概要
由于python是一种解释型语言,一般以*.py的方式发布、运行,源码容易被查看和修改,尤其是涉及鉴权相关的信息,不小心泄露出去就会造成信息安全风险。基于已有的实践经验,本文主要介绍:
- python项目中存量明文账号/密码的扫描;
- patch级敏感信息ci/cd拦截策略;
- python敏感模块的加密处理方法;
上述三个问题,总结实践经验,记录于此,为有需要的同学提供参考。
存量敏感信息的扫描
存量敏感信息一般分为两类:1、明文账号密码;2、明文token。在python中一般都是以字符串的形式明文写在代码里,相较于前者,后者一般长度更长、信息熵更高。在大型的python项目中,一般是多人协同开发,如果明文提交到git仓库,或者直接部署在生产环境,会导致系统安全问题且不利于系统维护。下面提供两种开源的方案(gitleaks 和 trufflehog),来扫描存量的明文账密/token。
参考文档:
https://github.com/gitleaks/gitleaks
https://zhuanlan.zhihu.com/p/672246664
https://blog.csdn.net/gitblog_00008/article/details/137004093
https://github.com/trufflesecurity/trufflehog
https://www.anquanke.com/post/id/281052#h2-0
gitleaks
gitleaks是一个开源的git仓库敏感信息扫描工具,非常适合用来检测git仓库中提交的硬编码密码、api token等,其最大的特点是:
- 与主流的git、github、gitee、gerrit、gitlab等vcs管理系统兼容较好,支持by patch扫描,并能过滤出对应的patch owner,便于定责整改;
- 支持普通文件夹扫描,扫描结果支持导出为json/csv文件;
- 官方集成了主流token(aliyun、aws、google、facebook、rsa私钥等)的扫描规则,可以直接拿来用,也支持自定义扫描规则(传入正则表达式);
- 支持基线扫描;
官方提供了几大主流平台的二进制文件,可以直接下载使用,也开源了go源码,有条件的也可以编译使用。
在使用时是可以通过分析存量明文账密/token的coding规律,提炼出一个通用的正则表达式,然后扫描整个仓库,导出明文密码列表。
如不便从官方渠道(github)下载,文末提供已经下载好的二进制文件,供有需要的兄弟拿去用。
下面提供一个使用示例:
- by patch扫描,输出信息携带patch owner,导出为json文件
–source::为git仓库路径
–report-path:为导出的敏感文件路径
–log-opts=“–since=7.days.ago”,仅分析最近7天的commit diff
gitleaks detect --source=. \
--log-opts="--since=7.days.ago" \
--report-format=json \
--report-path=leaks_report.json
- 扫描普通目录,导出为csv报告
注意:按照非git方式扫描,无法读取author信息
gitleaks detect --source="c:/my-project" \
--report-format=csv \
--report-path="secrets_report.csv" \
--verbose
- 指定自定义规则
注意:–config选项不传参数时,默认会启用常见服务的检测规则(如 aws access key、google api key、aliyun secret、ssh private key 等)。
假设自定义扫描规则的文件内容如下:
title = "custom gitleaks config"
[[rules]]
id = "aliyun-access-key-custom"
description = "detect aliyun access key"
regex = '''(ltai[0-9a-za-z]{20})'''
secretgroup = 1
entropy = 3.0
keywords = ["ltai"]
[[rules]]
id = "private-key-custom"
