前言
在日常办公和数据处理中,pdf文件几乎无处不在。合同、报告、论文、发票……每天都有大量pdf文档需要处理。当我们需要从中提取文字信息时,手动复制粘贴不仅效率低下,而且容易出错。
python的pypdf2库,正是解决这一痛点的利器。它轻量、纯python实现、无需安装额外依赖,是初学者入门pdf自动化处理的最佳选择。
本文将带你从零开始,用pypdf2快速提取pdf文本,涵盖安装配置、核心操作、元数据获取、中文乱码避坑等全流程。全程附代码和图示,确保你读完就能上手写代码。
一、pypdf2 是什么?适用场景与核心优缺点
1.1 适用场景
pypdf2是一个纯python的pdf处理库,能够在不借助任何外部软件的情况下,对pdf文件进行各种操作[reference:0]。它在以下场景中表现出色:
- 批量提取pdf文本:从成百上千份报告中提取关键词、摘要或全文
- 合并/拆分pdf:将多个pdf合并为一个文档,或将大型pdf按页拆分
- 读取pdf元信息:获取文档的作者、标题、创建时间等信息
- 加密/解密pdf:为敏感文档添加密码保护
- 页面旋转、裁剪、添加水印等基础页面操作
1.2 核心优缺点
| 维度 | 评价 | 说明 |
|---|---|---|
| 优点 | 轻量易上手 | 纯python实现,一行pip安装,api简洁直观 |
| 优点 | 零外部依赖 | 无需安装adobe acrobat或其他pdf软件 |
| 优点 | 基础功能全覆盖 | 合并、拆分、提取、加密等一应俱全 |
| 缺点 | 中文易乱码 | 对中文字体编码支持较弱,这是最常见的坑 |
| 缺点 | 文本提取能力有限 | 对复杂排版、表格、扫描件基本失效 |
| 缺点 | 大文件内存占用高 | 将整个pdf加载到内存,几百页可能卡死 |
特别提醒:pypdf2对中文pdf提取文本时容易产生乱码。官方原版pypdf2已停止维护,推荐使用其现代分支 pypdf(api几乎完全兼容)[reference:1]。下文代码同时支持两种写法,你只需将 import pypdf2 替换为 import pypdf 即可平滑迁移。
1.3 与其他pdf处理库的对比
为了让读者更清楚pypdf2的定位,下图展示了主流python pdf库的对比:
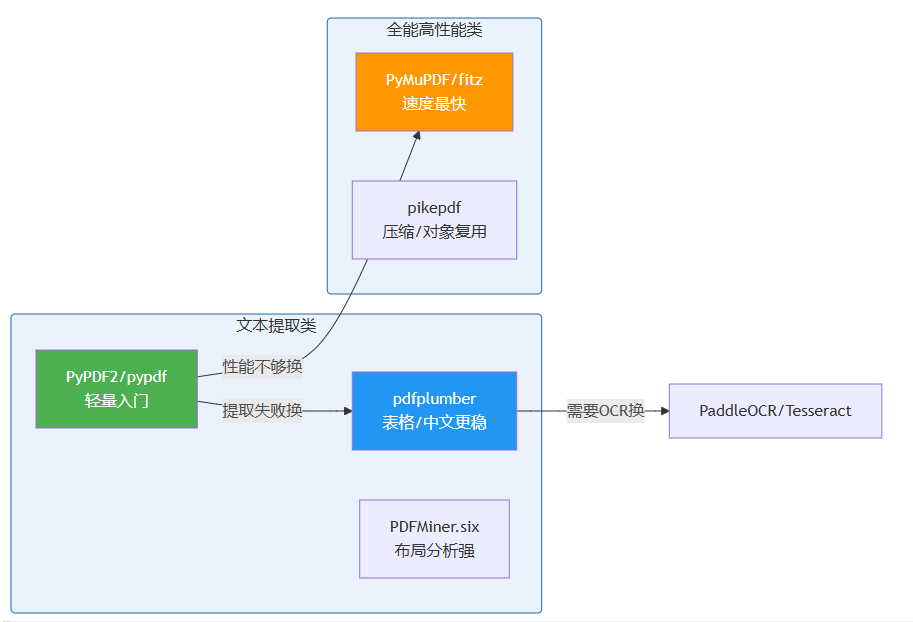
一句话选择建议:日常基础操作用pypdf2/pypdf;提取中文或表格换pdfplumber;追求性能或处理大型pdf用pymupdf;扫描件pdf直接上ocr。
二、环境准备:pip安装 + 虚拟环境配置
2.1 基础安装
打开终端/命令提示符,执行以下命令:
pip install pypdf2
如果你决定使用现代分支pypdf(强烈推荐),执行:
pip install pypdf
验证安装是否成功:
python -c "import pypdf2; print(pypdf2.__version__)" # 输出类似:3.0.0
2.2 虚拟环境配置(团队项目推荐)
# 创建虚拟环境 python -m venv pdf_env # 激活虚拟环境(windows) pdf_env\scripts\activate # 激活虚拟环境(mac/linux) source pdf_env/bin/activate # 在虚拟环境中安装 pip install pypdf2 # 导出依赖清单 pip freeze > requirements.txt
2.3 安装常见问题
| 错误信息 | 原因 | 解决方案 |
|---|---|---|
| no module named 'pypdf2' | 未安装库 | 执行 pip install pypdf2 |
| importerror: cannot import name 'pdffilereader' | 新版api变更 | 改用 from pypdf2 import pdfreader |
| pip install 超时 | 网络问题 | 换国内镜像:pip install pypdf2 -i https://pypi.tuna.tsinghua.edu.cn/simple |
三、核心操作:逐页读取pdf文本
3.1 初学者最易犯的错误
很多新手会这样写:
import pypdf2
with open('example.pdf', 'rb') as file:
reader = pypdf2.pdfreader(file)
print(reader) # 输出:<pypdf2._reader.pdfreader object at 0x...>
打印出来的只是一个内存地址,而不是pdf的内容[reference:2]。这是因为pdfreader对象代表的是整个pdf文档的结构,而不是文本本身。
3.2 逐页提取完整代码
import pypdf2
def extract_text_from_pdf(pdf_path):
"""从pdf文件中提取所有文本并打印"""
try:
