在linux系统中,file命令是一个看似简单却功能强大的工具。它能够帮助我们快速识别文件的真实类型,而不仅仅依赖于文件扩展名。对于开发者、系统管理员和安全工程师来说,掌握file命令的原理和应用至关重要。本文将从基础用法讲起,深入到其工作原理,并结合java代码示例展示如何在程序中实现类似功能。
什么是 file 命令?
file命令是linux/unix系统中的一个标准工具,用于确定文件类型。它通过检查文件内容而非仅仅依赖文件扩展名来判断文件类型,这使得它在处理无扩展名文件、伪装文件或损坏文件时特别有用。
file myfile.txt file /bin/ls file image.jpg
执行这些命令后,你会看到类似这样的输出:
myfile.txt: ascii text /bin/ls: elf 64-bit lsb executable, x86-64, version 1 (sysv), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for gnu/linux 3.2.0, buildid[sha1]=..., stripped image.jpg: jpeg image data, jfif standard 1.01, aspect ratio, density 1x1, segment length 16, baseline, precision 8, 1920x1080, components 3
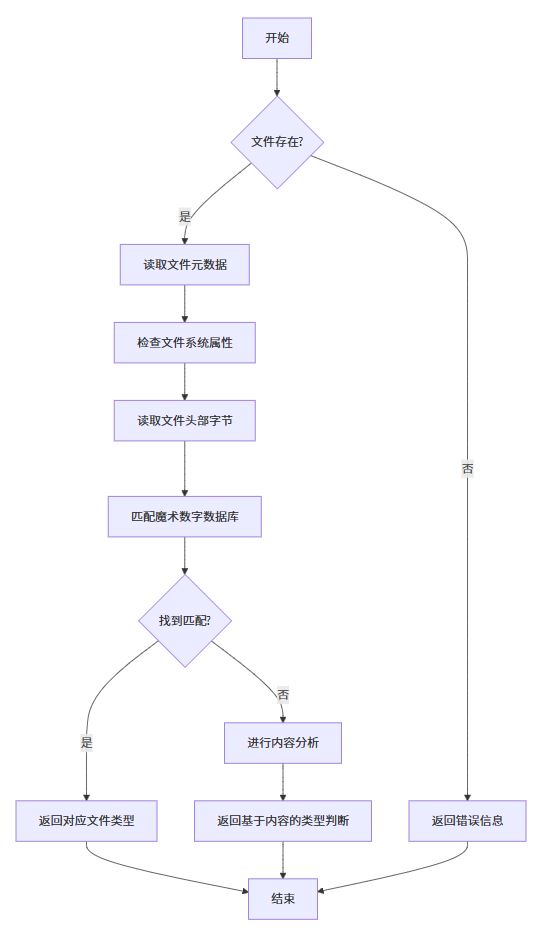
file 命令的工作原理
file命令主要通过三种方式来识别文件类型:
- 文件系统测试:检查文件的元数据(如是否为目录、符号链接等)
- 魔术数字测试:检查文件开头的特定字节序列(magic numbers)
- 语言测试:分析文件内容以确定是否为特定编程语言或文本格式
魔术数字揭秘
许多文件格式在文件开头都有特定的"签名"或"魔术数字"。例如:
- jpeg文件通常以
ff d8 ff开头 - png文件以
89 50 4e 47 0d 0a 1a 0a开头 - pdf文件以
%pdf-开头 - zip文件以
50 4b 03 04开头
file 命令的基本用法
基础语法
file [选项] 文件名...
最简单的用法就是直接跟文件名:
file document.pdf
常用选项
-b(brief) 简洁模式
只显示文件类型,不显示文件名:
file -b document.pdf # 输出: pdf document, version 1.7
-i(mime) mime类型模式
显示mime类型:
file -i document.pdf # 输出: document.pdf: application/pdf; charset=binary
-l跟随符号链接
默认情况下,file命令会报告符号链接本身的信息。使用-l选项可以跟随链接到目标文件:
file -l symlink_to_file
-z解压压缩文件
如果文件是压缩的,尝试解压并识别内部文件类型:
file -z compressed.gz
-f从文件读取文件名列表
可以从一个包含文件名列表的文件中批量识别:
file -f filelist.txt
其中filelist.txt包含要检查的文件路径,每行一个。
实际应用场景
安全扫描
在安全领域,file命令常用于识别潜在的恶意文件:
# 检查上传目录中的所有文件
find /var/www/uploads -type f -exec file {} \;
系统管理
系统管理员可以用它来清理未知文件:
# 找出所有非文本文件
find /tmp -type f -exec file {} \; | grep -v "text"
开发调试
开发者可以用它来验证编译结果:
# 确认编译后的文件确实是可执行文件 file myprogram # 应该输出类似: elf 64-bit lsb executable...
file 命令的高级技巧
自定义魔术文件
file命令的行为可以通过自定义魔术文件来扩展。魔术文件定义了如何识别特定文件类型。
创建自定义魔术文件 /etc/magic 或 ~/.magic:
# 自定义魔术文件示例 0 string myapp1.0 my custom application file >4 byte x \b, version %d >5 leshort x \b.%d
然后使用 -m 选项指定自定义魔术文件:
file -m ~/.magic myfile.dat
批量处理
结合其他命令进行批量处理:
# 统计目录中各种文件类型的数量 file * | cut -d: -f2 | sort | uniq -c | sort -nr
输出格式化
# 只获取文件类型部分,用于脚本处理 file -b --mime-type myfile.pdf # 输出: application/pdf
java实现文件类型识别
现在让我们用java实现一个简化版的file命令功能。这个实现将展示如何在程序中识别文件类型。
基础版本
import java.io.*;
import java.nio.file.files;
import java.nio.file.path;
import java.nio.file.paths;
import java.util.hashmap;
import java.util.map;
public class simplefileidentifier {
// 魔术数字映射表
private static final map<string, string> magic_numbers = new hashmap<>();
static {
// 初始化魔术数字
magic_numbers.put("89504e470d0a1a0a", "png image");
magic_numbers.put("ffd8ffe0", "jpeg image");
magic_numbers.put("ffd8ffe1", "jpeg image");
magic_numbers.put("ffd8ffdb", "jpeg image");
magic_numbers.put("255044462d", "pdf document"); // %pdf-
magic_numbers.put("504b0304", "zip archive"); // pk..
