1. 什么是 alembic,为什么需要它?
alembic 是由 sqlalchemy 的作者 mike bayer 编写的数据库迁移工具。你可以把它理解成「数据库的 git」——它跟踪数据库结构(schema)的变化,让你可以在不同版本之间前进和后退。
没有 alembic 时的痛点
假设你在开发一个博客项目,一开始 users 表只有 id 和 name,后来需要加一个 email 字段。你可能会:
- 手动登录数据库执行
alter table users add column email varchar(255); - 告诉团队成员「记得去改一下数据库」
- 生产环境上线时再手动执行一遍
这种方式的问题显而易见:容易遗漏、无法追踪、无法回滚。
有了 alembic 之后
- 所有数据库结构的变更都以 迁移脚本 的形式保存在代码仓库中
- 团队成员只需执行一条命令
alembic upgrade head即可同步最新结构 - 可以随时 回滚 到任意历史版本
- 支持自动检测 sqlalchemy model 的变化,自动生成迁移脚本
2. 安装与初始化
安装
pip install alembic sqlalchemy
如果你使用 postgresql:
pip install psycopg2-binary
初始化 alembic 环境
在项目根目录下执行以下命令完成初始化:
alembic init alembic
执行后,项目目录结构如下:
myproject/
├── alembic/
│ ├── env.py # 核心配置脚本,每次运行迁移都会执行
│ ├── readme
│ ├── script.py.mako # 迁移脚本的模板文件
│ └── versions/ # 存放所有迁移版本文件的目录
│ └── (这里会生成迁移脚本)
├── alembic.ini # alembic 的主配置文件
└── app/
└── models.py # 你的 sqlalchemy 模型
理解各个文件的作用
alembic.ini — 主配置文件,主要配置数据库连接 url:
[alembic] # 迁移脚本存放位置 script_location = alembic # 数据库连接 url sqlalchemy.url = sqlalchemy.url = postgresql+psycopg2://username:password@db_ip:5432/db_name # 省略其他...
env.py — 这是 alembic 的核心运行脚本。每次你执行任何 alembic 命令,这个文件都会被执行。它负责:
- 建立数据库连接
- 配置迁移上下文
- 区分「在线模式」(直接执行 sql)和「离线模式」(生成 sql 文件)
versions/ — 存放所有迁移文件。文件名格式类似 3512b954651e_add_users_table.py,使用部分 guid 而非递增整数来命名,这样可以更好地支持分支合并。
3. 基本使用
1 创建你的第一个 model
先创建一个简单的 sqlalchemy 模型文件:
# app/models.py
from sqlalchemy import column, integer, string, datetime
from sqlalchemy.orm import declarative_base
import datetime
base = declarative_base()
class user(base):
__tablename__ = "users"
id = column(integer, primary_key=true, index=true)
name = column(string(50), nullable=false)
email = column(string(200), nullable=false, unique=true)
created_at = column(datetime, default=datetime.datetime.utcnow)
2 将model 与 alembic关联
修改 alembic/env.py,让 alembic 知道你的 model 在哪里:
# alembic/env.py 中找到这行: # target_metadata = none # 替换为: import sys import os from app.models import base # 导入你的 base target_metadata = base.metadata # 告诉 alembic 用哪个 metadata 来检测变化 # 或 target_metadata = [base.metadata, ]
💡 新手常见错误:忘记把
target_metadata = none改成你的base.metadata,导致自动生成的迁移脚本是空的。
3 创建第一个迁移脚本
alembic revision --autogenerate-m "create users table"
执行后,alembic/versions/ 目录下会生成类似这样的文件:
# alembic/versions/673707e9f34b_create_users_table.py
"""create users table
revision id: 673707e9f34b
revises:
create date: 2026-03-20 08:57:19.170729
"""
from typing import sequence, union
from alembic import op
import sqlalchemy as sa
# 版本标识,alembic 用这个来追踪当前在哪个版本
revision: str = '673707e9f34b'
down_revision: union[str, sequence[str], none] = none # 前一个版本的 revision id, none 表示这是第一个迁移
branch_labels: union[str, sequence[str], none] = none
depends_on: union[str, sequence[str], none] = none
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.create_table('users',
sa.column('id', sa.integer(), nullable=false),
sa.column('name', sa.string(length=50), nullable=false),
