一、背景:为什么需要这个工具
在日常工作中,我们每天要接触大量不同类型的文件——pdf 报告、word 文档、excel 表格、powerpoint 演示文稿、图片、视频,以及无数个网页链接。这些内容分散存储在不同磁盘目录和浏览器书签里,切换查找极为低效。
市面上存在的方案要么是重型的文档管理系统(学习成本高、功能过剩),要么是简单的书签管理器(仅支持 url,不能管理本地文件)。我们真正需要的,是一个轻量、跨类型、可以在同一界面查看文件详情和预览内容的本地桌面应用。
痛点:文件分散在多个目录,缺少统一入口;不同格式(pdf、word、图片)需要打开不同程序才能看内容;打开次数、标签、备注等元数据无处记录。
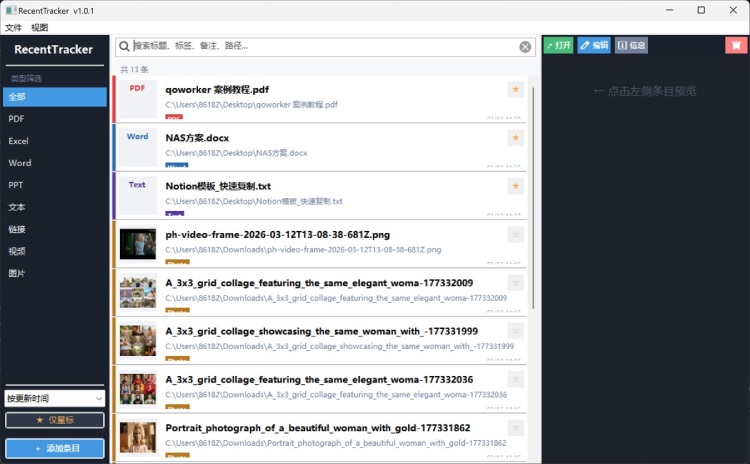
基于以上背景,本项目决定用 python + wxpython 在本地构建一个名为 recenttracker 的桌面工具,目标是填补"轻量全文件类型管理器"这一空白。
二、目标:定义产品功能边界
在动手写代码之前,我们对这个工具做了明确的功能定义:
核心功能(必须实现)
- 统一管理 pdf、word、excel、ppt、txt、图片、视频和网页链接
- 卡片式列表展示,支持关键字搜索、类型筛选、星标收藏、多维排序
- 右侧内嵌预览区:图片可缩放、pdf 可翻页/旋转、office 文件提取文字
- sqlite 本地数据库持久化,数据完全存储在用户本机
- 支持拖放文件批量导入、文件夹扫描导入
体验目标(质量约束)
- 单击卡片立即响应,不因文件 i/o 卡顿界面
- 刷新列表时不闪烁、不跳动滚动位置
- python 3.8+ 兼容,windows / macos / linux 均可运行
- 依赖库尽量可选:核心功能不强制安装 pillow / pymupdf
| 文件类型 | 支持格式 | 预览方式 |
| 文档 | pdf, docx, doc, xlsx, xls, pptx, ppt, txt | 文字提取 / pdf 渲染 |
| 图片 | jpg, png, gif, bmp, webp, tiff | 缩略图 + 可缩放显示 |
| 视频 | mp4, avi, mkv, mov, wmv, flv | 文件信息展示 |
| 链接 | http(s) url | url 展示 + 浏览器打开 |
三、方法:技术选型与架构设计
3.1 技术栈选型
python 桌面 gui 框架的主流选择有三类:
| 框架 | 优点 | 缺点 | 适合场景 |
| tkinter | 内置,无需安装 | 外观陈旧,控件有限 | 极简工具 |
| pyqt / pyside | 功能强大,外观现代 | 授权复杂,体积大 | 商业软件 |
| wxpython | 原生控件,跨平台,mit | 文档分散,api 较老 | 本地工具 |
本项目选择 wxpython 4.x,理由是它使用系统原生控件(在 windows 上看起来就像 windows 应用),mit 授权无顾虑,且 scrolledpanel、splitterwindow 等控件完全满足需求。
3.2 整体架构
整个项目是单文件应用(main.py,约 2100 行),遵循分层架构:
┌─────────────────────────────────────────────────────┐
│ mainframe │
│ ┌──────────┐ ┌─────────────┐ ┌──────────────┐ │
│ │ left │ │ cardlist │ │ detailpanel │ │
│ │ sidebar │ │ (卡片列表) │ │ (预览面板) │ │
│ │ (筛选栏) │ │ │ │ │ │
│ └──────────┘ └─────────────┘ └──────────────┘ │
│ ↕ 数据层 │
│ database (sqlite3) │|
└─────────────────────────────────────────────────────┘
各层职责划分清晰:
- 数据层(database 类):封装所有 sqlite 操作,对上层暴露 add_item / get_all / update_item 等纯数据接口
- 控件层(itemcard / cardlist):负责列表渲染与用户交互,通过回调函数通知 mainframe
- 预览层(detailpanel):右侧预览,内部管理 pdf 文档句柄和图片状态,与数据层直接通信