magic_numbers.put("526172211a0700", "rar archive"); // rar!..
magic_numbers.put("526172211a070100", "rar archive"); // rar!....
magic_numbers.put("1f8b08", "gzip compressed");
magic_numbers.put("424d", "bmp image"); // bm
magic_numbers.put("474946383761", "gif image"); // gif87a
magic_numbers.put("474946383961", "gif image"); // gif89a
}
public static string identifyfiletype(string filepath) throws ioexception {
path path = paths.get(filepath);
// 检查文件是否存在
if (!files.exists(path)) {
return "file does not exist";
}
// 检查是否为目录
if (files.isdirectory(path)) {
return "directory";
}
// 读取文件头部字节
byte[] header = readheaderbytes(path, 8);
// 尝试匹配魔术数字
string filetype = matchmagicnumber(header);
if (filetype != null) {
return filetype;
}
// 如果没有匹配到魔术数字,尝试文本检测
if (istextfile(path)) {
return "ascii text";
}
return "data"; // 未知二进制数据
}
private static byte[] readheaderbytes(path path, int length) throws ioexception {
try (inputstream is = files.newinputstream(path)) {
byte[] buffer = new byte[length];
int bytesread = is.read(buffer);
if (bytesread < length) {
byte[] result = new byte[bytesread];
system.arraycopy(buffer, 0, result, 0, bytesread);
return result;
}
return buffer;
}
}
private static string matchmagicnumber(byte[] header) {
// 将字节数组转换为十六进制字符串
string hexheader = bytestohex(header);
// 尝试匹配不同长度的魔术数字
for (int len = hexheader.length(); len >= 2; len -= 2) {
string prefix = hexheader.substring(0, len);
if (magic_numbers.containskey(prefix)) {
return magic_numbers.get(prefix);
}
}
return null;
}
private static string bytestohex(byte[] bytes) {
stringbuilder sb = new stringbuilder();
for (byte b : bytes) {
sb.append(string.format("%02x", b));
}
return sb.tostring();
}
private static boolean istextfile(path path) {
try {
byte[] content = files.readallbytes(path);
if (content.length == 0) {
return true; // 空文件视为文本文件
}
// 检查是否包含大量非打印字符
int nonprintablecount = 0;
for (byte b : content) {
if (b < 32 && b != 9 && b != 10 && b != 13) { // 不包括制表符、换行符、回车符
nonprintablecount++;
}
}
// 如果非打印字符比例超过30%,则认为是二进制文件
return ((double) nonprintablecount / content.length) < 0.3;
} catch (ioexception e) {
return false;
}
}
public static void main(string[] args) {
if (args.length == 0) {
system.out.println("usage: java simplefileidentifier <file_path>");
return;
}
try {
string result = identifyfiletype(args[0]);
system.out.println(args[0] + ": " + result);
} catch (ioexception e) {
system.err.println("error: " + e.getmessage());
}
}
}
进阶版本:支持mime类型
import java.io.*;
import java.nio.file.files;
import java.nio.file.path;
import java.nio.file.paths;
import java.util.hashmap;
import java.util.map;
public class advancedfileidentifier {
// 魔术数字到文件类型的映射
private static final map<string, filetype> magic_signatures = new hashmap<>();
static {
// 图像文件
magic_signatures.put("89504e470d0a1a0a",
new filetype("png image", "image/png"));
magic_signatures.put("ffd8ffe0",
new filetype("jpeg image", "image/jpeg"));
magic_signatures.put("ffd8ffe1",
new filetype("jpeg image", "image/jpeg"));
magic_signatures.put("ffd8ffdb",
new filetype("jpeg image", "image/jpeg"));
magic_signatures.put("474946383761",
new filetype("gif image", "image/gif"));
magic_signatures.put("474946383961",
new filetype("gif image", "image/gif"));
magic_signatures.put("424d",
new filetype("bmp image", "image/bmp"));
// 文档文件
magic_signatures.put("255044462d",
new filetype("pdf document", "application/pdf"));
magic_signatures.put("504b0304",
new filetype("zip archive", "application/zip"));
magic_signatures.put("526172211a0700",
new filetype("rar archive", "application/x-rar-compressed"));
magic_signatures.put("526172211a070100",
new filetype("rar archive", "application/x-rar-compressed"));
// 压缩文件
magic_signatures.put("1f8b08",
new filetype("gzip compressed", "application/gzip"));
magic_signatures.put("425a68",
new filetype("bzip2 compressed", "application/x-bzip2"));
// 可执行文件
magic_signatures.put("7f454c46",
new filetype("elf executable", "application/x-executable"));
// office文档
magic_signatures.put("d0cf11e0a1b11ae1",
new filetype("microsoft office document", "application/msword"));
}
// 文件类型内部类
static class filetype {
private final string description;
private final string mimetype;
public filetype(string description, string mimetype) {
this.description = description;
this.mimetype = mimetype;
}
public string getdescription() { return description; }
public string getmimetype() { return mimetype; }
@override
public string tostring() {
return description;
}
}
public static filetype identifyfiletype(string filepath) throws ioexception {
path path = paths.get(filepath);
// 检查文件是否存在
if (!files.exists(path)) {
throw new filenotfoundexception("file does not exist: " + filepath);
}
// 检查是否为目录
if (files.isdirectory(path)) {
return new filetype("directory", "inode/directory");
}
// 获取文件大小
long filesize = files.size(path);
if (filesize == 0) {
return new filetype("empty", "inode/x-empty");
}
// 读取文件头部字节(最多16字节)
byte[] header = readheaderbytes(path, 16);
// 尝试匹配魔术数字
filetype filetype = matchmagicsignature(header);
if (filetype != null) {
return filetype;
}
// 如果没有匹配到魔术数字,尝试文本检测
if (isplaintextfile(path)) {
string encoding = detectencoding(path);
return new filetype("ascii text", "text/plain; charset=" + encoding);
}
