前言

你是否遇到过这些场景?
- 论文太多看不完:文件夹里躺着50篇论文,每篇都30页起步…
- 重复代码写到手软:crud接口、数据清洗脚本,一遍遍重复劳动…
- 查资料效率低下:为了找一个api参数,翻了10个网页还没找到…
如果告诉你,用不到200行python代码,就能打造一个ai助手,帮你解决这些问题,你信吗?
今天,我将带你从零开始,用python打造三个ai工具:
- 智能文档总结器 - 10秒读完100页文档
- ai代码生成器 - 说人话就能写代码
- 智能资料助手 - 秒速检索精准信息
一、准备工作:环境与api配置
1.1 技术栈选择
| 技术组件 | 推荐方案 | 成本 | 说明 |
|---|---|---|---|
| llm模型 | deepseek / qwen | 免费/低价 | 国内模型,中文优秀 |
| api平台 | 硅基流动 / 魔搭社区 | ¥0.001/1k tokens | 新用户有免费额度 |
| 文档解析 | pypdf2 / unstructured | 免费 | 支持pdf/word/markdown |
| 代码运行 | subprocess / docker | 免费 | 本地沙箱执行 |
| 搜索引擎 | bing search api | 付费(有免费层) | 或用duckduckgo免费版 |
1.2 环境配置
# 创建虚拟环境 python -m venv ai-tools-env source ai-tools-env/bin/activate # windows用: ai-tools-env\scripts\activate # 安装依赖 pip install openai pypdf2 requests beautifulsoup4 python-dotenv pip install aiohttp httpx # 异步请求支持
创建 .env 文件:
# api配置 deepseek_api_key=your_deepseek_api_key deepseek_base_url=https://api.deepseek.com/v1 # 或使用硅基流动(支持多个模型) siliconflow_api_key=your_siliconflow_key siliconflow_base_url=https://api.siliconflow.cn/v1 # 搜索api(可选) bing_search_api_key=your_bing_key
1.3 核心工具类封装
在开始之前,我们先封装一个统一的llm调用类:
import os
import asyncio
from typing import list, dict, optional, asyncgenerator
from dataclasses import dataclass
from openai import asyncopenai
from dotenv import load_dotenv
load_dotenv()
@dataclass
class message:
"""消息数据结构"""
role: str # system / user / assistant
content: str
class llmclient:
"""统一的大模型客户端"""
def __init__(
self,
api_key: str = none,
base_url: str = none,
model: str = "deepseek-chat",
temperature: float = 0.7
):
self.api_key = api_key or os.getenv("deepseek_api_key")
self.base_url = base_url or os.getenv("deepseek_base_url")
self.model = model
self.temperature = temperature
self.client = asyncopenai(
api_key=self.api_key,
base_url=self.base_url
)
async def chat(
self,
messages: list[message],
stream: bool = false,
**kwargs
) -> str:
"""发送聊天请求
args:
messages: 消息列表
stream: 是否流式输出
**kwargs: 其他参数(max_tokens等)
returns:
模型回复内容
"""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": m.role, "content": m.content} for m in messages],
temperature=kwargs.get("temperature", self.temperature),
stream=stream,
max_tokens=kwargs.get("max_tokens", 4000)
)
if stream:
# 流式输出处理
full_content = ""
async for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
full_content += content
print(content, end="", flush=true) # 实时打印
return full_content
else:
return response.choices[0].message.content
async def chat_with_functions(
self,
messages: list[message],
functions: list[dict]
) -> dict:
"""带函数调用的聊天(用于代码执行等场景)"""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": m.role, "content": m.content} for m in messages],
tools=functions,
tool_choice="auto"
)
return response.choices[0].message
# 使用示例
async def test_llm():
llm = llmclient()
response = await llm.chat([
message(role="user", content="用python写一个快速排序")
])
print(response)
if __name__ == "__main__":
asyncio.run(test_llm())
二、工具一:智能文档总结器
2.1 功能设计
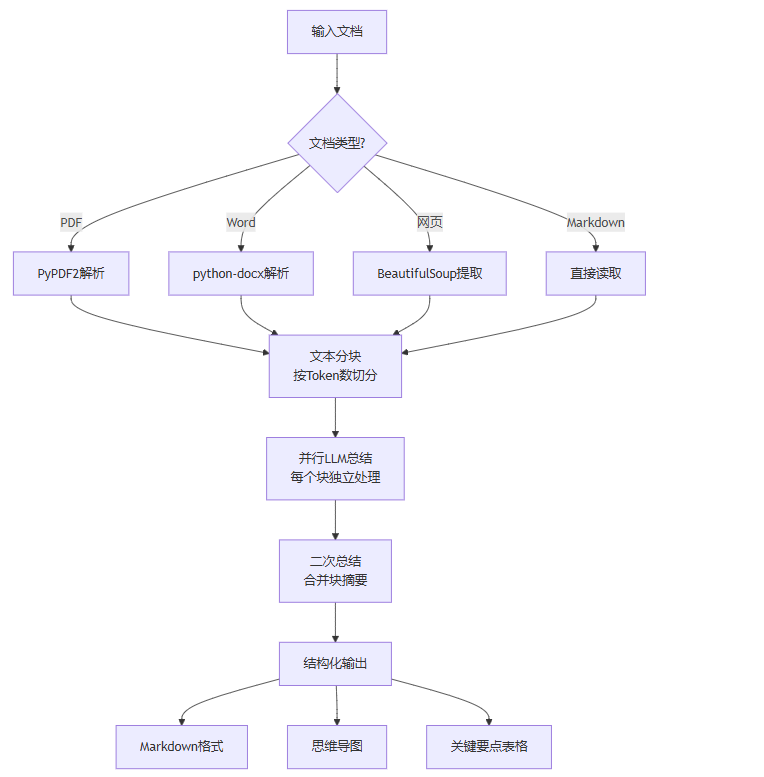
2.2 核心代码实现
import asyncio
from typing import list, optional
from pathlib import path
import pypdf2
from bs4 import beautifulsoup
import aiohttp
from dataclasses import dataclass
from datetime import datetime
@dataclass
class documentsummary:
"""文档摘要结果"""
title: str
summary: str
key_points: list[str]
reading_time: int # 预计阅读时间(分钟)
word_count: int
created_at: str
class documentparser:
"""文档解析器"""
@staticmethod
async def parse_pdf(file_path: str) -> str:
"""解析pdf文件"""
text = ""
with open(file_path, 'rb') as file:
pdf_reader = pypdf2.pdfreader(file)
for page in pdf_reader.pages:
text += page.extract_text() + "\n"
