前言
在 mysql 数据库的日常运维与开发中,drop、delete 和 truncate 是三种常用于“清除数据”的 sql 语句。
然而,它们在实现机制、事务行为、性能表现及适用场景上存在根本性差异。
一、语法与基本语义
| 语句 | 语法示例 | 作用对象 | 语义说明 |
|---|---|---|---|
delete | delete from table_name [where ...]; | 表中的行 | 逐行删除满足条件的记录(若无 where,则删除全部行) |
truncate | truncate table table_name; | 整张表 | 快速清空表中所有数据,重置自增计数器(若存在) |
drop | drop table table_name; | 表结构本身 | 删除整张表(包括结构、索引、权限等元数据) |
注意:
truncate和drop是 ddl(data definition language),而delete是 dml(data manipulation language)。
二、核心维度对比
delete、truncate 与 drop:mysql 数据清除操作全对比
| 维度 | delete | truncate | drop |
|---|---|---|---|
| 语句类型 | dml | ddl | ddl |
| 是否可带 where | ✅ 是 | ❌ 否 | ❌ 否 |
| 事务性 | ✅ 可回滚(在事务中) | ❌ 隐式提交,不可回滚 | ❌ 隐式提交,不可回滚 |
| 触发器 | ✅ 触发 delete 触发器 | ❌ 不触发 | ❌ 不触发 |
| 写 redo/undo log | ✅ 写 undo(支持回滚)+ redo | ❌ 不写 undo;部分 redo(元数据) | ❌ 不写 undo;写 redo(元数据) |
| 锁粒度 | 行锁(innodb) | 表级元数据锁(mdl) | 表级元数据锁(mdl) |
| 自增列重置 | ❌ 不重置 | ✅ 重置为初始值(通常为1) | ✅ 表被删除,自然重置 |
| 空间回收 | ❌ 标记删除,空间由 purge 线程异步回收 | ✅ 立即释放表空间(innodb) | ✅ 删除.ibd文件,立即释放磁盘空间 |
| 执行速度 | 慢(逐行处理) | 快(重建表) | 快(删除文件) |
注:在 myisam 引擎中,
truncate行为类似drop + create,但 innodb 自 5.7 起已优化为原地重建(instant truncate)。
delete、truncate 与 drop 对性能的影响对比
| 维度 | delete | truncate | drop |
|---|---|---|---|
| 执行机制 | 逐行扫描、标记删除(逻辑删除),写入 undo log 和 redo log | 删除原表数据文件,重建空表结构(物理清空) | 删除表的元数据及物理文件(.frm/.ibd),彻底移除表 |
| i/o 开销 | 高:每行都要写 undo + redo,大量随机 i/o | 极低:仅元数据操作 + 文件截断/重建,顺序 i/o | 极低:直接删除文件,少量元数据日志写入 |
| 事务日志增长 | 显著:undo log 可能非常大(尤其全表删除) | 几乎无:不生成行级 undo,仅少量 ddl redo | 无 undo;仅写入 ddl 相关 redo(用于崩溃恢复) |
| 锁竞争 | 行锁 + 可能升级为间隙锁,长时间运行易阻塞其他事务 | 短暂表级元数据锁(mdl),通常毫秒级完成 | 短暂表级元数据锁(mdl),持有时间略长于 truncate(因涉及字典操作) |
| 空间回收 | 延迟:由后台 purge 线程异步回收,可能造成“表膨胀” | 立即:.ibd 文件被截断或重建,磁盘空间即时释放 | 立即:.ibd 和 .frm(或数据字典记录)被删除,磁盘空间完全释放 |
| 适用数据量 | 小到中等规模(建议 < 10 万行) | 任意规模(百万/亿级均可高效处理) | 任意规模,但仅适用于不再需要该表的场景 |
| 是否可回滚 | ✅ 是(在事务中) | ❌ 否(隐式提交) | ❌ 否(隐式提交) |
| 对自增列影响 | 不重置(下次插入继续递增) | 重置为初始值(如 1) | 表被删除,自增信息随之消失 |
| 触发器/外键 | 触发 delete 触发器;受外键约束影响 | 不触发触发器;若存在外键引用则失败 | 不触发触发器;自动解除外键依赖(因表已不存在) |
为什么truncate和drop不产生undo log,却会产生redo log
1. 核心结论
drop 和 truncate 虽然不写入“行数据”的 redo log,但会写入“元数据变更”的 redo log,目的是确保:
- 在数据库崩溃后能正确恢复表结构状态(如:表是否还存在);
- 保证 ddl 操作的原子性与持久性(acid 中的 durability)。
这与 delete 写入“行级 redo”有本质区别。
2. redo log 的作用回顾
innodb 的 redo log 主要用于:
- 记录 物理页(page)的变更;
- 在 crash recovery 时重做(replay)这些变更,使数据库回到崩溃前的一致状态;
- 只记录“做了什么”,不记录“如何撤销”(undo log 才负责回滚)。
因此:
- dml(如
delete)修改了数据页 → 必须写 redo; - ddl 修改了数据字典(data dictionary)或文件系统结构 → 也必须写 redo,否则崩溃后无法知道“表是否已被删除”。
3. 为什么drop/truncate不写“行级 redo”?
