引言

在数字化转型浪潮中,智能问答机器人正成为企业客服、知识库检索乃至个人助理等场景的关键交互入口。它能让员工秒级获取技术解答、客户即时获得业务支持、学习者随时得到个性化辅导,极大提升信息获取效率与用户体验。
为何选择 python 与开源 ai 模型?python 拥有成熟的 ai 生态——hugging face transformers、langchain、faiss 等工具大幅降低开发门槛;而本地部署的开源大模型(如 phi-3、mistral、llama 系列)则保障了数据隐私、规避了 api 成本,特别适合对安全性或离线能力有要求的场景。
本文将手把手带你从零构建一个基于 rag(检索增强生成)架构的本地智能问答系统:使用 sentence-bert 实现语义检索,faiss 作为向量数据库,并集成轻量级开源语言模型生成答案。整个方案完全开源、免费,且可在普通消费级电脑上运行,无论你是开发者还是技术爱好者,都能快速上手并应用于实际项目。
技术选型分析
- 在深入实现之前,有必要先理解不同技术路线的差异。传统的问答系统通常基于规则引擎或关键词匹配,开发者需要预先编写大量的 if-else 规则或维护一个精心设计的问题-答案对数据库。这种方案的优点是响应快速、结果可控,但缺点也很明显:缺乏灵活性,无法理解语义相近但表达不同的用户问题,维护成本随着知识库规模呈指数级增长。例如,当用户问"密码忘记了怎么办"和"如何重置登录凭证"时,传统系统可能需要分别为这两个问题配置答案,尽管它们的语义完全相同。
- 基于大语言模型(llm)的问答系统则通过语义理解彻底改变了这一局面。llm 能够理解用户意图,捕捉语言中的细微差别,并生成自然流畅的回答。更重要的是,通过 rag 技术,我们可以将 llm 与本地知识库结合,既保证回答的准确性,又避免了模型幻觉问题。
在本项目中,我们选用了以下技术栈:
- 嵌入模型:
sentence-transformers/all-minilm-l6-v2。这是一个轻量级的语义编码器,能够将文本转换为 384 维的向量表示,在速度和效果之间取得了良好平衡。 - 向量数据库:
faiss(facebook ai similarity search)。这是 meta 开发的高效相似度搜索库,支持海量向量的快速检索。 - 生成模型:
microsoft/phi-3-mini-4k-instruct。phi-3 是微软推出的轻量级开源模型,参数量约 38 亿,在消费级 gpu 甚至 cpu 上即可流畅运行,同时具备出色的指令遵循能力。 - 开发框架:
langchain和transformers。langchain 提供了便捷的 rag 管道抽象,transformers 则负责模型的加载和推理。
为什么不直接调用 openai、文心一言等云端 api?原因有三:首先,本地部署确保数据完全私密,适合处理敏感信息;其次,一次投入即可无限使用,没有按 token 计费的成本压力;最后,离线环境下的可用性对于某些行业(如军工、金融、医疗)至关重要。当然,本地模型的性能在复杂推理任务上可能略逊于 gpt-4 等顶级模型,但对于知识库问答这类相对封闭的场景,已经能够取得令人满意的效果。
系统架构设计
- 一个典型的 rag 问答系统包含两个主要阶段:离线索引阶段和在线推理阶段。
- 离线索引阶段,我们需要将非结构化的知识库文档(如 markdown 文件、pdf 文档等)进行预处理。首先,将长文档切分成较小的文本块,这是为了确保检索时的语义聚焦和上下文窗口的高效利用。接着,使用嵌入模型将每个文本块转换为向量表示,并构建 faiss 索引。这一阶段类似于为书籍建立"语义目录",让后续的检索能够快速定位相关内容。
- 在线推理阶段则是用户交互的核心流程。当用户提出问题时,系统首先对问题文本进行相同的嵌入处理,得到问题向量。然后,在 faiss 索引中搜索与问题向量最相似的前 k 个文本块。这些检索到的文本块将与用户问题一起组成完整的上下文,送入 llm 生成最终答案。llm 会根据提供的上下文,结合其预训练的知识,生成一个自然、准确、连贯的回答。
整个系统的数据流动可以概括为以下流程:
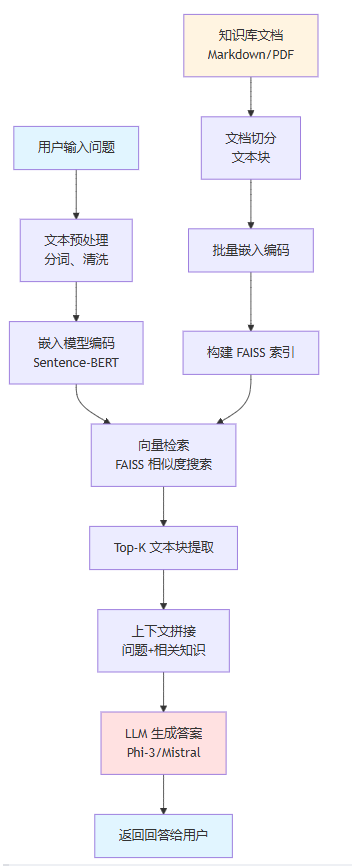
这个架构设计充分考虑了系统的可扩展性。例如,可以轻松替换不同的嵌入模型或生成模型以适应特定需求;faiss 索引支持增量更新,新增知识时无需重建整个索引;通过调整 top-k 值可以平衡召回率和精确度。在实际部署中,还可以添加查询改写、结果重排序、缓存机制等模块进一步提升性能。
核心代码实现
现在让我们开始编写代码。整个项目将被组织为清晰的模块,包括知识库构建、向量检索、llm 推理和主循环控制。所有代码均在 python 3.10+ 环境中测试通过。
第一步:安装依赖
首先,我们需要安装必要的 python 库。创建一个 requirements.txt 文件:
transformers>=4.35.0 sentence-transformers>=2.2.2 faiss-cpu>=1.7.4 langchain>=0.1.0 langchain-community>=0.0.10 torch>=2.0.0 accelerate>=0.25.0 pypdf>=3.17.0 python-dotenv>=1.0.0
然后执行安装命令:
pip install -r requirements.txt
如果你的机器有 nvidia gpu,建议安装 faiss-gpu 替代 faiss-cpu 以获得更快的检索速度。
第二步:构建本地知识库