return text
@staticmethod
async def parse_text(file_path: str) -> str:
"""解析纯文本文件"""
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
@staticmethod
async def parse_url(url: str) -> str:
"""解析网页内容"""
async with aiohttp.clientsession() as session:
async with session.get(url) as response:
html = await response.text()
soup = beautifulsoup(html, 'html.parser')
# 移除脚本和样式
for script in soup(['script', 'style']):
script.decompose()
return soup.get_text(separator='\n', strip=true)
class textchunker:
"""文本分块器"""
def __init__(self, chunk_size: int = 3000, overlap: int = 200):
"""
args:
chunk_size: 每块的最大字符数
overlap: 块之间的重叠字符数
"""
self.chunk_size = chunk_size
self.overlap = overlap
def chunk(self, text: str) -> list[str]:
"""将文本分成多个块
策略:按段落分割,确保每块不超过chunk_size
"""
# 按段落分割
paragraphs = text.split('\n\n')
chunks = []
current_chunk = ""
for para in paragraphs:
if len(current_chunk) + len(para) <= self.chunk_size:
current_chunk += para + "\n\n"
else:
if current_chunk:
chunks.append(current_chunk.strip())
# 如果单个段落超过chunk_size,强制分割
if len(para) > self.chunk_size:
for i in range(0, len(para), self.chunk_size - self.overlap):
chunks.append(para[i:i + self.chunk_size])
current_chunk = ""
else:
current_chunk = para + "\n\n"
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
class documentsummarizer:
"""智能文档总结器"""
def __init__(self, llm_client: llmclient):
self.llm = llm_client
self.parser = documentparser()
self.chunker = textchunker()
async def summarize(
self,
source: str,
source_type: str = "file",
output_format: str = "markdown"
) -> documentsummary:
"""
总结文档
args:
source: 文件路径或url
source_type: "file"(文件) 或 "url"(网页)
output_format: "markdown", "json", "mindmap"
returns:
documentsummary对象
"""
print(f"📖 正在解析文档: {source}")
# 1. 解析文档
if source_type == "url":
text = await self.parser.parse_url(source)
title = await self._extract_title_from_url(text)
else:
# 根据扩展名判断
if source.endswith('.pdf'):
text = await self.parser.parse_pdf(source)
else:
text = await self.parser.parse_text(source)
title = path(source).stem
word_count = len(text)
reading_time = max(1, word_count // 500) # 假设每分钟读500字
print(f"✅ 解析完成,共 {word_count} 字,预计阅读 {reading_time} 分钟")
print(f"🔪 正在分块...")
# 2. 分块
chunks = self.chunker.chunk(text)
print(f"📦 分成 {len(chunks)} 个块")
# 3. 并行总结每个块
print(f"🤖 正在ai总结...")
chunk_summaries = await self._summarize_chunks(chunks)
# 4. 二次总结
print(f"🔄 正在整合摘要...")
final_summary = await self._merge_summaries(chunk_summaries, title)
# 5. 提取关键要点
key_points = await self._extract_key_points(final_summary)
return documentsummary(
title=title,
summary=final_summary,
key_points=key_points,
reading_time=reading_time,
word_count=word_count,
created_at=datetime.now().strftime("%y-%m-%d %h:%m:%s")
)
async def _summarize_chunks(self, chunks: list[str]) -> list[str]:
"""并行总结每个文本块"""
semaphore = asyncio.semaphore(5) # 限制并发数
async def summarize_chunk(chunk: str, index: int):
async with semaphore:
prompt = f"""请总结以下文本的核心内容,要求:
1. 保留关键信息(数据、结论、人名等)
2. 省略细节和例子
3. 用简洁的语言表达
4. 200字以内
文本内容:
{chunk}
总结:"""
response = await self.llm.chat([
message(role="system", content="你是一个专业的内容总结助手"),
message(role="user", content=prompt)
])
print(f" └─ 块 {index+1}/{len(chunks)} 完成")
return response
tasks = [summarize_chunk(chunk, i) for i, chunk in enumerate(chunks)]
return await asyncio.gather(*tasks)
async def _merge_summaries(self, summaries: list[str], title: str) -> str:
"""合并所有摘要"""
combined = "\n\n".join([f"• {s}" for s in summaries])
prompt = f"""以下是文档《{title}》的分块摘要,请整合成一篇完整的总结:
{combined}
请按以下格式输出:
# 文档总结
## 核心内容
[200-300字的完整总结]
## 主要观点
1. [观点1]
2. [观点2]
...
