1、前言
在进行集群搭建时,需要保证单机版本的redis搭建没有问题,可以参考《linux服务器redis 6.x安装、配置》
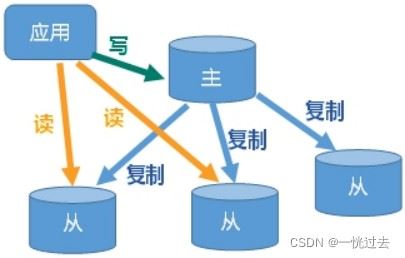
2、主从复制好处
- 读写分离,性能扩展
- 容灾快速恢复
主库负责写操作,从库负责读操作。
3、服务器准备
搭建redis一主一从,分为3组,实际中可以将3组实例搭建到不同服务器上,本次为了演示操作,所有redis实例都在一台服务器,通过端口进行区分
注意:
如果使用云服务器需要安全组端口和防火墙开放的redis客户端与reids总线的端口(+10000),比如:reids的端口为7001-7006,那么reids总线的端口为17001-17006,所以需要开放的端口为:7001-7006、17001-17006
4、环境搭建
4.1、创建集群工作目录
mkdir /usr/local/redis/cluster -p
4.2、搭建单机环境
在cluster目录下创建redis7001目录并且成功搭建一个单机版的redis,端口设置为7001
4.3、集群配置
关闭7001单机实例,修改配置文件
vim /usr/local/redis/cluster/redis7001/config/redis.conf
内容如下:
daemonize yes 注释 bind 127.0.0.1 protected-mode no daemonize yes cluster-enabled yes logfile "/usr/local/redis/cluster/redis7001/log/redis.log" port 7001 # 直接指定就行,不用手动创建conf文件 cluster-config-file nodes-7001.conf #集群向外网暴漏的ip(网外ip)及端口 cluster-announce-ip 111.xxx.xxx.175 cluster-announce-port 7001
4.4、复制实例
将redis7001实例目录复制分别为:redis7002~redis7006
cp redis7001/ redis7002 -r ... ... cp redis7001/ redis7006 -r

4.5、修改其他实例配置文件
其他实例是从redis7001拷贝而来,所以只需要修改配置文件的不同点即可,如下:
# 将logfile中的redis700x修改为对应的文件夹,比如redis7002 logfile "/usr/local/redis/cluster/redis700x/log/redis.log" # 将700x修改为对应实例的端口,比如7002 port 700x # 将700x修改为对应实例的端口,比如7002 cluster-config-file nodes-700x.conf # 将700x修改为对应实例的端口,比如7002 cluster-announce-port 700x
4.6、创建批量启动/关闭脚本
由于所有的redis实例都在一台服务器中,为了方便进行统一的管理,创建批量启动与关闭的脚本,脚本所在目录为:/usr/local/redis/cluster
1、集群启动脚本:
vim start-all.sh
内容:
cd redis7001/bin ./redis-server ../config/redis.conf cd ../.. cd redis7002/bin ./redis-server ../config/redis.conf cd ../.. cd redis7003/bin ./redis-server ../config/redis.conf cd ../.. cd redis7004/bin ./redis-server ../config/redis.conf cd ../.. cd redis7005/bin ./redis-server ../config/redis.conf cd ../.. cd redis7006/bin ./redis-server ../config/redis.conf cd ../..