// 检查是否为utf-8编码的文本文件
if (isutf8textfile(path)) {
return new filetype("utf-8 unicode text", "text/plain; charset=utf-8");
}
return new filetype("data", "application/octet-stream"); // 未知二进制数据
}
private static byte[] readheaderbytes(path path, int maxlength) throws ioexception {
try (inputstream is = files.newinputstream(path)) {
byte[] buffer = new byte[maxlength];
int totalread = 0;
int bytesread;
while (totalread < maxlength && (bytesread = is.read(buffer, totalread, maxlength - totalread)) != -1) {
totalread += bytesread;
}
if (totalread < maxlength) {
byte[] result = new byte[totalread];
system.arraycopy(buffer, 0, result, 0, totalread);
return result;
}
return buffer;
}
}
private static filetype matchmagicsignature(byte[] header) {
string hexheader = bytestohex(header);
// 尝试匹配不同长度的签名
for (int len = math.min(hexheader.length(), 32); len >= 2; len -= 2) {
string prefix = hexheader.substring(0, len);
if (magic_signatures.containskey(prefix)) {
return magic_signatures.get(prefix);
}
}
return null;
}
private static string bytestohex(byte[] bytes) {
stringbuilder sb = new stringbuilder();
for (byte b : bytes) {
sb.append(string.format("%02x", b));
}
return sb.tostring();
}
private static boolean isplaintextfile(path path) {
try {
// 对于大文件,只检查前几kb
long maxsizetocheck = math.min(files.size(path), 8192);
byte[] content = files.readallbytes(path);
if (maxsizetocheck < content.length) {
byte[] truncated = new byte[(int) maxsizetocheck];
system.arraycopy(content, 0, truncated, 0, (int) maxsizetocheck);
content = truncated;
}
if (content.length == 0) {
return true;
}
// 检查是否包含大量非ascii字符
int nonasciicount = 0;
for (byte b : content) {
if (b < 0 || (b > 127 && b != -1)) { // 负数表示非ascii
nonasciicount++;
}
}
// 如果非ascii字符比例超过20%,可能不是纯文本
return ((double) nonasciicount / content.length) < 0.2;
} catch (ioexception e) {
return false;
}
}
private static boolean isutf8textfile(path path) {
try {
// 尝试作为utf-8读取
byte[] content = files.readallbytes(path);
if (content.length == 0) {
return true;
}
// 简单的utf-8验证
int i = 0;
while (i < content.length) {
byte b = content[i];
if ((b & 0x80) == 0) {
// 1-byte sequence
i++;
} else if ((b & 0xe0) == 0xc0) {
// 2-byte sequence
if (i + 1 >= content.length) return false;
if ((content[i+1] & 0xc0) != 0x80) return false;
i += 2;
} else if ((b & 0xf0) == 0xe0) {
// 3-byte sequence
if (i + 2 >= content.length) return false;
if ((content[i+1] & 0xc0) != 0x80) return false;
if ((content[i+2] & 0xc0) != 0x80) return false;
i += 3;
} else if ((b & 0xf8) == 0xf0) {
// 4-byte sequence
if (i + 3 >= content.length) return false;
if ((content[i+1] & 0xc0) != 0x80) return false;
if ((content[i+2] & 0xc0) != 0x80) return false;
if ((content[i+3] & 0xc0) != 0x80) return false;
i += 4;
} else {
return false; // invalid utf-8
}
}
// 如果能成功解析为utf-8,再检查是否主要是文本
string text = new string(content, "utf-8");
int controlcharcount = 0;
for (char c : text.tochararray()) {
if (c < 32 && c != '\t' && c != '\n' && c != '\r') {
controlcharcount++;
}
}
return ((double) controlcharcount / text.length()) < 0.3;
} catch (exception e) {
return false;
}
}
private static string detectencoding(path path) {
// 简单的编码检测
try {
byte[] content = files.readallbytes(path);
if (content.length == 0) {
return "us-ascii";
}
// 检查utf-8 bom
if (content.length >= 3 &&
content[0] == (byte)0xef &&
content[1] == (byte)0xbb &&
content[2] == (byte)0xbf) {
return "utf-8";
}
// 检查utf-16 le bom
if (content.length >= 2 &&
content[0] == (byte)0xff &&
content[1] == (byte)0xfe) {
return "utf-16le";
}
// 检查utf-16 be bom
if (content.length >= 2 &&
content[0] == (byte)0xfe &&
content[1] == (byte)0xff) {
return "utf-16be";
}
// 默认假设为ascii
return "us-ascii";
} catch (ioexception e) {
return "unknown";
}
}
public static void printfileinfo(string filepath, boolean showmime) {
try {
filetype filetype = identifyfiletype(filepath);
if (showmime) {
system.out.println(filepath + ": " + filetype.getmimetype());
} else {
system.out.println(filepath + ": " + filetype.getdescription());
}
} catch (ioexception e) {
system.err.println(filepath + ": error - " + e.getmessage());
}
}
public static void main(string[] args) {
if (args.length == 0) {
system.out.println("usage: java advancedfileidentifier [-i] <file_path> [file_path...]");
system.out.println(" -i: show mime type instead of description");
return;
}
boolean showmime = false;
int startindex = 0;
if (args[0].equals("-i")) {
showmime = true;
startindex = 1;
}
if (startindex >= args.length) {
system.out.println("no files specified");
return;
}
for (int i = startindex; i < args.length; i++) {
printfileinfo(args[i], showmime);
}
}
}
完整的应用程序:带批量处理功能
import java.io.*;
import java.nio.file.*;
import java.nio.file.attribute.basicfileattributes;
import java.text.simpledateformat;
import java.util.*;
import java.util.stream.collectors;
public class professionalfileidentifier {
// 支持的文件类型签名
private static final map<string, filetypesignature> file_signatures = new hashmap<>();
private static final simpledateformat date_format = new simpledateformat("yyyy-mm-dd hh:mm:ss");
static {
initializesignatures();
}
static class filetypesignature {
private final string description;
private final string mimetype;
private final string extension;
private final int confidencelevel; // 1-100
