在 java 并发编程的江湖里,volatile 是最轻量级的同步机制,但也是最容易被误用、最难讲透的一个关键字。很多开发者能脱口而出“可见性”和“禁止重排序”,但若追问其底层驱动力是什么?为什么它不能保证原子性?往往就语焉不详。
今天,我们就拨开迷雾,从硬件底层到 jvm 规范,一步步彻底讲透 jmm 与 volatile。
1. 这篇文章要解决什么问题?
在多线程环境下,我们经常会遇到一些“诡异”的现象:
- 不可见性:线程 a 修改了一个全局变量,线程 b 却一直读到旧值,导致代码逻辑死循环。
- 乱序搞鬼:明明代码写的是先初始化对象再赋值给引用,结果线程 b 拿到了一个还没初始化完的“半成品”对象(经典 dcl 漏洞)。
这些现象背后的根源是 cpu 缓存不一致 和 指令重排序。jmm(java memory model)和 volatile 的出现,就是为了给开发者提供一套标准的“契约”,确保在多线程环境下内存交互的正确性。
2. 核心原理:为什么需要 jmm?
jmm 的抽象模型
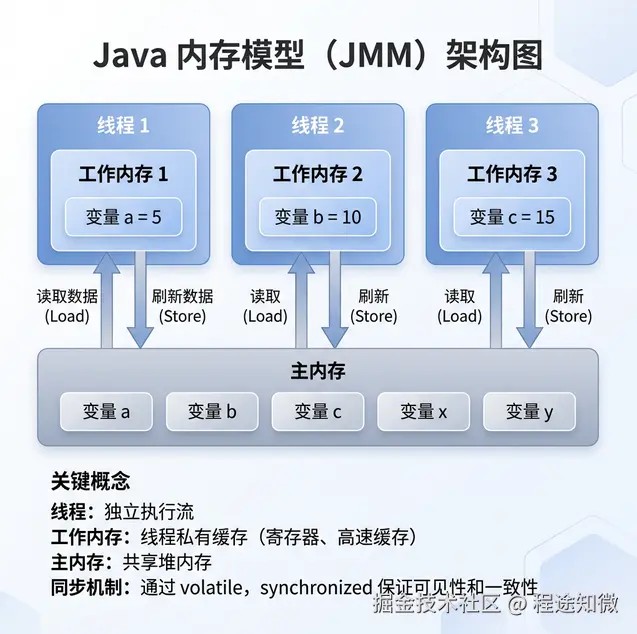
java 虚拟机规范定义了 jmm,目的是屏蔽掉各种硬件和操作系统的内存访问差异。
jmm 规定:
- 主内存(main memory):所有变量都存储在主内存中。
- 工作内存(working memory):每个线程都有自己的工作内存,保存了该线程使用到的变量的主内存副本。
线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存。
硬件背景:千里寻踪 mesi 协议
为什么需要工作内存?因为 cpu 太快了,内存太慢了。为了弥补速度差,cpu 引入了多级缓存(l1/l2/l3)。
当多个 cpu 核心同时操作同一个内存地址时,就会出现缓存不一致。硬件层面通过 mesi(modified, exclusive, shared, invalid)协议 来解决:
- modified:该行数据被修改,与主存不一致,需写回。
- exclusive:该行数据仅由当前 cpu 持有,且与主存一致。
- shared:多核共享,与主存一致。
- invalid:该行数据失效,需从主存或其它核心重新加载。
volatile 在底层正是利用了触发硬件缓存一致性的机制。
重排序:代码并不总是按你想的运行
为了提高性能,从源代码到执行指令,会经历三重重排序:
- 编译器优化重排序:编译器在不改变单线程语义的前提下重排。
- 指令级并行重排序:cpu 将多条指令重叠执行。
- 内存系统重排序:由于缓存和读写缓冲区的存在,加载和存储看起来是乱序的。
3. 流程/机制描述:volatile 是如何工作的?