授权:
chmod u+x start-all.sh
2、集群关闭脚本:
vim shutdow-all.sh
内容:
redis7001/bin/redis-cli -p 7001 shutdown redis7001/bin/redis-cli -p 7002 shutdown redis7001/bin/redis-cli -p 7003 shutdown redis7001/bin/redis-cli -p 7004 shutdown redis7001/bin/redis-cli -p 7005 shutdown redis7001/bin/redis-cli -p 7006 shutdown
授权:
chmod u+x shutdow-all.sh
4.7、创建集群
1、启动所有节点
sh start-all.sh

2、创建集群连接
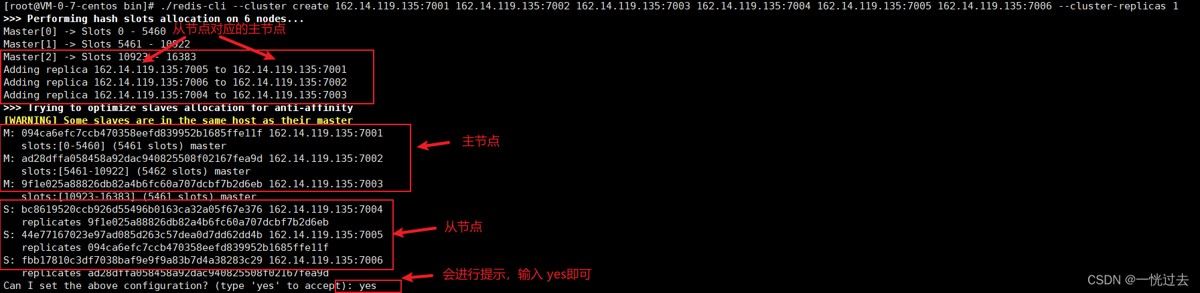
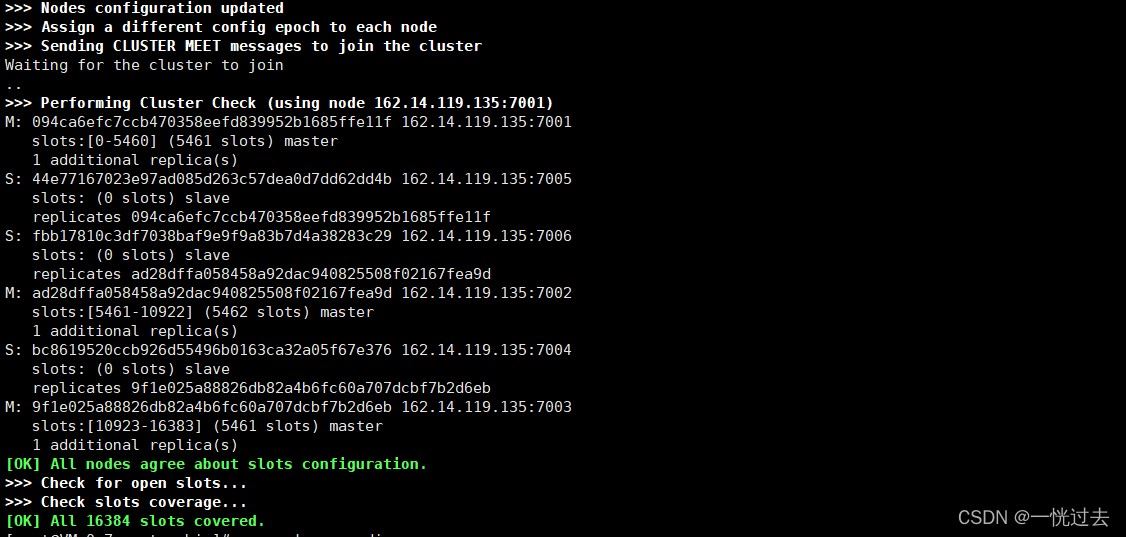
# 进入集群目录 cd /usr/local/redis/cluster/redis7001/bin # 在搭建集群时,要求至少有三个主节点(因为投票机制),6个实例自动分配主从关系 # --cluster-replicas 1,表示主库有多少个从库,为1就表示有一个从库 ./redis-cli --cluster create 162.14.119.135:7001 162.14.119.135:7002 162.14.119.135:7003 162.14.119.135:7004 162.14.119.135:7005 162.14.119.135:7006 --cluster-replicas 1
3、集群连接测试
连接进入任意节点
cd redis7001/bin ./redis-cli -h 162.14.119.135 -c -p 7001
