在现代分布式系统和高并发服务架构中,磁盘 i/o 性能往往是系统瓶颈的重要来源。无论是数据库服务器、日志收集系统,还是缓存层与持久化存储的交互,磁盘读写速度直接决定了整体响应能力。特别是在 java 应用广泛部署的 linux 服务器环境中,掌握磁盘 i/o 监控技巧是保障服务稳定性和性能优化的关键。
本文将从基础命令工具开始,逐步深入到 java 程序如何集成磁盘监控,最终构建一个完整的自动化监控体系。我们将涵盖:
- linux 原生命令行工具(iostat, iotop, sar)
- /proc 和 /sys 文件系统中的 i/o 数据
- java 中调用系统命令获取磁盘指标
- 使用 jmx 暴露自定义磁盘监控 mbean
- prometheus + grafana 构建可视化大盘
- 告警策略与阈值配置建议
- 性能调优实战案例
无论你是 devops 工程师、java 后端开发者,还是系统架构师,都能从本文获得实用技能。
为什么需要监控磁盘 i/o?
磁盘 i/o 是系统中最慢的操作之一。相比内存访问(纳秒级)和 cpu 运算(皮秒级),即使是 nvme ssd 也需要微秒甚至毫秒级别的响应时间。当磁盘成为瓶颈时,会导致:
- 请求堆积、线程阻塞
- gc 频率升高(因日志刷盘慢)
- 数据库写入延迟飙升
- 服务超时、熔断触发
- 用户体验下降
根据 google sre 手册 中的经验法则:“如果你无法度量它,你就无法改进它。” 因此,建立有效的磁盘 i/o 监控体系,是保障系统 sla 的第一步。
linux 原生监控工具概览
1.iostat—— 最常用的 i/o 统计工具
iostat 属于 sysstat 包,提供设备级别的 i/o 统计信息。
# 安装 sysstat(如未安装) sudo apt install sysstat # ubuntu/debian sudo yum install sysstat # centos/rhel # 查看每秒统计,刷新间隔2秒,共5次 iostat -x 2 5
输出示例:
device r/s w/s rkb/s wkb/s rrqm/s wrqm/s %util sda 8.33 2.50 266.67 80.00 0.00 0.20 1.20 nvme0n1 15.40 12.80 1232.00 1024.00 0.00 0.00 8.90
关键字段解释:
r/s,w/s:每秒读/写请求数rkb/s,wkb/s:每秒读/写字节数(kb)%util:设备利用率(接近 100% 表示饱和)
提示:%util 并非绝对性能指标,ssd 多队列并发下即使 %util=100%,也可能未达性能极限。
2.iotop—— 实时进程级 i/o 监控
类似 top,但专注于 i/o:
sudo iotop -opa
参数说明:
-o:仅显示有 i/o 活动的进程-p:仅显示进程(不显示线程)-a:累积模式(显示历史总量)
适合定位“谁在疯狂读写磁盘”。
3.sar—— 历史数据回溯利器
sar 可记录历史 i/o 数据,默认每10分钟采样一次。
# 查看昨天全天磁盘使用情况 sar -d -f /var/log/sysstat/sa$(date -d yesterday +%d) # 实时查看,每3秒一次 sar -d 3 5
从 /proc 和 /sys 获取原始数据
linux 内核通过虚拟文件系统暴露大量运行时数据。
/proc/diskstats
每一行代表一个块设备的统计:
cat /proc/diskstats
输出格式(部分字段):
8 0 sda 12345 0 67890 123 4567 0 89012 456 0 579 579
字段含义(按顺序):
- 主设备号
- 次设备号
- 设备名
- 读完成次数
- 合并读次数
- 读扇区数(*512字节)
- 读花费毫秒数
- 写完成次数
- 合并写次数
- 写扇区数
- 写花费毫秒数
…
我们可以通过两次采样差值计算实时速率。
/sys/block/[dev]/stat
结构与 /proc/diskstats 类似,但按设备组织:
cat /sys/block/sda/stat
java 中监控磁盘 i/o —— 基础版
下面我们用 java 编写一个简单的磁盘监控器,调用 iostat 并解析结果。
import java.io.bufferedreader;
import java.io.inputstreamreader;
import java.util.concurrent.executors;
import java.util.concurrent.scheduledexecutorservice;
import java.util.concurrent.timeunit;
public class simplediskmonitor {
public static void main(string[] args) {
scheduledexecutorservice scheduler = executors.newscheduledthreadpool(1);
scheduler.scheduleatfixedrate(() -> {
try {
process process = runtime.getruntime().exec("iostat -x 1 1");
bufferedreader reader = new bufferedreader(new inputstreamreader(process.getinputstream()));
string line;
boolean startreading = false;
while ((line = reader.readline()) != null) {
if (line.startswith("device")) {
startreading = true;
continue;
}
if (startreading && !line.trim().isempty()) {
string[] parts = line.split("\\s+");
if (parts.length >= 14) {
string device = parts[0];
double util = double.parsedouble(parts[13]);
system.out.printf("[%s] device: %-8s utilization: %.2f%%%n",
java.time.localdatetime.now(), device, util);
}
}
}
process.waitfor();
} catch (exception e) {
e.printstacktrace();
