做后端开发久了,难免碰到这类刚需:用户上传word、pdf、excel、txt各种文档,后台得自动扒出文本做内容审核、全文检索或者数据库归档。要是挨个用poi、pdfbox适配格式,代码写得又碎又乱,后期维护、扩展全是坑。
本文使用 apache tika 搞定全格式解析,不用管底层解析差异,支持文件类型识别、元数据提取、格式校验这几个开发必用的高频场景,完全贴合真实业务。
一、前期准备:项目环境与核心依赖
先说明环境版本:
- jdk版本:17+
- springboot版本:3.2.5
- tika:3.2.3
在pom.xml文件引入相关依赖:
<?xml version="1.0" encoding="utf-8"?>
<project xmlns="http://maven.apache.org/pom/4.0.0" xmlns:xsi="http://www.w3.org/2001/xmlschema-instance"
xsi:schemalocation="http://maven.apache.org/pom/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- maven模型版本,固定4.0.0适配springboot3 -->
<modelversion>4.0.0</modelversion>
<!-- springboot3父依赖,统一版本管理,避免依赖冲突 -->
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>3.2.5</version>
<relativepath/>
</parent>
<!-- 项目基础信息,可根据实际业务修改 -->
<groupid>com.example</groupid>
<artifactid>springboot3-tika-demo</artifactid>
<version>0.0.1-snapshot</version>
<name>springboot3-tika-demo</name>
<description>springboot3集成apache tika文件解析实战</description>
<!-- 全局版本属性,统一管理依赖版本,方便后续升级 -->
<properties>
<java.version>17</java.version>
<tika.version>3.2.3</tika.version>
</properties>
<dependencies>
<!-- springboot web核心依赖,提供http接口、mvc等能力 -->
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-web</artifactid>
</dependency>
<!-- tika核心依赖,提供基础文件解析api -->
<dependency>
<groupid>org.apache.tika</groupid>
<artifactid>tika-core</artifactid>
<version>${tika.version}</version>
</dependency>
<!-- tika标准解析器池,覆盖office/pdf/txt/excel等主流办公格式 -->
<dependency>
<groupid>org.apache.tika</groupid>
<artifactid>tika-parsers-standard-pooled</artifactid>
<version>${tika.version}</version>
<type>pom</type>
</dependency>
<!-- apache通用工具包,简化字符串、集合、io操作 -->
<dependency>
<groupid>org.apache.commons</groupid>
<artifactid>commons-lang3</artifactid>
<version>3.20.0</version>
</dependency>
<!-- lombok注解工具,省略getter/setter/构造器,简化代码 -->
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
<optional>true</optional>
</dependency>
<!-- fastjson2,高性能json序列化/反序列化,适配接口返回 -->
<dependency>
<groupid>com.alibaba.fastjson2</groupid>
<artifactid>fastjson2</artifactid>
<version>2.0.32</version>
</dependency>
<!-- 单元测试依赖,本地调试、接口测试使用 -->
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-test</artifactid>
<scope>test</scope>
</dependency>
</dependencies>
<!-- springboot打包插件,打包可执行jar -->
<build>
<plugins>
<plugin>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-maven-plugin</artifactid>
<configuration>
<excludes>
<!-- 打包时排除lombok,减小jar包体积 -->
<exclude>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>二、实战集成:三步写完核心代码
1. 单例配置:避免重复创建实例
autodetectparser自动解析器是线程安全的,没必要每次解析都新建实例,交给spring托管单例最划算,既能节省内存开销,后续自定义解析规则、扩展配置也更方便。
import org.apache.tika.parser.autodetectparser;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
/**
* tika解析器配置类
* 作用:将autodetectparser交给spring管理单例,避免重复创建消耗资源
*/
@configuration
public class filedetectparserconfig {
/**
* 注册自动解析器bean