- 主窗口(mainframe):协调各组件,持有筛选/排序/搜索状态,统一调用 refresh()
四、过程:逐模块源码解析
4.1 数据库层——database 类
database 类是整个应用的数据基础,使用 sqlite3 标准库,无需任何第三方 orm。核心表结构如下:
create table items (
id integer primary key autoincrement,
title text not null,
type text not null, -- pdf/docx/photo/link/video...
path text, -- 本地文件路径
url text, -- 网页链接
tags text default '',
note text default '',
thumbnail blob, -- png 缩略图二进制
star integer default 0,
created_at text,
updated_at text,
last_opened text,
open_count integer default 0
);每次操作都通过 _conn() 方法获取连接,使用 with 语句自动提交/回滚,保证线程安全。row_factory = sqlite3.row 让查询结果像字典一样按列名访问,代码可读性大幅提升。
设计亮点:get_all() 方法将搜索、过滤、排序全部在 sql 层完成,避免在 python 层做大量数据处理;排序字段经白名单校验防止 sql 注入;thumbnail 字段直接存储 png 的 blob 数据,免去外部图片文件管理的复杂性。
技巧:update_item() 使用 **kwargs 动态构建 set 子句,只更新传入的字段,避免每次更新都要写完整列名,非常适合局部更新场景(如只更新星标、或只更新 open_count)。
4.2 可选依赖的优雅处理
项目有三个可选依赖库,任何一个缺失都不应导致程序崩溃:
try:
from pil import image as pilimage
has_pil = true
except importerror:
has_pil = false
try:
import fitz # pymupdf
has_fitz = true
except importerror:
has_fitz = false在运行时检查这些标志,缺失时给出安装提示而非异常。例如 pdf 预览:有 pymupdf 则渲染为图片,无则降级为文字提取;有 pillow 则生成图片缩略图,无则只显示类型文字。这种"渐进增强"策略是小型工具的最佳实践。
另一个值得注意的处理是 _safe_webbrowser() 函数:
def _safe_webbrowser():
import importlib.util, sysconfig
stdlib = sysconfig.get_path("stdlib")
wb_file = os.path.join(stdlib, "webbrowser.py")
spec = importlib.util.spec_from_file_location("_wb", wb_file)
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod)
return mod这是为了解决一个真实 bug:用户 python 路径中存在一个同名的 webbrowser.py 文件(内部导入了 pandas),导致标准库的 webbrowser 模块被遮蔽,打开链接时抛出异常。通过 sysconfig 定位标准库绝对路径并直接加载,完全绕过路径遮蔽问题。
4.3 itemcard——卡片控件设计
每一条记录在列表中都渲染为一个 itemcard(继承 wx.panel)。卡片由三部分水平排列:
- 左侧色条(5px 宽):颜色由文件类型决定,快速视觉区分
- 类型徽章区(56px):优先显示图片缩略图,无缩略图则显示类型文字
- 信息区:标题(粗体)+ 星标按钮 + 路径(小字灰色)+ 底部标签和日期
交互行为通过回调函数解耦:itemcard 本身不知道父容器是谁,只持有三个回调:on_select(单击选中)、on_open(双击打开)、on_star(切换星标)。这种设计让卡片完全可测试、可复用。