可以看到在7001节点,set一个值,会自动跳转到7002节点,并且可以取出值,表示当前值存入在7002的节点中;

我们再次使用./redis-cli -h 162.14.119.135 -c -p 7001进入7001节点,并且获取name值,可以看到redis会自动从7002节点取值;

5、整合springboot
springboot整合reids单机版本可以参考《springboot整合redis》,其实整合集群版与单机版的区别在于yaml文件的配置,配置如下:
spring:
redis:
cluster:
nodes:
- 162.14.119.135:7001
- 162.14.119.135:7002
- 162.14.119.135:7003
- 162.14.119.135:7004
- 162.14.119.135:7005
- 162.14.119.135:7006
#连接超时时间
timeout: 3600ms
#密码
password:
lettuce:
pool:
# 连接池最大连接数(使用负值表示没有限制)
max-active: 8
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
# 连接池中的最大空闲连接
max-idle: 8
# 连接池中的最小空闲连接
min-idle: 1
#关闭超时
shutdown-timeout: 500ms
6、删除、新增节点
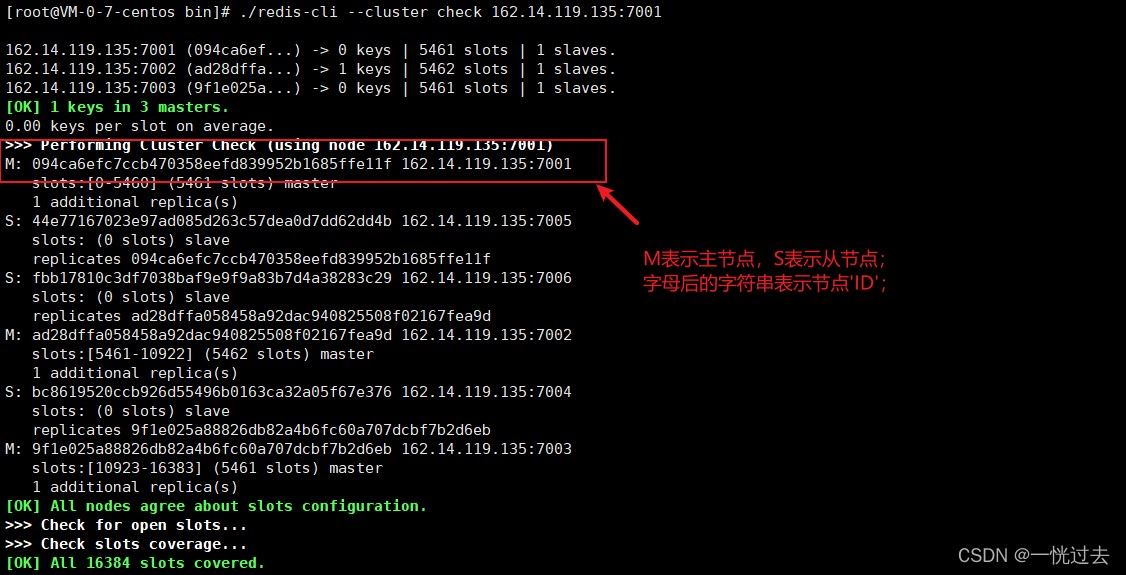
删除节点前,需要redis-cli --cluster check ip:port查询集群情况,获取相应的节点的id和主从关系。
6.1、删除从节点
删除命令:redis-cli --cluster del-node ip:port id
