redis缓存介绍
在高并发的场景下,直接使用传统的面向内存的数据库,资源开销会非常大,性能也非常低,数据库服务器很容易崩溃。因此可以把一些经常用到的数据(热数据:使用频率很高,但是占总数据量较少)统一放到redis中,当客户端查询时,先查询redis,查询不到,再去查询数据库。
这便是redis缓存,它就像一个保护罩,为数据库抵达掉了大部分请求:
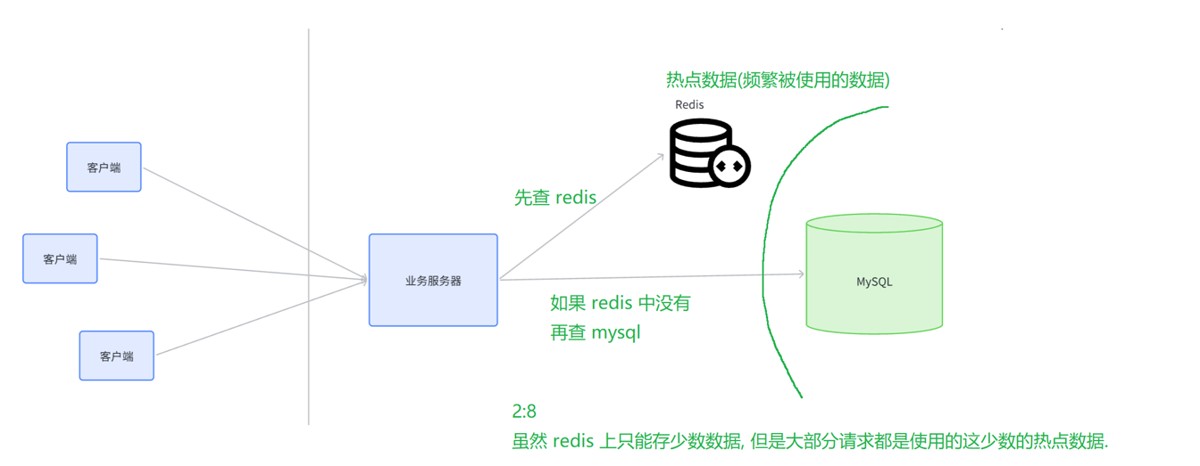
那么问题就来了:
- 我们怎么知道那些数据是热数据?
- 怎么保证redis中存储的一直都是热数据?
以上便是我们接下来要讨论的问题。
缓存策略
1)定期生成
每个一定的周期,对于访问数据库数据的频率进行统计,选出前n%的数据,放到redis缓存中。
这种方式操作最简单,对于数据的掌控也更加稳定。缺点也很明显,就是时效性非常低。
2)实时生成
先给缓存设定容量上限(可以通过 redis 配置⽂件的 maxmemory 参数设定)。
接下来按照这个流程执行:
- 先从redis中查询,查到了直接返回
- 查不到从数据库中查,返回结果的同时,把这个数据写入redis
当缓存达到上线,我们根据可靠的缓存淘汰策略,删除redis中相对不那么“热”的数据。以此达到热数据的动态平衡。
3)缓存淘汰策略
包括但不限于redis,缓存淘汰策略基本上涵盖了以下这四点:
- fifo (first in first out) 先进先出
把缓存中存在时间最久的 (也就是先来的数据) 淘汰掉 - lru (least recently used) 淘汰最久未使用的
记录每个 key 的最近访问时间. 把最近访问时间最老的 key 淘汰掉 - lfu (least frequently used) 淘汰访问次数最少的
记录每个 key 最近⼀段时间的访问次数. 把访问次数最少的淘汰掉 - random 随机淘汰
从所有的 key 中抽取幸运⼉淘汰掉
redis中提供的缓存淘汰策略:
volatile-lru
当内存不足以容纳新写入数据时,从设置了过期时间的 key 中使用 lru(最近最少使用)算法进行淘汰。allkeys-lru
当内存不足以容纳新写入数据时,从所有 key 中使用 lru(最近最少使用)算法进行淘汰。volatile-lfu
4.0 版本新增,当内存不足以容纳新写入数据时,在过期期的 key 中,使用 lfu 算法进行淘汰 key。allkeys-lfu
4.0 版本新增,当内存不足以容纳新写入数据时,从所有 key 中使用 lfu 算法进行淘汰。volatile-random
当内存不足以容纳新写入数据时,从设置了过期时间的 key 中,随机淘汰数据。allkeys-random
当内存不足以容纳新写入数据时,从所有 key 中随机淘汰数据。volatile-ttl
在设置了过期时间的 key 中,根据过期时间的剩余大小,提前淘汰剩余时间最短的 key(相当于 fifo,只要过期最早的 key)。noeviction
默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