假设我们有一份 markdown 格式的产品手册作为知识库。以下代码展示了如何加载文档并进行切分:
# knowledge_base.py
import os
from typing import list, dict
import re
class knowledgebase:
"""本地知识库管理类"""
def __init__(self, chunk_size: int = 500, chunk_overlap: int = 50):
"""
初始化知识库
args:
chunk_size: 文本块的最大字符数
chunk_overlap: 相邻文本块之间的重叠字符数
"""
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.documents = [] # 存储所有文本块
def load_markdown_file(self, file_path: str) -> str:
"""
加载 markdown 文件内容
args:
file_path: 文件路径
returns:
文件文本内容
"""
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
def split_text_into_chunks(self, text: str, source: str = "") -> list[dict]:
"""
将长文本切分为小块
args:
text: 待切分的文本
source: 文本来源标识(如文件名)
returns:
文本块列表,每个块包含内容和元数据
"""
chunks = []
start = 0
text_length = len(text)
while start < text_length:
end = start + self.chunk_size
# 如果不是最后一块,尝试在句号、问号或换行处切分
if end < text_length:
# 寻找最近的句子结束符
for delimiter in ['。', '!', '?', '\n\n', '. ', '! ', '? ']:
pos = text.rfind(delimiter, start, end)
if pos != -1:
end = pos + len(delimiter)
break
chunk_text = text[start:end].strip()
if chunk_text: # 跳过空块
chunks.append({
'content': chunk_text,
'metadata': {
'source': source,
'start': start,
'end': end
}
})
# 移动到下一块,考虑重叠区域
start = end - self.chunk_overlap
return chunks
def load_directory(self, directory: str, extension: str = '.md') -> none:
"""
加载目录下所有指定扩展名的文件
args:
directory: 目录路径
extension: 文件扩展名
"""
for filename in os.listdir(directory):
if filename.endswith(extension):
file_path = os.path.join(directory, filename)
print(f"正在加载文件: {filename}")
content = self.load_markdown_file(file_path)
chunks = self.split_text_into_chunks(content, source=filename)
self.documents.extend(chunks)
print(f"知识库构建完成,共 {len(self.documents)} 个文本块")
def get_documents(self) -> list[dict]:
"""获取所有文档块"""
return self.documents第三步:生成嵌入向量并构建 faiss 索引
接下来,我们使用 sentence-bert 将文本块转换为向量,并构建 faiss 索引:
# vector_store.py
import numpy as np
import faiss
from sentence_transformers import sentencetransformer
from typing import list, dict, tuple
class vectorstore:
"""向量存储和检索类"""
def __init__(self, model_name: str = 'sentence-transformers/all-minilm-l6-v2'):
"""
初始化向量存储
args:
model_name: 嵌入模型名称
"""
print(f"正在加载嵌入模型: {model_name}")
self.embedding_model = sentencetransformer(model_name)
self.dimension = self.embedding_model.get_sentence_embedding_dimension()
self.index = none
self.documents = [] # 存储原始文档块
def build_index(self, documents: list[dict]) -> none:
"""
为文档构建 faiss 索引
args:
documents: 文档块列表
"""
self.documents = documents
print(f"正在为 {len(documents)} 个文档块生成嵌入向量...")
# 批量生成嵌入向量
texts = [doc['content'] for doc in documents]
embeddings = self.embedding_model.encode(
texts,
show_progress_bar=true,
convert_to_numpy=true
)
# 构建 faiss 索引(使用 l2 距离)
self.index = faiss.indexflatl2(self.dimension)
self.index.add(embeddings.astype('float32'))
print(f"索引构建完成,向量维度: {self.dimension}, 索引大小: {self.index.ntotal}")
def save_index(self, index_path: str, docs_path: str) -> none:
"""
保存索引和文档到磁盘
args:
index_path: faiss 索引保存路径
docs_path: 文档保存路径
"""
if self.index is none:
raise valueerror("索引尚未构建")
faiss.write_index(self.index, index_path)
np.save(docs_path, self.documents)
print(f"索引已保存到 {index_path}")
print(f"文档已保存到 {docs_path}")
def load_index(self, index_path: str, docs_path: str) -> none:
"""
从磁盘加载索引和文档
args:
index_path: faiss 索引路径
docs_path: 文档路径
"""
self.index = faiss.read_index(index_path)
self.documents = np.load(docs_path, allow_pickle=true).tolist()
print(f"索引已加载,包含 {self.index.ntotal} 个向量")
def search(self, query: str, top_k: int = 3) -> list[dict]:
"""
搜索与查询最相似的文档
args:
query: 查询文本
top_k: 返回最相似的前 k 个结果
returns:
包含文档内容和相似度分数的列表
"""
if self.index is none:
raise valueerror("索引尚未构建或加载")
# 将查询转换为向量
query_vector = self.embedding_model.encode(
[query],
convert_to_numpy=true
).astype('float32')
# 搜索最相似的向量
distances, indices = self.index.search(query_vector, top_k)
# 构建结果列表
results = []
for i, (distance, idx) in enumerate(zip(distances[0], indices[0])):
if idx < len(self.documents): # 确保索引有效
result = self.documents[idx].copy()
# 将 l2 距离转换为相似度分数(0-1 之间)
result['score'] = 1 / (1 + distance)
result['rank'] = i + 1
results.append(result)
return results
第四步:集成轻量级 llm
现在我们使用 transformers 库加载 phi-3 模型进行答案生成:
# llm_generator.py
import torch
from transformers import autotokenizer, automodelforcausallm
from typing import list, dict
class llmgenerator:
"""llm 答案生成器"""
def __init__(
self,
model_name: str = 'microsoft/phi-3-mini-4k-instruct',
device: str = 'auto'
):
"""
初始化 llm 生成器
args:
model_name: 模型名称或本地路径
device: 运行设备 ('cuda', 'cpu', 'auto')
"""
if device == 'auto':
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
else:
self.device = device
print(f"正在加载模型: {model_name}")
print(f"使用设备: {self.device}")
self.tokenizer = autotokenizer.from_pretrained(
model_name,
trust_remote_code=true
)
self.model = automodelforcausallm.from_pretrained(