with open(pdf_path, 'rb') as file:
reader = pypdf2.pdfreader(file)
print(f"文件共 {len(reader.pages)} 页\n")
for page_num, page in enumerate(reader.pages):
text = page.extract_text()
print(f"--- 第 {page_num + 1} 页 ---")
print(text if text else "[该页无文本或提取失败]")
print()
except filenotfounderror:
print(f"错误:文件 '{pdf_path}' 不存在")
except exception as e:
print(f"处理pdf时发生错误:{e}")
# 使用示例
extract_text_from_pdf('example.pdf')
3.3 只提取指定页面
# 只提取第3页(索引从0开始,所以第3页的索引是2)
reader = pypdf2.pdfreader('example.pdf')
third_page_text = reader.pages[2].extract_text()
print(third_page_text)
3.4 合并多个pdf文件
from pypdf2 import pdfreader, pdfwriter
def merge_pdfs(pdf_list, output_path):
writer = pdfwriter()
for pdf_file in pdf_list:
reader = pdfreader(pdf_file)
for page in reader.pages:
writer.add_page(page)
with open(output_path, 'wb') as f:
writer.write(f)
print(f"合并完成!共 {len(writer.pages)} 页,保存至 {output_path}")
# 使用示例
merge_pdfs(['file1.pdf', 'file2.pdf', 'file3.pdf'], 'merged.pdf')
3.5 拆分pdf文件
from pypdf2 import pdfreader, pdfwriter
def split_pdf(input_pdf, output_dir):
reader = pdfreader(input_pdf)
for i, page in enumerate(reader.pages):
writer = pdfwriter()
writer.add_page(page)
output_path = f"{output_dir}/page_{i+1}.pdf"
with open(output_path, 'wb') as f:
writer.write(f)
print(f"拆分完成!共 {len(reader.pages)} 个文件")
# 只拆分前5页
def split_first_n_pages(input_pdf, n, output_dir):
reader = pdfreader(input_pdf)
writer = pdfwriter()
for page in reader.pages[:n]:
writer.add_page(page)
with open(f"{output_dir}/first_{n}_pages.pdf", 'wb') as f:
writer.write(f)
四、进阶:获取pdf元信息
pdf文件通常包含元数据(metadata),如作者、标题、创建工具、加密状态等。pypdf2可以轻松读取这些信息。
4.1 获取完整元信息
from pypdf2 import pdfreader
reader = pdfreader('example.pdf')
info = reader.metadata
print("=" * 40)
print("pdf 元信息")
print("=" * 40)
print(f"标题: {info.title}")
print(f"作者: {info.author}")
print(f"主题: {info.subject}")
print(f"创建者: info.creator}")
print(f"生产者: info.producer}")
print(f"页数: {len(reader.pages)}")
print(f"是否加密: {reader.is_encrypted}")
print("=" * 40)
4.2 处理加密pdf
from pypdf2 import pdfreader
reader = pdfreader('encrypted.pdf')
if reader.is_encrypted:
try:
# 尝试解密
reader.decrypt('your_password')
print("解密成功!")