redis中的缓存淘汰策略也都是围绕lcu,lfu来进行的,只不过分为allkeys(全部数据)和volatile(设置过期时间的数据)
缓存中需要考虑的问题
1)缓存预热
试想以下,加入redis刚启动,里面还没有任何数据写入,那么发过来的请求,直接就进入到了数据库中,数据库仍然会面临很大的压力。
解决办法很简单,就是按照定期生成热数据的方式,把热数据先写入redsi。即使时效性不高,能为数据库(如mysql)抵挡大部分请求就可以。
2)缓存穿透 (cache penetration)
定义:
- 由于发送过来的key是无效的。
- 数据库和redis缓存中肯定都没有,频繁的这种无效key请求,一定会压垮数据库。
产生原因:
- 业务代码出现漏洞,对参数的校验出了问题
- 开发/运维不小心删除了某个热数据key,自己却没有发现
- 黑客恶意攻击
解决办法:
- 针对数据库查询的参数进行严格校验,避免无效key请求
- 对于数据库中不存在的key,在redis缓存中设置一个""值,直接拦截非法key请求
- 使用布隆过滤器,判定key是否存储在,存在才进行查询
布隆过滤器
- 是一种高效查询元素是否存在的数据结构。
- 简单的可以认为是hash+位图方式实现,不存储实际值,占用的内存很少
3)缓存雪崩(cache avalanche)
定义:
- 短时间内大量key同时过期,导致数据库查询操作激增
出现原因:
- 设置key,时使用了统一的过期时间
解决办法:
- 不给key添加过期时间或者添加随机过期时间因子
4) 缓存击穿(cache breakdown)
定义:
- 缓存雪崩是大量key同时失效,cache breakdown是某一个或者多个热数据的key失效。而这些热数据访问频率很高,导致数据库查询次数激增
- 在 redis 和缓存系统的语境下,“缓存 breakdown”通常指 缓存击穿。
简单来说,就是某一个热点 key(比如双 11 的秒杀商品)在过期的瞬间,同时有海量的请求打过来。因为缓存失效了,这些请求会像洪流一样直接冲向数据库,可能导致数据库瞬间宕机。
处理这个问题,核心思路只有两个:不让请求全都去查数据库,或者干脆不让热点 key 过期。
1. 设置互斥锁 (mutex lock)
这是最常用的方案。当缓存失效时,不是每个请求都去查数据库,而是先让请求尝试获取一个“锁”(通常用 redis 的 setnx 命令)。
- 原理:只有拿到锁的那个请求能去数据库查数据并回写缓存,其他没拿到锁的请求要么等待重试,要么返回空值。
- 优点:保证了数据库的安全性,数据一致性高。
- 缺点:代码逻辑稍微复杂,且在高并发下会有一定的等待延迟。
2. 热点数据“永不过期”
从物理上或者逻辑上让这个 key 永远存在。
- 物理永不过期:在
set的时候不设置过期时间。这种方式最稳,但占用内存且无法自动更新。 - 逻辑永不过期(后台异步更新):给数据设置一个逻辑上的过期时间(存放在 value 里)。
- 当程序发现逻辑时间快到期时,由一个后台线程异步去数据库更新这个 key,并延长逻辑时间。
- 在更新完成前,所有请求继续读取旧的数据。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论