model_name,
torch_dtype=torch.float16 if self.device == 'cuda' else torch.float32,
device_map='auto' if self.device == 'cuda' else none,
trust_remote_code=true
)
if self.device == 'cpu':
self.model = self.model.to(self.device)
print("模型加载完成")
def generate_answer(
self,
query: str,
context_docs: list[dict],
max_new_tokens: int = 256,
temperature: float = 0.7
) -> str:
"""
基于上下文生成答案
args:
query: 用户问题
context_docs: 检索到的相关文档
max_new_tokens: 最大生成 token 数
temperature: 采样温度(越低越确定)
returns:
生成的答案
"""
# 构建上下文
context_text = "\n\n".join([
f"[参考信息 {i+1}]\n{doc['content']}"
for i, doc in enumerate(context_docs)
])
# 构建提示词(prompt engineering)
prompt = f"""你是一个专业的智能客服助手。请根据以下参考信息回答用户的问题。
参考信息:
{context_text}
用户问题:{query}
请基于参考信息给出准确、简洁、友好的回答。如果参考信息中没有相关内容,请礼貌告知用户你无法从现有资料中找到答案。
回答:"""
# 编码输入
inputs = self.tokenizer(
prompt,
return_tensors='pt',
truncation=true,
max_length=2048 # 控制输入长度
).to(self.device)
# 生成答案
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=true if temperature > 0 else false,
top_p=0.9,
repetition_penalty=1.1,
pad_token_id=self.tokenizer.eos_token_id
)
# 解码输出(只返回新生成的部分)
answer = self.tokenizer.decode(
outputs[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=true
)
return answer.strip()
第五步:主问答循环
最后,我们将所有组件组合起来,构建完整的问答系统:
# main.py
import os
from dotenv import load_dotenv
from knowledge_base import knowledgebase
from vector_store import vectorstore
from llm_generator import llmgenerator
class qasystem:
"""智能问答系统主类"""
def __init__(
self,
knowledge_dir: str = './knowledge',
index_path: str = './faiss_index.bin',
docs_path: str = './documents.npy',
rebuild_index: bool = false
):
"""
初始化问答系统
args:
knowledge_dir: 知识库目录
index_path: faiss 索引路径
docs_path: 文档存储路径
rebuild_index: 是否重建索引
"""
# 初始化组件
self.kb = knowledgebase(chunk_size=500, chunk_overlap=50)
self.vector_store = vectorstore()
self.llm = llmgenerator()
# 加载或构建索引
if rebuild_index or not os.path.exists(index_path):
print("正在构建新索引...")
self.kb.load_directory(knowledge_dir)
documents = self.kb.get_documents()
self.vector_store.build_index(documents)
self.vector_store.save_index(index_path, docs_path)
else:
print("正在加载已有索引...")
self.vector_store.load_index(index_path, docs_path)
print("=" * 50)
print("智能问答系统初始化完成!")
print("=" * 50)
def ask(self, query: str, top_k: int = 3) -> dict:
"""
处理用户问题
args:
query: 用户问题
top_k: 检索的文档数量
returns:
包含答案和参考信息的字典
"""
print(f"\n用户问题: {query}")
print("正在检索相关知识...")