}
}, 0, 5, timeunit.seconds);
}
}
注意:生产环境慎用 runtime.exec(),存在安全与稳定性风险。建议改用 jni 或 jna 调用底层 api。
使用 sigar 库(已归档,仅作参考)
sigar(system information gatherer and reporter)曾是流行的跨平台系统监控库,现虽已停止维护,但其设计思想仍具参考价值。
maven 依赖(若仓库仍有缓存):
<dependency>
<groupid>org.fusesource</groupid>
<artifactid>sigar</artifactid>
<version>1.6.4</version>
</dependency>
示例代码:
import org.hyperic.sigar.diskusage;
import org.hyperic.sigar.sigar;
import org.hyperic.sigar.sigarexception;
public class sigardiskmonitor {
public static void main(string[] args) throws sigarexception, interruptedexception {
sigar sigar = new sigar();
while (true) {
string[] devices = sigar.getfilesystemlist();
for (string dev : devices) {
try {
diskusage usage = sigar.getdiskusage(dev);
system.out.printf("device: %s, readbytes: %d, writebytes: %d%n",
dev, usage.getreadbytes(), usage.getwritebytes());
} catch (sigarexception e) {
// 忽略不可读设备
}
}
thread.sleep(3000);
}
}
}
替代方案:推荐使用 oshi(operating system and hardware information library),活跃维护中。
使用 oshi 库监控磁盘(推荐)
oshi 是当前 java 生态中最活跃的系统信息库,支持 linux、windows、macos。
添加 maven 依赖:
<dependency>
<groupid>com.github.oshi</groupid>
<artifactid>oshi-core</artifactid>
<version>6.4.4</version>
</dependency>
完整监控示例:
import oshi.systeminfo;
import oshi.hardware.hwdiskstore;
import oshi.hardware.hardwareabstractionlayer;
import java.util.arrays;
import java.util.concurrent.executors;
import java.util.concurrent.scheduledexecutorservice;
import java.util.concurrent.timeunit;
public class oshidiskmonitor {
private static hwdiskstore[] previousdisks = new hwdiskstore[0];
public static void main(string[] args) {
systeminfo si = new systeminfo();
hardwareabstractionlayer hal = si.gethardware();
scheduledexecutorservice scheduler = executors.newscheduledthreadpool(1);
scheduler.scheduleatfixedrate(() -> {
hwdiskstore[] currentdisks = hal.getdiskstores();
if (previousdisks.length == 0) {
previousdisks = currentdisks.clone();
return;
}
long now = system.currenttimemillis();
for (int i = 0; i < currentdisks.length; i++) {
hwdiskstore curr = currentdisks[i];
hwdiskstore prev = findpreviousdisk(curr.getname());
if (prev != null) {
long timediff = now - prev.gettimestamp();
if (timediff <= 0) continue;
double readbytespersec = (curr.getreadbytes() - prev.getreadbytes()) * 1000.0 / timediff;
double writebytespersec = (curr.getwritebytes() - prev.getwritebytes()) * 1000.0 / timediff;
double transferspersec = (curr.getreads() + curr.getwrites() - prev.getreads() - prev.getwrites()) * 1000.0 / timediff;
system.out.printf("[%s] %-10s | r: %7.2f kb/s | w: %7.2f kb/s | iops: %.1f%n",
java.time.localtime.now(),
curr.getname(),
readbytespersec / 1024,
writebytespersec / 1024,
transferspersec);
}
}
previousdisks = currentdisks.clone();
}, 0, 2, timeunit.seconds);
}
private static hwdiskstore findpreviousdisk(string name) {
return arrays.stream(previousdisks)
.filter(d -> d.getname().equals(name))
.findfirst()