_update_item() 方法 是性能优化的关键:刷新列表时,已有的卡片不销毁重建,而是调用此方法原地更新星标按钮的文字和颜色,然后 refresh()。避免了大量 panel 的销毁/创建开销,是消除列表闪烁的基础。
4.4 cardlist——无闪烁刷新
cardlist 是最复杂的控件之一,其 refresh() 方法经历了多次迭代才达到当前无闪烁效果。核心策略是 freeze / thaw 包裹 + 最小化 dom 变更:
def refresh(self, items, keep_selection=false):
self.freeze() # 暂停所有重绘,消除中间状态闪烁
try:
scroll_x, scroll_y = self.getviewstart() # 记录滚动位置
prev_selected = self.selected_id
# 1. 销毁已删除的卡片
removed = [oid for oid in self.cards if oid not in new_ids]
for oid in removed:
self.cards.pop(oid).destroy()
# 2. 销毁廉价分隔线,清空 sizer(不销毁卡片窗口)
for child in self.getchildren():
if isinstance(child, wx.staticline): child.destroy()
self.sizer.clear(false)
# 3. 按新顺序重新添加卡片 + 新建分隔线
for item in items:
if iid in self.cards:
self.cards[iid]._update_item(dict(item)) # 原地更新
else:
self.cards[iid] = itemcard(...) # 新建
self.sizer.add(self.cards[iid], 0, wx.expand)
self.sizer.add(wx.staticline(self), 0, wx.expand)
self.layout()
self.scroll(scroll_x, scroll_y) # 恢复滚动位置
finally:
self.thaw() # 一次性重绘,用户看不到中间状态关键:sizer.clear(false) 只解除布局关联,不销毁窗口对象,使得卡片 panel 可以被重新 add 到 sizer 中复用,而不是每次都重新创建大量控件。
4.5 detailpanel——内嵌预览引擎
右侧 detailpanel 是功能最丰富的部分,支持六种预览模式,并为 pdf 和图片提供独立的工具栏控件。
| 文件类型 | 预览实现 | 控件栏 |
| 图片 | pillow 加载 → wx.staticbitmap 渲染 | 缩放-+ / 适应 / 原始 |
| pymupdf page.get_pixmap() 渲染为 png | 翻页 ◀▶ / 缩放 / 旋转 ↺↻ | |
| txt | 自动检测编码(utf-8/gbk/big5) | 无 |
| word | python-docx 提取段落+表格文字 | 无 |
| excel | openpyxl 多 sheet 提取,最多 3 个 | 无 |
| ppt | python-pptx 逐页提取文字 | 无 |
| 链接 | url 展示 + 浏览器打开按钮 | 无 |
pdf 缩放采用"适应宽度"作为默认值,通过 _calc_fit_scale() 方法动态计算:
def _calc_fit_scale(self):
page = self._pdf_doc[self._pdf_page]
cw = max(self.canvas.getsize().width - 30, 300) # 画布宽度
pw = page.rect.width # pdf 页面原始宽度
return max(0.3, cw / pw / 1.5) # 1.5 是 pymupdf 渲染分辨率倍率4.6 后台线程——消除 ui 卡顿
文件读取(尤其是大型 word / excel / pdf)是耗时操作,如果在主线程执行,界面会在读取期间完全冻结。项目采用"令牌化后台线程"方案彻底解决这一问题:
def load(self, id_):
self._load_token += 1 # 递增令牌
token = self._load_token
self._show_loading() # 主线程立即显示"加载中…"
def _bg():
