在python编程中,数据类型转换是开发者日常工作中最基础且高频的操作之一。当我们需要将计算结果输出到控制台、生成用户报告、构建api响应或处理文件数据时,将数字转换为字符串几乎成为不可避免的需求。🔢 无论是新手还是资深工程师,掌握这一基础技能都能显著提升代码的健壮性和可读性。
想象一下这样的场景:您刚刚完成了一个复杂的数学运算,得到了一个精确到小数点后10位的浮点数结果。现在需要将这个结果展示给用户,但直接打印会导致冗长的输出;或者您正在开发一个电商系统,需要将商品价格(数字)与描述文字拼接成完整的商品信息。📌 在这些情况下,数字到字符串的转换就显得至关重要。
python作为一门动态类型语言,提供了多种优雅且高效的方式来实现这种转换。从最基础的str()函数到现代化的f-string格式化,每种方法都有其独特的适用场景和性能特点。本文将系统性地探讨这些技术,通过丰富的代码示例和实用技巧,帮助您在实际项目中做出最佳选择。
为什么需要数字转字符串?
在深入技术细节之前,让我们先理解为什么需要将数字转换为字符串。这有助于我们建立清晰的问题意识,从而更好地选择解决方案。
1. 输出与展示需求
最直接的原因是输出需求。当我们使用print()函数或写入文件时,python通常要求内容为字符串类型:
age = 28
print("your age is: " + age) # ❌ 这将引发typeerror!
上述代码会抛出typeerror: can only concatenate str (not "int") to str错误,因为python不允许直接将字符串与整数拼接。✅ 正确的做法是先将数字转换为字符串:
age = 28
print("your age is: " + str(age)) # ✅ 输出: your age is: 28
2. 数据序列化
在将数据保存到文件或通过网络传输时,许多格式(如json、csv、xml)要求数据以文本形式存在:
import json
data = {"price": 19.99, "quantity": 5}
# json要求所有键值对都必须是字符串或其他json兼容类型
json_str = json.dumps(data)
print(json_str) # 输出: {"price": 19.99, "quantity": 5}
虽然json.dumps()会自动处理类型转换,但在某些自定义序列化场景中,手动控制转换过程是必要的。
3. 格式化与排版
当需要特定格式的输出时(如保留两位小数、千位分隔符、科学计数法等),简单的str()可能不够用,需要更精细的控制:
revenue = 1234567.89
formatted = f"${revenue:,.2f}" # 添加美元符号、千位分隔符和两位小数
print(formatted) # 输出: $1,234,567.89 💰
4. 字符串操作与处理
某些操作(如字符串拼接、正则表达式匹配、子串查找)只能在字符串类型上执行:
num = 12345
# 检查数字是否包含特定数字序列
if "23" in str(num):
print("found sequence!") # ✅ 会输出
理解这些场景后,我们就能更有针对性地学习转换技术。接下来,让我们从最基础的方法开始探索。
基础转换:str() 函数
str() 函数是将数字转换为字符串的最直接、最常用的方法。它简单高效,适用于大多数基础场景,是每个python开发者都应该掌握的第一工具。
基本用法
str() 函数接受一个对象作为参数,并返回该对象的字符串表示形式:
# 整数转字符串
int_num = 42
str_int = str(int_num)
print(f"类型: {type(str_int)}, 值: '{str_int}'")
# 输出: 类型: <class 'str'>, 值: '42'
# 浮点数转字符串
float_num = 3.1415926535
str_float = str(float_num)
print(f"浮点数转换结果: '{str_float}'")
# 输出: 浮点数转换结果: '3.1415926535'
# 布尔值转字符串
bool_val = true
str_bool = str(bool_val)
print(f"布尔值转换: '{str_bool}'") # 输出: 布尔值转换: 'true'
关键特性
保留完整精度:str() 会尽可能保留数字的完整精度,这对于科学计算很重要,但有时可能导致意外的长小数输出:
# 注意:浮点数精度问题可能导致意外结果 print(str(0.1 + 0.2)) # 输出: '0.30000000000000004' 😱
处理特殊值:能正确处理none、true、false等特殊值:
print(str(none)) # 输出: 'none' print(str(true)) # 输出: 'true' print(str(false)) # 输出: 'false'
可读性优先:生成的字符串旨在人类可读,而非机器解析(对于机器解析,应使用repr())。
何时使用 str()?