因为它们不逐行修改数据页**!**
| 操作 | 是否修改数据页内容? | 是否需要行级 redo? |
|---|---|---|
delete | ✅ 是(标记删除位、更新链) | ✅ 需要 |
truncate | ❌ 否(直接释放/重建整个表空间) | ❌ 不需要 |
drop | ❌ 否(删除整个 .ibd 文件) | ❌ 不需要 |
truncate在 innodb 中本质是 “丢弃旧表空间 + 创建新空表空间”;drop是 “从数据字典移除表元数据 + 删除 .ibd 文件”;- 两者都不遍历或修改原有数据行,因此无需记录每行的 redo。
4.那它们写的是什么 redo?
它们写的是 “元数据操作”的 redo log,主要包括:
(1)数据字典(data dictionary)变更
mysql 8.0 将数据字典完全存储在 innodb 表中(如 tables等)。
执行 drop table t 时,innodb 会:
- 在
tables中删除对应记录; - 这个删除操作本身就是一个 dml,会生成 redo log!
所以:虽然用户表的数据没写 redo,但系统表的变更写了 redo。
(2)表空间(tablespace)元信息变更
truncate会分配新的表空间 id 或重置空间头;drop会标记表空间为“可删除”并在 purge 阶段清理;- 这些操作涉及 innodb 系统页(如 fsp_hdr、ibuf_bitmap)的修改,也会产生 redo。
(3)ddl 日志(ddl log table)
mysql 8.0 引入了 原子 ddl 机制,使用一张隐藏的 mysql.innodb_ddl_log 表(临时表)记录 ddl 步骤。
例如 drop table 可能包含:
1. 删除索引 2. 删除表数据字典记录 3. 删除 .ibd 文件
每一步都记录到 innodb_ddl_log,而该表的插入/删除操作同样会写 redo log,确保崩溃后能回放或回滚整个 ddl。
可通过
select * from mysql.innodb_ddl_log;(需 super 权限)查看(通常为空,因操作完成后自动清理)。
5. 崩溃恢复时如何工作?
假设在 drop table t 执行到一半时 mysql 崩溃:
- 重启时,innodb 进行 crash recovery,重放 redo log;
- redo 中包含:
- 对
mysql.tables的删除记录; - 对
innodb_ddl_log的写入;
- 对
- 若 ddl 未完成,innodb 会根据
innodb_ddl_log自动回滚或完成剩余步骤(原子 ddl 保证); - 最终结果:要么表完全存在,要么完全不存在——不会出现“半删除”状态。
6. 对比总结
| 特性 | delete | truncate / drop |
|---|---|---|
| 修改用户数据页? | ✅ 是 | ❌ 否 |
| 写行级 redo? | ✅ 是 | ❌ 否 |
| 修改系统表(数据字典)? | ❌ 否 | ✅ 是 |
| 写元数据 redo? | ❌ 否 | ✅ 是 |
| 支持事务回滚? | ✅ 是(靠 undo) | ❌ 否(但崩溃可恢复一致性) |
| 崩溃后能否保证状态一致? | ✅ 能 | ✅ 能(靠 ddl redo + 原子 ddl) |
总结:
drop 和 truncate 之所以“仅写入 ddl 相关 redo”,是因为它们不修改用户数据行,但必须持久化“表结构是否还存在”这一元数据状态。
这些 redo 记录的是对 innodb 数据字典表 和 表空间元信息 的变更,用于在崩溃恢复时确保 ddl 操作的原子性与持久性,而非用于恢复被删除的数据内容。
这也是为什么:你可以从崩溃中恢复出“表是否被删”的正确状态,但无法恢复被 drop 或 truncate 删除的数据本身——因为数据页从未被 redo 记录过。
三、内部处理流程
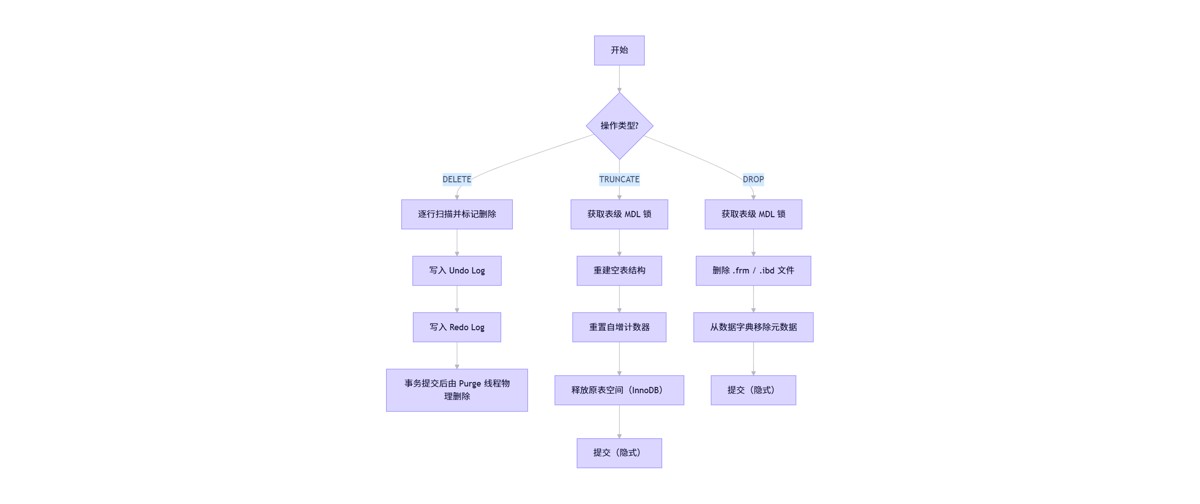
该流程图展示了 innodb 引擎下三种操作的核心路径。注意:
delete是唯一支持回滚的操作。
四、典型使用场景建议
使用 delete:
- 需要按条件删除部分数据;
- 要求操作可回滚(如在事务中);
- 存在