public filetypesignature(string description, string mimetype, string extension, int confidencelevel) {
this.description = description;
this.mimetype = mimetype;
this.extension = extension;
this.confidencelevel = confidencelevel;
}
// getters
public string getdescription() { return description; }
public string getmimetype() { return mimetype; }
public string getextension() { return extension; }
public int getconfidencelevel() { return confidencelevel; }
@override
public string tostring() {
return string.format("%s (%s) - %d%% confidence", description, mimetype, confidencelevel);
}
}
private static void initializesignatures() {
// 图像格式
file_signatures.put("89504e470d0a1a0a",
new filetypesignature("png image", "image/png", "png", 100));
file_signatures.put("ffd8ffe0",
new filetypesignature("jpeg image", "image/jpeg", "jpg", 95));
file_signatures.put("ffd8ffe1",
new filetypesignature("jpeg image", "image/jpeg", "jpg", 95));
file_signatures.put("ffd8ffdb",
new filetypesignature("jpeg image", "image/jpeg", "jpg", 95));
file_signatures.put("474946383761",
new filetypesignature("gif image", "image/gif", "gif", 100));
file_signatures.put("474946383961",
new filetypesignature("gif image", "image/gif", "gif", 100));
file_signatures.put("424d",
new filetypesignature("bmp image", "image/bmp", "bmp", 90));
file_signatures.put("49492a00",
new filetypesignature("tiff image", "image/tiff", "tif", 95));
file_signatures.put("4d4d002a",
new filetypesignature("tiff image", "image/tiff", "tif", 95));
// 文档格式
file_signatures.put("255044462d",
new filetypesignature("pdf document", "application/pdf", "pdf", 100));
file_signatures.put("d0cf11e0a1b11ae1",
new filetypesignature("microsoft office document", "application/msword", "doc", 85));
file_signatures.put("504b030414000600",
new filetypesignature("microsoft office open xml", "application/vnd.openxmlformats-officedocument", "docx", 90));
// 压缩格式
file_signatures.put("504b0304",
new filetypesignature("zip archive", "application/zip", "zip", 95));
file_signatures.put("526172211a0700",
new filetypesignature("rar archive", "application/x-rar-compressed", "rar", 95));
file_signatures.put("526172211a070100",
new filetypesignature("rar archive", "application/x-rar-compressed", "rar", 95));
file_signatures.put("1f8b08",
new filetypesignature("gzip compressed", "application/gzip", "gz", 95));
file_signatures.put("425a68",
new filetypesignature("bzip2 compressed", "application/x-bzip2", "bz2", 95));
file_signatures.put("504b0506",
new filetypesignature("zip archive (empty)", "application/zip", "zip", 90));
// 可执行文件
file_signatures.put("7f454c46",
new filetypesignature("elf executable", "application/x-executable", "bin", 95));
file_signatures.put("4d5a",
new filetypesignature("windows pe executable", "application/x-msdownload", "exe", 90));
// 音频视频
file_signatures.put("494433",
new filetypesignature("mp3 audio", "audio/mpeg", "mp3", 85));
file_signatures.put("52494646",
new filetypesignature("riff container (wav/avi)", "audio/wav", "wav", 80));
file_signatures.put("00000018667479706d703432",
new filetypesignature("mp4 video", "video/mp4", "mp4", 90));
// 数据库
file_signatures.put("53514c69746520666f726d6174203300",
new filetypesignature("sqlite database", "application/x-sqlite3", "db", 100));
}
public static class fileidentificationresult {
private final string filename;
private final string filepath;
private final filetypesignature identifiedtype;
private final string fallbacktype;
private final long filesize;
private final date lastmodified;
private final boolean isdirectory;
private final boolean exists;
public fileidentificationresult(string filename, string filepath, filetypesignature identifiedtype,
string fallbacktype, long filesize, date lastmodified,
boolean isdirectory, boolean exists) {
this.filename = filename;
this.filepath = filepath;
this.identifiedtype = identifiedtype;
this.fallbacktype = fallbacktype;
this.filesize = filesize;
this.lastmodified = lastmodified;
this.isdirectory = isdirectory;
this.exists = exists;
}
// getters
public string getfilename() { return filename; }
public string getfilepath() { return filepath; }
public filetypesignature getidentifiedtype() { return identifiedtype; }
public string getfallbacktype() { return fallbacktype; }
public long getfilesize() { return filesize; }
public date getlastmodified() { return lastmodified; }
public boolean isdirectory() { return isdirectory; }
public boolean exists() { return exists; }
public string getformattedfilesize() {
if (filesize < 1024) return filesize + " b";
else if (filesize < 1024 * 1024) return string.format("%.1f kb", filesize / 1024.0);
else if (filesize < 1024 * 1024 * 1024) return string.format("%.1f mb", filesize / (1024.0 * 1024.0));
else return string.format("%.1f gb", filesize / (1024.0 * 1024.0 * 1024.0));
}
public string getformattedlastmodified() {
return date_format.format(lastmodified);
}
public string getfinaltypedescription() {
if (!exists) return "file does not exist";
if (isdirectory) return "directory";
if (identifiedtype != null) return identifiedtype.getdescription();
return fallbacktype != null ? fallbacktype : "unknown data";
}
public string getfinalmimetype() {
if (!exists) return "application/x-not-exist";