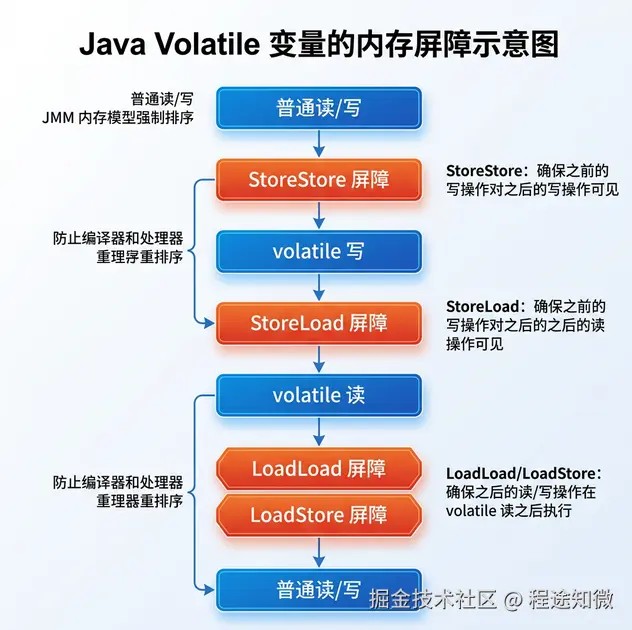
内存屏障(memory barrier)
jvm 会在 volatile 变量读写前后插入 内存屏障,它是一组处理器指令,用于限制编译器和处理器的重排序。
jmm 的屏障规则非常严苛:
- storestore 屏障:在
volatile写之前插入,禁止前面的普通写和volatile写重排序。 - storeload 屏障:在
volatile写之后插入,保证该写操作对所有处理器可见(开销最大,最关键)。 - loadload 屏障:在
volatile读之后插入,禁止后面所有普通读操作和该读重排序。 - loadstore 屏障:在
volatile读之后插入,禁止后面所有普通写操作和该读重排序。
x86 底层:lock 前缀指令
在常见的 x86 架构 cpu 上,volatile 的底层实现其实是依靠一个 lock 前缀指令。 当 jvm 执行带有 volatile 的写操作时,会生成的汇编代码中会包含 lock addl $0x0, (%esp)(或者类似的空操作)。
这个 lock 前缀有两大核心作用:
- 立即刷新主存:它会将该 cpu 核缓存行的数据立即写回到系统内存。
- 使其它缓存失效:由于 mesi 协议的嗅探机制,其它 cpu 核心会监听到该数据的变化,并将其对应的缓存行设置为 invalid 状态。下次其它核心读取时,强制去主存加载。
4. 关键代码/示例
场景一:可见性演示
如果不用 volatile,这个程序可能永远不会停止。
import java.util.concurrent.timeunit;
/**
* 可见性案例:flag 标记位
*/
public class visibilitydemo {
// 若不加 volatile,主线程修改 stop 标记后,workthread 可能永远感知不到
private static volatile boolean stop = false;
public static void main(string[] args) throws interruptedexception {
thread workthread = new thread(() -> {
system.out.println("工作线程启动...");
while (!stop) {
// 循环执行业务
}
system.out.println("工作线程感知到停止信号,退出循环。");
});
workthread.start();
// 睡眠 1 秒确保工作线程已经进入循环
timeunit.seconds.sleep(1);
stop = true;
system.out.println("主线程已修改 stop 标记为 true");
}
}场景二:禁止重排序(dcl 单例)
这是 volatile 在企业级应用中最经典的场景。
可通过高并发模拟验证,或使用jcstress进行验证
/**
* 双重检查锁定(dcl)单例模式
*/
public class singleton {
// 必须加 volatile,防止指令重排序
private static volatile singleton instance;
private singleton() {
// 初始化逻辑
}
public static singleton getinstance() {
if (instance == null) {
synchronized (singleton.class) {
if (instance == null) {
/*
* 重点:new singleton() 包含三步:
* 1. 分配内存空间
* 2. 执行构造方法初始化对象
* 3. 将 instance 指向分配的内存空间
*
* 若无 volatile,2 和 3 可能重排序。
* 线程 a 执行了 1、3,还未执行 2 时,线程 b 判断 instance 不为空,
* 于是拿到了一个未完成初始化的“空壳”对象,造成空指针异常。
*/
instance = new singleton();
}
}
}
return instance;
}
}5. 常见误区
误区 1:volatile 保证原子性
绝对错误! volatile 只保证可见性和有序性。对于类似 i++ 这种操作(包含:读取、加一、写回),它无法保证三步操作的整体原子性。多线程下依然会出现覆写。 对策:使用 atomicinteger 或 synchronized。
误区 2:volatile 性能非常差
片面。 volatile 的写操作由于需要插入 storeload 屏障刷新缓存,确实比普通写慢。但在读操作上,由于现代 cpu 的优化,其开销非常接近普通读。它比 synchronized 这种重量级锁要快得多。
6. 实际工作中怎么用?
- 状态标志位:如上面的
stop标记,用于优雅退出线程。 - 多线程环境下的单次赋值:如 dcl 单例中防止拿到半初始化对象。
- “happens-before” 传递性配合: jmm 规定,如果你先写一个
volatile变量,再由另一个线程读这个变量,那么写之前的所有可见修改对读之后的线程都是可见的。你可以利用这一点,通过修改一个volatile变量来“顺带”发布一组其它变量。
总结
volatile 是深入理解 jvm 内存模型的入场券。它就像是 cpu 缓存一致性协议在 java 层的投影,通过内存屏障和硬件指令,在纷乱的并发世界中强行划定了一道名为“确定性”的边界。
作为资深开发者,理解它不仅是为了写出高性能的代码,更是为了掌握系统底层的运行规律,在面对复杂的并发难题时,能一眼看穿真相。
到此这篇关于java 内存模型 (jmm) 与 volatile 底层实现的文章就介绍到这了,更多相关java 内存模型 内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论