作为数据库运维的核心工具,pt-query-digest 凭借强大的慢查询聚合分析能力,成为我日常排查 mysql 性能问题的 “左手剑”。本文将从安装配置、核心原理、实战场景到避坑指南,带你彻底掌握这个工具的用法,让慢查询优化不再盲目。
一、前置准备:安装与环境校验
1.1 快速安装(支持主流 linux 发行版)
pt-query-digest 是 percona toolkit 的核心组件,推荐直接安装完整工具包(自动解决依赖问题):
# 1. 下载rpm包 wget https://downloads.percona.com/downloads/percona-toolkit/3.5.4/binary/redhat/7/x86_64/percona-toolkit-3.5.4-2.el7.x86_64.rpm # 2. 安装(依赖yum自动解决) yum install percona-toolkit-3.5.4-2.el7.x86_64.rpm -y # 验证安装成功 pt-query-digest --version # 输出版本号即正常

🔔 避坑提示:centos 7 若提示依赖缺失,需先安装扩展源:
yum install epel-release -y yum install perl-dbi perl-dbd-mysql perl-time-hires -y
1.2 慢查询日志配置(关键前提)
使用前需确保 mysql 已开启慢查询日志,执行以下 sql 校验配置:
show global variables like "%slow_query%"; show global variables like "long_query_time"; show global variables like "log_output";
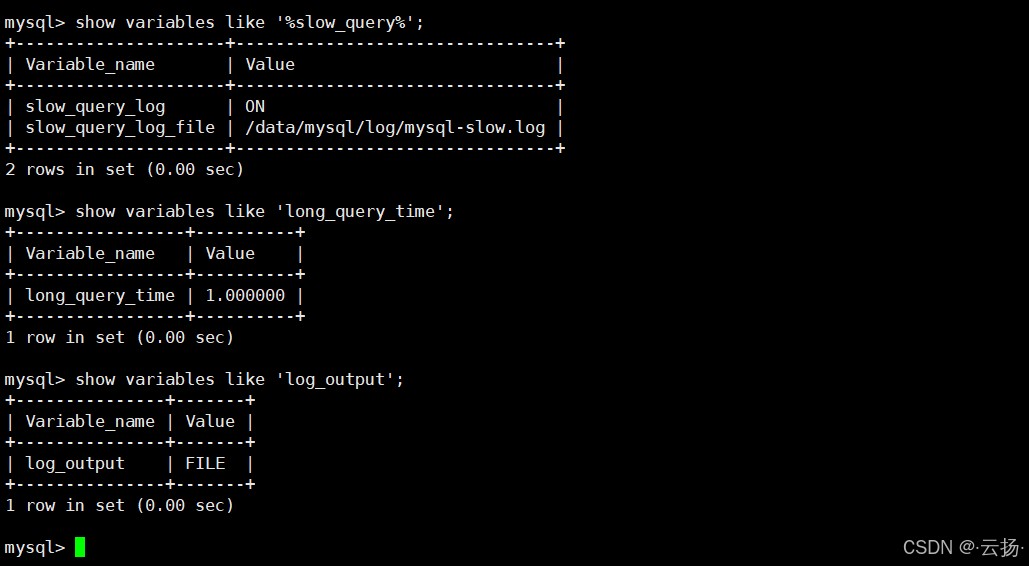
核心配置要求:
slow_query_log = on(必须开启)long_query_time ≤ 1(建议阈值设为 1 秒,默认 10 秒太宽松)log_output = file(输出为文件格式,pt-query-digest 不支持表存储)slow_query_log_file路径需确保 mysql 进程有写权限
临时生效配置(重启后失效):
set global slow_query_log = on; set global long_query_time = 1;
永久生效:修改 my.cnf 配置文件(重启 mysql):
[mysqld] slow_query_log = on slow_query_log_file = /data/mysql/log/mysql-slow.log long_query_time = 1 log_output = file
二、核心原理:sql 指纹与聚合逻辑
2.1 什么是 sql 指纹?
这是 pt-query-digest 的核心设计:将语义相同、参数不同的 sql,通过替换变量为占位符(?)生成统一模板,实现同类查询聚合。
示例:
- 原始 sql:
select * from user where id=1/select * from user where id=2 - 生成指纹:
select * from user where id=?