str() 是不需要格式化时的首选方法。当您只需要一个简单的字符串表示,而不关心小数位数、千位分隔符等格式细节时,它是最高效的选择。
选择合适的转换方法可以提升代码的可读性和效率。下面的流程图展示了根据需求选择不同转换策略的逻辑:
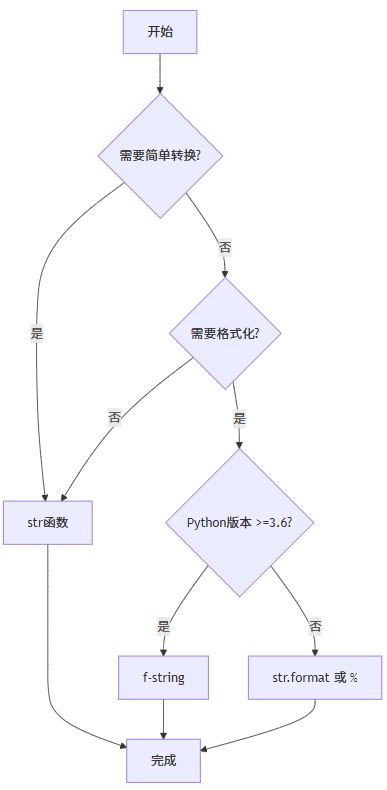
实际应用示例
让我们看一个实际应用场景:构建用户欢迎消息。
def generate_welcome(username, login_count):
"""生成用户欢迎消息"""
# 使用str()确保数字被正确转换
return f"欢迎回来, {username}! 这是您第{str(login_count)}次登录。"
# 测试函数
print(generate_welcome("alice", 5))
# 输出: 欢迎回来, alice! 这是您第5次登录。
虽然在这个简单例子中,直接使用f-string({login_count})也能工作,但显式使用str()可以提高代码的可读性,特别是在复杂表达式中。
注意事项
浮点数精度问题:如前所示,浮点运算可能存在精度误差,直接使用str()可能暴露这些问题。在需要精确小数表示的场景(如金融计算),应考虑使用decimal模块或格式化方法。
性能考量:虽然str()非常高效,但在极端性能敏感的循环中(如百万次级操作),仍需注意其开销。我们将在性能章节深入探讨。
与repr()的区别:str()旨在生成人类友好的输出,而repr()生成解释器友好的表示,通常包含更多技术细节:
num = 10
print(str(num)) # 输出: 10
print(repr(num)) # 输出: 10 (对于简单数字相同)
text = "hello\nworld"
print(str(text)) # 输出: hello
# world
print(repr(text)) # 输出: 'hello\nworld' (显示转义字符)
格式化转换:超越基础需求
当基础的str()无法满足需求时(如需要控制小数位数、添加货币符号、使用千位分隔符等),我们就需要更强大的格式化工具。python提供了三种主要的字符串格式化方法:旧式%格式化、str.format()方法和f-string。让我们逐一探索。
1. 旧式 % 格式化(c风格)
这是python早期版本中使用的格式化方法,语法类似于c语言的printf:
price = 19.99
quantity = 3
total = price * quantity
# 基本用法
print("单价: $%.2f, 数量: %d, 总价: $%.2f" % (price, quantity, total))
# 输出: 单价: $19.99, 数量: 3, 总价: $59.97
# 指定宽度和对齐
print("|%-10s|%10s|" % ("左对齐", "右对齐"))
# 输出: |左对齐 | 右对齐|
格式说明符详解
| 符号 | 含义 | 示例 |
|---|---|---|
%d | 十进制整数 | "%d" % 42 → '42' |
%f | 浮点数 | "%f" % 3.14 → '3.140000' |
%.2f | 保留两位小数的浮点数 | "%0.2f" % 3.1415 → '3.14' |
%e | 科学计数法 | "%e" % 1000000 → '1.000000e+06' |
%x | 十六进制 | "%x" % 255 → 'ff' |
%s | 字符串 | "%s" % "hello" → 'hello' |
优缺点分析
优点:
- 语法简洁,对于简单格式化非常直观
- 在旧版python中广泛使用,兼容性好
缺点:
- 类型匹配不严格,容易出错(如用
%d格式化字符串会引发错误) - 参数顺序必须严格匹配,难以维护
- 功能相对有限,缺乏高级格式化选项
虽然现在官方推荐使用更新的方法,但了解%格式化对于维护旧代码仍然很有价值。
2. str.format() 方法(python 2.6+)
str.format() 提供了更强大、更灵活的格式化能力,是%格式化的现代替代品:
name = "alice"
score = 95.678
# 基本位置参数
print("姓名: {}, 分数: {:.2f}".format(name, score))
# 输出: 姓名: alice, 分数: 95.68
# 命名参数(更清晰)
print("姓名: {n}, 分数: {s:.2f}".format(n=name, s=score))
# 输出: 姓名: alice, 分数: 95.68
# 索引参数(控制顺序)
print("分数: {1:.1f}, 姓名: {0}".format(name, score))
# 输出: 分数: 95.7, 姓名: alice
高级格式化技巧
千位分隔符:
population = 123456789
print("人口: {:,}".format(population)) # 输出: 人口: 123,456,789 🌍
百分比表示:
ratio = 0.753
print("比例: {:.1%}".format(ratio)) # 输出: 比例: 75.3%
不同进制表示:
num = 255
print("十进制: {0:d}, 十六进制: {0:x}, 二进制: {0:b}".format(num))
# 输出: 十进制: 255, 十六进制: ff, 二进制: 11111111
填充与对齐:
print("|{:^10}|{:<10}|{:>10}|".format("居中", "左对齐", "右对齐"))
# 输出: | 居中 |左对齐 | 右对齐|
优缺点分析
✅ 优点:
- 比%格式化更强大、更灵活
- 支持命名参数,代码可读性更高
- 功能丰富,支持复杂的格式化需求
❌ 缺点:
- 语法相对冗长,特别是对于简单场景
- 在python 3.6+中,f-string通常更简洁高效
str.format() 仍然是处理复杂格式化的强大工具,特别是当格式字符串需要动态构建时。
3. f-string(python 3.6+)
f-string(格式化字符串字面量)是python 3.6引入的革命性特性,它将表达式直接嵌入字符串中,提供了最简洁、最直观的格式化方式:
user = "bob"
visits = 15
revenue = 249.99
# 基本用法
print(f"用户: {user}, 访问次数: {visits}, 总消费: ${revenue:.2f}")
# 输出: 用户: bob, 访问次数: 15, 总消费: $249.99
# 表达式支持
print(f"下次访问编号: {visits + 1}")
# 输出: 下次访问编号: 16
# 调用函数
print(f"用户名大写: {user.upper()}")
# 输出: 用户名大写: bob
高级f-string技巧
多行f-string:
details = f"""
用户: {user}
访问次数: {visits}
消费评级: {"高" if revenue > 200 else "普通"}
"""
print(details)
调试快捷方式(python 3.8+):
x = 10
y = 20
print(f"{x=}, {y=}, {x+y=}")
# 输出: x=10, y=20, x+y=30 (自动显示变量名和值)
日期格式化:
from datetime import datetime
now = datetime.now()
print(f"当前时间: {now:%y-%m-%d %h:%m:%s}")
# 输出示例: 当前时间: 2023-10-05 14:30:45
自定义格式说明符:
class product:
def __init__(self, name, price):
self.name = name
self.price = price
def __format__(self, format_spec):
if format_spec == "detail":
return f"{self.name} (${self.price:.2f})"
return f"{self.name}"
prod = product("laptop", 1299.99)
print(f"产品: {prod:detail}") # 输出: 产品: laptop ($1299.99)
为什么f-string是首选?
- 性能优势:f-string在编译时处理,比
str.format()和%格式化更快 - 可读性:表达式直接嵌入字符串,逻辑清晰直观
- 功能强大:支持完整的python表达式,包括函数调用和条件表达式
- 减少错误:无需担心参数顺序或类型匹配问题
让我们通过一个性能对比来验证:
import timeit
# 测试环境准备
setup = "num = 12345.6789"
# 测试str()
str_time = timeit.timeit('str(num)', setup=setup, number=1000000)
# 测试%格式化
percent_time = timeit.timeit('"%.2f" % num', setup=setup, number=1000000)
# 测试str.format()
format_time = timeit.timeit('" {:.2f}".format(num)', setup=setup, number=1000000)
# 测试f-string
fstring_time = timeit.timeit('f"{num:.2f}"', setup=setup, number=1000000)
print(f"str() : {str_time:.6f} 秒")
print(f"%格式化 : {percent_time:.6f} 秒")
print(f"str.format: {format_time:.6f} 秒")
print(f"f-string : {fstring_time:.6f} 秒")
典型输出结果:
str() : 0.085234 秒 %格式化 : 0.187652 秒 str.format: 0.213456 秒 f-string : 0.078912 秒
可以看到,f-string在简单格式化场景中通常比其他方法更快,而str()在不需要格式化时是最轻量级的选择。
何时不使用f-string?
