在oracle数据库运维过程中,undo空间爆满是高频且棘手的问题——一旦发生,会直接导致事务无法提交、数据库报错(如ora-01555、ora-30036)、业务卡顿甚至中断,给运维和业务带来不小麻烦。很多dba习惯用在线切换undo表空间的方式解决,但其实不同场景下有更高效、更安全的方案。本文将从基础认知、问题诊断、核心解决方案(含参考内容优化)、更优替代方案、避坑指南及长期预防,全方位搞定undo空间爆满问题,新手也能直接上手实操。
一、先搞懂:undo空间是什么?为什么会爆满?
1. undo空间核心作用
undo空间(回滚表空间)是oracle数据库的核心组件,主要用于:① 事务回滚(执行rollback时,通过undo数据恢复数据原貌);② 一致性读(多用户并发时,让查询看到事务提交前的一致性数据,避免脏读);③ 闪回查询(通过undo数据恢复误操作前的数据)。
2. 爆满的3大核心原因(高频场景)
- 长事务/未提交事务:这是最常见原因!比如批量更新、全表删除等操作未及时提交,会持续占用undo空间,甚至导致空间被耗尽,尤其高并发场景下风险更高。
- undo参数配置不合理:
undo_retention(undo数据保留时间)设置过长,导致过期undo数据无法被回收;或undo表空间初始配置过小、未开启自动扩展,无法满足事务需求。 - 异常事务/业务逻辑问题:比如循环中反复执行dml操作却不提交、超大范围更新未拆分,或事务中混入耗时的非核心操作(如发消息、调接口),导致undo数据持续累积。
3. 爆满的典型报错(快速识别)
当出现以下报错时,基本可以判定为undo空间爆满或相关异常,需优先排查undo表空间:
- ora-01555: snapshot too old(快照过旧,多因undo数据被提前覆盖或空间不足)
- ora-30036: unable to extend segment in undo tablespace(无法扩展undo段,空间已耗尽)
- ora-30013: undo tablespace 'xxx' is currently in use(删除undo表空间时常见,提示表空间仍被占用)
二、基础排查:先确认undo空间爆满情况
在动手解决前,需先通过sql查询,明确undo表空间的使用率、占用会话、异常事务,避免盲目操作。以下是3个核心排查sql,直接复制执行即可。
1. 查询所有表空间使用情况(重点看undo表空间)
select tablespace_name,
round(used_space*
(select value
from v$parameter
where name='db_block_size')/power(2,30),2) used_gb, -- 已使用空间(gb) round(tablespace_size*
(select value
from v$parameter
where name='db_block_size')/power(2,30)) maxsize_gb, -- 最大可用空间(gb) round(used_percent,2) as usage -- 使用率(%)
from dba_tablespace_usage_metrics
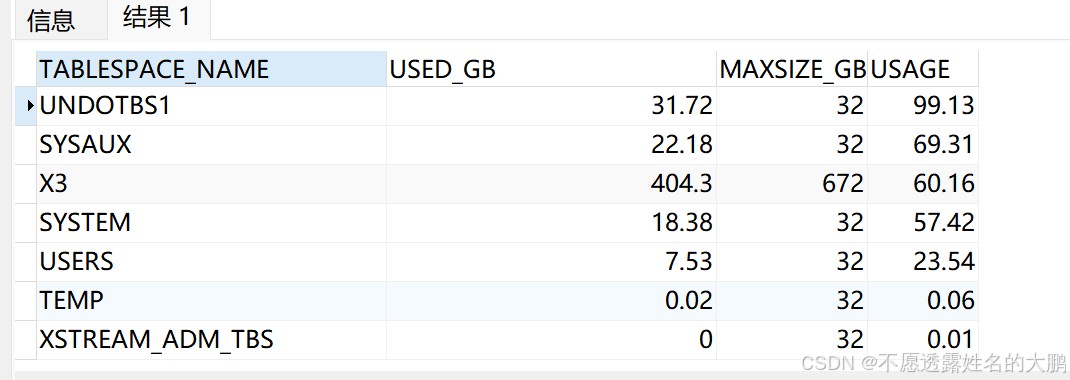
order by usage desc;【说明】:执行后,重点关注tablespace_name为undotbs1(默认undo表空间)的usage字段,若使用率超过90%,需及时处理;若达到100%,则已完全爆满。
2. 排查占用undo空间的未提交事务
-- 方法1:查询关联undo表空间的未释放会话select s.sid,
s.serial#,
s.username,
s.program,
s.machine,
t.start_time,
t.status,
t.xidusn
from v$session s, v$transaction t
where s.saddr = t.ses_addr
and t.xidusn in
(select segment_id
from dba_rollback_segs
where tablespace_name = 'undotbs1'); -- 替换为爆满的undo表空间名 -- 方法2:查询超过1小时未释放的活跃事务(精准定位长事务)select s.sid,
s.serial#,
s.username,
s.sql_id,
q.sql_text,
s.last_call_et/3600 as hours_in_exec
from v$session s, v$sql q
where s.sql_id = q.sql_id
