确认负载高的问题类型
查看当前负载:
uptime # 显示1/5/15分钟负载平均值 top # 查看实时负载(load average行)及cpu使用率
负载值的合理范围:建议5分钟负载 ≤ cpu逻辑核心数。若持续高于核心数,需深入排查。
检查cpu使用情况
查看cpu整体使用率:
top # 按`1`显示多核cpu详情,观察us(用户态)、sy(内核态)、wa(i/o等待)等指标 vmstat 1 # 查看上下文切换(cs)、中断(in)等
高us:用户进程占用高,需排查具体进程。
高sy:内核态占用高,可能是系统调用频繁或中断异常。
高wa:i/o等待高,可能磁盘或网络瓶颈(需结合i/o排查)。
定位高cpu进程:
top中按p(按cpu排序)或m(按内存排序)。- 记录占用最高的pid(进程id)。
分析进程内线程:
top -hp [pid] # 查看指定进程的线程cpu占用 printf "%x\n" [tid] # 将线程id转为16进制(用于后续分析)
深入分析代码热点:
perf top -p [pid] # 查看进程的函数级cpu消耗(需安装perf) strace -p [pid] # 跟踪系统调用(排查频繁调用)
检查i/o瓶颈
查看磁盘i/o负载:
iostat -x 1 # 观察%util(设备利用率)、await(i/o等待时间) iotop # 按进程查看磁盘i/o使用
高%util:磁盘繁忙,可能频繁读写或硬件性能不足。
高await:i/o响应慢,可能磁盘故障或配置问题。
检查文件系统状态:
df -h # 查看磁盘空间是否耗尽 dmesg | grep -i error# 检查磁盘错误日志
内存与swap分析
查看内存使用:
free -h # 查看物理内存和swap使用 top # 按`m`排序内存占用进程
- swap频繁使用:物理内存不足,需优化内存或扩容。
- oom killer触发:检查
dmesg是否有oom日志。
排查僵尸进程和异常进程
检查僵尸进程:
ps -a -ostat,ppid,pid,cmd | grep -e '^[zz]' # 列出僵尸进程
僵尸进程需终止其父进程(通过kill -9 [ppid])。
检查异常进程:
ps aux | grep [可疑进程名] lsof -p [pid] # 查看进程打开的文件和网络连接
网络瓶颈排查
查看网络流量:
sar -n dev 1 # 实时监控网络接口流量 netstat -antp # 查看tcp连接状态
其他工具
sar(历史数据分析):
sar -q # 查看历史负载趋势 sar -u # 查看历史cpu使用率
系统日志:
journalctl -f # 实时查看系统日志 cat /var/log/messages | grep -i error
查看磁盘状态
通过命令查看磁盘io较高
iostat -xd 2
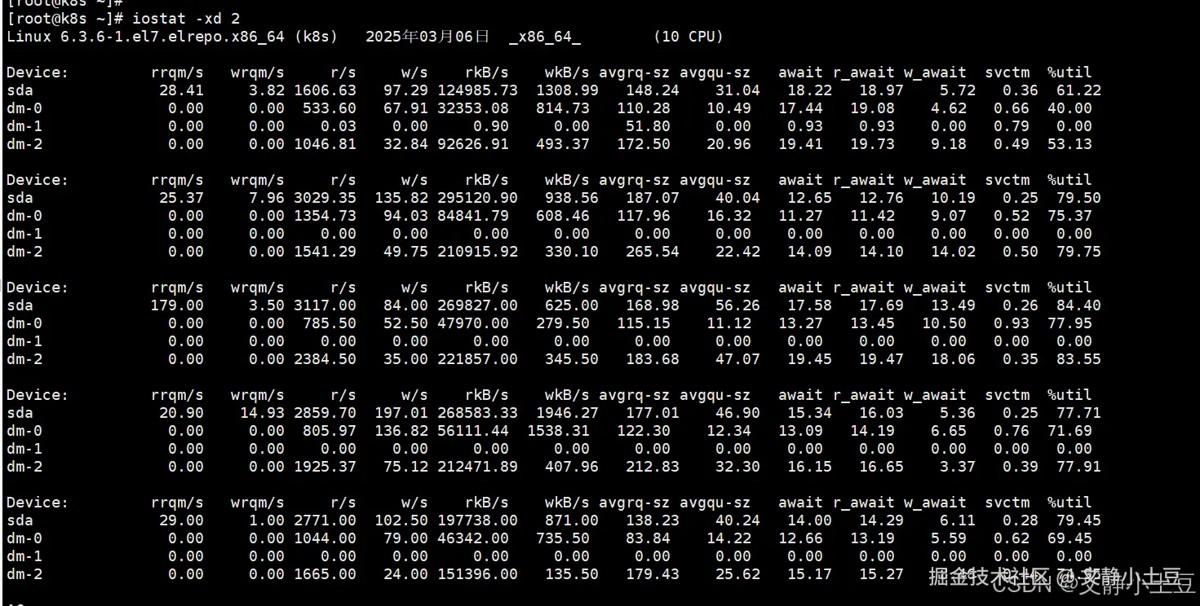
高i/o负载设备
sda 磁盘:
- %util:首次采样达 63.03%,后续波动在 12.45%~29.80%,但最后一次采样中
dm-0的 %util 达 100%(参考输出第二组数据)。 - 读写吞吐:首次采样 rkb/s=126,551.57(约 123.6 mb/s),说明大量读操作。