.orelse(null);
}
}
输出效果:
[14:23:05.123] sda | r: 128.50 kb/s | w: 64.25 kb/s | iops: 15.3 [14:23:07.125] sda | r: 32.10 kb/s | w: 256.80 kb/s | iops: 8.7 [14:23:09.127] nvme0n1 | r: 1024.00 kb/s | w: 512.00 kb/s | iops: 120.5
使用 jmx 暴露磁盘指标
为了让监控数据被外部系统(如 prometheus、zabbix)采集,我们将其封装为 jmx mbean。
首先定义接口:
public interface diskmonitormbean {
double getreadbytespersecond(string devicename);
double getwritebytespersecond(string devicename);
double getiops(string devicename);
string[] getdevicenames();
}
实现类:
import oshi.systeminfo;
import oshi.hardware.hwdiskstore;
import oshi.hardware.hardwareabstractionlayer;
import javax.management.notification;
import javax.management.notificationbroadcastersupport;
import java.util.hashmap;
import java.util.map;
import java.util.concurrent.executors;
import java.util.concurrent.scheduledexecutorservice;
import java.util.concurrent.timeunit;
public class diskmonitor extends notificationbroadcastersupport implements diskmonitormbean {
private final map<string, hwdiskstore> previousstats = new hashmap<>();
private final hardwareabstractionlayer hal;
private long sequencenumber = 1;
public diskmonitor() {
this.hal = new systeminfo().gethardware();
startsampling();
}
private void startsampling() {
scheduledexecutorservice scheduler = executors.newscheduledthreadpool(1);
scheduler.scheduleatfixedrate(this::sampledisks, 0, 2, timeunit.seconds);
}
private void sampledisks() {
hwdiskstore[] disks = hal.getdiskstores();
long now = system.currenttimemillis();
for (hwdiskstore disk : disks) {
hwdiskstore prev = previousstats.get(disk.getname());
if (prev != null) {
long timediff = now - prev.gettimestamp();
if (timediff > 0) {
double rps = (disk.getreadbytes() - prev.getreadbytes()) * 1000.0 / timediff;
double wps = (disk.getwritebytes() - prev.getwritebytes()) * 1000.0 / timediff;
double iops = (disk.getreads() + disk.getwrites() - prev.getreads() - prev.getwrites()) * 1000.0 / timediff;
// 发送 jmx 通知(可选)
sendnotification(new notification(
"disk.stats.update",
this,
sequencenumber++,
string.format("device %s updated: r=%.2f kb/s, w=%.2f kb/s, iops=%.1f",
disk.getname(), rps/1024, wps/1024, iops)));
}
}
previousstats.put(disk.getname(), disk);
}
}
@override
public double getreadbytespersecond(string devicename) {
hwdiskstore curr = getdiskbyname(devicename);
hwdiskstore prev = previousstats.get(devicename);
if (curr == null || prev == null) return 0.0;
long timediff = curr.gettimestamp() - prev.gettimestamp();
if (timediff <= 0) return 0.0;
return (curr.getreadbytes() - prev.getreadbytes()) * 1000.0 / timediff;
}
@override
public double getwritebytespersecond(string devicename) {
hwdiskstore curr = getdiskbyname(devicename);
hwdiskstore prev = previousstats.get(devicename);
if (curr == null || prev == null) return 0.0;
long timediff = curr.gettimestamp() - prev.gettimestamp();
if (timediff <= 0) return 0.0;