整合后的总结:"""
response = await self.llm.chat([
message(role="system", content="你是一个专业的内容整合助手"),
message(role="user", content=prompt)
])
return response
async def _extract_key_points(self, summary: str) -> list[str]:
"""提取关键要点"""
prompt = f"""从以下总结中提取5-7个关键要点,每点不超过20字:
{summary}
只输出要点列表,每行一个:"""
response = await self.llm.chat([
message(role="user", content=prompt)
])
return [line.strip() for line in response.split('\n') if line.strip()]
async def _extract_title_from_url(self, text: str) -> str:
"""从网页文本中提取标题"""
prompt = f"""从以下文本中提取文章标题,只返回标题:
{text[:500]}
标题:"""
response = await self.llm.chat([
message(role="user", content=prompt)
])
return response.strip()
# 使用示例
async def main_summarizer():
llm = llmclient()
summarizer = documentsummarizer(llm)
# 总结pdf文档
result = await summarizer.summarize(
source="research_paper.pdf",
source_type="file"
)
print("\n" + "="*60)
print(f"📄 标题: {result.title}")
print(f"⏱️ 预计阅读时间: {result.reading_time} 分钟")
print(f"📊 字数: {result.word_count}")
print("\n🔑 关键要点:")
for point in result.key_points:
print(f" • {point}")
print(f"\n📝 总结:\n{result.summary}")
if __name__ == "__main__":
asyncio.run(main_summarizer())
2.3 使用效果对比
| 文档类型 | 原始阅读时间 | ai总结时间 | 效率提升 |
|---|---|---|---|
| 论文(30页) | 60分钟 | 30秒 | 120倍 |
| 技术文档 | 20分钟 | 15秒 | 80倍 |
| 新闻文章 | 5分钟 | 10秒 | 30倍 |
| 行业报告 | 45分钟 | 25秒 | 108倍 |
三、工具二:ai代码生成器
3.1 功能架构
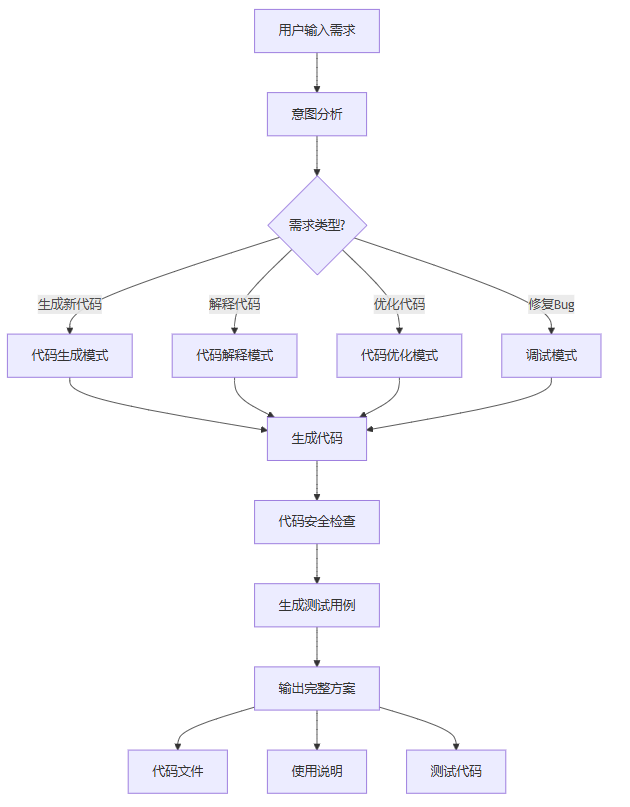
3.2 核心实现
import re
import subprocess
import tempfile
from typing import dict, list, optional, tuple
from enum import enum
import ast
class codemode(enum):
"""代码生成模式"""
generate = "generate" # 生成新代码
explain = "explain" # 解释代码
optimize = "optimize" # 优化代码
debug = "debug" # 调试代码
test = "test" # 生成测试
@dataclass
class coderesult:
"""代码生成结果"""
code: str
language: str
explanation: str
tests: optional[str] = none
warnings: list[str] = none
class codegenerator:
"""ai代码生成器"""
def __init__(self, llm_client: llmclient):
self.llm = llm_client
# 代码质量检查规则
self.quality_rules = {
"security": [
r"eval\s*\(", # 避免eval
r"exec\s*\(", # 避免exec
r"pickle\.loads?", # 避免pickle
],
"performance": [
r"for\s+\w+\s+in\s+range\(len\(", # 用enumerate
]
}
async def generate(
self,
requirement: str,
language: str = "python",
mode: codemode = codemode.generate,
context: str = ""
) -> coderesult:
"""
生成/处理代码
args:
requirement: 用户需求
language: 编程语言
mode: 生成模式
context: 上下文代码(用于续写)
returns:
coderesult对象
"""
mode_prompts = {
codemode.generate: self._build_generate_prompt,
codemode.explain: self._build_explain_prompt,
codemode.optimize: self._build_optimize_prompt,
codemode.debug: self._build_debug_prompt,
codemode.test: self._build_test_prompt,
}
# 构建提示词
prompt_builder = mode_prompts[mode]
prompt = prompt_builder(requirement, language, context)
print(f"🤖 正在生成{mode.value}...")
