本文目标
本文以 真实案例 + 深度拆解 的方式,带你从零开始掌握 pyspark 的核心机制,涵盖:
- rdd 基本概念与创建
- 数据类型转换:
t → t与t → u - 核心算子详解(
map,flatmap,filter,distinct,sortby,reducebykey) - 如何修改 rdd 分区?
- 如何修复
msvcr120.dll缺失?(windows 专属) - 如何解决 spark 超时问题?
- 两个实战案例:城市销量排名 & 词频统计
一、pyspark 环境搭建基础配置(关键!)
特此强调:windows 用户务必设置以下环境变量,否则几乎所有操作都可能失败!
import os # 1. 指定 python 解释器路径(必须!) os.environ["pyspark_python"] = "d:\\app\\anaconda\\envs\\spark_env\\python.exe" # 2. windows 超时问题(防止 task 超时崩溃) os.environ['pyspark_timeout'] = '600' os.environ['pyspark_driver_timeout'] = '600' # 3. hadoop native dll 加载导致 msvcr120.dll 报错 os.environ['path'] += os.pathsep + 'e:\\app\\hadoop-3.4.2\\bin' # 4. 强制设置 driver python(可选但推荐) os.environ["pyspark_driver_python"] = "d:\\app\\anaconda\\envs\\spark_env\\python.exe"
为什么这步如此重要?
msvcr120.dll是 visual c++ 2013 运行时库,常在 hadoop 的hadoop.dll调用失败时出现。- 即使你不用
saveastextfile(),如果path中包含hadoop/bin,spark 仍会触发 native io!- 终极建议:仅当必须使用原生 io 时才保留
path;否则删除该路径!
如何检查到是 msvcr120.dll 的问题: 这是我的报错
from pyspark import sparkconf,sparkcontext
import os
os.environ["pyspark_python"] = "d:\app\anaconda\envs\spark_env\python.exe"
os.environ['path'] += os.pathsep + 'e:\\app\\hadoop-3.4.2\\bin'
conf = sparkconf().setmaster("local").setappname("test_spark_app")
sc = sparkcontext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
rdd.saveastextfile("d:/output1")
sc.stop()d:\app\anaconda\envs\spark_env\python.exe d:\pythonprojects\python\day11_pyspark\数据输出\输出为文本文档.py
setting default log level to "warn".
to adjust logging level use sc.setloglevel(newlevel). for sparkr, use setloglevel(newlevel).
26/04/01 22:22:55 warn nativecodeloader: unable to load native-hadoop library for your platform... using builtin-java classes where applicable
26/04/01 22:22:58 error sparkhadoopwriter: aborting job job_202604012222567528972640969878075_0003.
java.lang.unsatisfiedlinkerror: org.apache.hadoop.io.nativeio.nativeio$windows.access0(ljava/lang/string;i)z
at org.apache.hadoop.io.nativeio.nativeio$windows.access0(native method)
at org.apache.hadoop.io.nativeio.nativeio$windows.access(nativeio.java:793)
at org.apache.hadoop.fs.fileutil.canread(fileutil.java:1249)
at org.apache.hadoop.fs.fileutil.list(fileutil.java:1454)
at org.apache.hadoop.fs.rawlocalfilesystem.liststatus(rawlocalfilesystem.java:601)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:1972)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:2014)
at org.apache.hadoop.fs.checksumfilesystem.liststatus(checksumfilesystem.java:761)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:1972)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:2014)
at org.apache.hadoop.mapreduce.lib.output.fileoutputcommitter.getallcommittedtaskpaths(fileoutputcommitter.java:334)