result = {}
# ... 在后台线程读取文件,不调用任何 wx api ...
result["text"] = _read_word(path)
# 回到主线程前检查令牌是否仍然有效
if token == self._load_token:
wx.callafter(self._apply_result, result, token)
threading.thread(target=_bg, daemon=true).start()令牌机制(_load_token)确保快速切换条目时,旧线程的结果不会覆盖新请求的内容。例如用户快速点击 a → b → c,只有 c 的加载结果会被渲染,a 和 b 的后台线程完成后发现令牌已过期,直接丢弃结果。
原则:wxpython 与大多数 gui 框架相同,所有控件操作必须在主线程执行。后台线程只做纯 python 计算(读文件、解析文档),完成后通过 wx.callafter() 将渲染任务派发回主线程。
4.7 文件读取函数族
为了让代码结构清晰,所有文件读取逻辑被提取为模块级纯函数(不依赖 wx),分别是:
- _read_text(path):自动尝试 utf-8-sig / utf-8 / gbk / gb2312 / big5 / latin-1 六种编码,确保中文内容能正确读取
- _read_word(path):.docx 用 python-docx 提取段落和表格;.doc 旧格式先尝试 python-docx,失败则从二进制提取可打印字符(gbk/utf-16-le)
- _read_excel(path):.xlsx 用 openpyxl 读取,最多预览 3 个 sheet;.xls 先尝试 openpyxl,再尝试 xlrd 作为备选
- _read_pptx(path):用 python-pptx 逐页提取文字,并标注页码
这些函数完全无副作用,输入文件路径,输出字符串,易于独立测试和维护。
4.8 主窗口 mainframe——三栏布局
界面采用两级 splitterwindow 嵌套实现三栏自由拖拽布局:
sp_root = wx.splitterwindow(self) # 根分割器(左 | 右) sp_right = wx.splitterwindow(sp_root) # 右侧分割器(列表 | 预览) sp_right.splitvertically(mid, self.detail, -305) # 预览栏默认 305px sp_root.splitvertically(left, sp_right, 158) # 侧边栏固定 158px
左侧边栏固定宽度 158px,包含类型筛选按钮、排序下拉、星标切换和添加按钮;中间列表栏自适应宽度,包含搜索框和卡片列表;右侧预览栏默认 305px 宽。三栏均可拖动调整。
4.9 数据流动与事件机制
整个应用的数据流遵循单向原则:
用户操作(点击 / 搜索 / 筛选)
↓
mainframe 更新状态(filter_type / search_text / sort_by)
↓
refresh() → db.get_all() → cardlist.refresh(items)
↓
选中 → detailpanel.load(id_) → 后台线程读文件 → 渲染
wxpython 事件通过 bind 挂接,mainframe 统一持有状态。子控件通过构造时传入的回调函数(on_select、on_open、on_star)向上通知,不直接引用父容器,保持解耦。
4.10 兼容性处理细节
项目在开发过程中遇到并解决了多个 wxpython 兼容性问题:
- wx.newid() 废弃警告:改用 wx.menuitem(menu, wx.id_any, label) + mi.getid() 绑定事件
- boxsizer 无 getitemindex() 方法(版本差异):改用"销毁 staticline → sizer.clear(false) → 重新 add"的方式重排,完全规避该方法
- bytes | none 类型注解语法(python 3.10+ 特性):改为 optional[bytes] 或去掉注解,保持 3.8+ 兼容
- sqlite 数据库路径:改为 os.path.expanduser("~") 用户主目录,避免写权限问题