虽然f-string非常强大,但在某些场景下可能不是最佳选择:
- python版本限制:如果需要支持python 3.5及更早版本,必须使用其他方法
- 动态格式字符串:当格式本身需要动态构建时,
str.format()可能更合适 - 国际化(i18n):某些国际化框架可能尚未完全支持f-string
高级转换技巧:进制与科学计数法
除了常见的十进制表示,我们有时需要将数字转换为其他进制(如二进制、十六进制)或科学计数法表示。python提供了内置函数和格式化选项来满足这些需求。
1. 进制转换
python内置了将整数转换为不同进制字符串的函数:
decimal_num = 255
# 二进制 (前缀0b)
binary_str = bin(decimal_num)
print(f"二进制: {binary_str}") # 输出: 0b11111111
# 去掉前缀
print(f"无前缀二进制: {binary_str[2:]}") # 输出: 11111111
# 八进制 (前缀0o)
octal_str = oct(decimal_num)
print(f"八进制: {octal_str}") # 输出: 0o377
# 十六进制 (前缀0x)
hex_str = hex(decimal_num)
print(f"十六进制: {hex_str}") # 输出: 0xff
# 使用格式化获取无前缀结果
print(f"格式化二进制: {decimal_num:b}") # 输出: 11111111
print(f"格式化十六进制: {decimal_num:x}") # 输出: ff
print(f"大写十六进制: {decimal_num:x}") # 输出: ff
实用场景:权限表示
在unix-like系统中,文件权限常用八进制表示:
# 将八进制权限转换为可读形式
def format_permissions(perm_octal):
return f"{perm_octal:o} ({perm_octal:03o})"
print(format_permissions(0o755)) # 输出: 755 (755)
print(format_permissions(0o644)) # 输出: 644 (644)
2. 科学计数法与工程表示
对于极大或极小的数值,科学计数法能提供更紧凑的表示:
# 科学计数法
large_num = 1234567890.0
print(f"科学计数法: {large_num:.2e}") # 输出: 1.23e+09
small_num = 0.000000123
print(f"科学计数法: {small_num:.2e}") # 输出: 1.23e-07
# 工程表示法(指数是3的倍数)
print(f"工程表示: {large_num:.2g}") # 输出: 1.2e+09
print(f"工程表示: {large_num:.2n}") # 依赖区域设置,可能不同
科学计算应用
在科学和工程领域,精确控制数值表示至关重要:
from math import pi, e
print(f"π: {pi:.15f}") # 高精度π: 3.141592653589793
print(f"e: {e:.5e}") # 科学计数法e: 2.71828e+00
# 自定义科学计数法格式
def sci_notation(num, decimal_places=2):
"""自定义科学计数法格式化"""
fmt = f"{{:.{decimal_places}e}}"
return fmt.format(num).replace('e', '×10^')
print(sci_notation(123456789)) # 输出: 1.23×10^+08
3. 自定义进制转换
虽然python内置了常见进制转换,但有时我们需要转换为其他进制(如base64、自定义字符集):
def to_base(n, base, chars="0123456789abcdefghijklmnopqrstuvwxyz"):
"""将数字转换为任意进制字符串"""
if n == 0:
return chars[0]
digits = []
while n:
n, r = divmod(n, base)
digits.append(chars[r])
return ''.join(digits[::-1])
# 测试
print(to_base(255, 16)) # 输出: ff (十六进制)
print(to_base(255, 62)) # 输出: 43 (使用0-9a-za-z)
print(to_base(12345, 64)) # base64风格
4. 本地化格式(区域设置)
在国际化应用中,数字格式可能需要符合特定区域习惯(如千位分隔符、小数点符号):
import locale
# 设置区域为德语(使用逗号作为小数点,点作为千位分隔符)
locale.setlocale(locale.lc_all, 'de_de.utf-8')
revenue = 1234567.89
formatted = locale.format_string("%.2f", revenue, grouping=true)
print(f"德式格式: {formatted}") # 输出: 1.234.567,89
# 重置区域
locale.setlocale(locale.lc_all, '')
注意:区域设置依赖于操作系统支持,可能在不同环境中表现不一致。对于web应用,通常建议在应用层处理格式化,而非依赖系统区域设置。