# 比如删除7006从节点 ./redis-cli --cluster del-node 162.14.119.135:7006 fbb17810c3df7038baf9e9f9a83b7d4a38283c29

6.2、新增从节点
当被删除掉的节点重新启动之后不能自动加入集群,本身已经是个独立的master节点了;
新增的从节点可以是之前的删除的节点,也可以是新增的redis实例;
如果想要加入集群,则需要先在该节点执行cluster reset,再用add-node进行添加,进行增量同步复制;
为了方便演示,我们直接将之前删除的'7006'节点重新加入到集群中,如果不想加入之前删除的节点,可以新增一个实例然后加入到集群中;
重置节点:
# 保证已经删除的节点是启动状态,比如7006节点 # 进入7006客户端 ./redis-cli -h 162.14.119.135 -c -p 7006 # 执行重置命令 cluster reset

加入集群:
# 加入集群命令,指定7006加入到7002节点下: ./redis-cli --cluster add-node 162.14.119.135:7006 162.14.119.135:7002 --cluster-slave --cluster-master-id d882c3ab7f37613663d7f063c4d7eae5cefd7fb7 #add-node: 后面的分别跟着新加入的slave和slave对应的master #cluster-slave:表示加入的是slave节点 #--cluster-master-id:表示slave对应的master的node id #如果不通过 --cluster-master-id指定主节点id 会随机分配到任意一个主节点
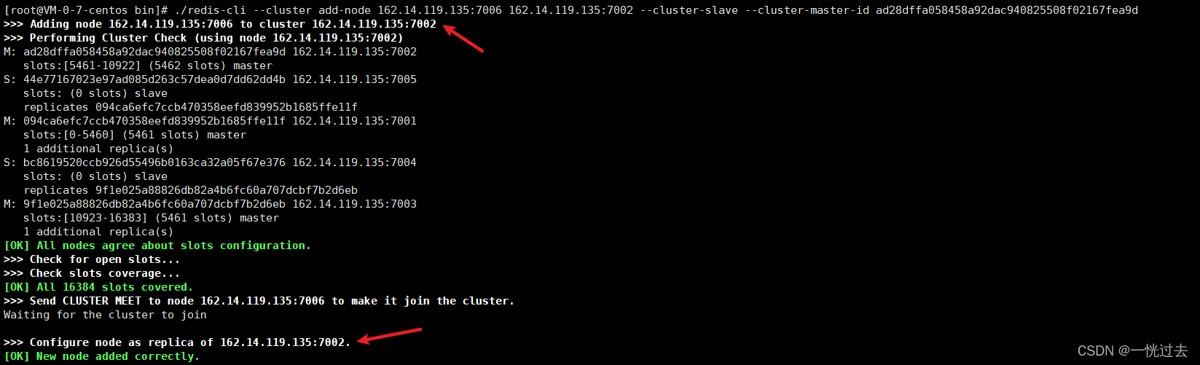
查看集群情况:
# 再次查看集群情况: ./redis-cli --cluster check 162.14.119.135:7001
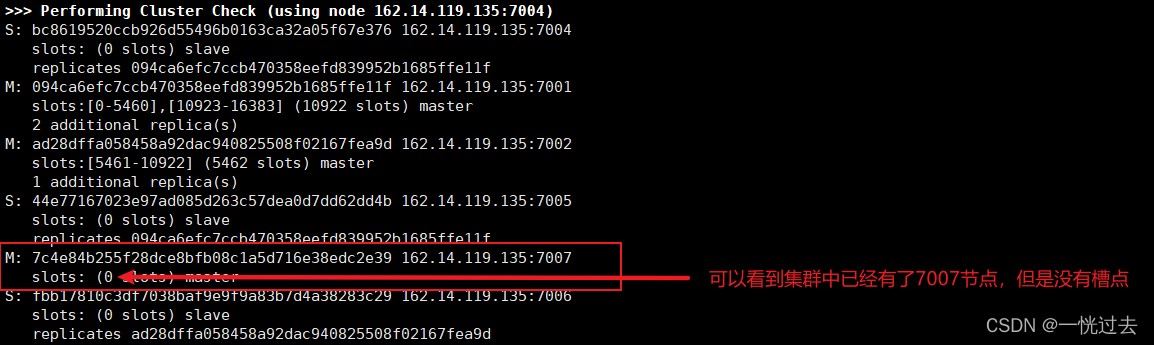
