一、什么是缓存雪崩?
缓存雪崩(cache avalanche) 是指在某一时刻,大量缓存 key 同时失效,导致所有请求穿透到后端数据库,瞬间压垮数据库服务,进而引发整个系统雪崩式崩溃的现象。
典型场景
- 批量缓存设置相同 ttl(如
expire key 3600); - redis 集群宕机或主从切换期间缓存不可用;
- 热点数据集中过期且无降级/限流机制。
与 缓存击穿(单个热点 key 失效被大量并发击穿)和 缓存穿透(查询不存在的数据绕过缓存)不同,雪崩是 大规模并发失效,影响范围更广、破坏力更强。
二、缓存雪崩 vs 击穿 vs 穿透:三者对比
| 维度 | 缓存雪崩 | 缓存击穿 | 缓存穿透 |
|---|---|---|---|
| 触发原因 | 大量 key 同时过期或缓存服务宕机 | 单个热点 key 过期,高并发访问 | 查询不存在的数据(恶意或逻辑错误) |
| 影响范围 | 全局性,可能压垮 db | 局部性,影响特定接口 | 可能全量穿透,消耗 db 资源 |
| 典型表现 | db qps 暴涨、连接池耗尽 | 接口响应延迟飙升 | db 被无效查询打满 |
| 防御重点 | 分散过期时间、多级缓存、熔断 | 互斥重建、永不过期 | 布隆过滤器、空值缓存 |
三、核心防御策略详解
1. 随机过期时间(ttl jitter)
原理:为每个缓存 key 设置基础 ttl + 随机偏移量,避免集体失效。
# 示例:python 设置随机 ttl(单位:秒)
import random
base_ttl = 3600
jitter = random.randint(0, 300) # ±5 分钟抖动
redis.setex("user:1001", base_ttl + jitter, user_data)✅ 优点:简单有效,成本低
❌ 局限:无法应对 redis 宕机等全局故障
2. 多级缓存架构(l1 + l2)
架构示意:
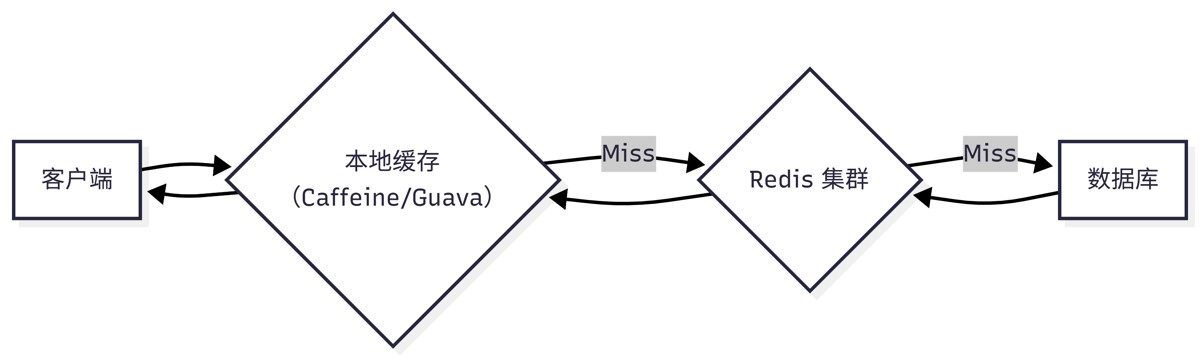
- l1(本地缓存):毫秒级响应,抗 redis 短时不可用;
- l2(redis):分布式共享,一致性保障;
- 策略:本地缓存 ttl < redis ttl,形成“缓冲带”。
实践建议:本地缓存使用 软引用 + 自动淘汰,避免内存泄漏。
3. 互斥锁重建(mutex lock)——适用于缓存击穿,慎用于雪崩
当单个热点 key 失效时,高并发请求可能同时穿透到数据库,形成“缓存击穿”。此时可使用互斥锁,确保仅一个线程重建缓存,其余线程等待或返回兜底数据。
# redis lua 脚本实现原子锁(锁有效期 10 秒)
eval"if redis.call('set', keys[1], 'locked', 'nx', 'ex', 10) then return 1 else return 0 end"1 cache_key_mutex✅ 适用场景:
- 单个 key(如热门商品、首页配置)过期;
- 重建成本高(如需聚合多表数据)。
❌ 不适用于大规模缓存雪崩:
- 若成千上万个 key 同时失效,为每个 key 加锁会导致:
- redis 锁操作本身成为瓶颈;
- 数据库仍需处理大量串行查询,整体响应变慢;
- 用户体验下降(大量请求阻塞等待)。
工程建议:互斥锁是缓存击穿的标准解法,但缓存雪崩应优先通过“随机 ttl”和“多级缓存”预防,而非依赖锁机制。
4. 永不过期 + 后台刷新
- 缓存写入时不设 ttl;
- 启动后台任务定期刷新热点数据;
- 请求直接读缓存,无穿透风险。
“后台刷新”就是让系统自己默默地、定期地去数据库拿最新数据更新缓存,用户永远读的是“现成的”,既快又稳,还不怕 db 被打垮。