- 队列积压:
avgqu-sz首次采样为 31.26(高队列积压),await首次达 18ms(i/o延迟较高)。
逻辑卷 dm-0/dm-2:
- dm-0:首次采样 rkb/s=32,555.22(约 31.8 mb/s),
%util=40.64%。 - dm-2:首次采样 rkb/s=93,990.45(约 91.8 mb/s),
%util=54.94%,读写请求密集。
问题定位
- i/o瓶颈:
%util多次超过 70%(如dm-0达 100%),表明磁盘已饱和,请求排队严重。 - 高读操作:
rkb/s和r/s显著偏高,可能是频繁读取大文件或数据库全表扫描导致。
排查步骤
定位高i/o进程
使用 iotop 或 pidstat 直接查看实时i/o占用:
iotop -o # 显示活跃i/o进程 pidstat -d 1 # 按进程统计i/o
重点观察 disk read 和 disk write 列,定位占用高的进程。
检查文件系统和磁盘空间
df -h # 确认磁盘空间是否耗尽 dmesg | grep -i error # 检查磁盘错误日志
若磁盘空间不足或存在坏道,会导致i/o性能骤降。
分析文件访问模式
大文件读写:若进程频繁读写大文件(如日志、数据库文件),需优化文件切分或归档策略。
小文件频繁操作:大量小文件读写(如web静态资源)需考虑合并或使用缓存(如redis)。
磁盘健康:使用 smartctl 检测磁盘健康:
smartctl -a /dev/sda
直接原因:sda/dm-0/dm-2 的i/o饱和,大量读请求导致队列积压和延迟。
查看cpu使用情况
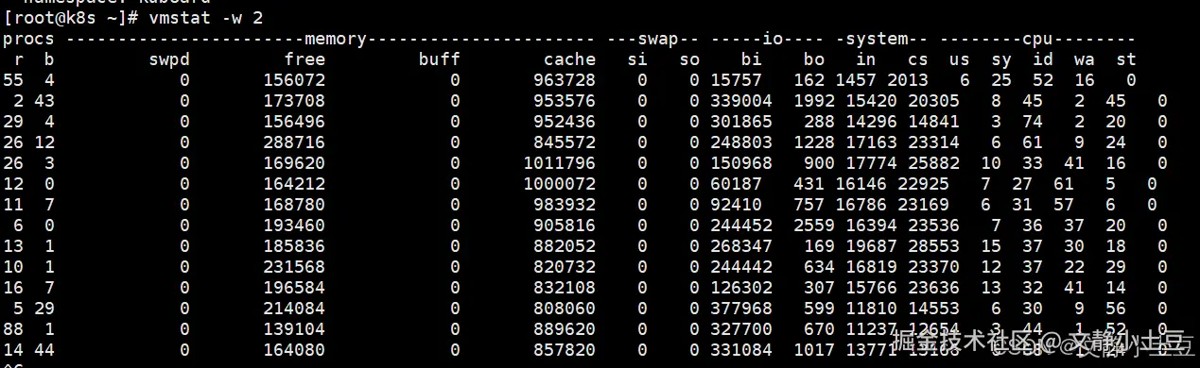
关键指标分析
cpu负载:
- 运行队列(
r列):多次超过 50(如r=88),远超cpu核心数(10核),说明进程排队严重。 - 等待i/o的进程(
b列):最高达 44,表明大量进程因i/o阻塞。 - cpu时间分配:
- 用户态(
us):较低(3%~15%),排除用户进程直接占用cpu的可能。 - 系统态(
sy):多次超过 70%(如sy=74%),内核处理i/o或锁竞争导致。 - i/o等待(
wa):最高达 56%,确认磁盘是瓶颈。
- 用户态(
i/o活动:
- 块设备读(
bi):最高达 377,968 块/秒(约 147.5 mb/s),远超机械盘吞吐能力。 - 上下文切换(
cs):高达 28,553次/秒,频繁进程切换加剧cpu压力。
内存:
- 空闲内存(
free):波动大(最低 139 mb),但cache较高(约 800 mb~1 gb),系统利用缓存缓解i/o压力。 - 无swap使用(
si/so=0):内存未耗尽,但缓存频繁刷写可能影响性能。
排查步骤
定位高i/o进程
iotop -o -p # 查看实时i/o读写进程 pidstat -d 1 # 按进程统计i/o
示例关注:
- disk read 列高(如 mysql、日志服务)。
- 进程状态:若多为
d(不可中断睡眠),表明等待磁盘i/o。
检查磁盘健康
