pandas取出重复数据
平常我们用pandas做重复数据处理时,常常调用到drop_duplicates方法来去除重。
现在我不想完全去除重复,而是把重复数据输出,现有数据如下所示:
dic = {'序号':[2,3,4,5,6,7,8,9,10,11,12,13,14,15],'地市缩写': ['lf', 'cz', 'hs', 'zj', 'ts', 'hd', '广阳', 'cd', 'qh', 'xt', 'xa', 'bd', 'sj', '栾城'],
'地市': ['廊坊', '沧州', '衡水', '张家口', '唐山', '邯郸', '廊坊', '承德', '秦皇岛', '邢台', '雄安', '保定',
'石家庄', '石家庄']}
p_city = pd.dataframe(dic)
print(p_city )输出:
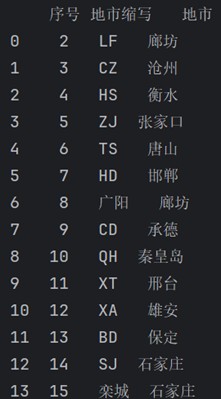
方法一
重复数据保留一个,duplicate_bool输出的是bool类型值,通过判断bool==true,取出重复行。
duplicate_bool = p_city.duplicated(subset=['地市'], keep='first') print(duplicate_bool ) repeat =p_city.loc[duplicate_bool == true] print(repeat)
输出:
方法二
采用drop_duplicates对数据去两次重,一次将重复数据全部去除(keep=false),一次将重复数据保留一个(keep=last/first),将两个去重后的数据做差集,取出重复行。
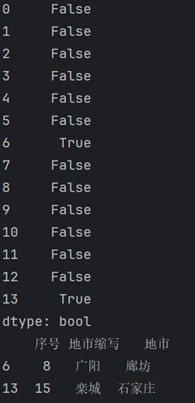
# 重复数据全部去除 data1 = p_city.drop_duplicates(subset=['地市'], keep=false) print(data1)
输出:
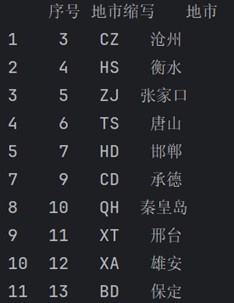
# 重复数据保留一个 data2 = p_city.drop_duplicates(subset=['地市'], keep='last') print(data2)
输出:
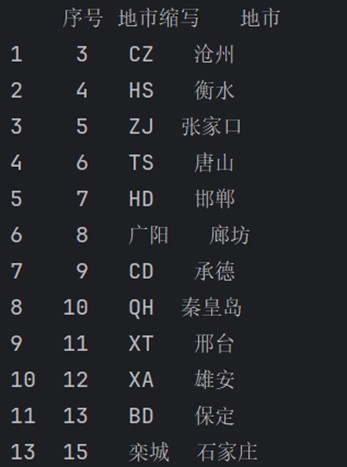
# 做差集,取出重复行 data1 = p_city.drop_duplicates(subset=['地市'], keep=false) data2 = p_city.drop_duplicates(subset=['地市'], keep='last') repeat = pd.concat([data2,data1]).drop_duplicates(keep=false) print(repeat)
输出:

总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论