* autodetectparser:自动识别文件格式,无需手动指定解析器
* 线程安全,全局单例使用即可
*/
@bean
public autodetectparser detectparser() {
// 默认配置适配绝大多数场景,可自定义编码、超时、解析规则
return new autodetectparser();
}
}2. 文件解析结果对象实体类封装
新建文件信息实体类,统一封装解析文本和元数据,方便接口返回和业务层调用。
import lombok.builder;
import lombok.data;
import java.util.map;
/**
* 文件解析结果实体
* 统一封装:提取的文本内容 + 文件元数据,标准化返回格式
*/
@data
@builder
public class fileinfo {
/**
* 从文件中提取的纯文本内容
*/
private string filetext;
/**
* 文件元数据集合
* key:元数据字段名(如content-type、author、creation-date)
* value:对应字段值
*/
private map<string,object> metadata;
}3. 核心服务类:覆盖高频解析场景
封装通用文件解析方法,内置10mb缓冲区阈值,兼顾大文件解析和内存控制。
import com.example.springboot3tikademo.entity.fileinfo;
import lombok.requiredargsconstructor;
import lombok.extern.slf4j.slf4j;
import org.apache.tika.exception.tikaexception;
import org.apache.tika.metadata.metadata;
import org.apache.tika.parser.autodetectparser;
import org.apache.tika.parser.parsecontext;
import org.apache.tika.sax.bodycontenthandler;
import org.springframework.stereotype.service;
import org.xml.sax.contenthandler;
import org.xml.sax.saxexception;
import java.io.ioexception;
import java.io.inputstream;
import java.util.hashmap;
import java.util.map;
/**
* 文件解析核心业务类
* 封装统一解析逻辑,处理普通/大文件、元数据转换、异常捕获
*/
@slf4j
@service
@requiredargsconstructor
public class filedetectservice {
/**
* 注入自动解析器单例
*/
private final autodetectparser detectparser;
/**
* 统一文件解析入口
* @param inputstream 文件输入流(前端上传/本地文件均可)
* @return fileinfo 封装后的解析结果
*/
public fileinfo parsefile(inputstream inputstream) {
// 入参非空校验,防止空指针
if (inputstream == null) {
throw new illegalargumentexception("文件输入流不能为空,请检查文件上传状态");
}
try {
// 设置10mb缓冲区,平衡解析速度与内存占用,防止oom
contenthandler handler = new bodycontenthandler(10 * 1024 * 1024);
// 元数据对象:存储文件类型、作者、创建时间等属性
metadata metadata = new metadata();
// 解析上下文:用于扩展自定义解析规则、传参
parsecontext context = new parsecontext();
// 执行文件解析核心逻辑
detectparser.parse(inputstream, handler, metadata, context);
// metadata对象无法直接序列化,转为hashmap适配接口返回
map<string,object> metadatamap = new hashmap<>();
for (string name : metadata.names()){
metadatamap.put(name, metadata.get(name));
}
// 构建结果对象返回
return fileinfo.builder()
.filetext(handler.tostring())
.metadata(metadatamap)
.build();
} catch (saxexception | tikaexception | ioexception e) {
// 打印详细异常日志,方便线上排查问题
log.error("文件解析失败,异常堆栈:", e);
return null;
}
}
}4. 接口开发:场景化测试调用
编写文件上传解析接口,接收前端上传文件,调用核心服务完成解析,返回结构化json数据,方便自测和前端对接;后续可在此基础上扩展单独的文件类型校验接口。
import com.alibaba.fastjson2.jsonobject;
import com.example.springboot3tikademo.entity.fileinfo;
import com.example.springboot3tikademo.service.filedetectservice;
import lombok.requiredargsconstructor;
import lombok.extern.slf4j.slf4j;
import org.springframework.web.bind.annotation.postmapping;
import org.springframework.web.bind.annotation.requestmapping;
import org.springframework.web.bind.annotation.requestparam;
import org.springframework.web.bind.annotation.restcontroller;