sa.column('email', sa.string(length=200), nullable=false),
sa.column('created_at', sa.datetime(), nullable=true),
sa.primarykeyconstraint('id'),
sa.uniqueconstraint('email')
)
op.create_index(op.f('ix_users_id'), 'users', ['id'], unique=false)
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_index(op.f('ix_users_id'), table_name='users')
op.drop_table('users')
# ### end alembic commands ###
每个迁移脚本包含两个函数:
upgrade()— 应用变更(往新版本走)downgrade()— 撤销变更(往旧版本退)
4 执行迁移(升级到最新版本)
alembic upgrade head
head 表示升级到最新版本。执行后,alembic 会:
- 连接数据库
- 检查
alembic_version表(首次运行时自动创建),确认当前所处的版本 - 依次执行所有尚未应用的迁移脚本中的
upgrade()函数
如果你想升级到某个特定版本:
alembic upgrade 3512b954651e # revision id
或者升级 n 步:
alembic upgrade +2
5 回滚迁移
回滚到上一个版本:
alembic downgrade -1
回滚到某个特定版本:
alembic downgrade 3512b954651e # alembic downgrade 3512b954651e
回滚到最初状态(撤销所有迁移):
alembic downgrade base
4. 自动生成迁移脚本(autogenerate)
手动编写迁移脚本很麻烦,alembic 的杀手锏功能是 自动生成(autogenerate) 。
其工作原理是:将你的 sqlalchemy model 定义(目标状态)与数据库中实际的表结构(当前状态)进行比对,自动生成一个描述两者「差异」的迁移脚本。
使用示例
假设你在 user.py 中新增了一个 phone 字段:
# app/models/user.py
from sqlalchemy import column, integer, string, datetime
from sqlalchemy.orm import declarative_base
import datetime
base = declarative_base()
class user(base):
__tablename__ = "users" # 命名约束,定义表名,建议添加
id = column(integer, primary_key=true, index=true)
name = column(string(50), nullable=false)
email = column(string(200), nullable=false, unique=true)
phone = column(string(20), nullable=false, unique=true) # 新增phone字段
created_at = column(datetime, default=datetime.datetime.utcnow)
然后执行自动生成命令:
alembic revision --autogenerate -m "add phone field to user table"
alembic 会自动生成:
# alembic/versions/7f29ab2b2004_add_phone_field_to_user_table.py
"""add phone field to user table
revision id: 7f29ab2b2004
revises: 673707e9f34b
create date: 2026-03-20 09:12:51.346000
"""
from typing import sequence, union
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by alembic.
revision: str = '7f29ab2b2004'
down_revision: union[str, sequence[str], none] = '673707e9f34b'
branch_labels: union[str, sequence[str], none] = none
depends_on: union[str, sequence[str], none] = none
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.add_column('users', sa.column('phone', sa.string(length=20), nullable=false))
op.create_unique_constraint(none, 'users', ['phone'])
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_constraint(none, 'users', type_='unique')
op.drop_column('users', 'phone')
# ### end alembic commands ###
最后执行升级命令使变更生效:
alembic upgrade head
查看当前版本和历史
查看当前数据库所在的版本:
alembic current
输出示例
info [alembic.runtime.migration] context impl postgresqlimpl. info [alembic.runtime.migration] will assume transactional ddl. 7f29ab2b2004 (head)
查看所有迁移历史:
alembic history
输出示例:
673707e9f34b -> 7f29ab2b2004 (head), add phone field to user table <base> -> 673707e9f34b, create users table
autogenerate 能检测哪些变化?