at org.apache.hadoop.mapreduce.lib.output.fileoutputcommitter.commitjobinternal(fileoutputcommitter.java:404)
at org.apache.hadoop.mapreduce.lib.output.fileoutputcommitter.commitjob(fileoutputcommitter.java:377)
at org.apache.hadoop.mapred.fileoutputcommitter.commitjob(fileoutputcommitter.java:136)
at org.apache.hadoop.mapred.outputcommitter.commitjob(outputcommitter.java:291)
at org.apache.spark.internal.io.hadoopmapreducecommitprotocol.commitjob(hadoopmapreducecommitprotocol.scala:192)
at org.apache.spark.internal.io.sparkhadoopwriter$.$anonfun$write$3(sparkhadoopwriter.scala:100)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.util.utils$.timetakenms(utils.scala:552)
at org.apache.spark.internal.io.sparkhadoopwriter$.write(sparkhadoopwriter.scala:100)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopdataset$1(pairrddfunctions.scala:1091)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopdataset(pairrddfunctions.scala:1089)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopfile$4(pairrddfunctions.scala:1062)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopfile(pairrddfunctions.scala:1027)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopfile$3(pairrddfunctions.scala:1009)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopfile(pairrddfunctions.scala:1008)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopfile$2(pairrddfunctions.scala:965)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopfile(pairrddfunctions.scala:963)
at org.apache.spark.rdd.rdd.$anonfun$saveastextfile$2(rdd.scala:1620)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.rdd.saveastextfile(rdd.scala:1620)
at org.apache.spark.rdd.rdd.$anonfun$saveastextfile$1(rdd.scala:1606)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.rdd.saveastextfile(rdd.scala:1606)
at org.apache.spark.api.java.javarddlike.saveastextfile(javarddlike.scala:564)
at org.apache.spark.api.java.javarddlike.saveastextfile$(javarddlike.scala:563)
at org.apache.spark.api.java.abstractjavarddlike.saveastextfile(javarddlike.scala:45)
at sun.reflect.nativemethodaccessorimpl.invoke0(native method)
at sun.reflect.nativemethodaccessorimpl.invoke(unknown source)
at sun.reflect.delegatingmethodaccessorimpl.invoke(unknown source)
at java.lang.reflect.method.invoke(unknown source)
at py4j.reflection.methodinvoker.invoke(methodinvoker.java:244)
at py4j.reflection.reflectionengine.invoke(reflectionengine.java:374)
at py4j.gateway.invoke(gateway.java:282)
at py4j.commands.abstractcommand.invokemethod(abstractcommand.java:132)
at py4j.commands.callcommand.execute(callcommand.java:79)
at py4j.clientserverconnection.waitforcommands(clientserverconnection.java:182)
at py4j.clientserverconnection.run(clientserverconnection.java:106)
at java.lang.thread.run(unknown source)