and s.status = 'active'
and s.last_call_et > 3600; -- 单位:秒,3600即1小时【说明】:通过上述sql,可找到占用undo空间的会话id(sid)、序列号(serial#)、操作的sql语句,判断是否为长事务或异常事务,为后续处理提供依据。
3. 查看undo回滚段状态
select *
from dba_rollback_segs t
where t.status='online'
and t.tablespace_name='undotbs1'; -- 替换为目标undo表空间名【说明】:若查询结果为空,说明该undo表空间已无在线回滚段,可安全处理;若有结果,说明仍有事务占用,需先释放。
三、核心方案:在线切换undo表空间(参考内容优化版)
在线切换undo表空间是最常用、最安全的解决方案(无需停机,不影响业务正常运行),适用于undo表空间已爆满、无法快速释放空间的场景。以下是优化后的完整步骤,补充了注意事项和异常处理,比参考内容更具实操性。
步骤1:创建新的undo表空间
create undo tablespace undotbs2
on next 100m -- 数据文件路径,需确保路径存在且有写入权限 size 1024m
-- 初始大小(1gb),可根据实际需求调整 autoextend
-- 新undo表空间名,建议遵循undotbs+数字的命名规范 datafile '/data/oracle/oradata/orcl/undotbs2.dbf'
-- 自动扩展,每次扩展100m maxsize unlimited; -- 最大大小无限制,避免再次爆满【注意】:数据文件路径需根据自身oracle环境调整(可通过select name from v$datafile;查询现有数据文件路径),避免路径错误导致创建失败。
步骤2:切换undo表空间(核心操作)
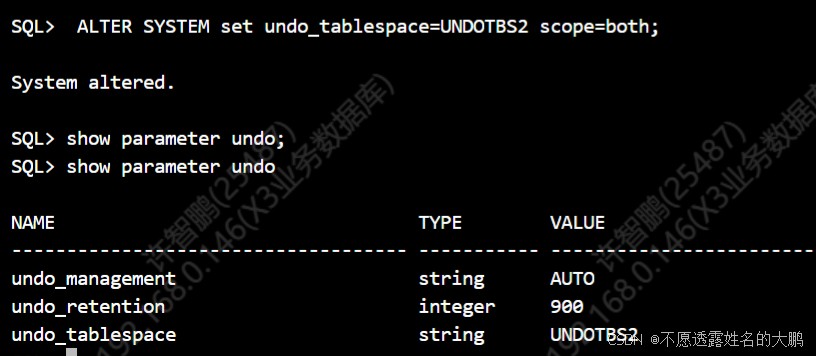
alter system set undo_tablespace=undotbs2 scope=both;
【说明】:scope=both表示修改同时生效于内存和参数文件,无需重启数据库;若仅写scope=memory,数据库重启后会恢复为原undo表空间。
步骤3:验证切换是否成功
-- 方法1:查看当前undo表空间配置 show parameter undo; -- 方法2:查看新undo表空间的回滚段状态(应显示多个online状态) select * from dba_rollback_segs t where t.status='online' and t.tablespace_name='undotbs2';
【验证标准】:方法1执行后,undo_tablespace的值应为undotbs2;方法2执行后,应显示多个状态为online的回滚段,说明切换成功。
步骤4:释放旧undo表空间(undotbs1)
切换成功后,旧undo表空间(undotbs1)仍占用磁盘空间,需手动释放,核心是先确保无事务占用,再删除表空间。
-- 1. 再次确认旧undo表空间无在线回滚段(关键步骤,避免删除失败)select *
from dba_rollback_segs t
where t.status='online'
and t.tablespace_name='undotbs1'; -- 2. 若仍有未释放的回滚段,手动离线(替换为实际回滚段名) alter rollback segment "_syssmu3_1723003836$" offline; alter rollback segment "_syssmu4_1254879796$" offline; -- 3. 确认无事务占用旧undo表空间(无结果即为无占用)select s.sid,
s.serial#,
s.username
from v$session s, v$transaction t
where s.saddr = t.ses_addr
and t.xidusn in
(select segment_id
from dba_rollback_segs
where tablespace_name = 'undotbs1'); -- 4. 删除旧undo表空间(彻底释放磁盘空间) drop tablespace undotbs1 including contents
and datafiles;【警告】:删除表空间前,务必确认无事务占用,否则会报ora-30013错误;若报错,可参考本文“避坑指南”中的解决方案处理。
步骤5:可选(优化新undo表空间配置)