# 现在可以正常提取文本
text = reader.pages[0].extract_text()
print(text)
except exception as e:
print(f"解密失败:{e}")
else:
print("文件未加密,直接读取")
重要提示:pypdf2对加密pdf的支持有限,仅支持旧式加密算法(rc4),不支持aes-256等现代加密方式[reference:3]。遇到 notimplementederror: only algorithm code 1 and 2 are supported 错误时,说明文件使用了不支持的加密算法,建议换用pikepdf处理[reference:4]。
五、避坑指南:中文乱码的根源与解决方案
这是初学者在使用pypdf2时最常踩的坑,值得花一整节来讲清楚。
5.1 乱码现象长什么样?
# 原本应该是:"这是一份中文pdf文档" # 实际输出: "ä¸è¿½ä»½ä¸æpdfææ£" # 或者输出: "?????????"
5.2 中文乱码的根源(重点理解)
乱码的根本原因并不复杂。下图清晰解释了为什么pypdf2会提取出乱码:
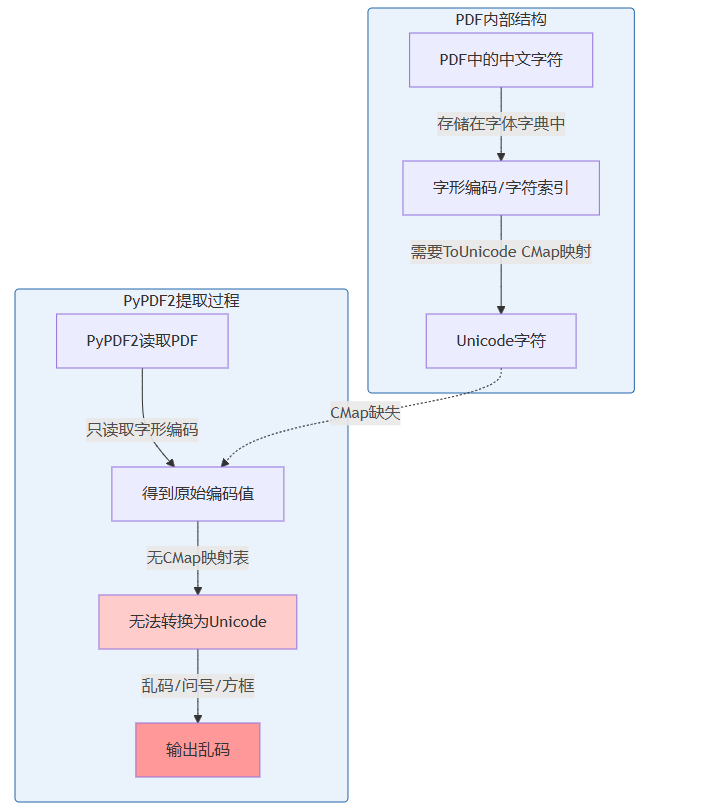
简单来说:pdf中的中文字符存储的是一串“编号”,需要借助“编码映射表”才能翻译成正确的中文。pypdf2恰恰缺少这个翻译能力,遇到非标准编码的中文字体就直接“放弃治疗”,输出占位符[reference:5]。
具体来说,乱码的根源有以下几种:
- 字体未嵌入或嵌入不全:pdf使用外部字体,提取时找不到对应关系
- 编码映射表(tounicode cmap)缺失:字符代码无法映射到unicode
- pypdf2本身不支持复杂字体解码:遇到cid字体、自定义编码的中文字体时直接输出乱码[reference:6]
- 编码方式不匹配:pdf实际使用gbk编码,而库默认按utf-8解码
5.3 如何判断pdf是否“可提取”?