traceback (most recent call last):
file "d:\pythonprojects\python\day11_pyspark\数据输出\输出为文本文档.py", line 9, in <module>
rdd.saveastextfile("d:/output1")
file "d:\app\anaconda\envs\spark_env\lib\site-packages\pyspark\rdd.py", line 3425, in saveastextfile
keyed._jrdd.map(self.ctx._jvm.bytestostring()).saveastextfile(path)
file "d:\app\anaconda\envs\spark_env\lib\site-packages\py4j\java_gateway.py", line 1322, in __call__
return_value = get_return_value(
file "d:\app\anaconda\envs\spark_env\lib\site-packages\py4j\protocol.py", line 326, in get_return_value
raise py4jjavaerror(
py4j.protocol.py4jjavaerror: an error occurred while calling o33.saveastextfile.
: org.apache.spark.sparkexception: job aborted.
at org.apache.spark.internal.io.sparkhadoopwriter$.write(sparkhadoopwriter.scala:106)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopdataset$1(pairrddfunctions.scala:1091)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopdataset(pairrddfunctions.scala:1089)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopfile$4(pairrddfunctions.scala:1062)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopfile(pairrddfunctions.scala:1027)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopfile$3(pairrddfunctions.scala:1009)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopfile(pairrddfunctions.scala:1008)
at org.apache.spark.rdd.pairrddfunctions.$anonfun$saveashadoopfile$2(pairrddfunctions.scala:965)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.pairrddfunctions.saveashadoopfile(pairrddfunctions.scala:963)
at org.apache.spark.rdd.rdd.$anonfun$saveastextfile$2(rdd.scala:1620)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.rdd.saveastextfile(rdd.scala:1620)
at org.apache.spark.rdd.rdd.$anonfun$saveastextfile$1(rdd.scala:1606)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:151)
at org.apache.spark.rdd.rddoperationscope$.withscope(rddoperationscope.scala:112)
at org.apache.spark.rdd.rdd.withscope(rdd.scala:407)
at org.apache.spark.rdd.rdd.saveastextfile(rdd.scala:1606)
at org.apache.spark.api.java.javarddlike.saveastextfile(javarddlike.scala:564)
at org.apache.spark.api.java.javarddlike.saveastextfile$(javarddlike.scala:563)
at org.apache.spark.api.java.abstractjavarddlike.saveastextfile(javarddlike.scala:45)
at sun.reflect.nativemethodaccessorimpl.invoke0(native method)
at sun.reflect.nativemethodaccessorimpl.invoke(unknown source)
at sun.reflect.delegatingmethodaccessorimpl.invoke(unknown source)
at java.lang.reflect.method.invoke(unknown source)
at py4j.reflection.methodinvoker.invoke(methodinvoker.java:244)
at py4j.reflection.reflectionengine.invoke(reflectionengine.java:374)
at py4j.gateway.invoke(gateway.java:282)
at py4j.commands.abstractcommand.invokemethod(abstractcommand.java:132)