默认支持检测✅
- 新增 / 删除表
- 新增 / 删除列
- 列的 nullable 状态变化
- 基本索引变化
- 显式命名的唯一约束变化
- 基本外键约束变化
无法检测 ❌
| 变化类型 | 原因 |
|---|---|
| 表名重命名 | 会被识别为「删除旧表 + 新建新表」,需手动改成 rename 操作 |
| 列名重命名 | 同上,会被识别为「删除旧列 + 新增新列」,直接导致数据丢失 |
| 匿名约束 | 没有名字的约束无法被可靠追踪 |
| 不原生支持 enum 的数据库上的枚举类型 | sqlite 等数据库用 char + check 模拟枚举,alembic 无法从反射结果中判断这是否是一个枚举 |
| 存储过程、函数、触发器等 | 超出 alembic 的管理范围 |
💡 自动生成的迁移脚本永远不是 100% 完美的,每次生成后都必须人工审核! 这是官方文档明确强调的原则,autogenerate 的目标是「辅助」而非「替代」人工判断。
5.结合fastapi + sqlmodel使用
sqlmodel是为fastapi设计的与数据库交互的库,基于 python 类型注解,并由 pydantic 和 sqlalchemy 驱动。
1. 安装依赖
pip install fastapi[standard] sqlmodel
2. 定义模型
# app/models/user.py
from sqlmodel import sqlmodel, field
from datetime import datetime, timezone
class userbase(sqlmodel):
"""
用户基础模型
公共字段基类,被 create / response 等 schema 复用
"""
name: str = field(index=true, description="用户名")
email: str = field(index=true, unique=true, description="用户邮箱")
created_at: datetime = field(lambda: datetime.now(timezone.utc), description="创建时间")
class user(userbase, table=true):
"""
用户模型
映射数据库表 users
"""
__tablename__ = "users"
id: int = field(default=none, primary_key=true)
# request schema
class usercreate(userbase):
"""
创建用户的请求体
"""
pass
# response schema
class userread(userbase):
"""
返回给前端的响应体
"""
id: int
3. 修改迁移脚本模板文件
script.py.mako 是所有迁移脚本的模板文件。由于 sqlmodel 生成的迁移脚本默认不会导入 sqlmodel 模块,但生成的脚本内容通常又依赖它,因此推荐在模板中统一添加这个导入,避免每次生成后都要手动修改。
# alembic/script.py.mako
# 添加 **import sqlmodel**
**"""${message}
revision id: ${up_revision}
revises: ${down_revision | comma,n}
create date: ${create_date}
"""
from typing import sequence, union
from alembic import op
import sqlalchemy as sa
import sqlmodel # 新增代码
${imports if imports else ""}
# revision identifiers, used by alembic.
revision: str = ${repr(up_revision)}
down_revision: union[str, sequence[str], none] = ${repr(down_revision)}
branch_labels: union[str, sequence[str], none] = ${repr(branch_labels)}
depends_on: union[str, sequence[str], none] = ${repr(depends_on)}
def upgrade() -> none:
"""upgrade schema."""
${upgrades if upgrades else "pass"}
def downgrade() -> none:
"""downgrade schema."""
${downgrades if downgrades else "pass"}**
4. 配置 env.py
from app.models.user import user
target_metadata = [
user.metadata,
]
# 省略其他
5.生成迁移脚本
alembic revision --autogenerate -m "create users table"
生成的迁移脚本如下:
"""create users table
revision id: 54b2d338fcc9
revises:
create date: 2026-03-20 10:11:18.524007
"""
from typing import sequence, union
from alembic import op
import sqlalchemy as sa
import sqlmodel # 如果不修改mako文件,这里需要手动引入sqlmodel
# revision identifiers, used by alembic.
revision: str = '54b2d338fcc9'
down_revision: union[str, sequence[str], none] = none
branch_labels: union[str, sequence[str], none] = none
depends_on: union[str, sequence[str], none] = none
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.create_table('users',
sa.column('name', sqlmodel.sql.sqltypes.autostring(), nullable=false),
sa.column('email', sqlmodel.sql.sqltypes.autostring(), nullable=false),
sa.column('created_at', sa.datetime(), nullable=false),
sa.column('id', sa.integer(), nullable=false),
sa.primarykeyconstraint('id')
)
op.create_index(op.f('ix_users_email'), 'users', ['email'], unique=true)
op.create_index(op.f('ix_users_name'), 'users', ['name'], unique=false)
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_index(op.f('ix_users_name'), table_name='users')
op.drop_index(op.f('ix_users_email'), table_name='users')