在执行代码之前,建议先手动测试一下pdf的文字是否可选:
from pypdf2 import pdfreader
def check_pdf_extractability(pdf_path):
reader = pdfreader(pdf_path)
print(f"文件名: {pdf_path}")
print(f"页数: {len(reader.pages)}")
print(f"是否加密: {reader.is_encrypted}")
# 尝试提取第一页的前200个字符
sample = reader.pages[0].extract_text()[:200]
print(f"第一页预览: {sample}")
# 检查生产者信息
producer = reader.metadata.get('/producer', '未知')
print(f"生产者: {producer}")
# 初步判断
if any(ord(c) > 127 for c in sample if c):
print(">>> 可能包含非ascii字符(中文),提取结果可能存在乱码风险")
else:
print(">>> 仅包含ascii字符,提取相对可靠")
check_pdf_extractability('test.pdf')
5.4 中文乱码的临时解决方案
虽然pypdf2无法完美解决中文乱码,但在某些场景下可以通过以下方式缓解:
方案1:使用pdfplumber替代(推荐)
# pip install pdfplumber
import pdfplumber
with pdfplumber.open('chinese_doc.pdf') as pdf:
for page in pdf.pages:
text = page.extract_text()
print(text)
pdfplumber基于pdfminer,对中文字体支持更稳定,api也非常相似[reference:7]。
方案2:使用pypdf(现代分支)加容错参数
from pypdf import pdfreader
# 添加strict=false忽略部分解析警告
reader = pdfreader('chinese_doc.pdf', strict=false)
text = reader.pages[0].extract_text()
方案3:处理扫描件pdf(图片型pdf)
# 图片型pdf需要先转换为图片,再用ocr识别
# pip install pdf2image pytesseract pillow
from pdf2image import convert_from_path
import pytesseract
images = convert_from_path('scanned.pdf')
text = pytesseract.image_to_string(images[0], lang='chi_sim')
print(text)
方案4:编码后处理
# 尝试手动修复编码(仅适用于特定场景)
def fix_encoding(broken_text):
# 尝试不同的编码方式
for encoding in ['gbk', 'gb2312', 'big5', 'utf-8']:
try:
return broken_text.encode('latin1').decode(encoding)
except:
continue
return broken_text
text = page.extract_text()
fixed_text = fix_encoding(text)
5.5 避坑总结
| 问题类型 | 表现 | 解决方案 |
|---|---|---|
| 文字型pdf | 输出乱码(如ä¸æ†) | 换用pdfplumber |
| 扫描件pdf | 提取为空或全是乱码 | 走ocr路线 |
| 加密pdf | 报notimplementederror | 换pikepdf解密 |
| 大文件 | 内存暴涨/卡死 | 分批处理或换pypdf |
六、完整可运行代码:批量处理文件夹内所有pdf
以下是一个生产环境可直接使用的脚本,一键提取文件夹内所有pdf的文本内容,并保存为独立的txt文件。
import os
import sys
from pathlib import path
from pypdf2 import pdfreader
def extract_text_from_pdf(pdf_path):
"""
从单个pdf文件提取文本
返回: (是否成功, 文本内容)
"""
try:
reader = pdfreader(pdf_path)
full_text = []
for page_num, page in enumerate(reader.pages, 1):
text = page.extract_text()
if text:
full_text.append(f"[第{page_num}页]\n{text}\n")
else:
full_text.append(f"[第{page_num}页]\n[无文本或提取失败]\n")
return true, "\n".join(full_text)
except exception as e:
return false, f"处理失败:{str(e)}"
def batch_extract_pdfs(input_folder, output_folder, extensions=none):
"""
批量提取文件夹内所有pdf的文本
参数:
input_folder: 存放pdf文件的文件夹路径
output_folder: 输出txt文件的文件夹路径
extensions: 文件扩展名列表,默认为['.pdf']
"""
if extensions is none:
extensions = ['.pdf', '.pdf']
# 创建输出文件夹
path(output_folder).mkdir(parents=true, exist_ok=true)
# 收集所有pdf文件
pdf_files = []
for ext in extensions:
pdf_files.extend(path(input_folder).glob(f"*{ext}"))
if not pdf_files:
print(f"在文件夹 '{input_folder}' 中未找到pdf文件")
return
print(f"共找到 {len(pdf_files)} 个pdf文件,开始处理...\n")
success_count = 0
fail_count = 0
for pdf_file in pdf_files:
print(f"正在处理: {pdf_file.name} ...")