on delete cascade外键依赖; - 需要触发
delete触发器。
使用 truncate:
- 需要快速清空整张大表;
- 不关心事务回滚;
- 希望重置自增 id;
- 表无外键引用(否则会报错)。
使用 drop:
- 表不再需要,需彻底移除;
- 释放磁盘空间是首要目标;
- 重构表结构(常配合
create使用)。
安全提示:生产环境中,建议对
drop和truncate设置sql_safe_updates=1或通过权限控制限制执行。
sql_safe_updates参数解析
sql_safe_updates 是 mysql 中的一个会话级系统变量,主要用于防止执行没有 where 条件的 update 和 delete 语句,以避免意外的大规模数据修改。
主要作用
当 sql_safe_updates 设置为 on(或 1)时:
1. 限制 update 语句
- 必须包含 where 子句
- where 子句中必须使用索引列
- 不能使用
limit子句(某些 mysql 版本)
2. 限制 delete 语句
- 必须包含 where 子句
- where 子句中必须使用索引列
- 不能使用
limit子句
五、优化delete操作的数据清理流程
当必须使用 delete(如按时间范围清理日志表)时,可采用以下策略避免性能灾难:
1.分批删除(chunked deletion)
-- 示例:每次删除 10,000 行,避免长事务和大 undo delete from logs where create_time < '2023-01-01' order by id limit 10000;
在应用层循环执行,直到返回影响行数为 0。配合
sleep(0.1)减少主从延迟。
2.使用主键或索引列排序
确保 order by 使用聚簇索引(如 innodb 的主键),避免全表扫描+临时排序。
3.控制事务大小
单次
delete不要超过innodb_log_file_size的 1/4;可显式提交每个批次:
start transaction; delete ... limit 10000; commit; -- 避免 undo log 过大
4.避免在高峰期执行
选择业务低峰期,并监控 innodb_rows_deleted、innodb_buffer_pool_pages_dirty 等指标。
5.考虑归档替代删除
对历史数据先 insert into archive_table select ...,再 drop 原表分区(若使用分区表),效率更高。
“不要删除旧数据,而是保留新数据并抛弃旧容器” —— 这是处理海量历史数据清理的高性能范式,尤其在分区表场景下,效率远超 delete。
6.调整 purge 线程参数(高级)
innodb_purge_threads = 4 # 默认 4,可增至 8(多核) innodb_max_purge_lag = 100000 # 控制 dml 延迟
六、高频面试题
q1:truncate能回滚吗?
答:不能。truncate 是 ddl 操作,在 mysql 中会隐式提交当前事务,因此无法回滚。
q2:delete不加 where 会锁全表吗?
答:在 innodb 中,delete 仍使用行锁,但会逐行加锁,可能因锁数量过多导致性能下降或锁等待,但并非“表锁”。
q3:为什么truncate比delete快?
答:因为 truncate 不逐行删除,而是直接释放数据页并重建空表,不写 undo log,也无需触发触发器或检查外键。
q4:drop table后还能恢复数据吗?
答:除非有备份或使用了企业级闪回功能(如 percona 的 pt-archiver 或 binlog 回放),否则无法直接恢复。.ibd 文件已被删除。
q5:truncate会重置自增 id 吗?delete呢?
答:truncate 会重置;delete 不会,即使删除所有行,下次插入仍从上次最大 id +1 开始。
总结
到此这篇关于mysql数据清除三剑客之drop、delete与truncate深度对比的文章就介绍到这了,更多相关mysql数据清除drop、delete与truncate内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论