if (isdirectory) return "inode/directory";
if (identifiedtype != null) return identifiedtype.getmimetype();
return "application/octet-stream";
}
@override
public string tostring() {
stringbuilder sb = new stringbuilder();
sb.append(filename).append(": ").append(getfinaltypedescription());
sb.append(" (").append(getformattedfilesize()).append(", modified: ").append(getformattedlastmodified()).append(")");
return sb.tostring();
}
}
public static fileidentificationresult identifyfile(string filepath, boolean followlinks) throws ioexception {
path path = paths.get(filepath);
// 解析符号链接
if (followlinks && files.issymboliclink(path)) {
try {
path = files.readsymboliclink(path);
} catch (ioexception e) {
// 如果无法解析符号链接,继续使用原路径
}
}
basicfileattributes attrs;
try {
attrs = files.readattributes(path, basicfileattributes.class);
} catch (nosuchfileexception e) {
return new fileidentificationresult(
new file(filepath).getname(),
filepath,
null,
null,
0,
new date(),
false,
false
);
}
// 检查是否为目录
if (attrs.isdirectory()) {
return new fileidentificationresult(
new file(filepath).getname(),
filepath,
null,
null,
attrs.size(),
new date(attrs.lastmodifiedtime().tomillis()),
true,
true
);
}
// 读取文件头部
byte[] header = readheaderbytes(path, 32);
// 匹配文件签名
filetypesignature matchedsignature = matchfilesignature(header);
// 如果没有匹配到签名,尝试文本检测
string fallbacktype = null;
if (matchedsignature == null) {
if (isplaintextfile(path)) {
fallbacktype = "ascii text";
} else if (isutf8textfile(path)) {
fallbacktype = "utf-8 unicode text";
} else {
fallbacktype = "data";
}
}
return new fileidentificationresult(
new file(filepath).getname(),
filepath,
matchedsignature,
fallbacktype,
attrs.size(),
new date(attrs.lastmodifiedtime().tomillis()),
false,
true
);
}
private static byte[] readheaderbytes(path path, int maxlength) throws ioexception {
try (inputstream is = files.newinputstream(path)) {
bytearrayoutputstream baos = new bytearrayoutputstream();
byte[] buffer = new byte[1024];
int totalread = 0;
int bytesread;
while (totalread < maxlength && (bytesread = is.read(buffer, 0,
math.min(buffer.length, maxlength - totalread))) != -1) {
baos.write(buffer, 0, bytesread);
totalread += bytesread;
}
return baos.tobytearray();
}
}
private static filetypesignature matchfilesignature(byte[] header) {
if (header.length == 0) {
return null;
}
string hexheader = bytestohex(header);
// 尝试匹配不同长度的签名
list<map.entry<string, filetypesignature>> matches = new arraylist<>();
for (map.entry<string, filetypesignature> entry : file_signatures.entryset()) {
string signature = entry.getkey();
if (hexheader.startswith(signature)) {
matches.add(entry);
}
}
// 如果有多个匹配,选择最长的那个(最具体的)
if (!matches.isempty()) {
matches.sort((a, b) -> integer.compare(b.getkey().length(), a.getkey().length()));
return matches.get(0).getvalue();
}
return null;
}
private static string bytestohex(byte[] bytes) {
stringbuilder sb = new stringbuilder();
for (byte b : bytes) {
sb.append(string.format("%02x", b));
}
return sb.tostring();
}
private static boolean isplaintextfile(path path) {
try {
long size = files.size(path);
if (size == 0) {
return true;
}
// 对于大文件,只检查前8kb
long checksize = math.min(size, 8192);
byte[] content = files.readallbytes(path);
if (checksize < content.length) {
byte[] truncated = new byte[(int) checksize];
system.arraycopy(content, 0, truncated, 0, (int) checksize);
content = truncated;
}
int nonprintablecount = 0;
for (byte b : content) {
// 允许的控制字符:制表符(9)、换行符(10)、回车符(13)
if (b < 32 && b != 9 && b != 10 && b != 13) {
nonprintablecount++;
}
// 检查高位设置的字符(可能是非ascii)
if (b < 0) {
nonprintablecount++; // 对于纯ascii文本,负值表示非ascii
}
}
// 如果非打印字符比例小于30%,认为是文本文件
return ((double) nonprintablecount / content.length) < 0.3;
} catch (ioexception e) {
return false;
}
}
private static boolean isutf8textfile(path path) {
try {
byte[] content = files.readallbytes(path);
if (content.length == 0) {
return true;
}
// 检查utf-8 bom
if (content.length >= 3 &&
content[0] == (byte)0xef &&
content[1] == (byte)0xbb &&
content[2] == (byte)0xbf) {
// 跳过bom
byte[] withoutbom = new byte[content.length - 3];
system.arraycopy(content, 3, withoutbom, 0, withoutbom.length);
content = withoutbom;
}
// 验证utf-8编码
int i = 0;
while (i < content.length) {
byte b = content[i];
if ((b & 0x80) == 0) {
// 1-byte sequence (ascii)
i++;
} else if ((b & 0xe0) == 0xc0) {
// 2-byte sequence
if (i + 1 >= content.length) return false;
if ((content[i+1] & 0xc0) != 0x80) return false;
i += 2;
} else if ((b & 0xf0) == 0xe0) {
// 3-byte sequence
if (i + 2 >= content.length) return false;
if ((content[i+1] & 0xc0) != 0x80) return false;
if ((content[i+2] & 0xc0) != 0x80) return false;
i += 3;
} else if ((b & 0xf8) == 0xf0) {
// 4-byte sequence
if (i + 3 >= content.length) return false;
if ((content[i+1] & 0xc0) != 0x80) return false;
if ((content[i+2] & 0xc0) != 0x80) return false;
if ((content[i+3] & 0xc0) != 0x80) return false;
i += 4;
} else {
return false; // invalid utf-8
}
}
// 如果是有效的utf-8,检查是否主要是文本内容
string text;
try {
text = new string(content, "utf-8");
} catch (exception e) {
return false;
}
int controlcharcount = 0;
for (char c : text.tochararray()) {
if (c < 32 && c != '\t' && c != '\n' && c != '\r') {
controlcharcount++;
}
}
