virtual -- 为虚拟列创建索引 create index idx_weekday on visits(weekday_val); -- 查询时使用虚拟列 select date(visit_date), count(*) from visits where weekday_val <= 4 group by date(visit_date);
stored:物理存储,占用空间但查询稍快。virtual:不占用空间,每次读取时计算,但索引仍然可用(8.0 前 virtual 列索引有限制,建议用 stored)。
3.4 方案四:预聚合汇总表(终极性能)
如果统计需求固定为“按日统计工作日数据”,可以维护一张日汇总表,通过定时任务或触发器增量更新。
create table visits_daily_summary (
visit_date date primary key,
total_count int default 0,
weekday_count int default 0,
weekend_count int default 0,
updated_at timestamp default current_timestamp on update current_timestamp
);
增量更新逻辑(每日凌晨执行或每笔写入时更新):
insert into visits_daily_summary (visit_date, total_count, weekday_count)
select
date(visit_date),
count(*),
sum(weekday(visit_date) <= 4)
from visits
where visit_date >= curdate() - interval 1 day
and visit_date < curdate()
group by date(visit_date)
on duplicate key update
total_count = total_count + values(total_count),
weekday_count = weekday_count + values(weekday_count);
查询时直接读汇总表,毫秒级响应,且完全避免函数计算。
四、方法选择流程图
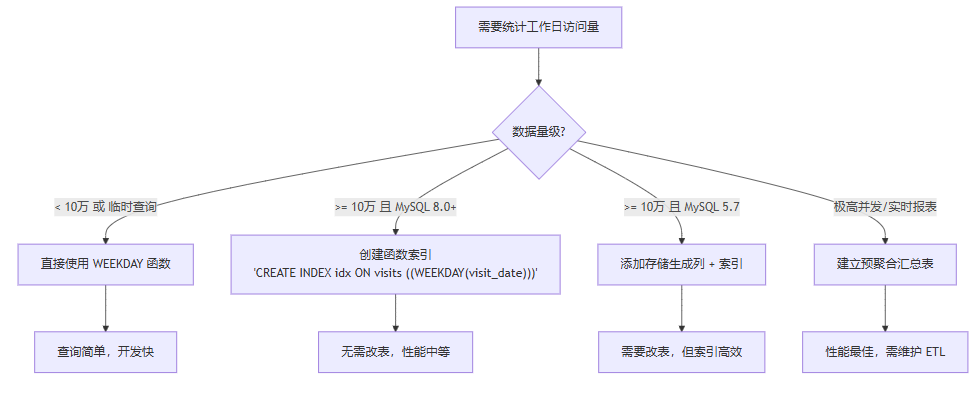
五、常见陷阱与注意事项
时区问题:weekday() 基于会话时区,如果数据时间是 utc,查询时需转换 convert_tz。
跨年周:weekday 只判断星期几,不关心周数。若需按自然周统计(周一到周日),需结合 yearweek()。
null 值:visit_date 应为 not null,否则 weekday(null) 返回 null,条件不成立。
性能误区:即使使用函数索引,where weekday(date) <= 4 and date between ... 仍可能部分走索引。应分析 explain 确认。
六、综合示例:统计某月的工作日日均访问量
-- 查询 2025年5月 工作日的日均访问量(使用虚拟列方案)
select
count(*) / count(distinct date(visit_date)) as avg_weekday_visits
from visits
where visit_date >= '2025-05-01'
and visit_date < '2025-06-01'
and weekday_val <= 4; -- 假设已添加虚拟列并建立索引
七、总结
| 方法 | 适用场景 | 索引利用 | 开发成本 | 维护成本 |
|---|---|---|---|---|
weekday() 直接过滤 | 临时查询、小表 | ❌ 全表扫描 | 低 | 无 |
| 函数索引 (8.0+) | 中等表,不想改结构 | ✅ 高效 | 中 | 低 |
| 虚拟列 + 索引 | 5.7 环境,中等表 | ✅ 高效 | 中 | 低 |
| 预聚合表 | 大表、高频统计 | ✅ 极快 | 高 | 中(需 etl) |
推荐策略:
- 开发测试或低并发场景:直接使用
weekday(),简单可靠。 - 生产环境百万级数据:采用虚拟列 + 索引(兼容性好)。
- 实时大屏或 api 高频调用:使用预聚合表或物化视图。
到此这篇关于mysql实现优雅统计工作日(周一至周五)数据的文章就介绍到这了,更多相关mysql统计工作日数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论