6.3、删除主节点
删除主节点时需要做更多操作,需要将槽点进行转移,然后才能进行删除,具体参考以下截图
比如,删除7003主节点,该主节点的id为9f1e025a88826db82a4b6fc60a707dcbf7b2d6eb

# 槽点转移 ./redis-cli --cluster reshard 162.14.119.135:7003
以下截图,为其他系统搭建时的截图,但是操作原理、步骤和删除7003节点时一致
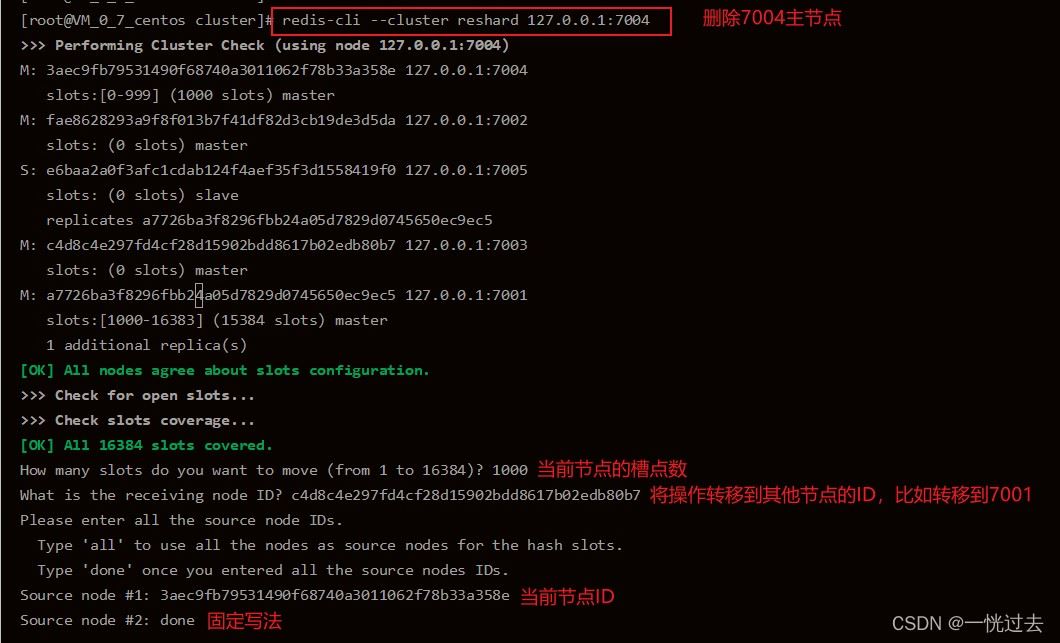
# 删除7003节点,当主节点槽点转移完成后尽可以删除节点了,执行命令: ./redis-cli --cluster del-node 162.14.119.135:7003 9f1e025a88826db82a4b6fc60a707dcbf7b2d6eb

再次执行check查看集群情况时,已经没有了7003节点
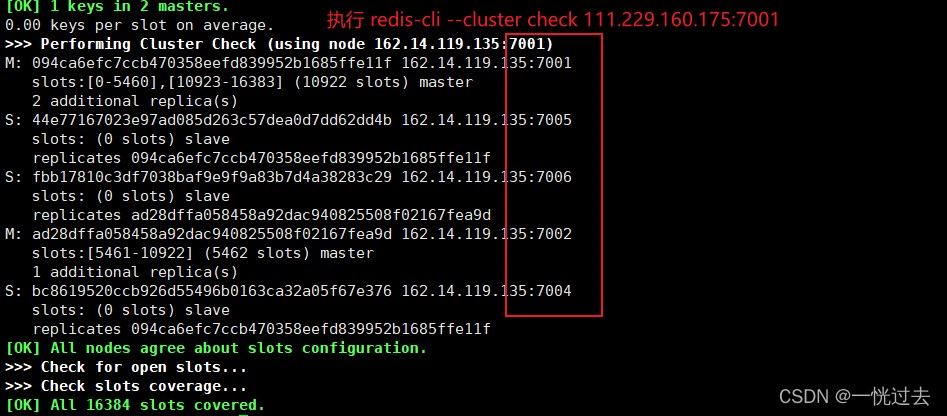
6.4、新增主节点
在之前的新增从节点中演示,新增之前删除过的节点,本次新增主节点采用新增实例的方式进行。
前置条件:
将redis7001拷贝一份为redis7007,并且修改redis7007的配置文件,然后启动实例;
加入集群:
# 将7007加入到集群,后面的111.229.160.175:7001为集群中的任意主节点ip:port ./redis-cli --cluster add-node 162.14.119.135:7007 162.14.119.135:7001
查看集群情况:
./redis-cli --cluster check 162.14.119.135:7001
分配槽点:
# 分配槽点时,过程较复杂,具体流程如下截图: ./redis-cli --cluster reshard 162.14.119.135:7007
以下截图,为其他系统搭建时的截图,但是操作原理、步骤和新增7007节点时一致