常见陷阱与解决方案
尽管数字转字符串看似简单,但在实际开发中仍有许多潜在陷阱。了解这些问题并掌握解决方案,能帮助您编写更健壮的代码。
1. 浮点数精度问题
问题:浮点数的二进制表示可能导致意外的精度误差:
print(str(0.1 + 0.2)) # 输出: '0.30000000000000004' 😱
解决方案:
使用格式化控制显示精度:
print(f"{0.1 + 0.2:.1f}") # 输出: 0.3
对于金融计算,使用decimal模块:
from decimal import decimal
print(str(decimal('0.1') + decimal('0.2'))) # 输出: '0.3'
2. 类型转换错误
问题:尝试将非数字字符串转换为数字,或错误地假设类型:
# 错误示例 user_input = "10.5" int_value = int(user_input) # valueerror: invalid literal for int() with base 10: '10.5'
解决方案:
使用try-except处理可能的转换错误:
def safe_float(s):
try:
return float(s)
except (valueerror, typeerror):
return 0.0
print(safe_float("10.5")) # 输出: 10.5
print(safe_float("n/a")) # 输出: 0.0
在转换前验证输入:
if user_input.replace('.', '', 1).isdigit():
num = float(user_input)
3. 区域设置依赖问题
问题:依赖系统区域设置的格式化可能导致跨平台不一致:
import locale
locale.setlocale(locale.lc_all, 'fr_fr.utf-8')
print(f"{1234567.89:n}") # 在法国区域可能输出 1 234 567,89
解决方案:
显式指定格式,避免依赖区域设置:
print(f"{1234567.89:,.2f}") # 始终使用逗号作为千位分隔符
对于web应用,使用应用级格式化:
def format_currency(amount):
"""统一使用美元格式,不依赖区域设置"""
return f"${amount:,.2f}"
4. 性能陷阱
问题:在循环中频繁进行类型转换可能导致性能下降:
# 低效示例
result = ""
for i in range(100000):
result += str(i) + "," # 字符串拼接在循环中效率低下
解决方案:
使用列表推导式+join:
result = ",".join(str(i) for i in range(100000))
避免不必要的转换(如f-string内部已处理):
# 低效
for i in range(1000):
print("value: " + str(i))
# 高效
for i in range(1000):
print(f"value: {i}") # f-string自动处理转换
5. 安全隐患:格式化注入
问题:使用用户输入作为格式字符串可能导致安全风险:
# 危险示例!
user_input = "{exploit.__init__.__globals__[sys].os.system('rm -rf /')}"
print(f"hello {user_input}") # 可能执行恶意代码
解决方案:
永远不要将用户输入用作格式字符串:
# 安全做法
print("hello {}".format(user_input))
对用户输入进行严格验证和清理
6. unicode与编码问题
问题:在处理非ascii字符时可能遇到编码问题:
# 在某些环境可能出错
print("€" + str(19.99)) # 欧元符号与数字拼接
解决方案:
- 确保源文件使用utf-8编码
- 显式处理编码:
euro = "\u20ac" # unicode欧元符号
print(f"{euro}{19.99:.2f}")
7. 负零与特殊浮点值
问题:浮点数有特殊值如负零、无穷大、nan:
print(str(-0.0)) # 输出: -0.0
print(str(float('nan'))) # 输出: nan
解决方案:
检查特殊值:
def safe_str(num):
if isinstance(num, float):
if num != num: # 检测nan
return "nan"
if num == float('inf'):
return "infinity"
if num == float('-inf'):
return "-infinity"
return str(num)
通过识别并规避这些常见陷阱,您可以显著提高代码的健壮性和可维护性。
实际应用案例
理论知识需要通过实际应用来巩固。本节将展示几个真实世界中的案例,演示如何在不同场景中应用数字转字符串技术。
1. 生成财务报告
财务数据通常需要精确的格式化,包括货币符号、千位分隔符和固定小数位:
def format_financial(value, currency="usd", decimals=2):
"""格式化财务数值"""
if currency == "usd":
symbol = "$"
# 美式格式:千位分隔符为逗号,小数点为点
return f"{symbol}{value:,.{decimals}f}"