return ((double) controlcharcount / text.length()) < 0.3;
} catch (exception e) {
return false;
}
}
public static list<fileidentificationresult> identifyfiles(list<string> filepaths, boolean followlinks) {
list<fileidentificationresult> results = new arraylist<>();
for (string filepath : filepaths) {
try {
fileidentificationresult result = identifyfile(filepath, followlinks);
results.add(result);
} catch (ioexception e) {
results.add(new fileidentificationresult(
new file(filepath).getname(),
filepath,
null,
"error: " + e.getmessage(),
0,
new date(),
false,
false
));
}
}
return results;
}
public static list<fileidentificationresult> identifydirectory(string dirpath, boolean recursive, boolean followlinks) {
list<fileidentificationresult> results = new arraylist<>();
try {
path dir = paths.get(dirpath);
if (!files.exists(dir)) {
system.err.println("directory does not exist: " + dirpath);
return results;
}
if (!files.isdirectory(dir)) {
// 如果不是目录,当作普通文件处理
try {
results.add(identifyfile(dirpath, followlinks));
} catch (ioexception e) {
system.err.println("error processing " + dirpath + ": " + e.getmessage());
}
return results;
}
if (recursive) {
files.walk(dir)
.filter(files::isregularfile)
.foreach(path -> {
try {
results.add(identifyfile(path.tostring(), followlinks));
} catch (ioexception e) {
system.err.println("error processing " + path + ": " + e.getmessage());
}
});
} else {
files.list(dir)
.filter(files::isregularfile)
.foreach(path -> {
try {
results.add(identifyfile(path.tostring(), followlinks));
} catch (ioexception e) {
system.err.println("error processing " + path + ": " + e.getmessage());
}
});
}
} catch (ioexception e) {
system.err.println("error accessing directory " + dirpath + ": " + e.getmessage());
}
return results;
}
public static void printresults(list<fileidentificationresult> results, boolean showmime, boolean showdetails) {
for (fileidentificationresult result : results) {
if (showdetails) {
system.out.println("=== file information ===");
system.out.println("name: " + result.getfilename());
system.out.println("path: " + result.getfilepath());
system.out.println("type: " + result.getfinaltypedescription());
if (showmime) {
system.out.println("mime: " + result.getfinalmimetype());
}
system.out.println("size: " + result.getformattedfilesize());
system.out.println("last modified: " + result.getformattedlastmodified());
if (result.getidentifiedtype() != null) {
system.out.println("confidence: " + result.getidentifiedtype().getconfidencelevel() + "%");
system.out.println("suggested extension: ." + result.getidentifiedtype().getextension());
}
system.out.println("========================");
} else {
if (showmime) {
system.out.println(result.getfilename() + ": " + result.getfinalmimetype());
} else {
system.out.println(result);
}
}
}
}
public static void printsummary(list<fileidentificationresult> results) {
system.out.println("\n=== summary ===");
system.out.println("total files processed: " + results.size());
long totalsize = results.stream()
.filter(fileidentificationresult::exists)
.maptolong(fileidentificationresult::getfilesize)
.sum();
system.out.println("total size: " + formatfilesize(totalsize));
map<string, long> typecounts = results.stream()
.filter(r -> r.exists() && !r.isdirectory())
.collect(collectors.groupingby(
fileidentificationresult::getfinaltypedescription,
collectors.counting()
));
system.out.println("file types:");
typecounts.entryset().stream()
.sorted(map.entry.<string, long>comparingbyvalue().reversed())
.foreach(entry ->
system.out.println(" " + entry.getkey() + ": " + entry.getvalue() + " file(s)")
);
}
private static string formatfilesize(long size) {
if (size < 1024) return size + " b";
else if (size < 1024 * 1024) return string.format("%.1f kb", size / 1024.0);
else if (size < 1024 * 1024 * 1024) return string.format("%.1f mb", size / (1024.0 * 1024.0));
else return string.format("%.1f gb", size / (1024.0 * 1024.0 * 1024.0));
}
public static void main(string[] args) {
if (args.length == 0) {
printhelp();
return;
}
boolean showmime = false;
boolean showdetails = false;
boolean followlinks = false;
boolean recursive = false;
boolean summary = false;
boolean batchmode = false;
list<string> filestoprocess = new arraylist<>();
for (int i = 0; i < args.length; i++) {
string arg = args[i];
if (arg.equals("-h") || arg.equals("--help")) {
printhelp();
return;
} else if (arg.equals("-i") || arg.equals("--mime")) {
showmime = true;
} else if (arg.equals("-l") || arg.equals("--long")) {
showdetails = true;
} else if (arg.equals("-l") || arg.equals("--follow-links")) {
followlinks = true;
} else if (arg.equals("-r") || arg.equals("--recursive")) {
recursive = true;
} else if (arg.equals("-s") || arg.equals("--summary")) {
summary = true;
} else if (arg.equals("-f") || arg.equals("--file-list")) {
if (i + 1 < args.length) {
batchmode = true;
string filelistpath = args[++i];
try {
list<string> filelist = files.readalllines(paths.get(filelistpath));
filestoprocess.addall(filelist);
} catch (ioexception e) {
system.err.println("error reading file list: " + e.getmessage());
return;
}
} else {
system.err.println("missing filename after " + arg);
return;
}
} else if (arg.startswith("-")) {