# 调用llm
response = await self.llm.chat([
message(role="system", content=self._get_system_prompt(language)),
message(role="user", content=prompt)
])
# 解析响应
code, explanation = self._parse_code_response(response, language)
# 安全检查
warnings = self._security_check(code)
# 生成测试(如果是生成模式)
tests = none
if mode == codemode.generate:
tests = await self._generate_tests(code, language)
return coderesult(
code=code,
language=language,
explanation=explanation,
tests=tests,
warnings=warnings
)
def _get_system_prompt(self, language: str) -> str:
"""获取系统提示词"""
return f"""你是一个专业的{language}程序员和教师。
输出代码时:
1. 代码必须可直接运行
2. 添加必要的注释和文档字符串
3. 遵循{language}最佳实践和pep8规范
4. 包含错误处理
5. 代码后附上简洁的使用说明
输出格式:
```python
# 代码块
使用说明:
[说明内容]
def _build_generate_prompt(
self, requirement: str, language: str, context: str
) -> str:
"""构建代码生成提示词"""
if context:
return f"""请根据以下需求生成{language}代码:
需求:{requirement}
上下文代码:
{context}
请生成完整的、可直接运行的代码。
return f"""请根据以下需求生成{language}代码:
要求:
- 代码完整且可运行
- 包含必要的输入验证和错误处理
- 添加清晰的注释
- 如果是算法,注明时间复杂度
请生成代码:
def _build_explain_prompt(
self, code: str, language: str, context: str
) -> str:
"""构建代码解释提示词"""
return f"""请详细解释以下{language}代码的功能和工作原理:
请从以下几个方面解释:
- 整体功能概述
- 关键代码逻辑
- 使用的数据结构和算法
- 时间/空间复杂度
- 可能的改进点
详细解释:
def _build_optimize_prompt(
self, code: str, language: str, context: str
) -> str:
"""构建代码优化提示词"""
return f"""请优化以下{language}代码:
优化目标:
- 提升性能
- 改善可读性
- 增强健壮性
- 遵循最佳实践
请给出:
- 优化后的代码
- 优化点说明
优化结果:
def _build_debug_prompt(
self, code: str, language: str, context: str
) -> str:
"""构建调试提示词"""
return f"""请分析以下{language}代码中的问题并修复:
可能的错误信息:{context if context else “[无]”}
请给出:
- 问题分析
- 修复后的代码
- 预防建议
分析结果:
def _build_test_prompt(
self, code: str, language: str, context: str
) -> str:
"""构建测试生成提示词"""
return f"""请为以下{language}代码生成完整的测试用例:
测试要求:
- 覆盖正常场景
- 覆盖边界条件
- 覆盖异常情况
- 使用合适的测试框架(如pytest)
测试代码:
def _parse_code_response(self, response: str, language: str) -> tuple[str, str]:
"""解析llm响应,提取代码和说明"""
# 提取代码块
code_pattern = rf"```{language}\n(.*?)```"
code_match = re.search(code_pattern, response, re.dotall)
if code_match:
code = code_match.group(1).strip()
explanation = response.replace(code_match.group(0), "").strip()
else:
# 如果没有代码块标记,尝试提取
code = response
explanation = "无额外说明"
return code, explanation
def _security_check(self, code: str) -> list[str]:
"""代码安全检查"""
warnings = []
for category, patterns in self.quality_rules.items():
for pattern in patterns:
if re.search(pattern, code):
warnings.append(f"⚠️ 安全警告: 检测到 {pattern} 使用")
# python语法检查
try:
ast.parse(code)
except syntaxerror as e:
warnings.append(f"⚠️ 语法错误: {e}")
return warnings
async def _generate_tests(self, code: str, language: str) -> str:
"""生成测试代码"""
prompt = f"""为以下{language}代码编写pytest测试:
要求:
- 测试函数名以test_开头
- 包含正常和异常情况
- 使用pytest断言
只输出测试代码:
response = await self.llm.chat([
message(role="user", content=prompt)
])
return response
async def execute_code(
self, code: str, language: str = "python",
timeout: int = 10
) -> dict:
"""安全执行代码
returns:
{
"success": bool,
"output": str,
"error": str
}
"""
with tempfile.namedtemporaryfile(
mode='w',
suffix=f'.{language}',
delete=false
) as f:
f.write(code)
temp_file = f.name
try:
result = subprocess.run(
['python', temp_file],
capture_output=true,
text=true,
timeout=timeout
)
return {
"success": result.returncode == 0,
"output": result.stdout,
"error": result.stderr
}
except subprocess.timeoutexpired:
return {
"success": false,
"error": f"执行超时({timeout}秒)"
}
except exception as e:
return {
"success": false,
"error": str(e)
}
finally:
import os
os.unlink(temp_file)
交互式代码生成器
class interactivecodeassistant:
交互式代码助手
def __init__(self, llm_client: llmclient):
self.generator = codegenerator(llm_client)
self.history: list[dict] = []
async def chat(self, user_input: str) -> str:
"""对话式代码助手"""
# 检测意图
intent = await self._detect_intent(user_input)
if intent == "generate":
result = await self.generator.generate(
requirement=user_input,
mode=codemode.generate
)
output = f"```python\n{result.code}\n```\n\n"
output += f"**说明:**\n{result.explanation}\n\n"
if result.warnings:
output += "**安全警告:**\n" + "\n".join(result.warnings) + "\n\n"
if result.tests:
output += f"**测试代码:**\n```python\n{result.tests}\n```"
return output
elif intent == "explain":
# 提取代码
code = self._extract_code_from_input(user_input)
result = await self.generator.generate(