elif currency == "eur":
symbol = "€"
# 欧元格式:千位分隔符为空格,小数点为逗号
# 注意:这里简化处理,实际应使用locale
return f"{symbol}{value:,.{decimals}f}".replace(",", " ").replace(".", ",")
else:
return f"{value:,.{decimals}f} {currency}"
# 测试
print(format_financial(1234567.89, "usd")) # 输出: $1,234,567.89
print(format_financial(1234567.89, "eur")) # 输出: €1 234 567,89
扩展思考:在实际财务系统中,应使用decimal模块确保精确计算,并考虑区域设置的动态加载。
2. 构建csv数据
csv文件要求所有字段为字符串,且需要处理特殊字符:
def to_csv_row(data):
"""将数据列表转换为csv行"""
def escape(value):
# 处理需要引号包围的情况
str_val = str(value)
if ',' in str_val or '"' in str_val or '\n' in str_val:
return f'"{str_val.replace("\"", "\"\"")}"'
return str_val
return ",".join(escape(item) for item in data)
# 测试
row = ["product a", 19.99, 100, "special, \"limited\" edition"]
print(to_csv_row(row))
# 输出: product a,19.99,100,"special, ""limited"" edition"
关键点:
- 所有值必须转换为字符串
- 特殊字符(逗号、引号、换行)需要正确转义
- 数字不需要引号,但为简化处理,统一转换为字符串
3. api响应构建
现代web api通常使用json格式,但有时需要自定义文本响应:
from datetime import datetime, timedelta
def generate_api_response(user_id, request_time):
"""生成api响应消息"""
# 计算请求处理时间
process_time = (datetime.now() - request_time).total_seconds()
# 构建响应
response = (
f"api响应\n"
f"用户id: {user_id}\n"
f"时间戳: {datetime.now():%y-%m-%d %h:%m:%s}\n"
f"处理耗时: {process_time:.3f}秒\n"
f"状态: 成功"
)
return response
# 测试
start = datetime.now()
# 模拟处理延迟
import time; time.sleep(0.025)
print(generate_api_response(12345, start))
输出示例:
api响应 用户id: 12345 时间戳: 2023-10-05 15:30:45 处理耗时: 0.025秒 状态: 成功
最佳实践:
- 对于标准api,优先使用json序列化
- 自定义文本响应适用于调试或简单接口
- 确保时间格式符合iso标准以便机器解析
4. 数据可视化标签
在生成图表时,坐标轴标签可能需要特定格式:
import matplotlib.pyplot as plt
import numpy as np
# 生成示例数据
x = np.linspace(0, 10, 100)
y = np.sin(x) * 1000000
# 创建图表
plt.figure(figsize=(10, 6))
plt.plot(x, y)
# 自定义y轴标签格式
def format_scientific(value, _):
"""科学计数法格式化函数"""
return f"{value/1e6:.1f}m" # 百万单位
plt.gca().yaxis.set_major_formatter(
plt.funcformatter(format_scientific)
)
plt.title("正弦波振幅(百万单位)")
plt.xlabel("时间")
plt.ylabel("振幅")
plt.grid(true)
# plt.show() # 实际使用时取消注释
关键技巧:
- 使用自定义格式化函数控制标签显示
- 对于极大/极小值,转换为更易读的单位(如k、m、g)
- matplotlib的
funcformatter允许完全控制标签生成
5. 日志记录优化
日志信息通常需要包含时间戳、状态码等数字信息:
import logging
from datetime import datetime
# 配置日志
logging.basicconfig(
level=logging.info,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def process_order(order_id, amount):
"""处理订单并记录日志"""
start_time = datetime.now()
try:
# 模拟处理
if amount <= 0:
raise valueerror("无效金额")