五、结果:最终交付物与实际效果
5.1 功能完成情况
| 功能模块 | 完成状态 | 备注 |
| 多类型文件管理 | 完成 | 9 种类型,颜色编码区分 |
| 卡片式列表 + 搜索/筛选/排序 | 完成 | 全文搜索 + 4 种排序 |
| 拖放导入 + 文件夹批量导入 | 完成 | filedrop 实现 |
| 图片预览(缩放) | 完成 | 需 pillow |
| pdf 预览(翻页/缩放/旋转) | 完成 | 需 pymupdf,降级文字 |
| word/excel/ppt 文字预览 | 完成 | 含旧格式兼容 |
| 后台线程加载,ui 不卡顿 | 完成 | 令牌机制防乱序 |
| 无闪烁列表刷新 | 完成 | freeze/thaw + 原地更新 |
| json 导出/导入 | 完成 | 缩略图 base64 编码 |
| sqlite 备份/恢复 | 完成 | shutil.copy2 |
| 数据统计 | 完成 | 按类型分组计数 |
5.2 版本迭代历程
本项目共经历 8 个版本迭代,每版都针对真实使用中发现的问题进行修复:
- v1:初始实现,功能基础可用
- v2:修复 wx.newid() 废弃警告、标准库遮蔽 bug、sqlite 路径权限问题
- v3:修复 python 3.8 类型注解兼容问题
- v4:新增预览功能(弹窗模式),支持 pdf 渲染、图片缩放
- v5:重构预览为内嵌模式,替换右侧属性面板,新增 pdf 翻页/旋转/缩放控件
- v6:单击不再弹出预览窗;cardlist 引入 freeze/thaw 消除列表闪烁
- v7:修复 getitemindex() 兼容性错误;pdf 默认"适应宽度"
- v8:word 预览修复(含 .doc 旧格式兼容);后台线程加载消除切换卡顿
5.3 代码规模与结构
| 指标 | 数值 |
| 总行数 | 约 2,100 行 |
| 核心类 | 6 个(database, itemcard, cardlist, detailpanel, addeditdialog, mainframe) |
| 模块级工具函数 | 10 个(含 4 个文件读取函数) |
| 依赖库(必须) | 1 个(wxpython) |
| 依赖库(可选) | 4 个(pillow, pymupdf, python-docx, openpyxl / python-pptx) |
| 数据存储 | sqlite,单文件,存于用户主目录 |
六、总结:经验与思考
6.1 值得推广的工程实践
① 可选依赖的渐进增强
用 try/except importerror + 全局标志的方式处理可选库,让核心功能无依赖可运行,丰富功能按需安装。这是命令行工具和桌面工具的通用最佳实践。
② 令牌化异步加载
_load_token 计数器是一种轻量级的"取消"机制,无需复杂的 future/promise,只需在回调时比较令牌值,即可优雅地处理快速切换时的竞态条件。
③ freeze/thaw 消除闪烁
wxpython 的 freeze() 暂停重绘,所有 ui 变更在内存中完成,最后 thaw() 一次性渲染。配合 sizer.clear(false)(不销毁窗口)+ 卡片复用,实现了真正无闪烁的列表刷新。
④ 纯函数文件读取
将 _read_word / _read_excel 等提取为模块级纯函数,不依赖任何实例状态或 wx 对象,使后台线程的调用完全安全,也方便独立测试。
6.2 局限性与改进方向
- 缩略图仅支持图片类型,pdf 首页缩略图、office 预览图尚未实现
- 搜索目前是实时触发(每次按键都查数据库),大数据量时可加防抖(debounce)
- 拖放排序(手动调整条目顺序)尚未实现,依赖数据库字段排序
- 暂无云同步,数据完全本地;可考虑 json 导出后对接 webdav 或 git
- .doc 旧格式的文字提取是启发式方法,精度有限,建议配合 libreoffice 转换
到此这篇关于python从零打造桌面文件管理工具的完整指南的文章就介绍到这了,更多相关python桌面文件管理工具内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论