架构示意:
| 场景 | 是否适合 |
|---|---|
| 商品详情、文章内容、配置信息 | ✅ 非常适合(变更不频繁,可接受短暂延迟) |
| 实时库存、金融余额 | ❌ 不适合(要求强一致或秒级更新) |
| 大促热点商品 | ✅ 极适合(避免流量高峰打穿 db) |
适合静态或准实时数据(如商品详情、配置信息)
不适合高频变更数据
总结:脏读可控,收益显著
| 维度 | 传统 ttl 模式 | 永不过期 + 后台刷新 |
|---|---|---|
| 一致性 | 较好(过期即更新) | 较差(有延迟) |
| 可用性 | 雪崩/击穿风险高 | 极高(无穿透) |
| 性能 | 首次请求慢 | 所有请求快 |
| 适用场景 | 通用 | 高并发只读热点数据 |
结论:
**“永不过期 + 后台刷新”确实会产生脏读,但通过合理的刷新策略、主动触发机制和业务容忍度设计,可以将风险控制在可接受范围内。在高并发、高可用优先的系统中,这是一种成熟且广泛采用的工程实践。
四、关键 redis 命令在防雪崩中的作用
| 命令 | 用途 | 防雪崩价值 |
|---|---|---|
set key value ex seconds | 设置带 ttl 的缓存 | 基础能力,需配合随机 ttl |
set key value nx | 仅当 key 不存在时设置 | 用于互斥锁实现 |
get key / ttl key | 读取缓存及剩余生存时间 | 监控缓存健康状态 |
expire key seconds | 动态调整 ttl | 用于后台刷新策略 |
建议:使用
set key value nx ex ttl原子操作替代set + expire,避免竞态条件。
五、高频面试题
q1:如何区分缓存雪崩和缓存击穿?
答:雪崩是大量 key 同时失效,击穿是单个热点 key 失效被高并发击穿。前者影响面广,后者聚焦热点。
q2:为什么随机 ttl 能缓解雪崩?
答:通过分散 key 的过期时间,避免在同一时刻大量缓存失效,从而平滑数据库负载。
q3:多级缓存中,本地缓存和 redis 的 ttl 如何设置?
答:本地缓存 ttl 应小于 redis ttl(如设为 redis ttl 的 50%~80%)并加随机抖动,主要目的是分散本地缓存失效时间,避免集体回源冲击 redis。它不能完全避免脏读,强一致性需依赖写时主动失效缓存(如删除 redis + 广播清除本地缓存)。
在多级缓存中,为本地缓存设置 基础 ttl + 随机抖动(如 ttl = base ± 20%),可有效将缓存失效从“瞬时尖峰”转化为“平缓流量”,显著降低对 redis 的冲击。虽然仍存在短时间内的批量回源,但其压力已降至系统可承受范围。若需更高一致性,应结合主动缓存失效机制。
举例:若 redis ttl = 60s,本地 ttl = 40s ± 5s,则各服务节点的本地缓存会在 35~45s 内陆续失效,分散了对redis 的回源请求,避免集体穿透。但这不能保证数据实时一致——若业务在 t=10s 更新了数据但未清理缓存,本地仍可能返回 t=0s 的旧值直至下次回源。
q4:互斥锁重建时,如果重建线程挂了怎么办?
答:设置合理的锁超时时间(如 10s),并配合重试机制;也可引入“重建失败降级”策略(如返回兜底数据)。
q5:缓存雪崩发生时,如何快速止损?
答:立即启用熔断(如 hystrix)、限流(如 sentinel),临时延长缓存 ttl,或切换至只读副本。
到此这篇关于redis缓存雪崩深度解析:原理、防御策略与工程实践的文章就介绍到这了,更多相关redis缓存雪崩内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论