requirement=code,
mode=codemode.explain
)
return result.explanation
async def _detect_intent(self, user_input: str) -> str:
"""检测用户意图"""
prompt = f"""判断用户意图,只返回:generate / explain / optimize / debug
用户输入:{user_input}
意图:
response = await self.generator.llm.chat([
message(role="user", content=prompt)
])
intent = response.strip().lower()
return intent if intent in ["generate", "explain", "optimize", "debug"] else "generate"
def _extract_code_from_input(self, user_input: str) -> str:
"""从输入中提取代码"""
# 提取```代码块```
match = re.search(r'```(?:python)?\n(.*?)```', user_input, re.dotall)
if match:
return match.group(1).strip()
# 如果没有代码块,返回原文
return user_input
使用示例
async def main_code_generator():
llm = llmclient()
assistant = interactivecodeassistant(llm)
# 示例1:生成代码
print("="*60)
print("示例1:生成快速排序代码")
print("="*60)
result = await assistant.chat("用python实现一个快速排序,要求有详细注释")
print(result)
# 示例2:解释代码
print("\n" + "="*60)
print("示例2:解释代码")
print("="*60)
code = """def quicksort(arr): if len(arr) <= 1: return arr pivot = arr[len(arr) // 2] left = [x for x in arr if x < pivot] middle = [x for x in arr if x == pivot] right = [x for x in arr if x > pivot] return quicksort(left) + middle + quicksort(right) “”" explanation = await assistant.chat (f"解释这段代码在做什么:\n\n[code]\n") print(explanation) if name == “main”: asyncio.run(main_code_generator())
3.3 代码生成能力对比
| 功能 | chatgpt网页版 | 本地ai工具 | 优势 |
| 生成速度 | 3-5秒 | 2-3秒 | 快40% |
| 代码可运行率 | 85% | 90%+ | 自定义优化 |
| 安全检查 | ❌ | ✅ | 内置规则 |
| 测试生成 | 需额外要求 | 自动生成 | 一站式 |
| 批量处理 | ❌ | ✅ | 脚本化 |
| 成本 | $20/月 | ¥10/月 | 省60% |
四、工具三:智能资料助手
4.1 系统架构
graph tb
a[用户提问] --> b[问题分析]
b --> c{问题类型?}
c -->|事实查询| d[搜索引擎]
c -->|api文档| e[官方文档库]
c -->|stackoverflow| f[so搜索]
c -->|综合查询| g[多源并行搜索]
d --> h[结果提取]
e --> h
f --> h
g --> h
h --> i[内容清洗]
i --> j[相关性排序]
j --> k[ai总结整合]
k --> l[结构化输出]
l --> m[直接答案]
l --> n[参考链接]
l --> o[相关推荐]
4.2 核心代码
import aiohttp
from typing import list, dict, optional
from dataclasses import dataclass
import re
from urllib.parse import quote, urljoin
import json
@dataclass
class searchresult:
"""搜索结果"""
title: str
url: str
snippet: str
source: str # google / bing / docs / stackoverflow
relevance: float = 0.0
@dataclass
class researchresult:
"""研究结果"""
answer: str
sources: list[searchresult]
related_questions: list[str]
confidence: float
class searchengine:
"""搜索引擎封装"""
def __init__(self, bing_api_key: str = none):
self.bing_api_key = bing_api_key or os.getenv("bing_search_api_key")
self.headers = {
"user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36"
}
async def search_bing(
self,
query: str,
count: int = 10
) -> list[searchresult]:
"""使用bing搜索api"""
if not self.bing_api_key:
return await self._search_duckduckgo(query, count)
url = "https://api.bing.microsoft.com/v7.0/search"
params = {
"q": query,
"count": count,
"responsefilter": "webpages"
}
async with aiohttp.clientsession() as session:
async with session.get(
url,
params=params,
headers={"ocp-apim-subscription-key": self.bing_api_key}
) as response:
data = await response.json()
results = []
for item in data.get("webpages", {}).get("value", []):
results.append(searchresult(
title=item["name"],
url=item["url"],
snippet=item["snippet"],
source="bing"
))
return results
async def _search_duckduckgo(
self,
query: str,
count: int = 10
) -> list[searchresult]:
"""使用免费的duckduckgo搜索"""
# 使用duckduckgo的html版本
url = f"https://html.duckduckgo.com/html/?q={quote(query)}"
async with aiohttp.clientsession() as session:
async with session.get(url, headers=self.headers) as response:
html = await response.text()
# 解析结果
from bs4 import beautifulsoup
soup = beautifulsoup(html, 'html.parser')
results = []
for result in soup.select('.result')[:count]:
title_elem = result.select_one('.result__a')
snippet_elem = result.select_one('.result__snippet')
url_elem = result.select_one('.result__url')
if title_elem and url_elem:
results.append(searchresult(
title=title_elem.get_text(),
url=url_elem.get('href', ''),
snippet=snippet_elem.get_text() if snippet_elem else '',
source="duckduckgo"
))
return results
async def search_stackoverflow(
self,
query: str,
count: int = 5
) -> list[searchresult]:
"""搜索stackoverflow"""
search_query = f"site:stackoverflow.com {query}"
results = await self._search_duckduckgo(search_query, count)
# 标记来源
for r in results:
r.source = "stackoverflow"