import org.springframework.web.multipart.multipartfile;
import java.io.inputstream;
/**
* 文件解析接口控制器
* 对外提供http接口,对接前端文件上传与解析请求
*/
@slf4j
@restcontroller
@requestmapping("/api/file")
@requiredargsconstructor
public class filecontroller {
/**
* 注入文件解析服务
*/
private final filedetectservice filedetectservice;
/**
* 文件上传 + 全量解析接口
* @param file 前端上传的文件对象
* @return jsonobject 标准化响应结果(状态码+提示+数据)
*/
@postmapping("/parse")
public jsonobject parsefile(@requestparam("file") multipartfile file) {
// 第一步:校验文件是否为空
if (file.isempty()) {
return jsonobject.of("code", 500, "msg", "上传文件不能为空,请选择文件后重试");
}
// try-with-resources:自动关闭输入流,避免资源泄漏
try (inputstream inputstream = file.getinputstream()) {
// 调用服务层执行解析
fileinfo fileinfo = filedetectservice.parsefile(inputstream);
// 解析失败返回友好提示
if (fileinfo == null) {
return jsonobject.of("code", 500, "msg", "文件解析失败,请检查文件格式是否支持或文件是否损坏");
}
// 封装成功响应:拼接状态码、提示、文件名、解析数据
jsonobject result = jsonobject.from(fileinfo);
result.put("code", 200);
result.put("msg", "文件解析成功");
result.put("filename", file.getoriginalfilename());
return result;
} catch (exception e) {
// 打印异常日志,定位上传/解析流程问题
log.error("文件上传解析异常,文件名:{}", file.getoriginalfilename(), e);
return jsonobject.of("code", 500, "msg", "解析异常:" + e.getmessage());
}
}
}三、接口测试:验证解析效果
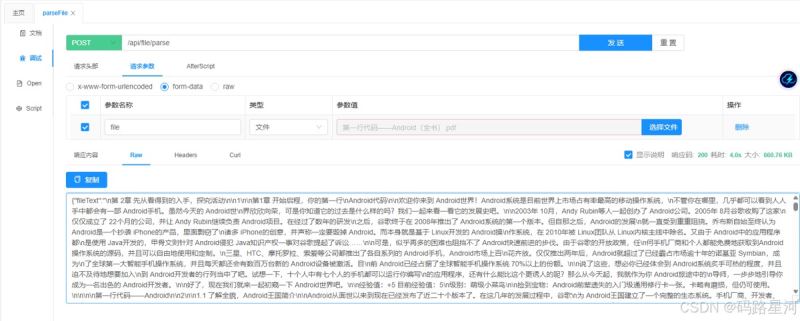
项目启动后,用postman或者接口测试工具调用:
- 请求地址:post localhost:8080/api/file/parse
- 请求方式:form-data,key设为file,选择本地文档(.doc/.docx/.pdf/.txt/.xlsx)
- 返回结果:结构化json,包含文件名、响应状态、提取文本、元数据(作者、文件类型、创建时间等)
实测主流办公格式都能正常解析,元数据完整不丢失,文本提取精准,不会出现乱码、内容截断问题。
四、常见问题与调优
1. 大文件解析报错:write limit exceeded
当前代码已设置10mb缓冲区,若需解析更大文件,直接调整bodycontenthandler数值即可;比如设置100mb阈值:new bodycontenthandler(100 * 1024 * 1024),不建议设为-1无限制,避免服务器oom。
2. pdf中文乱码
解析pdf出现中文乱码,优先排查两点:一是服务器安装对应中文字体包,二是在解析前手动指定utf-8编码,在metadata中添加配置:
// 解析前手动指定utf-8编码,解决pdf中文乱码、字符集不兼容问题 metadata.set(metadata.content_encoding, "utf-8");
3. 文件类型安全校验
严禁只靠文件名后缀判断文件类型,恶意文件篡改后缀极易绕过校验。可从元数据中提取真实mime类型,做白名单校验,拦截非法文件上传:
// 1. 从元数据获取文件真实mime类型,不依赖文件名后缀
string mimetype = (string) metadatamap.get("content-type");
// 2. 定义允许上传的文件白名单,可根据业务扩展(如excel、ppt)
list<string> allowtypes = arrays.aslist(
"application/pdf", // pdf格式
"application/msword", // doc旧版word
"application/vnd.openxmlformats-officedocument.wordprocessingml.document", // docx新版word
"text/plain" // txt纯文本
);
// 3. 白名单校验,拦截非法文件,防止恶意上传
if (!allowtypes.contains(mimetype)) {
throw new runtimeexception("不支持该文件类型,请上传pdf/word/txt格式文档");
}4. 生产性能优化
- 超大文件(100mb+)建议采用异步解析,避免接口超时阻塞主线程
- 对重复上传文件做md5缓存,复用解析结果,减少重复计算
- 配置springboot文件上传大小限制,防止恶意大文件攻击
- 文件流务必使用try-with-resources自动关闭,避免资源泄漏
五、总结
这套springboot3集成方案,配置简单,代码量小、侵入性极低,通过单例注入、标准化封装、统一解析,实现了多格式文件文本提取+元数据获取一站式搞定,完美适配内容审核、文档管理、数据录入、全文检索等业务场景。
除了基础的文档解析,apache tika还支持音视频文件元数据提取、图片文本ocr识别、压缩包内容遍历、加密文档解密等扩展能力,后续想叠加这些高阶功能,原有代码结构无需改动,直接扩展方法即可,兼容性和扩展性拉满。
以上就是springboot3使用apache tika实现多格式文件内容提取的详细内容,更多关于springboot3多格式文件内容提取的资料请关注代码网其它相关文章!






发表评论