at py4j.commands.callcommand.execute(callcommand.java:79)
at py4j.clientserverconnection.waitforcommands(clientserverconnection.java:182)
at py4j.clientserverconnection.run(clientserverconnection.java:106)
at java.lang.thread.run(unknown source)
caused by: java.lang.unsatisfiedlinkerror: org.apache.hadoop.io.nativeio.nativeio$windows.access0(ljava/lang/string;i)z
at org.apache.hadoop.io.nativeio.nativeio$windows.access0(native method)
at org.apache.hadoop.io.nativeio.nativeio$windows.access(nativeio.java:793)
at org.apache.hadoop.fs.fileutil.canread(fileutil.java:1249)
at org.apache.hadoop.fs.fileutil.list(fileutil.java:1454)
at org.apache.hadoop.fs.rawlocalfilesystem.liststatus(rawlocalfilesystem.java:601)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:1972)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:2014)
at org.apache.hadoop.fs.checksumfilesystem.liststatus(checksumfilesystem.java:761)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:1972)
at org.apache.hadoop.fs.filesystem.liststatus(filesystem.java:2014)
at org.apache.hadoop.mapreduce.lib.output.fileoutputcommitter.getallcommittedtaskpaths(fileoutputcommitter.java:334)
at org.apache.hadoop.mapreduce.lib.output.fileoutputcommitter.commitjobinternal(fileoutputcommitter.java:404)
at org.apache.hadoop.mapreduce.lib.output.fileoutputcommitter.commitjob(fileoutputcommitter.java:377)
at org.apache.hadoop.mapred.fileoutputcommitter.commitjob(fileoutputcommitter.java:136)
at org.apache.hadoop.mapred.outputcommitter.commitjob(outputcommitter.java:291)
at org.apache.spark.internal.io.hadoopmapreducecommitprotocol.commitjob(hadoopmapreducecommitprotocol.scala:192)
at org.apache.spark.internal.io.sparkhadoopwriter$.$anonfun$write$3(sparkhadoopwriter.scala:100)
at scala.runtime.java8.jfunction0$mcv$sp.apply(jfunction0$mcv$sp.java:23)
at org.apache.spark.util.utils$.timetakenms(utils.scala:552)
at org.apache.spark.internal.io.sparkhadoopwriter$.write(sparkhadoopwriter.scala:100)
... 51 more
进程已结束,退出代码为 1由于找不到 msvcr120.dll,无法继续执行代码。重新安装程序可能会解决此问题。 是 windows 系统缺少 c++ 运行时库 的典型问题。
🚨 根本原因:
msvcr120.dll 是 microsoft visual c++ 2013 redistributable 的一部分。
它被 hadoop 的原生 .dll 文件(如 hadoop.dll)所依赖,当你使用 saveastextfile() 时,spark 会尝试加载 hadoop 的本地库,而这些库又依赖于 vc++ 运行时。
即使你现在不用 saveastextfile(),你之前配置了 path += e:\app\hadoop-3.4.2\bin,说明你还在用 hadoop 二进制文件,所以问题依然存在。
我一开始怀疑是缺少winutils 环境配置 winutils配置可以看我上个文章 或者是 winutils.exe 权限不对
你的 winutils.exe 必须放在hadoop的bin目录下 e:\app\hadoop-3.4.2\bin\winutils.exe
然后检查 权限
以 管理员身份 打开 cmd
一定要右键 → 以管理员身份运行命令提示符
. 执行你这条命令
```bash winutils.exe chmod 777 c:\tmp\hive
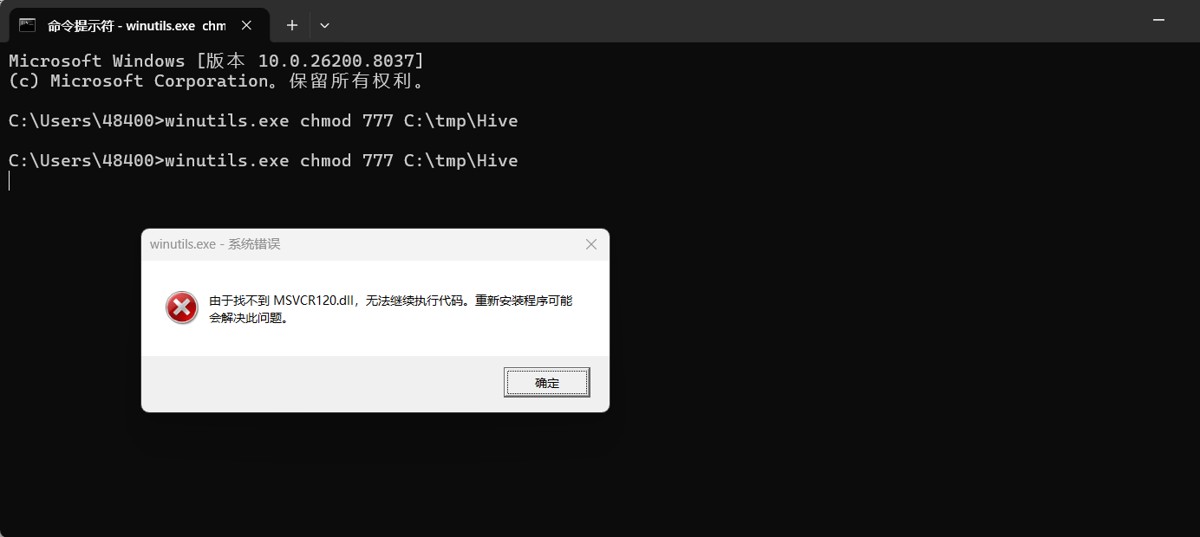
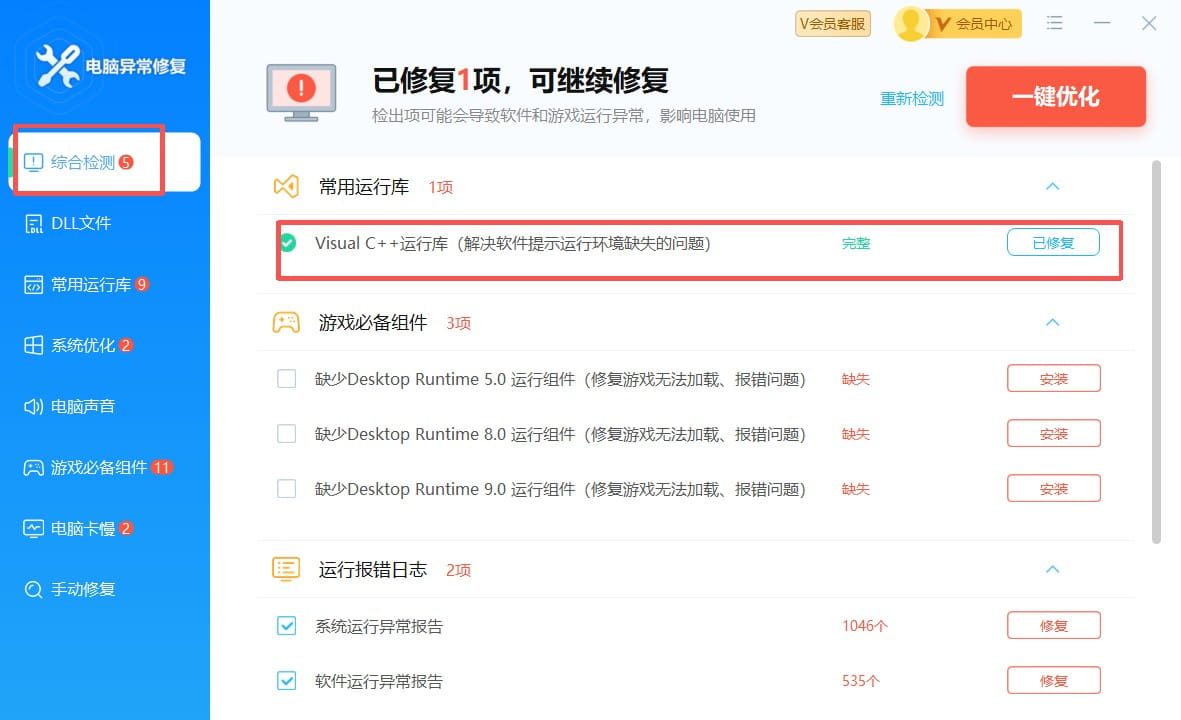
可以用联想的电脑异常修复直接修复
📌 二、rdd 基础概念与创建方式 💡
什么是 rdd?