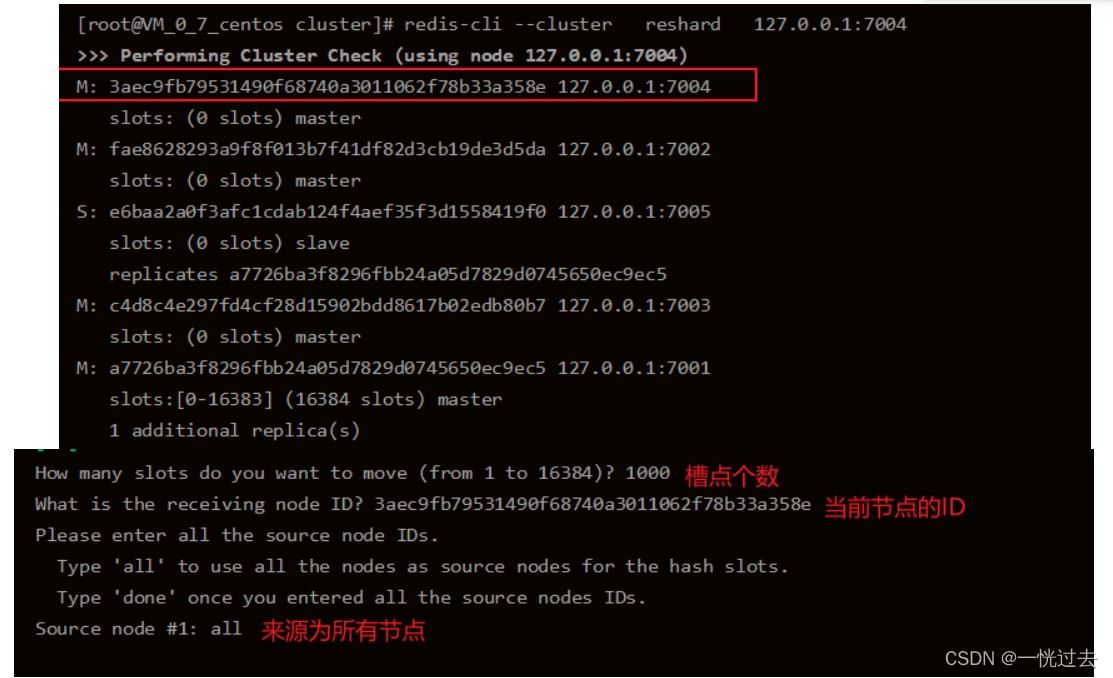
分配从节点:
在为主节点分配槽点时,如果集群中有多余的从节点,会自动成为新增主节点的从节点;
没有的话,可以采用新增从节点的方式进行指定,具体流程可以参考6.2、新增从节点;
7、投票机制
每个哈希槽都有一个主节点和多个从节点
- **比如:**如果有六个节点,则分a,b,c三个为主节点,a1,b1,c1三个为对应的从节点,当a发生故障后,集群会提升a1为主节点,a1会继承a节点的数据,其实a1就相当于a的一个副本,让集群继续工作。
- 投票过程是集群中所有主节点参与,如果半数以上主节点与故障主节点通信超时,则认为当前该主节点挂掉,所以集群中至少需要3个主节点,每个主节点至少需要一个从节点,所有至少就是需要6个redis实例。
什么时候整个集群不可用:
a:如果集群任意主节点挂掉,且没有从节点.集群进入fail状态
b:如果集群超过半数以上主节点挂掉,无论是否有从节点,集群都进入fail状态.
ps: 当集群不可用时,所有对集群的操作做都不可用,收到((error) clusterdown the cluster is down)错误。
8、主节点宕机演示
- 当某个主节点挂了以后,对应的从节点会自动升级为主节点,然后再次启动这个节点后,节点会自动加入到集群中,并且成为某个主节点(从原有从节点升级为主节点的节点)的从节点。
- 如果从节点挂了以后,然后再次启动这个节点后,可以将当前节点加入到集群中,并且继续成为原有主节点的从节点。
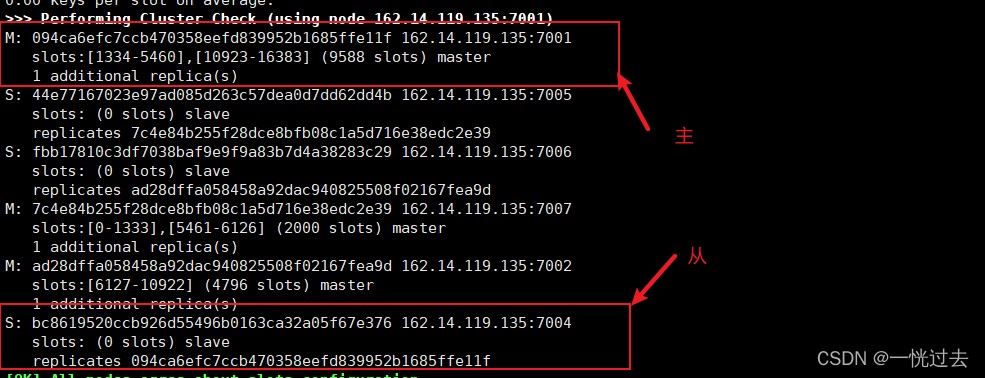
宕机前
我们可以看到:主节点7001,从节点7004;
宕机后
当7001宕机后[模拟手动关闭],过一段时间(默认15s),7004从节点会自动变为主节点并且会继承主节点的数据,后续当7001节点上线以后,会自动变成7004节点的从节点。