op.drop_table('users')
# ### end alembic commands ###
6. 多环境管理
实际项目中,通常需要分别管理本地开发、预发布(staging)和生产(production)三套环境的数据库,每套环境都有各自独立的连接配置和迁移历史。alembic 支持通过 -n 参数指定目标环境来实现这一需求。
1. 修改alembic.ini
[alembic] script_location = alembic/local sqlalchemy.url = postgresql+psycopg2://username:paasowrd@local_db_ip:5432/local_db_name [staging] script_location = alembic/staging sqlalchemy.url = postgresql+psycopg2://username:paasowrd@staging_db_ip:5432/staging_db_name [production] script_location = alembic/production sqlalchemy.url = postgresql+psycopg2://username:paasowrd@production_db_ip:5432/production_db_ip_name [default] prepend_sys_path = . version_path_separator = os # 省略其他配置
2. 初始化alembic环境
alembic init alembic/local alembic -n staging init alembic/staging alembic -n production init alembic/production
生成的目录结构如下
your_project/ ├── alembic/ │ ├── local/ │ │ └── versions/ │ ├── production/ │ │ └── versions/ │ └── staging/ │ └── versions/ ├── app/ │ └── models/ └── alembic.ini
3. 针对不同环境执行迁移
# local(默认环境,无需 -n 参数) alembic revision --autogenerate -m "add users table" alembic upgrade head # staging alembic -n staging revision --autogenerate -m "add users table" alembic -n staging upgrade head # production alembic -n production revision --autogenerate -m "add users table" alembic -n production upgrade head
7. 生产环境最佳实践
1. 迁移前务必备份数据库
在对生产数据库执行任何迁移之前,应当先完整备份,以防迁移失败时可以快速恢复。
# 全量备份 pg_dump -u postgres -f c -v -f test_db_$(date +%y%m%d_%h%m%s).backup test_db # 若需要恢复 psql -u postgres -c "create database test_db_restore;" pg_restore -u postgres -d test_db_restore -v --clean test_db_20260320_031055.backup
2. 生产环境的数据库 url 不应硬编码在配置文件中
将数据库连接地址明文写入 alembic.ini 存在安全隐患,推荐改用 pydantic_settings 从环境变量中读取。
第一步:删除 alembic.ini 中的 sqlalchemy.url
# 删除sqlalchemy.url [production] script_location = alembic/production
第二步:新增 pydantic 配置文件
# app/core/settings.py
from pydantic_settings import basesettings
class settings(basesettings):
database_url: str
settings = settings()
第三步:修改 production 的 env.py
# alembic/production/env.py
from app.core.settings import settings
# 使用环境变量里的databse url配置
config.set_main_option("sqlalchemy.url", settings.database_url)
第四步:设置环境变量后再执行迁移命令
# 设置迁url后再执行迁移命令 export database_url="你的databse_url" alembic -n production revision --autogenerate -m "create users table"
8. 枚举类型的正确处理方式
枚举(enum)字段的迁移处理是一个容易踩坑的地方,值得单独说明。
为什么不推荐 postgresql 原生 enum?
alembic 虽然支持 postgresql 的原生 enum 类型,但实际使用中存在以下问题:
- postgresql 原生枚举类型只能追加值,不能删除
- 如果需要修改枚举值,只能重建整个枚举类型,操作繁琐
- alembic 无法自动识别枚举值的变化,需要完全手动处理迁移脚本
# app/models/user.py
from enum import enum
from sqlmodel import sqlmodel, field
from datetime import datetime, timezone
class userstatus(str, enum):
"""用户状态枚举"""
active = "active"
banned = "banned"
deleted = "deleted"
class userbase(sqlmodel):
# 省略其他
status: userstatus = field(default=userstatus.active, description="用户状态") # 使用原生enum,❌不推荐
推荐方案:varchar+ check 约束
使用 sa_column 将字段定义为 varchar 类型,并通过 check 约束限制合法值范围。这样 alembic 就能检测到枚举值的变化并自动生成迁移脚本。
# app/models/user.py
from sqlalchemy import column, enum as saenum
class userbase(sqlmodel):
status: userstatus | none = field(
default=none,
description="用户状态",
sa_column=column(saenum(
userstatus,
name="user_status",
create_constraint=true,
native_enum=false,
nullable=true
))
)
# 省略其他
生成的迁移脚本如下:
# alembic/production/versions/568f7d9f2553_change_status_field.py
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.add_column(
'users',