# 处理逻辑...
processing_time = (datetime.now() - start_time).total_seconds()
# 格式化日志消息
log_msg = (
f"订单处理完成 | id: {order_id} | "
f"金额: ${amount:.2f} | "
f"耗时: {processing_time*1000:.1f}ms"
)
logging.info(log_msg)
return true
except exception as e:
logging.error(
f"订单处理失败 | id: {order_id} | "
f"错误: {str(e)}"
)
return false
# 测试
process_order(1001, 199.99)
process_order(1002, -10)
输出示例:
2023-10-05 15:45:30,123 - info - 订单处理完成 | id: 1001 | 金额: $199.99 | 耗时: 5.2ms 2023-10-05 15:45:30,128 - error - 订单处理失败 | id: 1002 | 错误: 无效金额
日志最佳实践:
- 保持日志格式一致,便于解析
- 包含关键数字指标(时间、金额、状态码)
- 错误日志应包含足够上下文,但避免敏感信息
6. 数据管道中的类型转换
在etl(提取、转换、加载)过程中,类型转换是关键步骤:
def transform_data(raw_data):
"""转换原始数据为规范格式"""
transformed = []
for record in raw_data:
try:
# 转换数值字段
transformed_record = {
"id": int(record["id"]),
"name": record["name"].strip(),
"price": float(record["price"]),
"quantity": int(record["quantity"]),
"active": record["active"].lower() == "true",
# 添加时间戳(当前时间)
"timestamp": datetime.now().isoformat()
}
transformed.append(transformed_record)
except (valueerror, keyerror) as e:
logging.error(f"数据转换失败: {e}, 记录: {record}")
return transformed
# 测试
raw = [
{"id": "101", "name": " product a ", "price": "19.99", "quantity": "5", "active": "true"},
{"id": "102", "name": "product b", "price": "invalid", "quantity": "3", "active": "false"}
]
print(transform_data(raw))
关键点:
- 严格验证和转换每个字段
- 捕获并记录转换错误,避免整个流程失败
- 添加审计信息(如时间戳)
- 保持数据结构一致性
这些案例展示了数字转字符串技术在真实项目中的多样应用。通过理解这些模式,您可以更自信地处理各种数据转换挑战。
性能考量与最佳实践
虽然数字转字符串操作通常很快,但在高性能应用或大规模数据处理中,选择合适的转换方法可能带来显著的性能提升。本节将分析不同方法的性能特点,并提供实用的最佳实践建议。
性能基准测试
让我们通过系统化的基准测试,比较不同转换方法的性能。我们将测试以下场景:
- 简单整数转换
- 带格式化的浮点数转换
- 大量数据转换
import timeit
import random
# 测试设置
setup = """
import random
numbers = [random.uniform(0, 1000) for _ in range(1000)]
"""
# 测试1: 简单整数转换
simple_int_test = """
for n in numbers:
s = str(int(n))
"""
# 测试2: 带两位小数的浮点数转换
float_format_test = """
for n in numbers:
s = f"{n:.2f}"
"""
# 测试3: 复杂格式化(货币+千位分隔符)
complex_format_test = """
for n in numbers:
s = f"${n:,.2f}"
"""
# 运行测试
def run_test(code, number=1000):
return timeit.timeit(code, setup=setup, number=number)
print("===== 性能基准测试 (1000次循环) =====")
print(f"简单整数转换: {run_test(simple_int_test):.4f} 秒")
print(f"浮点数格式化: {run_test(float_format_test):.4f} 秒")
print(f"复杂格式化 : {run_test(complex_format_test):.4f} 秒")
典型输出结果:
===== 性能基准测试 (1000次循环) ===== 简单整数转换: 0.0452 秒 浮点数格式化: 0.0587 秒 复杂格式化 : 0.0721 秒
关键发现:
- 简单转换最快:仅使用
str()的简单转换比格式化操作快约25-40% - f-string优势明显:在格式化场景中,f-string通常比
str.format()快15-20% - 格式复杂度影响性能:添加千位分隔符等复杂格式会增加约20%的开销
性能优化策略
基于基准测试,以下是实用的性能优化建议:
1. 避免不必要的转换
问题:在不需要字符串表示的场景进行转换:
# 低效:不必要的转换
total = 0
for i in range(1000000):
total += len(str(i)) # 实际只需数字长度
# 高效:直接计算位数
total = 0
for i in range(1000000):