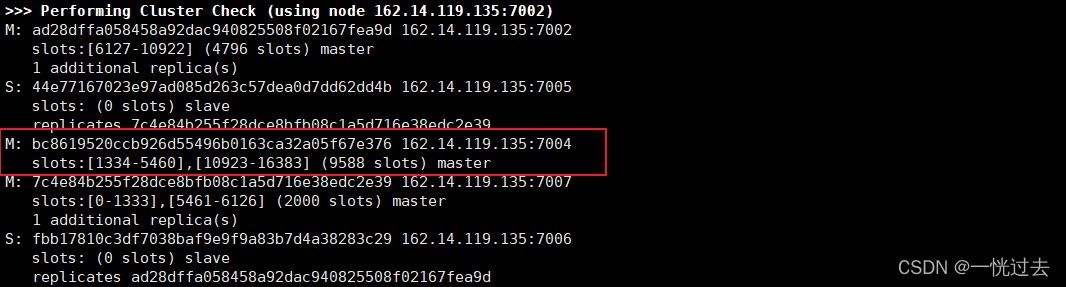
注意: 可以通过cluster-node-timeout设置时间;
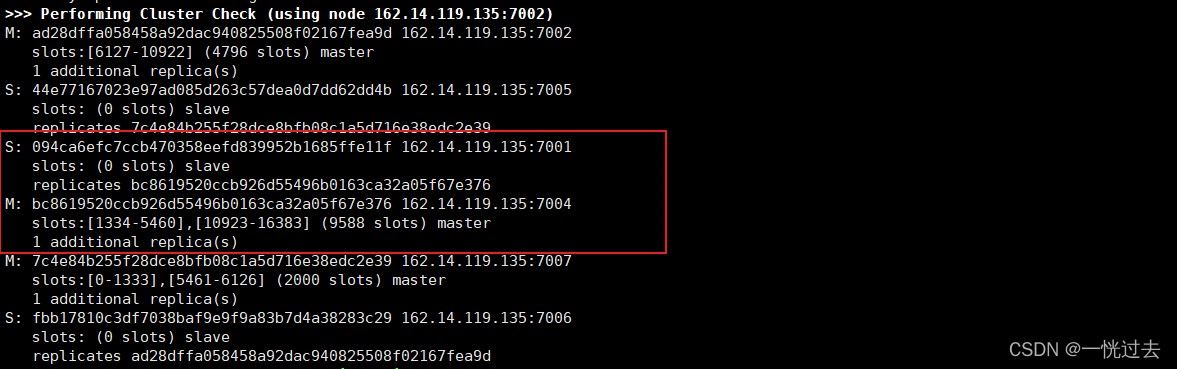
宕机后恢复
模拟重新启动7001节点,7001会自动成为7004节点的从节点;
9、重置集群
1、关闭集群中所有的实例
2、删除bin目录下的aof、rdb、nodes.conf文件
3、重新建立集群:
# 新建集群 ./redis-cli --cluster create 162.14.119.135:7001 162.14.119.135:7002 162.14.119.135:7003 162.14.119.135:7004 162.14.119.135:7005 162.14.119.135:7006 --cluster-replicas 1 # 查看集群情况 ./redis-cli --cluster check 162.14.119.135:7001
10、集群原理
redis集群就是将数据自动分片到不同的redis主节点实例上,然后主节点同步到从节点中,实现数据的高可用。
一个 redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个;
集群通过hash算法来计算键 key 属于哪个槽,将value存放到指定插槽或者从指定插槽中获取value;
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有3个主节点, 其中:
- 节点 a 负责处理 0 号至 5460 号插槽。
- 节点 b 负责处理 5461 号至 10922 号插槽。
- 节点 c 负责处理 10923 号至 16383 号插槽。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论