return (curr.getwritebytes() - prev.getwritebytes()) * 1000.0 / timediff;
}
@override
public double getiops(string devicename) {
hwdiskstore curr = getdiskbyname(devicename);
hwdiskstore prev = previousstats.get(devicename);
if (curr == null || prev == null) return 0.0;
long timediff = curr.gettimestamp() - prev.gettimestamp();
if (timediff <= 0) return 0.0;
return (curr.getreads() + curr.getwrites() - prev.getreads() - prev.getwrites()) * 1000.0 / timediff;
}
@override
public string[] getdevicenames() {
return hal.getdiskstores().stream()
.map(hwdiskstore::getname)
.toarray(string[]::new);
}
private hwdiskstore getdiskbyname(string name) {
return arrays.stream(hal.getdiskstores())
.filter(d -> d.getname().equals(name))
.findfirst()
.orelse(null);
}
}
注册 mbean:
import javax.management.mbeanserver;
import javax.management.objectname;
import java.lang.management.managementfactory;
public class jmxregistration {
public static void main(string[] args) throws exception {
mbeanserver mbs = managementfactory.getplatformmbeanserver();
objectname name = new objectname("com.example.monitoring:type=diskmonitor");
diskmonitor monitor = new diskmonitor();
mbs.registermbean(monitor, name);
system.out.println("jmx disk monitor registered. attach with jconsole or visualvm.");
thread.sleep(long.max_value); // keep alive
}
}
启动后,可用 jconsole 连接本地 jvm,查看磁盘指标。
集成 prometheus + grafana
prometheus 是当前最流行的时序数据库,grafana 是强大的可视化工具。我们将 java 应用暴露的 jmx 指标通过 jmx exporter 导出为 prometheus 格式。
步骤 1:下载 jmx_exporter
从 prometheus jmx exporter 页面 下载 jmx_prometheus_javaagent.jar(请自行搜索最新官方发布页)。
步骤 2:编写 config.yaml
rules: - pattern: ".*"
(简单起见,导出所有指标;生产环境应精细化配置)
步骤 3:启动 java 应用时附加 agent
java -javaagent:/path/to/jmx_prometheus_javaagent.jar=8081:/path/to/config.yaml \
-jar your-application.jar
此时访问 http://localhost:8081/metrics 可看到类似:
# help com_example_monitoring_diskmonitor_readbytespersecond
# type com_example_monitoring_diskmonitor_readbytespersecond gauge
com_example_monitoring_diskmonitor_readbytespersecond{devicename="sda",} 131072.0
com_example_monitoring_diskmonitor_writebytespersecond{devicename="sda",} 65536.0
步骤 4:配置 prometheus 抓取
在 prometheus.yml 中添加:
scrape_configs:
- job_name: 'java-disk-monitor'
static_configs:
- targets: ['localhost:8081']
重启 prometheus。
步骤 5:grafana 创建仪表盘
添加 prometheus 数据源,创建新面板,使用 promql 查询:
com_example_monitoring_diskmonitor_readbytespersecond{devicename="sda"} / 1024
单位设为 kb/s,即可看到实时曲线图。
mermaid 图表:磁盘监控架构流程
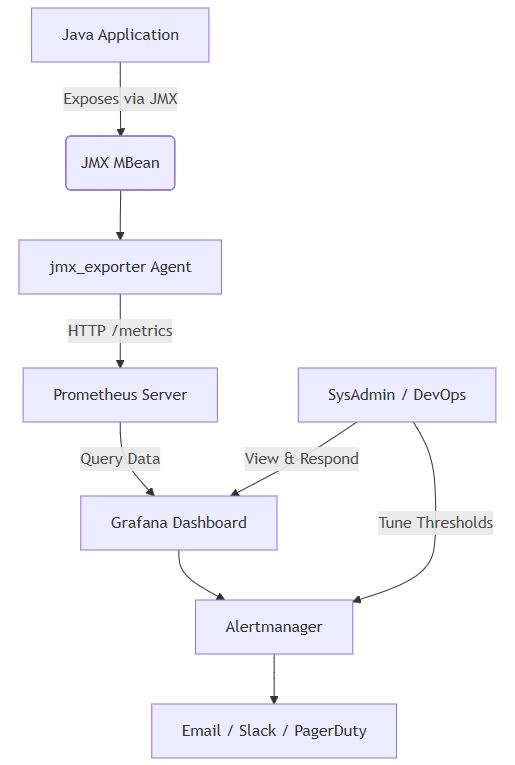
该架构实现了从应用层到告警通道的全链路监控闭环。
告警策略与阈值建议
合理的告警能避免“狼来了”效应。以下是针对磁盘 i/o 的典型告警规则(prometheus alertmanager 配置):
groups:
- name: disk-alerts
rules:
- alert: highdiskutilization
expr: com_example_monitoring_diskmonitor_utilization{devicename=~"sd.*"} > 85
for: 5m
labels:
severity: warning
annotations:
summary: "high disk utilization on {{ $labels.devicename }}"
description: "disk {{ $labels.devicename }} has been over 85% utilization for 5 minutes."