# 向量检索
retrieved_docs = self.vector_store.search(query, top_k=top_k)
print(f"检索到 {len(retrieved_docs)} 个相关文档片段")
# 生成答案
print("正在生成答案...")
answer = self.llm.generate_answer(query, retrieved_docs)
return {
'query': query,
'answer': answer,
'sources': [
{
'content': doc['content'][:100] + '...',
'score': doc['score'],
'source': doc['metadata']['source']
}
for doc in retrieved_docs
]
}
def run_interactive(self):
"""运行交互式问答循环"""
print("\n" + "=" * 50)
print("智能问答系统已就绪!")
print("输入您的问题,输入 'quit' 或 'exit' 退出")
print("=" * 50 + "\n")
while true:
try:
query = input("您的问题: ").strip()
if not query:
continue
if query.lower() in ['quit', 'exit', '退出']:
print("感谢使用,再见!")
break
# 处理问题
result = self.ask(query)
# 显示结果
print(f"\n{'='*50}")
print(f"答案: {result['answer']}")
print(f"{'='*50}")
print(f"参考信息 (共 {len(result['sources'])} 条):")
for i, source in enumerate(result['sources'], 1):
print(f"\n{i}. 来源: {source['source']}")
print(f" 相似度: {source['score']:.3f}")
print(f" 内容: {source['content']}")
except keyboardinterrupt:
print("\n\n检测到中断,正在退出...")
break
except exception as e:
print(f"\n发生错误: {str(e)}")
print("请尝试重新提问\n")
if __name__ == '__main__':
# 创建示例知识库目录和文件
os.makedirs('./knowledge', exist_ok=true)
# 创建示例知识库文件(如果不存在)
sample_md = """# 公司员工手册
## 密码重置流程
如果员工忘记了系统登录密码,可以按照以下步骤进行重置:
1. 访问公司内部系统登录页面
2. 点击"忘记密码"链接
3. 输入员工邮箱地址
4. 查收邮箱中的重置链接
5. 点击链接进入密码重置页面
6. 设置新密码(需包含大小写字母、数字和特殊字符)
7. 使用新密码登录系统
如遇到问题,请联系 it 部门热线:400-123-4567
## 年假申请流程
员工申请年假需要遵循以下流程:
1. 提前至少 3 个工作日提交申请
2. 登录 hr 系统,进入"假期管理"模块
3. 选择年假类型,填写起止日期
4. 填写假期期间的工作交接安排
5. 提交申请等待审批
6. 直属上级审批通过后生效
注意事项:
- 年假最小单位为 0.5 天
- 法定节假日前后 3 天内不得申请年假
- 年假需在当年 12 月 31 日前使用完毕
## 报销流程
员工日常费用报销流程如下:
1. 收集并整理所有原始发票
2. 登录财务系统,进入"费用报销"模块
3. 填写报销单,包括:
- 费用类型(交通、餐饮、办公用品等)
- 金额和发票张数
- 费用事由
4. 上传发票扫描件或照片
5. 提交申请
6. 等待财务部门审核(一般 3-5 个工作日)
7. 审核通过后,费用将转入员工工资卡
报销标准:
- 市内交通:单次不超过 50 元
- 餐饮费用:人均不超过 80 元/餐
- 住宿费用:一线城市不超过 500 元/晚
## 联系方式
各部门联系方式:
- it 部门:it@company.com | 内线 8888
- hr 部门:hr@company.com | 内线 6666
- 财务部门:finance@company.com | 内线 9999
"""
sample_path = './knowledge/员工手册.md'
if not os.path.exists(sample_path):
with open(sample_path, 'w', encoding='utf-8') as f:
f.write(sample_md)
print(f"已创建示例知识库文件: {sample_path}")
# 初始化并运行问答系统
qa_system = qasystem(rebuild_index=true)
qa_system.run_interactive()
效果演示与优化建议
完成上述代码后,运行 python main.py 即可启动问答系统。以下是几个实际问答示例:
示例 1:密码重置
您的问题: 我忘记密码了怎么办?
答案: 您可以通过访问公司内部系统登录页面,点击"忘记密码"链接来重置密码。输入您的员工邮箱地址,查收邮箱中的重置链接,点击链接后设置新密码即可。新密码需包含大小写字母、数字和特殊字符。如遇到问题,请联系 it 部门热线:400-123-4567。
示例 2:年假申请
您的问题: 年假怎么申请?