-- 调整undo数据保留时间(根据业务需求,默认900秒,可适当缩短减少空间占用) -- 查看调整后的保留时间 show parameter undo_retention; alter system set undo_retention=900 scope=both;
四、更优解决方案(分场景选择,比切换更高效)
在线切换undo表空间虽安全,但并非所有场景都最优。以下3种方案,根据实际场景选择,可快速解决问题,减少操作成本。
方案1:紧急扩容(适用于临时爆满,无需切换表空间)
若undo空间只是临时爆满,且无长时间未提交事务,可直接扩容undo表空间,比切换更快捷,适合业务高峰期紧急处理。
-- 方法1:新增数据文件扩容(推荐,不影响现有数据)
alter tablespace undotbs1 add datafile '/data/oracle/oradata/orcl/undotbs1_02.dbf' size 1024m autoextend
on next 100m maxsize unlimited;
-- 方法2:扩大现有数据文件大小(若数据文件未达最大限制)
alter database datafile '/data/oracle/oradata/orcl/undotbs1.dbf' resize 2048m; -- 扩大到2gb【优势】:操作简单、耗时短,无需切换表空间,适合紧急缓解空间压力;【适用场景】:临时突发爆满、undo表空间配置过小、无长事务占用。
方案2:终止长事务/异常事务(适用于长事务导致的爆满)
若排查发现,undo空间爆满是由少数长事务(如持续几小时的批量操作)导致,可直接终止事务,快速释放空间,无需扩容或切换。
-- 1. 先查询长事务对应的sid和serial#(参考前文排查sql)select s.sid,
s.serial#,
s.username,
q.sql_text,
s.last_call_et/3600 as hours_in_exec
from v$session s, v$sql q
where s.sql_id = q.sql_id
and s.status = 'active'
and s.last_call_et > 3600; -- 2. 终止事务(替换为查询到的sid和serial#,需谨慎操作) alter system kill session '24,111'; -- 格式:'sid,serial#'【注意事项】:① 终止会话前,需确认该事务并非核心业务事务(如订单支付、数据同步),避免导致业务数据不一致;② 终止后,事务会自动回滚,回滚时间取决于事务大小,回滚期间不要强制重启数据库;③ 执行kill操作需具备alter system权限或dba角色。
【优势】:从根源释放空间,无需额外占用磁盘,操作成本最低;【适用场景】:长事务、异常未提交事务导致的爆满,且事务可终止。
方案3:优化业务逻辑(长期根治,避免重复爆满)
若undo空间频繁爆满,说明核心问题在业务逻辑,需从源头优化,彻底解决问题,这是最推荐的长期方案。
- 拆分长事务:将超大批量操作(如全表更新、删除)拆分为小事务,每处理1000-5000行就执行一次commit,减少undo数据累积。
- 优化sql操作:用
bulk collect + forall替代逐行fetch+update,减少上下文切换和undo生成频次;报表导出等非核心操作,改用临时表(create global temporary table),避免占用undo空间。 - 异步化非核心操作:将事务中的发消息、写日志、调用外部接口等非核心动作,移出主事务,用dbms_scheduler或队列表后续处理,缩短事务周期。
- 合理设置
undo_retention:根据业务需求调整保留时间,参考v$undostat中的maxquerylen(最长查询时间),避免设置过长导致undo数据无法回收。
五、避坑指南(实操必看,避免踩雷)
坑1:kill会话后,undo空间仍未释放
【原因】:kill会话后,事务会进入回滚状态,回滚完成后空间才会释放;若事务过大,回滚可能需要几分钟甚至几小时。
【解决】:耐心等待回滚完成,可通过select * from v$transaction;查看回滚进度;若长时间未完成,可重启数据库(非紧急不推荐,会中断所有业务)。
坑2:删除旧undo表空间时报错(ora-30013)
【原因】:旧undo表空间仍有回滚段处于online状态,或有事务正在使用该表空间。
【解决】:① 先执行select segment_name,tablespace_name,status from dba_rollback_segs where tablespace_name='undotbs1';,找到所有online状态的回滚段;② 手动将其离线(alter rollback segment "回滚段名" offline;);③ 若仍报错,可修改pfile文件,添加隐含参数后重启数据库,再删除表空间(具体步骤参考)。