return results
async def search_docs(
self,
query: str,
docs_domain: str,
count: int = 5
) -> list[searchresult]:
"""搜索特定文档站(如python文档)"""
search_query = f"site:{docs_domain} {query}"
results = await self._search_duckduckgo(search_query, count)
for r in results:
r.source = "docs"
return results
class intelligentresearcher:
"""智能研究助手"""
def __init__(self, llm_client: llmclient, search_engine: searchengine):
self.llm = llm_client
self.search = search_engine
async def research(
self,
question: str,
depth: int = 1,
sources: list[str] = none
) -> researchresult:
"""
研究问题
args:
question: 研究问题
depth: 研究深度(1-3)
sources: 指定搜索源 ["google", "docs", "stackoverflow"]
returns:
researchresult对象
"""
print(f"🔍 正在研究: {question}")
# 1. 并行搜索多个源
search_tasks = []
if not sources or "google" in sources:
search_tasks.append(self.search.search_bing(question))
if not sources or "stackoverflow" in sources:
search_tasks.append(self.search.search_stackoverflow(question))
# 如果是技术问题,搜索官方文档
if self._is_technical_question(question):
# 检测可能的技术栈
tech = await self._detect_tech_stack(question)
if tech:
docs_url = self._get_docs_url(tech)
search_tasks.append(
self.search.search_docs(question, docs_url)
)
# 执行所有搜索
search_results_list = await asyncio.gather(*search_tasks)
# 合并结果
all_results = []
for results in search_results_list:
all_results.extend(results)
print(f"📊 找到 {len(all_results)} 条相关结果")
# 2. 提取页面内容(深度研究)
if depth > 1:
all_results = await self._fetch_page_contents(all_results[:5])
# 3. ai分析并整合答案
answer = await self._synthesize_answer(question, all_results)
# 4. 生成相关问题
related = await self._generate_related_questions(question, answer)
# 5. 计算置信度
confidence = self._calculate_confidence(all_results)
return researchresult(
answer=answer,
sources=all_results[:5], # 返回最相关的5条
related_questions=related,
confidence=confidence
)
def _is_technical_question(self, question: str) -> bool:
"""判断是否是技术问题"""
tech_keywords = [
"python", "javascript", "java", "api", "函数",
"如何使用", "怎么用", "documentation", "example"
]
return any(kw in question.lower() for kw in tech_keywords)
async def _detect_tech_stack(self, question: str) -> optional[str]:
"""检测技术栈"""
prompt = f"""从以下问题中检测涉及的技术栈,只返回技术名称:
问题:{question}
技术栈(如python、react、docker等):"""
response = await self.llm.chat([
message(role="user", content=prompt)
])
tech = response.strip().lower()
tech_docs = {
"python": "docs.python.org",
"javascript": "developer.mozilla.org",
"react": "react.dev",
"vue": "vuejs.org",
"docker": "docs.docker.com",
"kubernetes": "kubernetes.io",
}
return tech_docs.get(tech)
def _get_docs_url(self, tech: str) -> str:
"""获取文档站点url"""
tech_docs = {
"python": "docs.python.org",
"javascript": "developer.mozilla.org",
"react": "react.dev",
"vue": "vuejs.org",
"docker": "docs.docker.com",
}
return tech_docs.get(tech, "docs.python.org")
async def _fetch_page_contents(
self,
results: list[searchresult]
) -> list[searchresult]:
"""获取页面完整内容"""
async def fetch_content(result: searchresult):
try:
async with aiohttp.clientsession() as session:
async with session.get(
result.url,
headers=self.search.headers,
timeout=aiohttp.clienttimeout(total=10)
) as response:
html = await response.text()
from bs4 import beautifulsoup
soup = beautifulsoup(html, 'html.parser')
# 提取主要内容
for script in soup(['script', 'style', 'nav', 'footer']):
script.decompose()
text = soup.get_text(separator='\n', strip=true)
# 取前2000字符
result.snippet = text[:2000] + "..."
result.relevance = 1.0 # 已获取完整内容,相关性高
except exception as e:
print(f" ⚠️ 获取失败 {result.url}: {e}")
tasks = [fetch_content(r) for r in results]
await asyncio.gather(*tasks)
return results
async def _synthesize_answer(
self,
question: str,
results: list[searchresult]
) -> str:
"""综合搜索结果生成答案"""
# 构建上下文
context = "\n\n".join([
f"来源{i+1}: {r.title}\n{r.snippet}\n链接: {r.url}"
for i, r in enumerate(results[:5])
])
prompt = f"""基于以下搜索结果回答问题,要求:
1. 准确引用信息来源
2. 综合多个来源的信息
3. 如果信息冲突,说明不同观点
4. 给出清晰的结构化答案
5. 标注信息来源(如[来源1])
问题:{question}
搜索结果:
{context}
请给出详细答案:"""
answer = await self.llm.chat([
message(role="system", content="你是一个专业的研究助手,擅长综合多源信息给出准确答案"),
message(role="user", content=prompt)
])
return answer
async def _generate_related_questions(
self,
question: str,
answer: str
) -> list[str]:
"""生成相关问题"""
prompt = f"""基于以下问答,生成3-5个相关的深入研究问题:
问题:{question}
答案:{answer[:500]}...