答案: 员工申请年假需提前至少 3 个工作日提交申请。请登录 hr 系统的"假期管理"模块,选择年假类型并填写起止日期和工作交接安排,提交后等待直属上级审批。注意年假最小单位为 0.5 天,需在当年 12 月 31 日前使用完毕,且法定节假日前后 3 天内不得申请。
示例 3:超出知识库范围
您的问题: 公司有股票期权计划吗?
答案: 抱歉,我无法从现有资料中找到关于公司股票期权计划的信息。建议您咨询 hr 部门或查阅公司内部的相关政策文档。您可以通过内线 6666 或发送邮件至 hr@company.com 联系 hr 部门。
从示例中可以看出,系统不仅能够准确检索到相关信息,还能生成自然流畅的回答。当问题超出知识库范围时,系统也能优雅地处理,不会胡编乱造。
常见问题与解决方案
1. 模型幻觉
虽然 rag 架构大大降低了幻觉风险,但在某些情况下仍可能出现。解决方法包括:
- 在提示词中明确要求"只基于参考信息回答"
- 降低采样温度,使模型输出更确定
- 添加答案验证机制,检查生成内容是否与检索内容一致
2. 上下文截断
当检索到的文档总长度超过模型上下文窗口时,需要截断内容。优化策略:
- 使用更长的上下文模型(如 phi-3-mini-128k)
- 实现智能文档选择,优先保留高相关性片段
- 对长文档进行压缩摘要
3. 检索精度不足
某些复杂问题可能无法准确检索到相关文档。改进方案:
- 尝试更强大的嵌入模型(如
bge-large-zh-v1.5) - 实现查询重写,将用户问题转换为更适合检索的形式
- 引入重排序模型(reranker)对检索结果重新打分
进阶优化方向
缓存机制:对于重复问题,可以缓存答案以加快响应速度。使用 lru 缓存策略,存储问题-答案对,当相同问题再次出现时直接返回缓存结果。
前端集成:将系统封装为 web api,使用 flask 或 fastapi 提供 restful 接口,然后构建简洁的前端界面。这样可以让更多用户同时使用,也便于集成到现有系统中。
多模态支持:扩展系统以支持图片、表格等多模态内容。例如,可以使用 ocr 技术提取 pdf 中的图片文字,或使用表格解析器处理结构化数据。
持续学习:实现反馈机制,允许用户标记答案的正确性。收集这些反馈数据,可以用于知识库的更新和模型的微调,形成持续改进的闭环。
总结
- 本文从零开始,完整演示了如何使用 python 和开源 ai 技术构建一个本地可运行的智能问答系统。我们实现了基于 rag 架构的完整流程,包括知识库构建、向量检索、llm 生成等核心模块。整个系统完全开源、免费,无需依赖任何云端 api,既保护了数据隐私,也控制了使用成本。
- 这个项目的价值在于它为开发者提供了一个可复制、可扩展的 ai 应用开发范式。掌握了这些核心技术后,你可以轻松扩展到更多场景:接入 telegram 或微信平台构建聊天机器人、添加语音识别和合成实现多模态交互、集成到企业知识管理系统提供智能搜索等。
- ai 技术的门槛正在迅速降低,现在的关键是动手实践。希望这篇文章能够成为你探索 ai 应用开发的起点。不要满足于照抄代码,尝试修改参数、替换模型、添加新功能,在实践中深化理解。当你看到自己构建的系统能够真正帮助人们解决问题时,那种成就感是无与伦比的。
下一步行动建议:
- 运行本文的代码,搭建你的第一个问答系统
- 准备自己的知识库数据,替换示例内容
- 尝试不同的嵌入模型和生成模型,比较效果
- 添加你自己的创意功能,打造独特的应用
以上就是使用python搭建属于智能问答机器人的实战指南的详细内容,更多关于python智能问答机器人的资料请关注代码网其它相关文章!





发表评论