- alert: diskiopslimitapproaching
expr: com_example_monitoring_diskmonitor_iops{devicename="nvme0n1"} > 50000
for: 2m
labels:
severity: critical
annotations:
summary: "nvme drive approaching iops limit"
description: "device nvme0n1 is sustaining >50k iops, may impact latency."
- alert: zerodiskactivitysuspicious
expr: com_example_monitoring_diskmonitor_readbytespersecond{devicename="sdb"} == 0
for: 10m
labels:
severity: warning
annotations:
summary: "disk sdb has zero activity for 10m"
description: "this may indicate failure or misconfiguration."
告警黄金法则:
- 相关性:确保告警与业务影响强相关
- 可操作性:收到告警后知道该做什么
- 分级制:区分 warning / critical
- 抑制机制:避免重复轰炸
性能调优实战案例
案例一:日志写入导致 %util 飙升
现象:某 java 服务每隔 5 分钟 %util 达到 95%,gc 暂停时间增加。
诊断:
# 使用 iotop 定位进程 sudo iotop -opa # 发现 java 进程在刷日志 total disk read: 0.00 b/s | total disk write: 45.23 m/s pid prio user disk read disk write command 1234 be/4 appuser 0.00 b/s 45.23 m/s java -jar app.jar
解决方案:
- 将日志框架从同步改为异步(logback asyncappender)
- 增加日志缓冲区大小
- 使用更快的存储介质(如 ssd 专用日志盘)
调整后 logback 配置:
<appender name="async" class="ch.qos.logback.classic.asyncappender">
<appender-ref ref="file"/>
<queuesize>8192</queuesize>
<discardingthreshold>0</discardingthreshold>
<includecallerdata>false</includecallerdata>
</appender>
案例二:数据库写入延迟高
现象:mysql insert 延迟从 2ms 升至 50ms。
排查步骤:
# 查看设备详细统计 iostat -xmt 1 # 输出显示 await 很高 device: rrqm/s wrqm/s r/s w/s rmb/s wmb/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdb 0.00 5.00 0.00 200.00 0.00 8.00 81.92 8.00 40.00 0.00 40.00 5.00 100.00
await=40ms 表示平均 i/o 等待时间,远高于正常值(<5ms)。
根因分析:
- 磁盘队列深度(avgqu-sz=8)过高
- 服务时间(svctm=5ms)尚可,说明是排队导致延迟
优化措施:
- 调整 i/o scheduler:
echo deadline > /sys/block/sdb/queue/scheduler - 增大 nr_requests:
echo 1024 > /sys/block/sdb/queue/nr_requests - 应用层批量提交事务,减少小 i/o
自动化脚本:生成每日磁盘报告
结合 java 与 shell,我们可以每天凌晨生成磁盘健康报告。
java 部分(生成 json 数据):
import com.fasterxml.jackson.databind.objectmapper;
import oshi.hardware.hwdiskstore;
import oshi.hardware.hardwareabstractionlayer;
import oshi.systeminfo;
import java.io.filewriter;
import java.time.localdate;
import java.util.arrays;
import java.util.list;
import java.util.stream.collectors;
public class dailydiskreportgenerator {
public static void main(string[] args) throws exception {
systeminfo si = new systeminfo();
hardwareabstractionlayer hal = si.gethardware();
hwdiskstore[] disks = hal.getdiskstores();
list<disksummary> summaries = arrays.stream(disks)
.map(disk -> new disksummary(
disk.getname(),
disk.getsize(),
disk.getreadbytes(),
disk.getwritebytes(),
disk.getreads(),
disk.getwrites()))
.collect(collectors.tolist());
objectmapper mapper = new objectmapper();
string json = mapper.writerwithdefaultprettyprinter().writevalueasstring(summaries);
string filename = string.format("/var/log/disk-report-%s.json", localdate.now());
try (filewriter fw = new filewriter(filename)) {
fw.write(json);
}
system.out.println("report written to: " + filename);
}
static class disksummary {
public string name;
public long size;
public long totalreadbytes;