description = "detect rsa/dsa private key"
regex = '''-----begin (rsa|dsa|ec) private key-----'''
keywords = ["begin private key"]
自定义扫描规则保存到toml文件中,
gitleaks detect --source=. \
--config=custom-config.toml \
--report-path=custom_rules_report.json
- 指定基线扫描,比较适合用在大型项目的检测逻辑中
# 先生成基线文件
gitleaks detect --source=. \
--report-format=json \
--report-path=baseline.json
# 后续扫描时基于该基线,只扫描增量的新漏洞即可
gitleaks detect --source=. \
--baseline-path=baseline.json \
--report-path=new_leaks.json
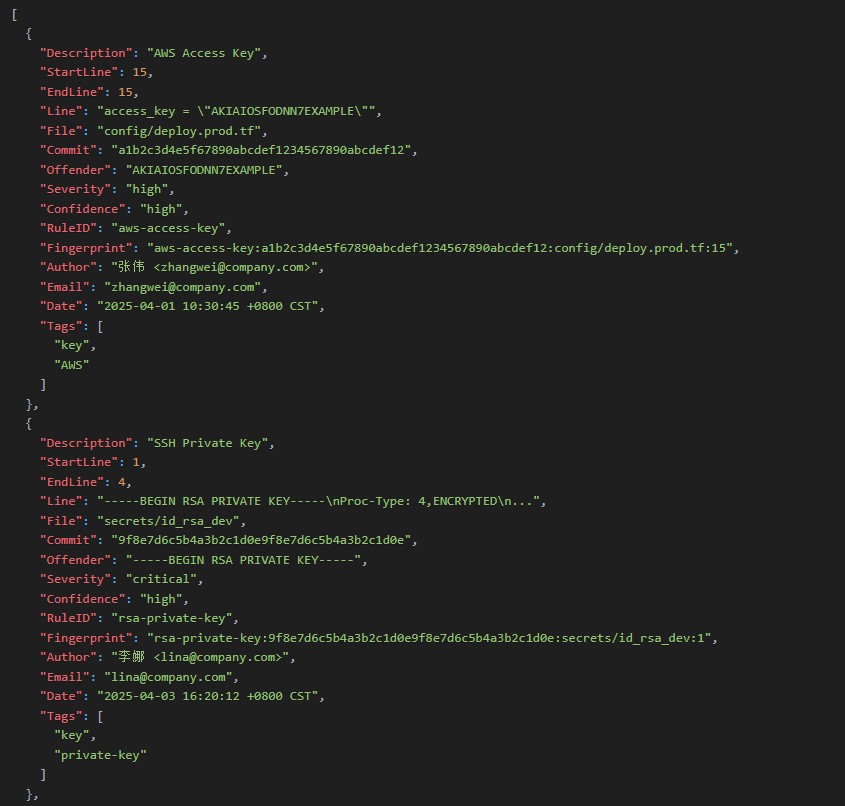
扫描出来的json文件效果:
trufflehog
trufflehog是一个开源的python项目,功能与gitleaks类似,主要特点或相对的gitleaks的区别是:
- 可以直接pip安装使用,需要注意的是,如果python版本过低,pip安装trufflehog可能存在版本兼容性问题,不推荐使用,更推荐直接用编译好的二进制文件做检查;
- 基于“熵值 + 正则”识别潜在密钥,并支持主动验证(verification) 是否真实有效(如调用 api 测试 key 是否可用);
- 强大的误报过滤能力:通过网络请求验证发现的密钥是否“可被使用”,大幅降低误报率;
- 与gitleaks类似,它也支持通过配置文件添加自定义 detector(需 protobuf id 或名称),但不如 gitleaks 的 toml 规则直观,例如设置最小的匹配长度,忽略特定的文件/目录;
- trufflehog更适合devops系统,能直接接入到ci/cd业务流,非常适合patch级的检查;
相对于gitleaks,trufflehog更适合集成到ci/cd系统中,做增量式的敏感信息检查,但是存量的明文账密检查,从使用效果上来看,gitleaks更胜一筹。不过需要注意的是:有些基于gerrit的vcs,在每笔patch中会打上change-id,此时这种hash字符串,也会被trufflehog检测出来,因此需要维护一个特定的白名单,避免检测误报。
下面提供一个简单的使用示例:
扫描本地项目目录中的敏感信息:
trufflehog filesystem ./my-project \
--json \
--only-verified
输出效果:
{
"sourcemetadata": {
"data": { "file": "deploy.sh", "line": 10 },
"encoding": "plain"
},
"detectorname": "aws",
"verified": true,
"raw": "akiaiosfodnn7example",
"redacted": "akiaiosfodnn7exxx",
"extradata": {"email": ""}
}
ci/cd前置拦截
存量的密码扫描只能解决历史遗留的漏洞,实际在项目开发中,治理完存量的硬编码鉴权信息,一般需要在patch合入远程仓库前,在ci/cd流程中提前拦截,未雨绸缪。这里也提供下面两个思路。
传统扫描策略
传统的扫描策略是指,扫描patch中所有的文本文件,借助开源工具或自定义的扫描规则拦截高信息熵字段和潜在的硬编码字符。这种拦截方式能直接借助上述的开源工具的能力来实施,但是缺陷也是很明显,这种拦截机制比较“死板”,如果有人特地提交了不能被正则表达式匹配到的明文账密(例如,把password 变量名全部改成candy,正则表达式就匹配不到password相关的字段),此时就会漏检。即这种拦截规则不能智能化地“进化”,需要定期维护拦截规则。
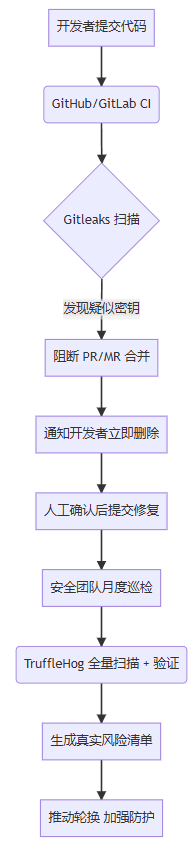
下面提供一份gitleaks+trufflehog协同部署在devops系统的业务流:
ai大模型拦截策略
在自然语言处理(nlp)领域,大型语言模型(large language models, llms)经过多年的发展与优化,已在文本理解、语义分析和敏感信息识别等方面展现出高度的成熟性与可靠性。随着企业对代码安全、数据合规及隐私保护要求的不断提升,传统的基于规则或正则表达式的敏感信息检测手段在面对复杂上下文、模糊命名模式或非标准格式时逐渐显现出局限性。因此,引入ai能力辅助进行增量式敏感信息检测,尤其是针对明文账号密码等高风险内容的识别,已成为一种具有前瞻性和实用价值的技术路径。
相较于依赖公开云服务的大模型应用,私有化部署的ai大模型更适用于此类安全敏感场景。原因在于:其一,私有部署可有效避免源代码、配置文件等内容上传至第三方平台所带来的数据泄露风险;其二,企业可在受控环境中对模型进行定制化微调,使其更精准地适应内部命名规范、技术栈特征和业务语境,从而提升检测准确率;其三,私有模型支持离线运行,满足金融、政务、能源等高合规要求行业的监管需求。
值得注意的是,大模型输出通常具有一定的开放性和不确定性,若仅以“是否存在账密”作为自由回答,可能导致结果难以结构化处理,影响后续自动化流程的判断。为此,在调用ai接口时,应通过精心设计的提示词工程(prompt engineering) 显式约束输出格式。推荐方式包括:要求模型返回分类级别判定(如“高/中/低”风险),或提供概率化评分(如“95% 可能包含明文密码”),以便集成系统依据预设阈值做出拦截、告警或放行决策。
示例:标准化ai调用请求与响应
请求 prompt:
请分析以下代码片段,判断其中是否可能包含明文账号或密码信息。请仅回答一个json对象,字段为
risk_level(取值:“high”, “medium”, “low”)和confidence_score(0.0~1.0之间的浮点数)。不要解释。db.connect("jdbc:mysql://localhost:3306/prod", "admin", "p@ssw0rd!2024")
ai 模型返回:
{
"risk_level": "high",
"confidence_score": 0.98
}
该结构化输出可被ci/cd流水线直接解析,触发高风险阻断策略,实现与devops流程的无缝集成。综上所述,结合私有化大模型与规范化输出机制,能够构建更加智能、安全且可操作的敏感信息防控体系。
明文密码加密处理
明文密码加密处理一般有两种:
- 把python脚本编译成二进制文件(例如 pyinstaller/cython 等);
- 使用python源码混淆/加密工具(例如 pyarmor/pyminifier 等);
python脚本编译成二进制
pyinstaller和cython都能生成“不可读”的产物,二者均可跨平台使用,且打包/编译后可以隐藏源码发布,但其设计目标、实现机制和适用场景有明显区别,对比如下:
| 特性 | pyinstaller | cython |
|---|---|---|
| 主要使用场景 | 打包整个python应用为独立的可执行文件 | 将python代码编译为c扩展模块(.so/.pyd) |
| 能否支持模块化导入 | 否,无法被其他python脚本 import | 是,可以作为独立的module被import |
| 性能提升 | 否,微乎其微,打包产物较臃肿 | 打包产物精简,运行性能接近c级别 |
总的来说,pyinstaller适合发布一个“黑盒应用”,与其功能类似的其他第三方模块还有 cx_freeze/py2exe/py2app/nuitka等,这些或多或少能弥补pyinstaller打包产物过于笨重的问题。相对pyinstaller,这里更推荐使用cython将包含秘钥、核心算法的敏感源码转换为c并编译成原生模块来使用。下面提供一个cython的使用示例:
创建一个包含敏感信息的模块:
# _crypto.pyx
def decrypt_data(char[:] encrypted_data):
# 模拟解密逻辑(实际可用 aes 等)
result = ""
for c in encrypted_data:
result += chr(c ^ 42)
return result
编写setup.py:
# setup.py
from setuptools import setup