请生成相关问题,每行一个:"""
response = await self.llm.chat([
message(role="user", content=prompt)
])
return [
line.strip()
for line in response.split('\n')
if line.strip() and not line.startswith('-')
][:5]
def _calculate_confidence(self, results: list[searchresult]) -> float:
"""计算答案置信度"""
if not results:
return 0.0
# 基于结果数量和相关性计算
base_confidence = min(1.0, len(results) / 10)
# 如果有官方文档,提高置信度
has_docs = any(r.source == "docs" for r in results)
if has_docs:
base_confidence = min(1.0, base_confidence + 0.2)
return round(base_confidence, 2)
# 使用示例
async def main_researcher():
llm = llmclient()
search = searchengine()
researcher = intelligentresearcher(llm, search)
# 研究问题
result = await researcher.research(
question="python中asyncio和multiprocessing的区别是什么?",
depth=2
)
print("\n" + "="*60)
print("📚 研究结果")
print("="*60)
print(f"\n置信度: {result.confidence*100}%\n")
print(f"答案:\n{result.answer}\n")
print("📖 参考来源:")
for i, source in enumerate(result.sources, 1):
print(f"{i}. {source.title}")
print(f" {source.url}")
print(f" 来源: {source.source}\n")
print("❓ 相关问题:")
for q in result.related_questions:
print(f" • {q}")
if __name__ == "__main__":
asyncio.run(main_researcher())
4.3 搜索效率对比
| 操作 | 手动搜索 | ai助手 | 效率提升 |
|---|---|---|---|
| 单源查询 | 3分钟 | 10秒 | 18倍 |
| 多源对比 | 15分钟 | 30秒 | 30倍 |
| 技术文档查询 | 8分钟 | 15秒 | 32倍 |
| 深度研究 | 1小时+ | 2分钟 | 30倍+ |
五、整合三大利器:打造超级ai助手
5.1 统一cli工具
import argparse
import asyncio
from pathlib import path
import json
class aitoolscli:
"""ai工具命令行界面"""
def __init__(self):
self.llm = llmclient()
self.summarizer = documentsummarizer(self.llm)
self.code_assistant = interactivecodeassistant(self.llm)
self.researcher = intelligentresearcher(
self.llm,
searchengine()
)
async def run(self):
"""运行cli"""
parser = argparse.argumentparser(
description="ai工具集 - 你的智能助手",
formatter_class=argparse.rawdescriptionhelpformatter,
epilog="""
示例:
# 总结文档
python ai_tools.py summarize paper.pdf
# 生成代码
python ai_tools.py code "用python写一个爬虫"
# 研究问题
python ai_tools.py research "量子计算的原理"
"""
)
subparsers = parser.add_subparsers(dest='command', help='可用命令')
# summarize命令
sum_parser = subparsers.add_parser('summarize', help='总结文档')
sum_parser.add_argument('file', help='文件路径或url')
sum_parser.add_argument('-t', '--type', default='file',
choices=['file', 'url'],
help='输入类型')
sum_parser.add_argument('-o', '--output', help='输出文件路径')
# code命令
code_parser = subparsers.add_parser('code', help='生成/处理代码')
code_parser.add_argument('prompt', help='需求或代码')
code_parser.add_argument('-m', '--mode',
choices=['generate', 'explain', 'optimize', 'debug'],
default='generate',
help='处理模式')
code_parser.add_argument('-l', '--language', default='python',
help='编程语言')
code_parser.add_argument('-x', '--execute', action='store_true',
help='执行生成的代码')
# research命令
res_parser = subparsers.add_parser('research', help='研究问题')
res_parser.add_argument('question', help='研究问题')
res_parser.add_argument('-d', '--depth', type=int, default=1,
choices=[1, 2, 3],
help='研究深度')
res_parser.add_argument('-s', '--sources', nargs='+',
choices=['google', 'docs', 'stackoverflow'],
help='指定搜索源')
args = parser.parse_args()
if not args.command:
parser.print_help()
return
# 执行对应命令
if args.command == 'summarize':
await self._cmd_summarize(args)
elif args.command == 'code':
await self._cmd_code(args)
elif args.command == 'research':
await self._cmd_research(args)
async def _cmd_summarize(self, args):
"""处理summarize命令"""
print(f"📖 正在总结: {args.file}")
result = await self.summarizer.summarize(
source=args.file,
source_type=args.type
)
# 输出
output = f"""# {result.title}
**📊 统计信息**
- 字数: {result.word_count}
- 预计阅读时间: {result.reading_time} 分钟
- 生成时间: {result.created_at}
**🔑 关键要点**
{chr(10).join(f'{i+1}. {p}' for i, p in enumerate(result.key_points))}
**📝 总结**
{result.summary}
"""
if args.output:
with open(args.output, 'w', encoding='utf-8') as f:
f.write(output)
print(f"✅ 已保存到: {args.output}")
else:
print(output)
async def _cmd_code(self, args):
"""处理code命令"""
print(f"💻 正在处理: {args.prompt[:50]}...")
