前言
超链接在 pdf 中被归类为“链接注释”(link annotations)。
根据 pdf 规范,超链接是一种特殊的注释类型,其核心结构包含定义可点击区域的矩形、指定跳转目标的 uri 或页面信息,以及可选的视觉样式。这种设计允许 pdf 阅读器识别并响应用户的点击行为。
本文基于 python 开源库 pdfplumber 来提取 pdf 中的超链接。
pdfplumber 库,专门用于解析 pdf 文档,可提取 pdf 的基本信息(作者、创建时间、修改时间…)及表格、文本、图片、超链接等信息,基本可以满足所有较为简单的内容提取。
pdfplumber 可直接使用 pip 命令进行安装,具体命令如下:
pip install pdfplumber
提取 pdf 中超链接详解
pdfplumber 自带的 .hyperlinks 属性,专门用于获得 pdf 中的所有超链接信息,返回结果为一个字典列表。
如以下代码,使用 pdfplumber 打开 test.pdf 后,采用 .hyperlinks 属性获取每一页的超链接信息。
import pdfplumber
with pdfplumber.open(r'./data/test.pdf') as pdf_info:
for page in pdf_info.pages:
links = page.hyperlinks
print(links)上述代码运行后,返回结果为一个字典列表,内容包含页码、uri(目标地址)等超链接信息。如下图:
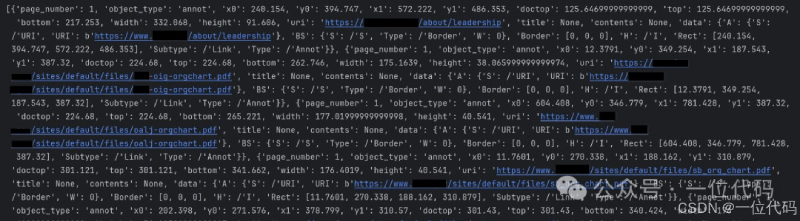
然后根据需要,提取字典列表中的超链接即可。
完整代码如下,直接复制该代码,修改文件路径为自己的 pdf 完整路径,即可获取到 pdf 所有页中所有的超链接。
import pdfplumber
def get_links(file_path):
res_links = []
with pdfplumber.open(file_path) as pdf_info:
page_number = 0
for page in pdf_info.pages:
page_number += 1
links = page.hyperlinks
if links:
for link in links:
res_link = link.get('uri')
res_links.append(res_link)
print(f'第{page_number}页,共有{len(links)}个超链接!')
else:
print(f'第{page_number}页,不存在超链接!')
return res_links
if __name__=="__main__":
# 文件路径为 pdf 完整路径
res_links = get_links('data/fcc_all.pdf')
print(res_links)以上仅为 pdf 中超链接提取的一种方法,可供参考。
方法补充
基本用法:提取所有超链接
核心代码很简单:打开 pdf,遍历每一页,然后从页面的 hyperlinks 属性中提取 uri(目标网址)。
import pdfplumber
def extract_links(pdf_path):
all_links = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
page_links = page.hyperlinks
if page_links:
for link in page_links:
# 每个 link 是一个字典,'uri' 键存储了目标网址
uri = link.get('uri')
if uri:
all_links.append(uri)
return all_links
if __name__ == "__main__":
links = extract_links("你的文件.pdf")
for link in links:
print(link)你也可以在遍历时加上页码,方便记录:
for i, page in enumerate(pdf.pages):
links = page.hyperlinks
if links:
print(f"第 {i+1} 页 有 {len(links)} 个链接")
for link in links:
print(f" - {link.get('uri')}")
else:
print(f"第 {i+1} 页 没有链接")高级用法:灵活处理
处理其他类型的链接
除了 uri(网页链接),hyperlinks 可能还包含内部链接(指向 pdf 内其他页面,键为 page)或文档级链接(键为 nameddest)。
if 'uri' in link:
print(f"网页链接: {link['uri']}")
elif 'page' in link:
print(f"内部链接: 第 {link['page']} 页")
elif 'nameddest' in link:
print(f"命名目标: {link['nameddest']}")提取链接的链接文本(高级技巧)
有时你需要知道链接所关联的文本(例如“点击这里”)。pdfplumber 本身不直接提供这个功能,但可以结合 chars 属性(包含每个字符的详细信息,如位置坐标)来间接获取。基本思路是获取链接的矩形区域(x0, y0, x1, y1),然后筛选出落在这个区域内的字符并组合成文本。这需要一定的坐标计算,但能更精确地处理复杂文档。
处理加密pdf
pdfplumber.open() 方法支持通过 password 参数打开加密的 pdf 文件。
with pdfplumber.open("encrypted.pdf", password="你的密码") as pdf:
# ... 正常提取链接常见问题与注意事项
- 链接提取不到:
pdfplumber提取的是 pdf 中的 “链接注释” (link annotations)。如果你需要提取的是文本内容中直接以 url 形式出现的字符串,直接使用文本搜索或正则表达式会更合适。 croppedpage相关bug:如果你对页面进行了裁剪操作,可能会遇到与croppedpage相关的超链接提取 bug。如果遇到此类问题,可以尝试更新pdfplumber到最新版本,或直接在原始page对象上提取链接。- 扫描版pdf:
pdfplumber主要用于处理由计算机生成的 pdf(machine-generated pdfs)。如果 pdf 是扫描件(图片形式),它无法直接提取其中的超链接或文本。你需要先用 ocr 技术(如pytesseract)进行识别。
到此这篇关于python使用pdfplumber库一键提取pdf中的所有超链接的文章就介绍到这了,更多相关python提取pdf超链接内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论