rdd(resilient distributed dataset):弹性分布式数据集,是 spark 的核心抽象。它是一个不可变、可并行、容错的数据集合。
创建 rdd 的 6 种方式:
| 类型 | 示例 | 说明 |
|---|---|---|
| python 列表 | sc.parallelize([1,2,3]) | 最常用 |
| 字典 | sc.parallelize({"k":1}) | 返回 [{"k":1}] |
| 元组 | sc.parallelize(("a","b")) | 返回 [("a","b")] |
| 集合 | sc.parallelize([1,1,2,3]) | 包含重复项 |
| 字符串 | sc.parallelize("abc") | 每个字符为一个元素 |
| 文件 | sc.textfile("path.txt") | 逐行读取文本 |
推荐使用
parallelize()+textfile()搭配处理本地数据。
三、核心算子详解:类型转换与功能解析
1.map(t)→u:传入类型与返回类型不一致
作用:对每个元素进行函数映射,返回新值
rdd = sc.parallelize([1,2,3,4,5]) rdd2 = rdd.map(lambda x: x * 2) print(rdd2.collect()) # 输出: [2, 4, 6, 8, 10]
| 特点 | 说明 |
|---|---|
t → u | 输入是 int,输出是 int(类型一致),但语义上是“变换” |
| 按元素处理 | 每个元素独立转换 |
| 无聚合 | 不改变数据总量 |
适用场景:数据清洗、类型转换、数学计算
2.map(t)→t:传入类型与返回类型一致
作用:返回原类型,但可以修改内容
rdd = sc.parallelize(["apple", "banana"]) rdd2 = rdd.map(lambda x: x.upper()) print(rdd2.collect()) # ['apple', 'banana']
虽然返回类型仍是
str,但内容被修改 → 仍属于t → t
适用场景:字符串大小写转换、去除空格、文本标准化
3.flatmap(t)→u:扁平化处理,去嵌套
作用:将结果展开成平面列表
rdd = sc.parallelize(["hello world", "py spark"])
rdd2 = rdd.flatmap(lambda x: x.split(" "))
print(rdd2.collect()) # ['hello', 'world', 'py', 'spark']
| 区别 | map vs flatmap |
|---|---|
map 返回 [[x], [y]] | 返回嵌套列表 |
flatmap 返回 [x, y] | 展开为单层列表 |
适用场景:文本分词、多行拆分、列表合并
4.filter(t)→t:条件过滤
作用:根据返回
true/false过滤元素
rdd = sc.parallelize([1,2,3,4,5,6]) rdd2 = rdd.filter(lambda x: x % 2 == 0) print(rdd2.collect()) # [2, 4, 6]
适用场景:筛选城市、过滤商品类别、去除空值
5.distinct():去重
作用:返回去重后的集合(全局去重)
rdd = sc.parallelize([1,2,2,3,4,4,5]) rdd2 = rdd.distinct() print(rdd2.collect()) # [1, 2, 3, 4, 5]
注意:distinct() 耗时高,会 shuffle 所有数据!慎用于大数据集!