smartctl -a /dev/sda # 检查磁盘smart状态 dmesg | grep -i error # 查看磁盘错误日志
若发现坏道或高延迟,需更换磁盘。
分析文件访问
lsof -p <pid> # 查看进程打开的文件 strace -p <pid> -e trace=file # 跟踪文件操作
确认是否为 大文件顺序读 或 小文件随机读,优化访问模式。
检查内存缓存
free -m # 查看缓存和缓冲区使用 sar -r 1 # 监控内存压力
若 cache 频繁释放,表明内存不足,需优化应用内存或扩容。
检查内存使用情况
根据提供的 free -h 输出系统存在 内存耗尽风险(总内存 15g,已用 14g,可用仅 600mb),但未触发 swap(swap=0),以下是详细分析和解决方案:

关键指标分析
内存分布:
- 已用内存(
used):14g,占比 93%,接近物理内存上限。 - 可用内存(
available):600mb,表明系统处于内存紧张状态,可能触发 oom killer。 - 缓存/缓冲区(
buff/cache):911mb,较低,说明系统未有效利用缓存缓解i/o压力。
潜在风险:
- oom killer:若突发内存需求,内核会强制终止进程释放内存(参考
/var/log/messages中的out of memory日志)。 - 性能下降:频繁内存回收导致cpu占用升高(如
kswapd进程活跃)。
定位高内存进程
top -o %mem # 按内存占用排序 ps aux --sort=-%mem | head -n 10 # 列出前10内存消耗进程
重点关注:
- %mem 列:持续高占比的进程(如 mysql、java 应用)。
- 进程状态:若为
d(不可中断睡眠)或z(僵尸进程),可能关联资源泄漏。
检查内存泄漏
valgrind --leak-check=full -v [应用程序路径] # 检测特定程序内存泄漏 cat /proc/[pid]/status | grep vmrss # 监控进程内存增长趋势
若进程内存持续增长且无释放,需重启服务或修复代码。
优化建议
系统层调优
i/o调度器:改为 deadline 或 noop(ssd适用):
echo deadline > /sys/block/sda/queue/scheduler
内核参数:增大磁盘队列深度:
echo 1024 > /sys/block/sda/queue/nr_requests
负载高的原因
- i/o密集型负载:大量读操作(
bi高)导致磁盘饱和,进程因等待i/o堆积(b列高),引发高负载和系统态cpu占用。 - 可能的场景:数据库全表扫描、日志文件未轮转、文件系统元数据操作频繁(如小文件读写)。
- 磁盘i/o饱和(高
bi、wa)导致进程排队(高b)和系统态cpu占用(高sy)。 - 物理内存耗尽(15g 中已用 14g),主要嫌疑为 mysql 配置不当或 应用内存泄漏。
到此这篇关于centos7负载异常过高的排查思路与解决方法(load average)的文章就介绍到这了,更多相关centos7负载异常过高排查与解决内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论