坑3:切换undo表空间后,数据库重启又恢复原状
【原因】:切换时未指定scope=both,仅修改了内存中的配置,未同步到参数文件(spfile)。
【解决】:重新执行alter system set undo_tablespace=undotbs2 scope=both;,确保参数同步到内存和参数文件;若仍有问题,可手动修改spfile文件。
坑4:盲目调整undo_retention参数,导致闪回查询失败
【原因】:将undo_retention设置过短,导致undo数据被提前覆盖,影响闪回查询、数据恢复功能。
【解决】:调整前先查询select max(maxquerylen) from v$undostat;,将undo_retention设置为不小于最长查询时间的值,兼顾空间释放和业务需求。
六、rac环境专属解决方案(补充)
rac(real application clusters)环境与单实例oracle的核心区别的是:每个节点有独立的undo表空间(默认配置),节点间undo资源相互独立,无法跨节点共享。因此rac环境undo爆满多为“单节点爆满”,少数情况下多节点同时爆满,处理需兼顾节点独立性和集群一致性,避免影响集群正常运行。
1. rac环境undo爆满核心特点(与单实例区别)
- 每个rac节点对应专属undo表空间(如节点1对应undotbs1,节点2对应undotbs2),单个节点undo爆满不影响其他节点,但会导致该节点上的事务无法执行。
- 集群层面无统一undo管理,需针对每个节点单独排查、处理,不可跨节点操作其他节点的undo表空间。
- 常见额外原因:节点负载不均衡(某节点承担大量批量事务)、集群服务异常导致undo回滚段无法正常回收、跨节点事务未及时提交(虽不共享undo,但会导致对应节点undo持续占用)。
2. rac环境专属排查步骤(精准定位爆满节点)
先定位哪个节点的undo表空间爆满,再针对性处理,核心排查sql如下(可在任意节点执行,查看所有节点状态):
-- 1. 查看所有节点的undo表空间使用情况(关键:区分节点)select inst_id,
-- 节点id(rac核心标识) tablespace_name,
round(used_space*
(select value
from v$parameter
where name='db_block_size')/power(2,30),2) used_gb, round(tablespace_size*
(select value
from v$parameter
where name='db_block_size')/power(2,30)) maxsize_gb, round(used_percent,2) as usage
from gv$tablespace_usage_metrics -- gv$视图:查询所有rac节点信息
where tablespace_name like 'undotbs%' -- 过滤undo表空间
order by inst_id,
usage desc; -- 2. 排查指定节点(如节点1)占用undo的未提交事务select s.inst_id,
s.sid,
s.serial#,
s.username,
s.program,
t.start_time,
t.status
from gv$session s, gv$transaction t
where s.saddr = t.ses_addr
and s.inst_id = 1 -- 替换为爆满的节点id
and t.xidusn in
(select segment_id
from dba_rollback_segs
where tablespace_name = 'undotbs1'); -- 对应节点的undo表空间 -- 3. 查看各节点undo回滚段状态select inst_id,
segment_name,
tablespace_name,
status
from gv$rollback_segs
where tablespace_name like 'undotbs%';【说明】:通过上述sql,可快速定位“哪个节点、哪个undo表空间、哪个事务”导致的爆满,为后续处理提供精准依据。
3. rac环境分场景解决方案(实操可直接复制)
场景1:单节点undo爆满(最常见)
处理原则:仅操作爆满节点的undo表空间,不影响其他节点,步骤与单实例类似,但需指定节点操作。