6.sortby(keyfunc, ascending):排序
作用:按指定规则排序
rdd = sc.parallelize([1,5,3,2,4]) rdd2 = rdd.sortby(lambda x: x, ascending=false) print(rdd2.collect()) # [5, 4, 3, 2, 1]
适用场景:销售排名、分数排序、top n 推荐
7.reducebykey(func):分组聚合(键值对专属)
前提:rdd 数据必须是
(k, v)元组形式
rdd = sc.parallelize([("a",1),("a",2),("b",3),("b",4)])
rdd2 = rdd.reducebykey(lambda a, b: a + b)
print(rdd2.collect()) # [('a', 3), ('b', 7)]
| 要求 | 说明 |
|---|---|
必须是 (k, v) | 否则报错 |
func(v,v) → v | 两个 value 聚合出一个 value |
| 本地预聚合 | 减少网络传输,效率极高 |
适用场景:统计商品销量、城市销售额、词频统计
四、修改 rdd 分区的 3 种方法
| 方法 | 说明 | 代码示例 |
|---|---|---|
set("spark.default.parallelism", "1") | 设置全局并行度 | conf.set("spark.default.parallelism", "1") |
numslices=1 | parallelize 时指定分区数 | sc.parallelize([1,2,3], 1) |
repartition(n) | 重新分区(常用于调优) | rdd.repartition(2) |
建议:小数据集用
numslices=1避免创建过多任务。
五、重难点攻克:如何修复msvcr120.dll缺失问题?💥
报错信息:
由于找不到 msvcr120.dll,无法继续执行代码
🔍 根本原因:
- spark 调用
hadoop.dll会依赖 vc++ 2013 运行时。 path中包含e:\app\hadoop-3.4.2\bin→ 启动 native io → 加载 dll → 找不到函数 → 报错。
终极解决方案:
修复 msvcr120.dll 可以用联想的电脑异常修复直接修复
六、案例实战:综合数据分析
案例 1:城市销量排名(p09_案例2.py)
需求:
- 读取
sales.txt文件(json 格式) - 统计每个城市销售额从大到小排序
- 获取全部城市商品类别(去重)
- 查询“北京”有哪些商品类别(过滤 + 去重)
步骤详解:
import json
from pyspark import sparkcontext, sparkconf
import os
os.environ["pyspark_python"] = "d:\\app\\anaconda\\envs\\spark_env\\python.exe"
os.environ['pyspark_timeout'] = '600'
os.environ['pyspark_driver_timeout'] = '600'
conf = sparkconf().setmaster("local[*]").setappname("sales_analysis")
sc = sparkcontext(conf=conf)
# 1. 读取文件并转为字典
file_rdd = sc.textfile("d:\\python_testdata\\sales.txt")
dict_rdd = file_rdd.map(lambda x: json.loads(x.rstrip().rstrip(',')))
# 2. 各城市销售额排名
city_money = dict_rdd.map(lambda x: (x['areaname'], int(x['money'])))
city_total = city_money.reducebykey(lambda a, b: a + b)
city_rank = city_total.sortby(lambda x: x[1], ascending=false)
print("各城市销售额排名:")
print(city_rank.collect())
# 3. 全部城市有哪些商品类别(去重)
categories = dict_rdd.map(lambda x: x['category'])
unique_categories = categories.distinct()
print("全部商品类别:")
print(unique_categories.collect())
# 4. 北京市的商品类别
beijing_rdd = dict_rdd.filter(lambda x: x['areaname'] == '北京')
beijing_cats = beijing_rdd.map(lambda x: x['category']).distinct()
print("北京市售卖的商品类别:")
print(beijing_cats.collect())
sc.stop()知识点总结:
json.loads():解析 json 字符串map:提取字段reducebykey:聚合销售额sortby:排序filter+distinct:组合过滤去重
案例 2:词频统计(p05_pyspark案例.py)
需求:统计words.txt中每个词出现次数
from pyspark import sparkcontext, sparkconf
import os
os.environ["pyspark_python"] = "d:\\app\\anaconda\\envs\\spark_env\\python.exe"
os.environ['pyspark_timeout'] = '600'
conf = sparkconf().setmaster("local[*]").setappname("word_count")
sc = sparkcontext(conf=conf)
rdd = sc.textfile("d:\\python_testdata\\words.txt")
words = rdd.flatmap(lambda x: x.split(" "))
word_pairs = words.map(lambda x: (x, 1))
word_count = word_pairs.reducebykey(lambda a, b: a + b)
print("词频统计结果:")
print(word_count.collect())
sc.stop()知识点:
flatmap分词map→(word, 1)reducebykey聚合- 典型的 mapreduce 模型
七、总结与建议
| 项目 | 推荐做法 |
|---|---|
| 数据输出 | ✅ 使用 collect() + open() 写文件,避免 saveastextfile() |
| 环境配置 | ✅ 设置 pyspark_timeout + spark.hadoop.io.native.io.enabled=false |
| 修复 dll 错误 | ✅ 删除 path 中 hadoop/bin,不加载 native io |
| 超时问题 | ✅ 设置 pyspark_timeout=600,防止任务中断 |
| 小数据集 | ✅ 用 numslices=1 控制分区 |
| 大数据集 | ✅ 用 repartition() 调优 |
到此这篇关于python pyspark 核心实操入门案例指南的文章就介绍到这了,更多相关python pyspark 入门内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论