sa.column(
'status',
sa.enum('active', 'banned', 'deleted',
name='user_status',
native_enum=false,
create_constraint=true
),
nullable=true
)
)
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_column('users', 'status')
# ### end alembic commands ###
查看 users 表的约束,可以看到 status 字段类型为 varchar,并关联了名为 user_status 的 check 约束。
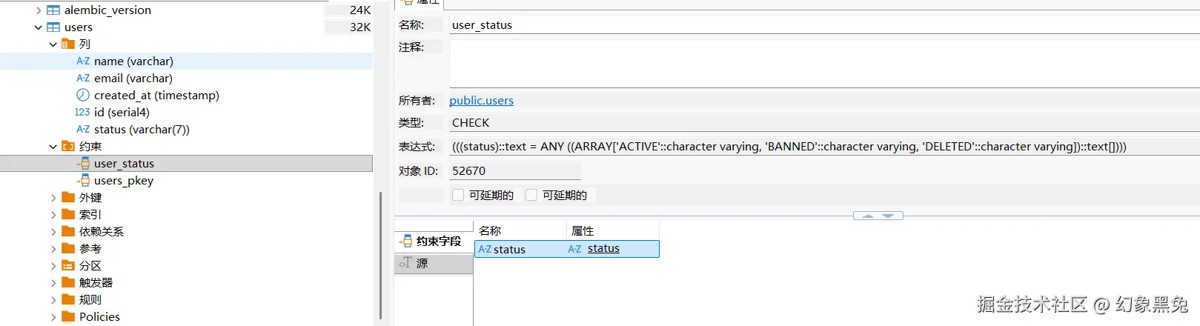
这种方案最大的优势是:当你修改 userstatus 枚举时,alembic 能够自动识别变化并生成对应的迁移脚本。
场景一:新增枚举值
# app/models/user.py
class userstatus(str, enum):
"""用户状态枚举"""
active = "active"
banned = "banned"
deleted = "deleted"
in_active = "in_active" # 新增
自动生成的迁移脚本如下:
# alembic/production/versions/568f7d9f2553_change_status_field.py
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.alter_column('users', 'status',
existing_type=sa.varchar(length=7),
type_=sa.enum('active', 'banned', 'deleted', 'in_active', name='user_status', native_enum=false, create_constraint=true),
existing_nullable=true)
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.alter_column('users', 'status',
existing_type=sa.enum('active', 'banned', 'deleted', 'in_active', name='user_status', native_enum=false, create_constraint=true),
type_=sa.varchar(length=7),
existing_nullable=true)
# ### end alembic commands ###
注意:直接执行上述脚本会报错:
sqlalchemy.exc.programmingerror: (psycopg2.errors.duplicateobject) constraint "user_status" for relation "users" already exists
原因是 alembic 在 alter_column 时会尝试重新创建 check 约束,但旧的约束还未删除。需要手动在脚本中先删除旧约束:
# alembic/production/versions/568f7d9f2553_change_status_field.py
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check') # 手动添加:先删除旧约束
op.alter_column('users', 'status',
existing_type=sa.varchar(length=7),
type_=sa.enum('active', 'banned', 'deleted', 'in_active', name='user_status', native_enum=false, create_constraint=true),
existing_nullable=true)
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check') # # 手动添加:先删除旧约束
op.alter_column('users', 'status',
existing_type=sa.enum('active', 'banned', 'deleted', 'in_active', name='user_status', native_enum=false, create_constraint=true),
type_=sa.varchar(length=7),
existing_nullable=true)
# ### end alembic commands ###
场景二:修改已有枚举值
💡 alembic 只能检测枚举结构的增删变化(新增或删除某个枚举值),对于修改枚举值本身(如将 banned 改为 disabled)则无法感知,需要完全手动编写迁移脚本。
# app/models/user.py
class userstatus(str, enum):
"""用户状态枚举"""
active = "active"
disabled = "disabled" # 将banned修改为disabled
deleted = "deleted"
in_active = "in_active"
对于这类情况,需要手动编写迁移脚本,包括:先删除旧约束、更新现有数据中的历史枚举值、再创建新约束:
# alembic/productionversions/0d46a300af09_change_status_banned_to_disabled.py
def upgrade() -> none:
"""upgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check')
op.execute("update users set status = 'in_active' where status = 'is_active'")
op.execute("update users set status = 'disabled' where status = 'banned'")
op.create_check_constraint(
'user_status', 'users',
"status in ('active', 'disabled', 'deleted', 'in_active')"
)
# ### end alembic commands ###
def downgrade() -> none:
"""downgrade schema."""
# ### commands auto generated by alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check')
op.execute("update users set status = 'banned' where status = 'disabled'")
op.create_check_constraint(
'user_status', 'users',
"status in ('active', 'banned', 'deleted', 'in_active')"
)
# ### end alembic commands ###
```alembic入门教程
到此这篇关于python使用alembic迁移数据库的文章就介绍到这了,更多相关python alembic迁移数据库内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论