system.err.println("unknown option: " + arg);
printhelp();
return;
} else {
filestoprocess.add(arg);
}
}
if (filestoprocess.isempty()) {
system.out.println("no files specified");
return;
}
list<fileidentificationresult> results = new arraylist<>();
if (batchmode) {
// 批量模式,每个参数都是文件路径
results = identifyfiles(filestoprocess, followlinks);
} else {
// 普通模式,检查每个参数是文件还是目录
for (string path : filestoprocess) {
file file = new file(path);
if (file.isdirectory()) {
list<fileidentificationresult> dirresults = identifydirectory(path, recursive, followlinks);
results.addall(dirresults);
} else {
try {
results.add(identifyfile(path, followlinks));
} catch (ioexception e) {
system.err.println("error processing " + path + ": " + e.getmessage());
}
}
}
}
printresults(results, showmime, showdetails);
if (summary && !results.isempty()) {
printsummary(results);
}
}
private static void printhelp() {
system.out.println("professional file identifier");
system.out.println("usage: java professionalfileidentifier [options] <file_or_directory>...");
system.out.println();
system.out.println("options:");
system.out.println(" -i, --mime show mime type instead of description");
system.out.println(" -l, --long show detailed information");
system.out.println(" -l, --follow-links follow symbolic links");
system.out.println(" -r, --recursive recursively process directories");
system.out.println(" -s, --summary show summary statistics");
system.out.println(" -f, --file-list <file> read file paths from specified file");
system.out.println(" -h, --help show this help message");
system.out.println();
system.out.println("examples:");
system.out.println(" java professionalfileidentifier myfile.pdf");
system.out.println(" java professionalfileidentifier -i myfile.pdf");
system.out.println(" java professionalfileidentifier -l myfile.pdf");
system.out.println(" java professionalfileidentifier -r /path/to/directory");
system.out.println(" java professionalfileidentifier -f filelist.txt");
system.out.println();
system.out.println("supported file formats include: png, jpeg, gif, bmp, tiff, pdf, zip, rar, gzip, bzip2, elf, mp3, wav, mp4, sqlite, and more.");
}
}
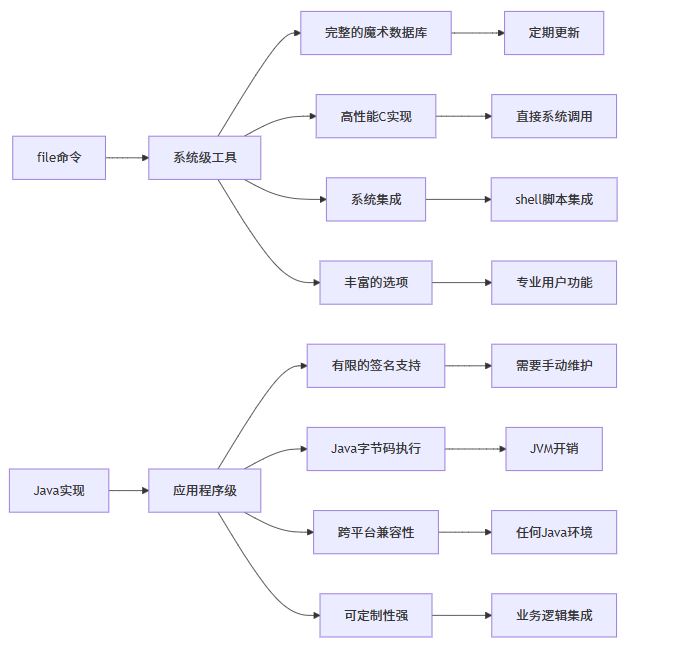
file 命令与java实现的对比
相关资源和参考
对于想要深入了解文件格式和魔术数字的开发者,以下资源非常有价值:
- the file signatures database - 一个全面的文件签名数据库,包含数百种文件格式的详细信息
- iana media types - 官方mime类型注册表
- linux man page for file command - file命令的官方手册页
性能优化建议
在实际应用中,文件类型识别可能成为性能瓶颈,特别是在处理大量文件时。以下是一些优化建议:
1. 缓存机制
import java.util.concurrent.concurrenthashmap;
import java.util.concurrent.timeunit;
public class cachedfileidentifier extends professionalfileidentifier {
private static final concurrenthashmap<string, fileidentificationresult> cache = new concurrenthashmap<>();
private static final long cache_expiration_ms = timeunit.minutes.tomillis(5);
private static class cacheentry {
final fileidentificationresult result;
final long timestamp;
cacheentry(fileidentificationresult result) {
this.result = result;
this.timestamp = system.currenttimemillis();
}
boolean isexpired() {
return system.currenttimemillis() - timestamp > cache_expiration_ms;
}
}
public static fileidentificationresult identifyfilewithcache(string filepath, boolean followlinks) throws ioexception {
// 清理过期缓存
cache.entryset().removeif(entry -> entry.getvalue().isexpired());
// 检查缓存
cacheentry cached = cache.get(filepath);
if (cached != null && !cached.isexpired()) {
return cached.result;
}
// 执行实际识别
fileidentificationresult result = identifyfile(filepath, followlinks);
// 缓存结果
cache.put(filepath, new cacheentry(result));
return result;
}
}
2. 并行处理
import java.util.concurrent.*;
import java.util.stream.collectors;
public class parallelfileidentifier {
public static list<fileidentificationresult> identifyfilesparallel(list<string> filepaths,
boolean followlinks,
int threads) {
executorservice executor = executors.newfixedthreadpool(threads);
list<future<fileidentificationresult>> futures = new arraylist<>();
for (string filepath : filepaths) {
future<fileidentificationresult> future = executor.submit(() -> {
try {
return professionalfileidentifier.identifyfile(filepath, followlinks);
} catch (ioexception e) {
return new professionalfileidentifier.fileidentificationresult(
new file(filepath).getname(),
filepath,
null,
"error: " + e.getmessage(),
0,
new date(),
false,
false
);
}
});
futures.add(future);
}
list<fileidentificationresult> results = new arraylist<>();
for (future<fileidentificationresult> future : futures) {
try {
results.add(future.get());
} catch (interruptedexception | executionexception e) {
// 处理异常
system.err.println("error in parallel processing: " + e.getmessage());
}
}
executor.shutdown();
return results;
}
}
安全考虑
在实现文件类型识别时,需要注意以下安全问题:
1. 路径遍历攻击防护
public class securefileidentifier {
private static final set<string> blacklisted_extensions = set.of(
"exe", "bat", "cmd", "com", "scr", "pif", "vbs", "js", "jar"
);
public static boolean issafetoprocess(string filepath) {
file file = new file(filepath);
// 规范化路径,防止../攻击
try {
string canonicalpath = file.getcanonicalpath();
string absolutepath = file.getabsolutepath();
// 检查路径遍历
if (!canonicalpath.equals(absolutepath)) {
return false;
}
// 检查黑名单扩展名
string filename = file.getname();
int dotindex = filename.lastindexof('.');