public long totalwritebytes;
public long totalreads;
public long totalwrites;
public disksummary(string name, long size, long totalreadbytes, long totalwritebytes, long totalreads, long totalwrites) {
this.name = name;
this.size = size;
this.totalreadbytes = totalreadbytes;
this.totalwritebytes = totalwritebytes;
this.totalreads = totalreads;
this.totalwrites = totalwrites;
}
}
}
shell 脚本(/etc/cron.daily/disk-report):
#!/bin/bash # 设置 java 环境 export java_home=/usr/lib/jvm/java-11-openjdk-amd64 export path=$java_home/bin:$path cd /opt/disk-monitor java -cp "lib/*:target/*" dailydiskreportgenerator # 可选:发送邮件或上传到对象存储 # mail -s "daily disk report" admin@company.com < /var/log/disk-report-$(date +%y-%m-%d).json
赋予执行权限:
sudo chmod +x /etc/cron.daily/disk-report
单元测试你的监控逻辑
良好的监控代码也应具备可测试性。
import org.junit.jupiter.api.test;
import org.mockito.mockito;
import static org.junit.jupiter.api.assertions.asserttrue;
public class diskmonitortest {
@test
public void testcalculatereadrate() {
hwdiskstore mockprev = mockito.mock(hwdiskstore.class);
hwdiskstore mockcurr = mockito.mock(hwdiskstore.class);
mockito.when(mockprev.getreadbytes()).thenreturn(1024l);
mockito.when(mockcurr.getreadbytes()).thenreturn(5120l); // +4096 bytes
mockito.when(mockprev.gettimestamp()).thenreturn(1000l);
mockito.when(mockcurr.gettimestamp()).thenreturn(3000l); // 2 seconds later
double rate = (mockcurr.getreadbytes() - mockprev.getreadbytes()) * 1000.0 /
(mockcurr.gettimestamp() - mockprev.gettimestamp());
asserttrue(math.abs(rate - 2048.0) < 0.01); // 2048 bytes/sec
}
@test
public void testzerotimediffreturnszero() {
hwdiskstore mockprev = mockito.mock(hwdiskstore.class);
hwdiskstore mockcurr = mockito.mock(hwdiskstore.class);
mockito.when(mockprev.gettimestamp()).thenreturn(1000l);
mockito.when(mockcurr.gettimestamp()).thenreturn(1000l);
double rate = (mockcurr.getreadbytes() - mockprev.getreadbytes()) * 1000.0 /
(mockcurr.gettimestamp() - mockprev.gettimestamp());
asserttrue(double.isnan(rate) || rate == 0.0);
}
}
云端环境注意事项
在 aws ec2、阿里云 ecs 等云主机上,磁盘 i/o 行为略有不同:
- ebs 卷:有基准 iops 限制,突发型实例使用积分制
- 实例存储:高性能但临时性,重启即丢失
- 网络延迟:云盘本质是网络存储,延迟高于本地 ssd
监控建议:
- 同时监控
cloudwatch或云厂商原生监控 - 关注 burstbalance(突发积分余额)
- 对比
iostat与云监控数据,验证一致性
aws cli 示例:
aws cloudwatch get-metric-statistics \
--namespace aws/ebs \
--metric-name volumereadbytes \
--dimensions name=volumeid,value=vol-1234567890abcdef0 \
--start-time $(date -u -d '1 hour ago' '+%y-%m-%dt%h:%m:%sz') \
--end-time $(date -u '+%y-%m-%dt%h:%m:%sz') \
--period 300 \
--statistics sum
未来演进方向
随着 ebpf、io_uring 等新技术普及,磁盘监控也在进化:
- ebpf:无需修改内核即可追踪 i/o 路径,开销极低
- io_uring:异步 i/o 新接口,需适配监控工具
- opentelemetry:统一观测性标准,未来可能替代部分 jmx/prometheus
总结
磁盘 i/o 监控不是一次性任务,而是持续优化的过程。我们从基础命令出发,逐步构建了:
- 实时监控(iostat/iotop)
- 程序集成(java + oshi)
- 标准化暴露(jmx → prometheus)
- 可视化与告警(grafana + alertmanager)
- 自动化报告
- 性能调优闭环
记住几个关键原则:
🔹 监控一切,但只告警重要的事
🔹 指标要可聚合、可对比、可预测
🔹 与业务指标联动(如“磁盘延迟上升 → 订单处理变慢”)
🔹 定期回顾告警有效性,删除噪音规则
以上就是linux监控系统磁盘io的方法汇总的详细内容,更多关于linux监控系统磁盘io的资料请关注代码网其它相关文章!




发表评论