create undo tablespace undotbs1_new datafile '/data/oracle/oradata/rac/undotbs1_new.dbf' size 2048m autoextend
on next 200m maxsize unlimited; -- 1. 切换到爆满节点(如节点1),创建新undo表空间(仅在该节点生效)-- 路径需对应节点1的数据文件路径
-- 2. 切换该节点的undo表空间(仅影响当前节点) alter system set undo_tablespace=undotbs1_new scope=both;后续验证切换、释放旧undo表空间的步骤,与单实例一致(参考第三章),但需确保所有操作均在爆满节点执行,不可跨节点删除其他节点的undo表空间。
场景2:多节点同时undo爆满
处理原则:逐个节点处理,优先处理核心业务所在节点,避免同时操作多个节点导致集群不稳定。
- 步骤1:通过排查sql,分别记录每个爆满节点的undo表空间名称(如节点1:undotbs1,节点2:undotbs2)。
- 步骤2:逐个节点执行“创建新undo表空间→切换→释放旧表空间”操作(参考场景1),不可批量执行跨节点操作。
- 步骤3:处理完成后,检查集群状态(
crsctl status cluster),确保所有节点undo表空间切换成功,无异常报错。
场景3:跨节点事务导致的undo持续占用
若排查发现,某节点undo爆满是由跨节点事务(如节点1发起、节点2执行的批量操作)导致,需先终止跨节点事务,再释放空间。
-- 1. 查询跨节点事务对应的节点、sid、serial#
select s.inst_id, s.sid, s.serial#, s.username, q.sql_text
from gv$session s, gv$sql q
where s.sql_id = q.sql_id and s.status = 'active'
and s.last_call_et > 3600 -- 超过1小时的长事务 and s.program like '%oracle@%'; -- 跨节点事务特征 -- 2. 终止跨节点事务(需在事务所在节点执行,替换对应inst_id、sid、serial#)
alter system kill session '100,200,1'; -- 格式:'sid,serial#,inst_id'4. rac环境专属避坑点
- 坑5:跨节点删除undo表空间(rac特有):误在节点1删除节点2的undo表空间,会导致节点2崩溃,需严格区分节点id和undo表空间的对应关系。
- 坑6:切换undo表空间未指定节点:在rac环境执行
alter system set undo_tablespace时,若未指定节点,仅会修改当前执行节点的配置,其他节点不受影响,需逐个节点切换或使用集群命令同步。 - 坑7:忽略集群服务状态:处理undo爆满前,需先检查集群服务(
crsctl status resource -t),若集群服务异常,需先恢复集群,再处理undo问题,避免操作失败。
七、长期预防:避免undo空间爆满再次发生
解决问题不如预防问题,做好以下3点,可大幅降低undo空间爆满的概率,减少运维成本。
- 定期监控undo空间:创建定时任务,每周查询undo表空间使用率,当使用率超过80%时,及时预警,提前处理(如扩容、优化事务)。
- 合理配置undo表空间:新建数据库时,根据业务量配置足够大的undo表空间(建议初始大小不小于2gb),开启自动扩展,避免初始配置过小。
- 定期优化业务和sql:排查系统中的长事务、慢sql,优化业务逻辑,避免批量操作未拆分、事务未及时提交等问题,从根源减少undo空间占用。
【rac环境额外预防】:① 均衡节点负载,避免单个节点承担过多批量事务;② 定期检查各节点undo表空间配置,确保所有节点undo初始大小、自动扩展参数一致;③ 监控跨节点长事务,建立预警机制(如超过30分钟未提交则预警)。
八、总结
oracle undo空间爆满的核心解决思路是:先排查(确认爆满原因、占用事务),再处理(根据场景选择切换、扩容、终止事务),最后预防(优化配置、业务逻辑)。
在线切换undo表空间是通用且安全的方案,适合大多数场景;紧急扩容适合临时爆满;终止长事务适合针对性解决;优化业务逻辑是长期根治的关键。实操时,务必注意备份数据、确认事务安全性,避免因操作失误导致业务中断。
rac环境需重点关注“节点独立性”,排查和处理均需区分节点,避免跨节点误操作;多节点爆满需逐个处理,兼顾集群稳定性。
以上就是oracle undo空间爆满的急救指南的详细内容,更多关于oracle undo空间爆满的资料请关注代码网其它相关文章!




发表评论