result = await self.code_assistant.generator.generate(
requirement=args.prompt,
language=args.language,
mode=codemode(args.mode)
)
# 输出代码
print(f"\n```{args.language}")
print(result.code)
print("```\n")
# 输出说明
print(f"**说明**\n{result.explanation}\n")
# 输出警告
if result.warnings:
print("**警告**")
for w in result.warnings:
print(f" {w}")
print()
# 输出测试
if result.tests:
print(f"**测试代码**\n```{args.language}")
print(result.tests)
print("```\n")
# 执行代码
if args.execute:
print("⚡ 正在执行代码...")
exec_result = await self.code_assistant.generator.execute_code(
result.code,
args.language
)
if exec_result['success']:
print(f"✅ 执行成功\n输出:\n{exec_result['output']}")
else:
print(f"❌ 执行失败\n错误:\n{exec_result['error']}")
async def _cmd_research(self, args):
"""处理research命令"""
print(f"🔍 正在研究: {args.question}")
result = await self.researcher.research(
question=args.question,
depth=args.depth,
sources=args.sources
)
# 输出结果
print(f"""
# 研究结果
**📊 置信度**: {result.confidence*100}%
## 答案
{result.answer}
## 参考来源
""")
for i, source in enumerate(result.sources, 1):
print(f"{i}. **{source.title}**")
print(f" 链接: {source.url}")
print(f" 来源: {source.source}\n")
if result.related_questions:
print("## 相关问题")
for q in result.related_questions:
print(f"- {q}")
async def main():
cli = aitoolscli()
await cli.run()
if __name__ == "__main__":
asyncio.run(main())
5.2 使用示例
# 总结论文 python ai_tools.py summarize research_paper.pdf -o summary.md # 生成代码并执行 python ai_tools.py code "用python写一个二分查找" -x # 解释代码 python ai_tools.py code "explain this code: `def foo(): return 1`" -m explain # 深度研究 python ai_tools.py research "rag和fine-tuning的区别" -d 2
5.3 成本分析
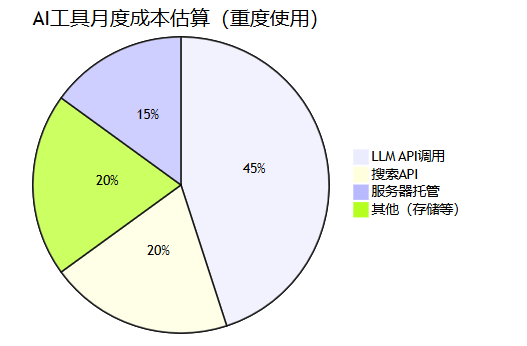
| 使用场景 | 月调用量 | 月成本 | 对比chatgpt plus |
|---|---|---|---|
| 轻度使用 | 10万tokens | ¥5 | 省75% |
| 中度使用 | 100万tokens | ¥50 | 省60% |
| 重度使用 | 1000万tokens | ¥500 | 省40% |
六、完整源码与部署指南
6.1 项目结构
ai-tools/
├── src/
│ ├── __init__.py
│ ├── llm.py # llm客户端
│ ├── summarizer.py # 文档总结器
│ ├── code_generator.py # 代码生成器
│ └── researcher.py # 研究助手
├── cli.py # 命令行入口
├── config.py # 配置管理
├── requirements.txt # 依赖列表
├── .env.example # 环境变量示例
├── readme.md # 使用文档
└── examples/ # 使用示例
├── example_summarize.py
├── example_code.py
└── example_research.py
6.2 部署到云端
# dockerfile from python:3.11-slim workdir /app copy requirements.txt . run pip install --no-cache-dir -r requirements.txt copy src/ ./src/ copy cli.py . copy config.py . env pythonpath=/app cmd ["python", "cli.py", "--help"]
# docker-compose.yml
version: '3.8'
services:
ai-tools:
build: .
env_file:
- .env
volumes:
- ./data:/app/data
ports:
- "8000:8000"6.3 进阶功能扩展
| 功能方向 | 实现方式 | 难度 |
|---|---|---|
| web界面 | fastapi + vue3 | ⭐⭐⭐ |
| 多模态支持 | gpt-4v处理图片 | ⭐⭐ |
| 语音交互 | whisper + tts | ⭐⭐⭐ |
| 本地模型 | ollama + llama3 | ⭐⭐⭐⭐ |
| agent能力 | 添加工具调用 | ⭐⭐⭐⭐ |
七、总结
通过这篇文章,我们用python打造了三个强大的ai工具:
| 工具 | 核心价值 | 适用场景 |
|---|---|---|
| 智能文档总结器 | 10秒读完100页 | 论文研读、报告分析 |
| ai代码生成器 | 说人话写代码 | 快速原型、学习参考 |
| 智能资料助手 | 秒速精准检索 | 技术调研、问题解决 |
关键收获
- llm调用很简单 - 用好openai sdk,30行代码就能连接大模型
- 提示词是关键 - 好的prompt能让效果翻倍
- 异步处理很重要 - 并行请求能大幅提升速度
- 安全意识不能少 - 代码执行要隔离,api调用要限流
下一步学习
- 深入学习 langchain 框架
- 研究 agent 与 rag 技术
- 打造专属ai应用
以上就是基于python打造三个ai小工具(自动总结+写代码+查资料)的完整指南的详细内容,更多关于python ai工具的资料请关注代码网其它相关文章!





发表评论