from cython.build import cythonize
setup(
ext_modules = cythonize("_crypto.pyx", compiler_directives={'language_level': "3"})
)
编译 python setup.py build_ext --inplace
生成 _crypto.cpython-xxx.so或 _crypto.pyd,在其他模块中如果想使用此模块,直接import即可,如:
from _crypto import decrypt_data plain_text = decrypt_data(b'encrypted_data')
发布时只需发布.so/.pyd即可实现安全调用的效果。
当然也可以将pyinstaller和cython结合使用:
[普通模块] → import → [cython 加密模块] → 打包 → [pyinstaller 可执行文件]
python源码混淆/加密(pyarmor/pyminifier)
pyarmor
pyarmor 是目前 python 领域中最成熟、功能最全面的源码保护工具之一。它不仅仅是一个“混淆器”,更是一套完整的代码加密 + 运行时保护 + 授权控制体系。其原理是将 .py 文件编译为加密的字节码,并生成一个运行时解密的包装层。真正的逻辑只有在运行时才会被动态还原,且原始代码不会以明文形式存在于磁盘上。主要特点:
- 支持函数级、模块机代码加密;
- 可绑定机器码(license控制),防止非法复制;
- 支持打包后的脚本防调试、防反编译;
pyarmor 的基础混淆和加密功能是免费的,可以通过 pip install pyarmor-core 安装使用,但是平台授权、动态许可证、更强的混淆策略则需要购买商业版本。
使用方法:pyarmor obfuscate --output dist/ myscript.py,生成的 dist/ 目录中包含加密后的脚本和运行所需的 pyarmor_runtime,部署时需一并发布。
相比 pyarmor 的“重装防护”,pyminifier 更像是一个“代码美化反向操作工具”。它的主要目标不是安全加密,而是通过压缩、重命名、删除注释等方式让代码变得难以阅读。主要特点:
- 删除空格、注释、文档字符串;
- 将变量名、函数名替换为单个字母(如 a, b, c);
- 支持简单的控制流扁平化(需配合其他库);
- 纯 python 实现,安装简单;
pyminifier
pyminifier完全开源免费,可直接pip install pyminifier安装,比较适合以下情况:
- 对安全性要求不高,仅希望“不让别人一眼看懂”代码
- 用于小型脚本、自动化工具的简易保护
- 作为 ci/cd 流程中的轻量混淆步骤
需要注意的是,pyminifier 生成的代码仍然是标准 python,只要有经验的人稍加分析就能还原逻辑,因此不能用于高安全场景。
除了 pyarmor 和 pyminifier,还有一些工具也提供了不同程度的代码保护能力,列出其核心功能供参考:
- dummy_py:通过插入无意义代码、改变控制流结构来增加反编译难度,属于“干扰型”混淆。
- python-obfuscator:一款新兴的混淆工具,支持变量重命名、字符串加密、代码打乱等功能,界面友好,适合初学
- bytecodeassembler:直接操作字节码层面的工具,技术门槛高,但防护更强,常用于研究或高级定制场景。
总结
本文简单介绍了python中明文账密的扫描、拦截和加密方法,旨在解决python项目开发过程中的信息安全、规范性问题。如果追求的是真正意义上的代码保护,尤其是要交付给外部客户或涉及商业机密,那么 pyarmor 是首选。如果只是想做一个“看得不太清楚”的版本,比如用于内部小工具防窥探,或者想减少脚本体积,那 pyminifier 就足够了,而且免费、轻便、易集成。对于极高敏感逻辑,建议结合 cython 编译核心模块 + pyarmor 加密部署 + 服务器端验证 的多重策略,才能构建真正可靠的防护体系。
到此这篇关于python源码中明文账密的扫描、拦截与加密处理的文章就介绍到这了,更多相关python源码明文账密处理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论