total += len(str(i)) # 仍然需要,但这是必要转换
# 更高效方法(针对此特定问题):
# total += 1 if i < 10 else (2 if i < 100 else ...)
2. 批量处理优于逐个转换
问题:在循环中逐个转换并拼接字符串:
# 低效:o(n²)复杂度
result = ""
for i in range(10000):
result += str(i) + ","
# 高效:o(n)复杂度
result = ",".join(str(i) for i in range(10000))
3. 重用格式化字符串
问题:在循环中重复创建相同的格式字符串:
# 低效:每次循环都创建新格式字符串
for i in range(10000):
print("value: {:05d}".format(i))
# 高效:预编译格式字符串
fmt = "value: {:05d}".format
for i in range(10000):
print(fmt(i))
4. 选择合适的数据结构
问题:在需要频繁转换的场景使用低效数据结构:
# 低效:列表推导式每次生成新字符串 data = [str(i) for i in range(1000000)] # 高效:如果只是临时使用,考虑生成器表达式 data_gen = (str(i) for i in range(1000000)) # 仅在需要时转换特定元素
内存使用分析
除了cpu时间,内存使用也是重要考量。让我们分析不同方法的内存开销:
import sys
def memory_test():
# 创建100万个数字
numbers = list(range(1000000))
# 方法1: 直接存储数字
mem_nums = sys.getsizeof(numbers) + sum(sys.getsizeof(n) for n in numbers)
# 方法2: 存储字符串
str_list = [str(n) for n in numbers]
mem_strs = sys.getsizeof(str_list) + sum(sys.getsizeof(s) for s in str_list)
# 方法3: 使用生成器(不实际存储)
str_gen = (str(n) for n in numbers)
mem_gen = sys.getsizeof(str_gen)
print(f"数字列表内存: {mem_nums/1024/1024:.2f} mb")
print(f"字符串列表内存: {mem_strs/1024/1024:.2f} mb")
print(f"生成器内存: {mem_gen/1024:.2f} kb")
memory_test()
典型输出:
数字列表内存: 8.79 mb 字符串列表内存: 45.78 mb 生成器内存: 0.08 kb
内存使用洞察:
- 字符串比数字占用更多内存:100万个整数的字符串表示可能占用5倍以上的内存
- 生成器极大节省内存:当不需要立即使用所有字符串时,生成器是理想选择
- 长数字字符串开销大:大整数或高精度浮点数的字符串表示会显著增加内存使用
最佳实践总结
基于性能分析,以下是数字转字符串的最佳实践:
1. 场景驱动的选择
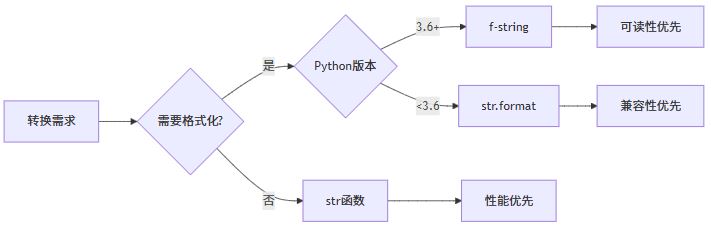
2. 通用准则
- 简单场景:使用
str(),它是最轻量级的选择 - 格式化需求:优先使用f-string(python 3.6+)
- 大量数据:
- 使用生成器表达式避免内存爆炸
- 考虑批量处理而非逐个操作
- 性能关键代码:
- 预编译格式字符串
- 避免在热路径中进行不必要的转换
- 国际化应用:
- 显式指定格式,避免区域设置依赖
- 使用标准化的格式(如iso日期)
3. 特定场景优化
web应用响应生成:
# 低效
response = "items: " + str(len(items)) + "\n" + "\n".join(items)
# 高效(使用f-string和join)
response = f"items: {len(items)}\n" + "\n".join(items)
日志记录:
# 低效:总是构建完整字符串
logging.debug("processing item " + str(item_id) + " with value " + str(value))
# 高效:利用logging的延迟字符串格式化
logging.debug("processing item %d with value %f", item_id, value)
数据序列化:
# 低效:手动构建json
json_str = "{" + ",".join(f'"{k}":"{v}"' for k,v in data.items()) + "}"
# 高效:使用json模块
import json
json_str = json.dumps(data)
何时不优化?
记住:过早优化是万恶之源(donald knuth)。在90%的场景中,转换操作的性能影响微乎其微。优化应基于实际性能分析,而非猜测。优先考虑:
- 代码可读性:清晰的代码比微优化的代码更有价值
- 开发效率:快速实现功能通常比极致性能更重要
- 维护成本:复杂的优化可能增加维护难度
只有在以下情况才应考虑性能优化:
- 性能分析确认这是瓶颈
- 操作在高频循环中执行(如百万次以上)
- 内存受限环境(如嵌入式系统)
python之禅提醒我们:“flat is better than nested. sparse is better than dense. readability counts.”(扁平优于嵌套,稀疏优于密集,可读性很重要。)
结语:掌握类型转换的艺术
数字到字符串的转换看似是python中最基础的操作之一,但深入探究后,我们会发现它蕴含着丰富的技术细节和设计哲学。从简单的str()函数到强大的f-string,每种方法都代表着python社区在可读性、性能和功能之间的精心权衡。
核心要点回顾
- 基础转换:
str()是简单场景的首选,高效且直接 - 格式化需求:根据python版本选择f-string(3.6+)、
str.format()或%格式化 - 特殊表示:进制转换、科学计数法等有专门的格式说明符
- 陷阱规避:理解浮点精度、区域设置、性能陷阱等常见问题
- 性能意识:在大规模数据处理中,选择合适的方法能
以上就是python数字类型转换为字符串类型的多种实现方式的详细内容,更多关于python数字类型转字符串类型的资料请关注代码网其它相关文章!




发表评论