通过指纹聚合,能快速定位 “高频慢查询” 或 “单次耗时极长” 的核心问题,避免被海量重复 sql 淹没。
2.2 分析流程拆解
- 读取日志文件(慢查询 / binlog / general log)
- 解析 sql 语句并生成指纹
- 按总响应时间排序(默认规则)
- 计算关键指标(执行次数、平均耗时、占比等)
- 输出结构化报告
三、基础实战:慢查询分析三步法
步骤 1:生成分析报告
# 基础用法:分析慢查询日志并输出到文件 pt-query-digest /data/mysql/log/mysql-slow.log > slow_query_report.log # 进阶用法:只保留前20条关键sql,按指纹聚合 pt-query-digest --group-by fingerprint --limit 20 /data/mysql/log/mysql-slow.log > top20_slow.log
步骤 2:解读报告核心指标
打开报告文件后,重点关注 4 个模块:
| 模块 | 关键信息 | 解读要点 |
|---|---|---|
| 工具执行信息 | user time、rss | 验证工具运行正常(无报错) |
| 总体统计(overall) | total(总慢查询数)、unique(指纹数)、qps | 快速判断慢查询规模 |
| 慢查询排行(rank) | response(总耗时)、time%(占比)、calls(执行次数) | 优先优化 time% > 10% 且 单次耗时 > 500ms 的 sql |
| 单条 sql 详情 | query_time 分布、rows_examined | 定位瓶颈(全表扫描 / 锁等待) |
📌 实战技巧:报告中
# query_time distribution字段能快速判断延迟分布,若显示10s+占比高,说明存在严重性能问题。
步骤 3:落地优化
根据报告定位的 sql,优先采取以下优化手段:
- 给过滤条件字段加索引(最常用)
- 优化 join 逻辑,避免笛卡尔积
- 拆分大事务,减少锁持有时间
- 调整 sql 写法(如用 in 代替 or,避免 select *)
四、高频场景:6 个实用命令模板
场景 1:分析近 24 小时的新增慢查询
pt-query-digest --since=24h /data/mysql/log/mysql-slow.log > last24h_slow.log
场景 2:精准分析指定时间范围
pt-query-digest /data/mysql/log/mysql-slow.log \ --since '2026-03-12 08:00:00' \ --until '2026-03-12 18:00:00' \ > worktime_slow.log
场景 3:过滤特定用户的慢查询
# 分析用户maria的所有慢查询
pt-query-digest --filter '($event->{user} || "") =~ m/^maria/i' \
/data/mysql/log/mysql-slow.log > maria_slow.log场景 4:分析 binlog 中的写操作性能
# 1. 先解析binlog为文本格式 mysqlbinlog /data/mysql/binlog/mysql-bin.000031 -vv > binlog.txt # 2. 分析写操作(insert/update/delete) pt-query-digest --type=binlog binlog.txt > binlog_slow.log
场景 5:将结果存储到 mysql 长期跟踪
pt-query-digest \ --user=slowlog_rw --password=ud81gdac_a -s /tmp/mysql.sock \ --review d=slow_log,t=global_query_review \ --history d=slow_log,t=global_query_review_history \ /data/mysql/log/mysql-slow.log
场景 6:生成 mysql慢查询邮件报表(需二次开发)
# 结合golang工具生成mysql慢查询邮件报表(推荐方案) git clone https://github.com/wangtuo1224/mysql_slowlog_report.git cd mysql_slowlog_report go build ./mysql_slowlog_report --slow-log.path=/data/mysql/log/mysql-slow.log --limit=10
五、避坑指南:80% 运维会踩的 5 个坑
坑 1:分析结果为空或偏少
- 原因:日志格式不兼容(如
log_output=table导出的 csv 文件) - 解决:确保日志是标准文件格式,csv 需先转换为文本格式
坑 2:mysql 8.0 日志解析失败
- 原因:8.0 默认时间戳带微秒(
# time: 2026-03-13t10:00:00.123456),老版本工具不支持 - 解决:升级 pt-query-digest 到 3.5.0+,或临时关闭微秒输出:
[mysqld] log-slow-verbosity=standard # mysql 8.0.26+支持
坑 3:同类 sql 未聚合
- 原因:未加
--group-by fingerprint参数 - 解决:执行命令时显式指定聚合规则
坑 4:中文乱码
- 原因:pt-query-digest 默认不处理 utf-8 编码
- 解决:修改工具源码(centos 路径
/usr/bin/pt-query-digest):
# 第9行新增 use encode; # 第8188行修改 # return $json; return encode::decode_utf8($json);
坑 5:general log 分析卡死
- 原因:通用日志体积过大(记录所有操作)
- 解决:仅在排查特定问题时临时开启,分析时加时间过滤:
pt-query-digest --type=genlog --since=1h /data/mysql/log/mysql-general.log > genlog_slow.log
六、进阶技巧:自定义分析维度
6.1 计算行扫描效率(新增自定义属性)
pt-query-digest --filter 'do { my $rows_sent = $event->{rows_sent} || 0; my $rows_examined = $event->{rows_examined} || 1; $event->{row_ratio} = $rows_sent / $rows_examined; 1 }' --order-by row_ratio /data/mysql/log/mysql-slow.log > row_ratio_report.log- 解读:
row_ratio越接近 1,说明扫描效率越高(避免全表扫描)
6.2 过滤无用 sql(如 sleep 语句)
pt-query-digest --filter '($event->{query} || "" !~ m/^select sleep/i)' /data/mysql/log/mysql-slow.log > filtered_report.log6.3 结合 tcpdump 分析未记录的慢查询
# 抓包3306端口流量 tcpdump -i any port 3306 -s 65535 -w mysql.tcpdump # 分析抓包文件 pt-query-digest --type=tcpdump mysql.tcpdump > tcpdump_slow.log
总结
pt-query-digest 的核心价值在于 “聚合同类、聚焦重点”,让我们从海量 sql 中快速定位性能瓶颈。建议在日常运维中养成 “慢查询分析 - 优化 - 验证” 的闭环习惯,结合本文的场景模板和避坑指南,让 mysql 性能优化更高效。
到此这篇关于mysql pt-query-digest从安装到实战的慢查询优化实战指南的文章就介绍到这了,更多相关mysql pt-query-digest内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论