if (dotindex > 0) {
string extension = filename.substring(dotindex + 1).tolowercase();
if (blacklisted_extensions.contains(extension)) {
return false;
}
}
return true;
} catch (ioexception e) {
return false;
}
}
public static fileidentificationresult secureidentifyfile(string filepath, boolean followlinks) throws ioexception {
if (!issafetoprocess(filepath)) {
throw new securityexception("file path is not safe to process: " + filepath);
}
return professionalfileidentifier.identifyfile(filepath, followlinks);
}
}
2. 文件大小限制
public class sizelimitedfileidentifier {
private static final long max_file_size = 100 * 1024 * 1024; // 100mb
public static fileidentificationresult identifyfilewithsizelimit(string filepath, boolean followlinks) throws ioexception {
path path = paths.get(filepath);
if (!files.exists(path)) {
throw new filenotfoundexception("file does not exist: " + filepath);
}
long filesize = files.size(path);
if (filesize > max_file_size) {
throw new ioexception("file too large to process: " + filesize + " bytes (limit: " + max_file_size + ")");
}
return professionalfileidentifier.identifyfile(filepath, followlinks);
}
}
实际应用案例
web应用中的文件上传验证
import javax.servlet.http.part;
import java.io.ioexception;
import java.io.inputstream;
public class fileuploadvalidator {
public static class uploadvalidationresult {
private final boolean isvalid;
private final string errormessage;
private final string detectedtype;
private final string suggestedextension;
public uploadvalidationresult(boolean isvalid, string errormessage, string detectedtype, string suggestedextension) {
this.isvalid = isvalid;
this.errormessage = errormessage;
this.detectedtype = detectedtype;
this.suggestedextension = suggestedextension;
}
// getters
public boolean isvalid() { return isvalid; }
public string geterrormessage() { return errormessage; }
public string getdetectedtype() { return detectedtype; }
public string getsuggestedextension() { return suggestedextension; }
}
private static final set<string> allowed_mime_types = set.of(
"image/jpeg", "image/png", "image/gif", "application/pdf"
);
private static final long max_upload_size = 10 * 1024 * 1024; // 10mb
public static uploadvalidationresult validateupload(part filepart) {
try {
// 检查文件大小
long filesize = filepart.getsize();
if (filesize > max_upload_size) {
return new uploadvalidationresult(false, "file too large", null, null);
}
if (filesize == 0) {
return new uploadvalidationresult(false, "empty file", null, null);
}
// 读取文件头部进行类型检测
byte[] header = readheaderfrompart(filepart, 32);
// 识别文件类型
professionalfileidentifier.filetypesignature signature =
professionalfileidentifier.matchfilesignature(header);
if (signature == null) {
return new uploadvalidationresult(false, "unknown or unsupported file type", null, null);
}
// 检查mime类型是否允许
if (!allowed_mime_types.contains(signature.getmimetype())) {
return new uploadvalidationresult(false, "file type not allowed", signature.getdescription(), signature.getextension());
}
return new uploadvalidationresult(true, null, signature.getdescription(), signature.getextension());
} catch (exception e) {
return new uploadvalidationresult(false, "error validating file: " + e.getmessage(), null, null);
}
}
private static byte[] readheaderfrompart(part filepart, int maxlength) throws ioexception {
try (inputstream is = filepart.getinputstream()) {
bytearrayoutputstream baos = new bytearrayoutputstream();
byte[] buffer = new byte[1024];
int totalread = 0;
int bytesread;
while (totalread < maxlength && (bytesread = is.read(buffer, 0,
math.min(buffer.length, maxlength - totalread))) != -1) {
baos.write(buffer, 0, bytesread);
totalread += bytesread;
}
return baos.tobytearray();
}
}
}
未来发展方向
随着技术的发展,文件类型识别也在不断进化:
1. 机器学习辅助识别
// 伪代码:基于机器学习的文件类型识别
public class mlbasedfileidentifier {
private mlmodel model;
public filetype predictfiletype(byte[] filecontent) {
// 提取特征
featurevector features = extractfeatures(filecontent);
// 使用机器学习模型预测
predictionresult prediction = model.predict(features);
// 返回预测结果
return new filetype(
prediction.getclassname(),
prediction.getmimetype(),
prediction.getconfidence()
);
}
private featurevector extractfeatures(byte[] content) {
// 提取统计特征、模式特征等
// 如:字节分布、熵值、特定模式出现频率等
return new featurevector();
}
}
2. 云服务集成
// 伪代码:与云文件识别服务集成
public class cloudfileidentifier {
private cloudfilerecognitionservice cloudservice;
public fileidentificationresult identifyfilecloud(string filepath) throws ioexception {
// 读取文件内容
byte[] filecontent = files.readallbytes(paths.get(filepath));
// 调用云服务api
cloudrecognitionresult result = cloudservice.recognizefile(filecontent);
// 转换为本地格式
return converttolocalresult(result);
}
private fileidentificationresult converttolocalresult(cloudrecognitionresult cloudresult) {
// 转换逻辑
return new fileidentificationresult(/* ... */);
}
}
学习建议
对于想要深入学习文件类型识别的开发者,我建议:
- 研究文件格式规范:了解常见文件格式的内部结构
- 阅读file命令源码:理解专业实现的细节
- 实践项目:构建自己的文件管理工具
- 关注安全:学习如何防范文件相关的安全漏洞
- 性能优化:研究如何提高大规模文件处理的效率
结语
文件类型识别是系统编程和应用开发中的基础技能。通过理解和实现类似file命令的功能,我们不仅能更好地理解文件系统的运作原理,还能构建更安全、更智能的应用程序。本文提供的java实现虽然简化了真实file命令的复杂性,但已经包含了核心概念和实用功能。
记住,真正的专家不仅知道如何使用工具,还理解工具背后的原理。希望本文能帮助你在成为linux和java专家的道路上迈出坚实的一步!
以上就是linux使用file命令判断文件类型的方法详解的详细内容,更多关于linux file判断文件类型的资料请关注代码网其它相关文章!




发表评论