success, content = extract_text_from_pdf(str(pdf_file))
output_path = path(output_folder) / f"{pdf_file.stem}.txt"
with open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
if success:
success_count += 1
print(f" ✓ 成功,已保存至: {output_path.name}")
else:
fail_count += 1
print(f" ✗ 失败: {content[:100]}")
print(f"\n{'='*50}")
print(f"处理完成!成功: {success_count},失败: {fail_count}")
print(f"输出目录: {output_folder}")
print(f"{'='*50}")
def extract_with_progress(input_folder, output_folder, show_preview=true):
"""
带进度预览的批量提取功能
"""
pdf_files = list(path(input_folder).glob("*.pdf")) + list(path(input_folder).glob("*.pdf"))
total = len(pdf_files)
for idx, pdf_file in enumerate(pdf_files, 1):
print(f"[{idx}/{total}] 处理: {pdf_file.name}")
success, content = extract_text_from_pdf(str(pdf_file))
if show_preview and success:
preview = content[:200].replace('\n', ' ')
print(f" 预览: {preview}...")
output_path = path(output_folder) / f"{pdf_file.stem}.txt"
with open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
print(f" ✓ 已保存\n")
if __name__ == "__main__":
# 方式1:直接运行
input_dir = "./pdfs" # 存放pdf的文件夹
output_dir = "./output" # 输出txt的文件夹
# 方式2:命令行传参
if len(sys.argv) >= 3:
input_dir = sys.argv[1]
output_dir = sys.argv[2]
batch_extract_pdfs(input_dir, output_dir)
# 如果需要更详细的处理进度,使用以下函数
# extract_with_progress(input_dir, output_dir, show_preview=true)
七、总结与延伸建议
7.1 本文核心要点回顾
| 知识点 | 关键内容 |
|---|---|
| 安装配置 | pip install pypdf2,推荐同时安装pdfplumber作为备选 |
| 文本提取 | 三步走:pdfreader → pages → .extract_text() |
| 合并/拆分 | 使用pdfwriter添加/写入页面 |
| 元数据 | reader.metadata获取标题、作者等信息 |
| 中文乱码 | 根源在于字体编码映射缺失,推荐pdfplumber替代 |
7.2 pypdf2 vs pypdf 版本选择建议
| 版本 | 维护状态 | 推荐度 | 适用场景 |
|---|---|---|---|
| pypdf2 1.x~2.x | 已停止 | ⭐ | 不推荐 |
| pypdf2 3.x | 最终版 | ⭐⭐ | 短期使用 |
| pypdf | 活跃更新 | ⭐⭐⭐⭐⭐ | 强烈推荐 |
只需将 import pypdf2 改为 import pypdf,from pypdf2 import xxx 改为 from pypdf import xxx,代码几乎无需其他改动即可平滑迁移。
7.3 进阶学习方向
- pdfplumber:提取中文pdf文本、表格数据的首选替代方案
- pymupdf:追求极致性能时使用,速度远超pypdf2
- pikepdf:处理加密pdf、优化合并后体积时使用
- paddleocr:处理扫描件pdf时使用,中英文识别准确率高
一点提醒:任何工具都有其边界。pypdf2最适合处理西文、无加密、文本型pdf的轻量级操作。遇到中文乱码、扫描件、大文件等场景,及时切换工具往往比“硬扛”更高效。
到此这篇关于python使用pypdf2实现快速提取pdf文本的文章就介绍到这了,更多相关python pypdf2提取pdf文本内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论